文章目录
- 神经网络基础
- 基本构成
- 如何训练?
- Word2Vec例子
- 负采样:
- 循环神经网络 RNN
- 门控计算单元 GRU
- 长短时记忆网络 LSTM
- 遗忘门
- 输入门
- 输出门
- 双向RNN
- 卷积神经网络 CNN
- pytorch实战
神经网络基础
基本构成
全称:人工神经网络。启发于生物神经细胞
单个神经元
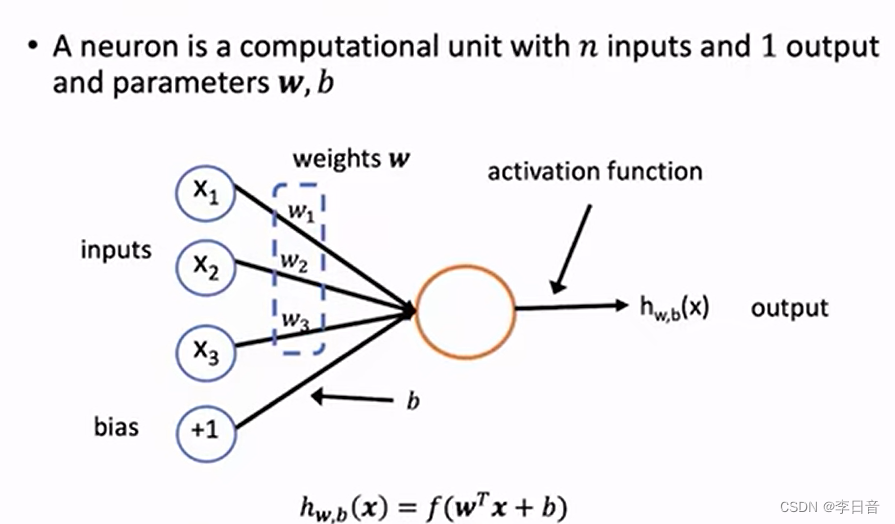
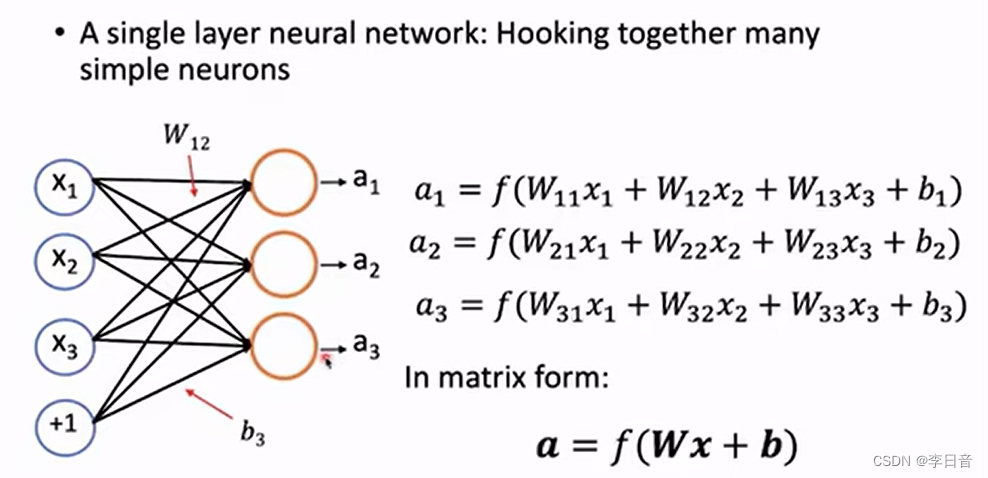
单层神经网络
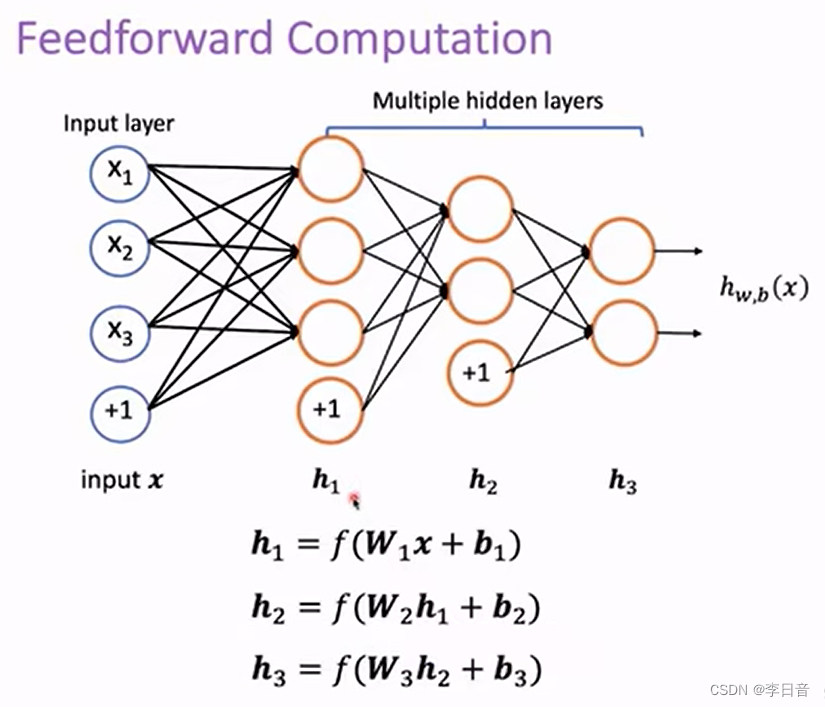
前向计算
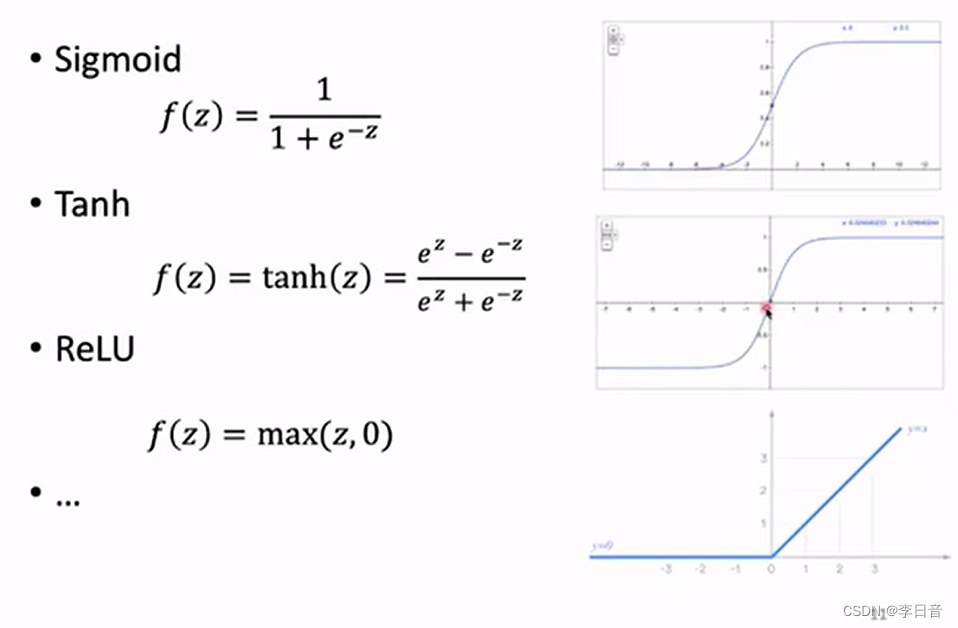
激活函数的作用:没有激活函数的话,多层神经网络就会退化为单层
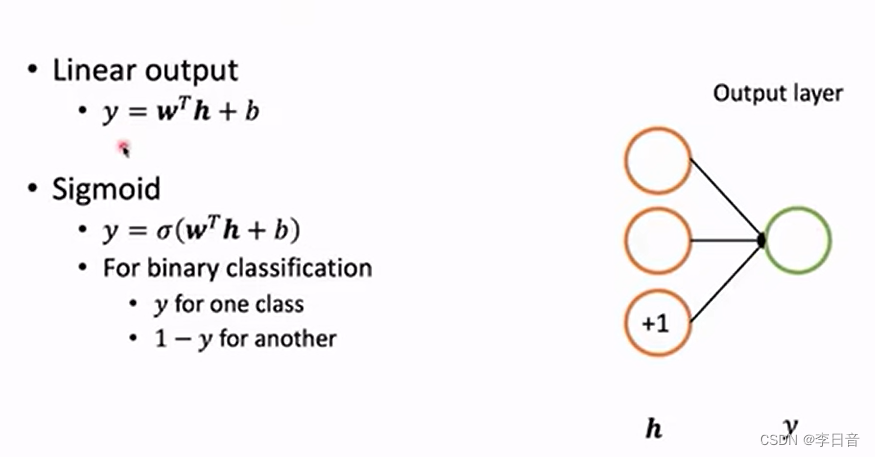
输出层
线性输出:回归问题
sigmoid:二分类
softmax:多分类

如何训练?
- 训练目标:
对回归问题:计算最小均方差

对分类问题:计算交叉熵

- 最小化损失函数:梯度下降法
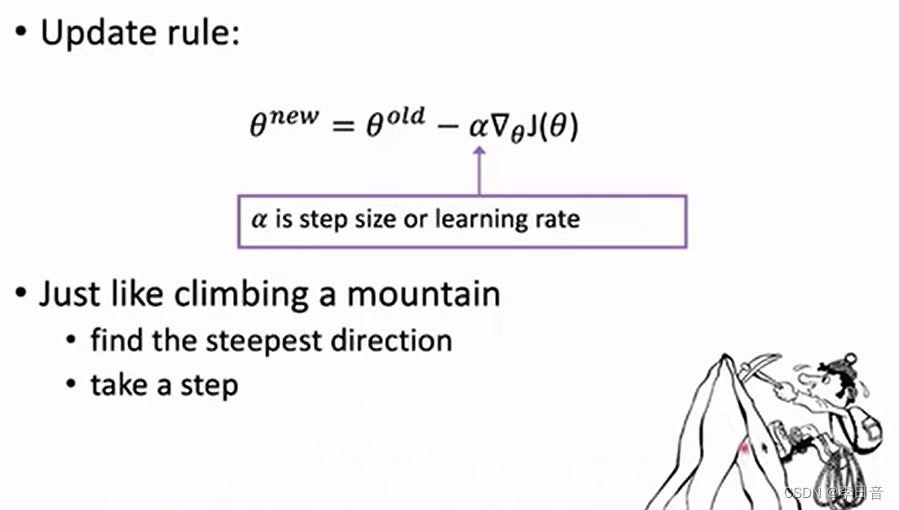
求导梯度从而进行梯度下降

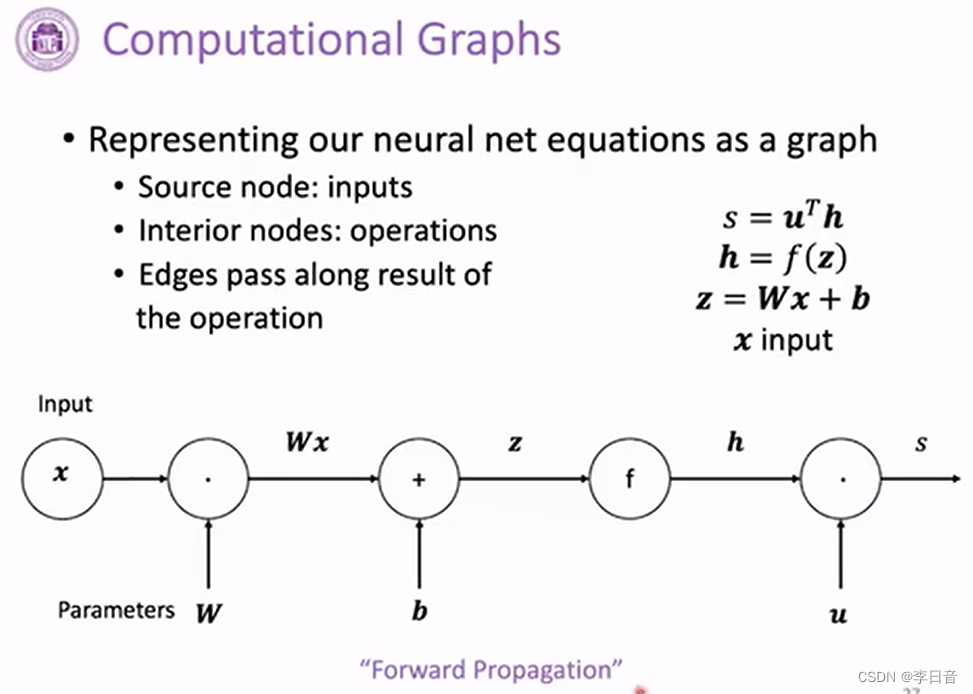
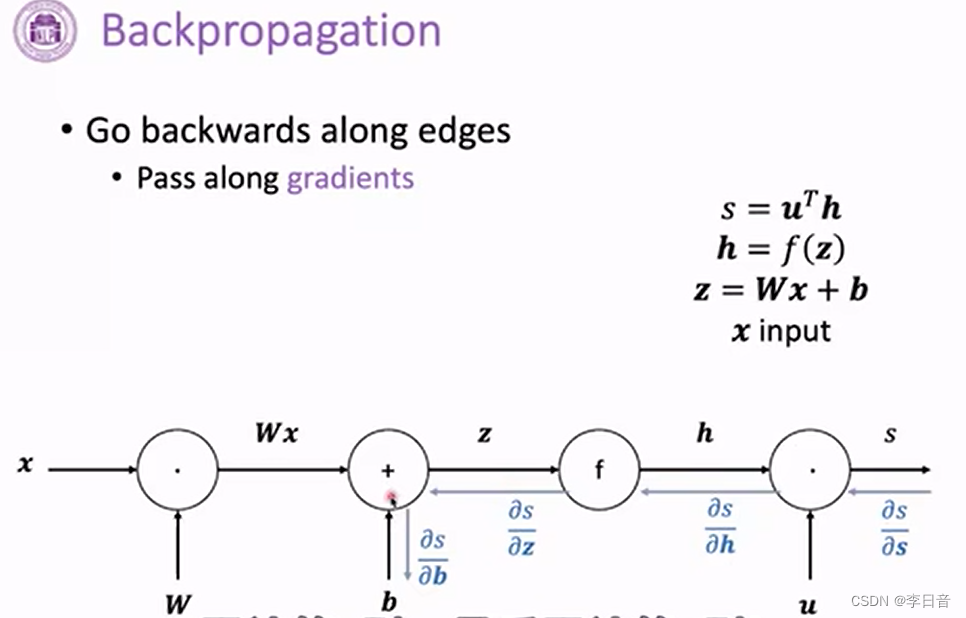
求微分的链式法则

计算图
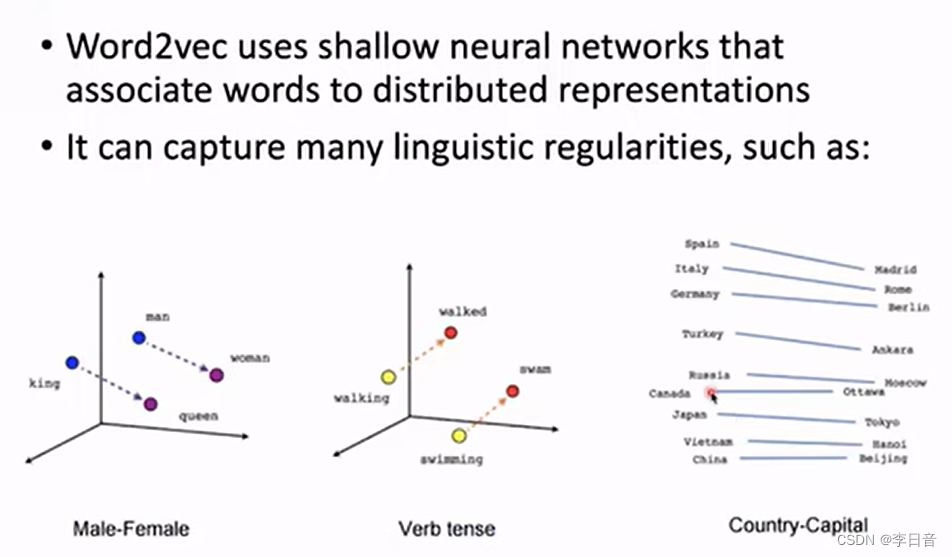
Word2Vec例子
- word2Vec可以学到词与词之间的关系
例如:king-Queen 与 man-woman 近似于平行,这两对词的差异也类似
- 实现:两类模型
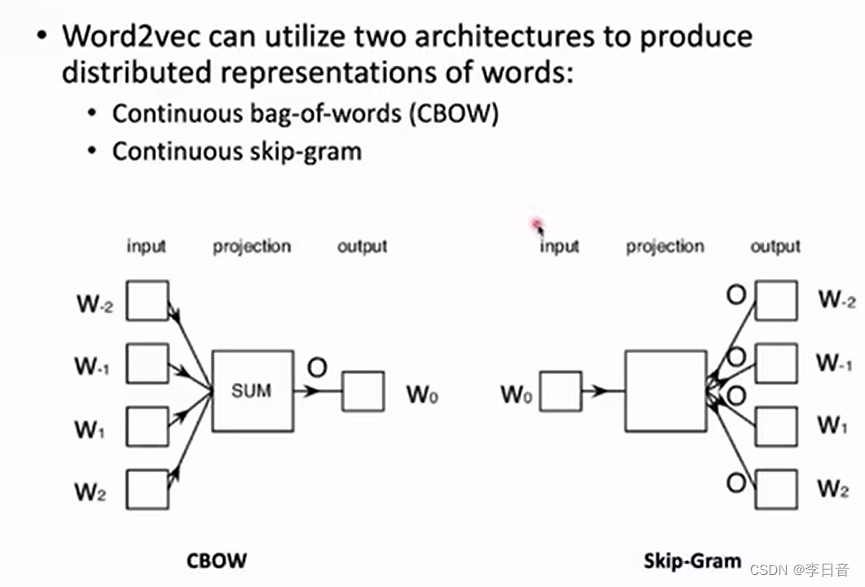
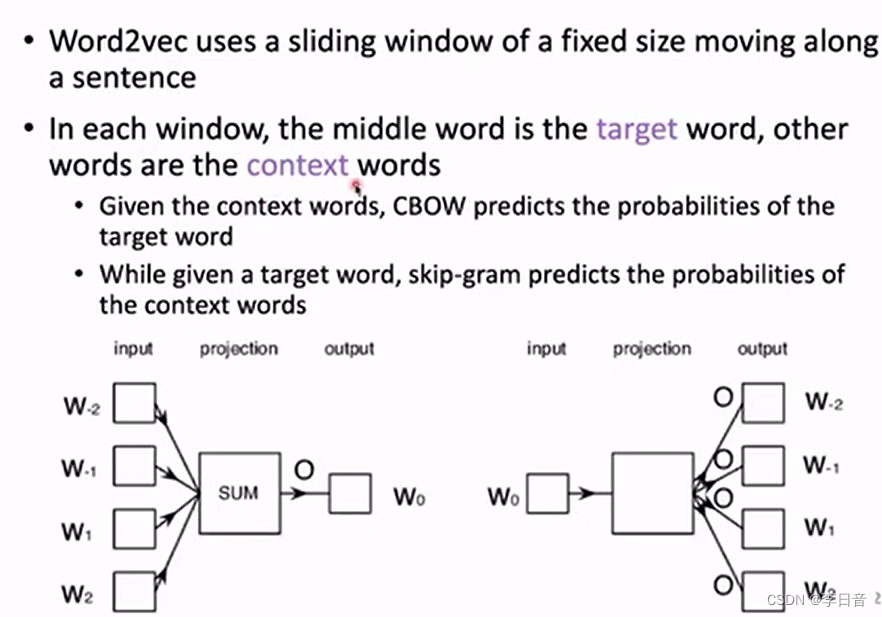
滑动窗口构造训练数据:目标词target ;其他词context
CBOW根据context预测target,skip-Gram相反
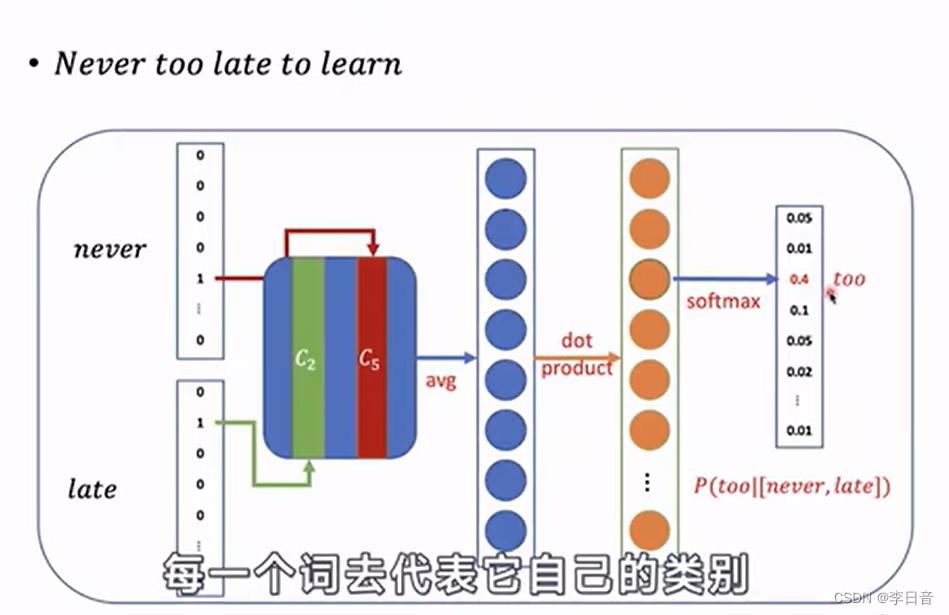
输出词表的概率分布,最大的概率应该对应target
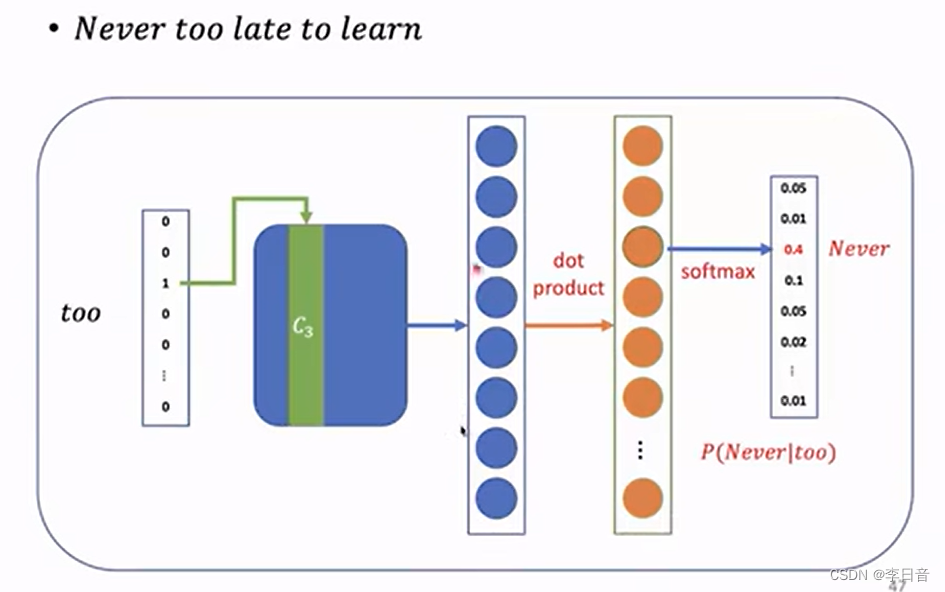
skip-Gram:预测context
- 问题:词表非常大,计算量大。
- 解决方法:负采样、分层softmax
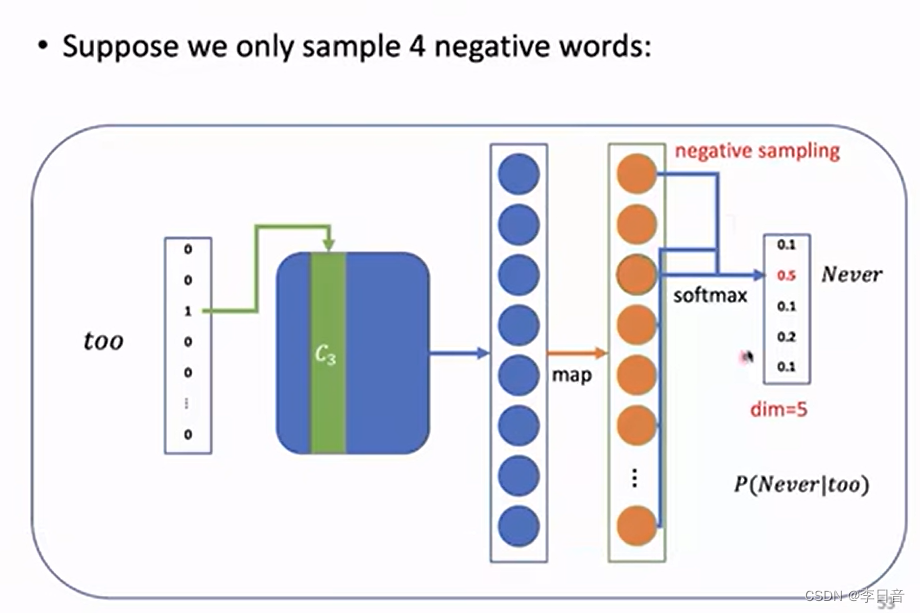
负采样:
只采样一小部分作为负例子,词频越高采样概率越大。3/4可以保证低频词也有一定的采样概率

只采样四个词,其他词不参与计算
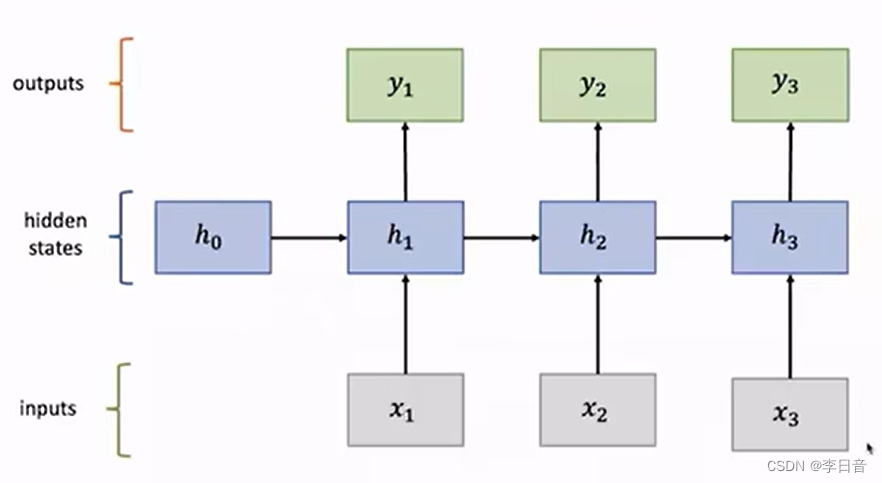
循环神经网络 RNN
处理序列数据时会进行顺序记忆
- 网络结构
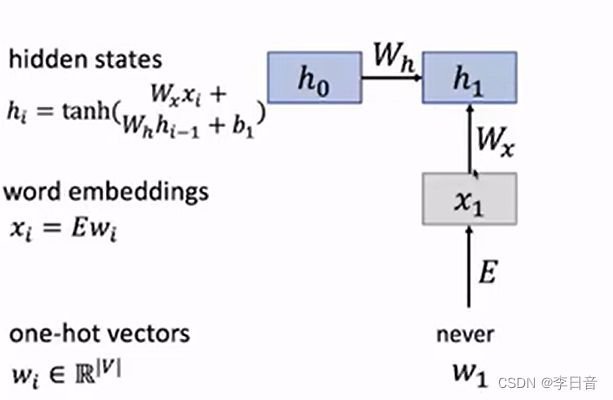
注意 h i h_i hi会有 h i − 1 h_{i-1} hi−1部分的输入

选取概率最大的词作为下一个词
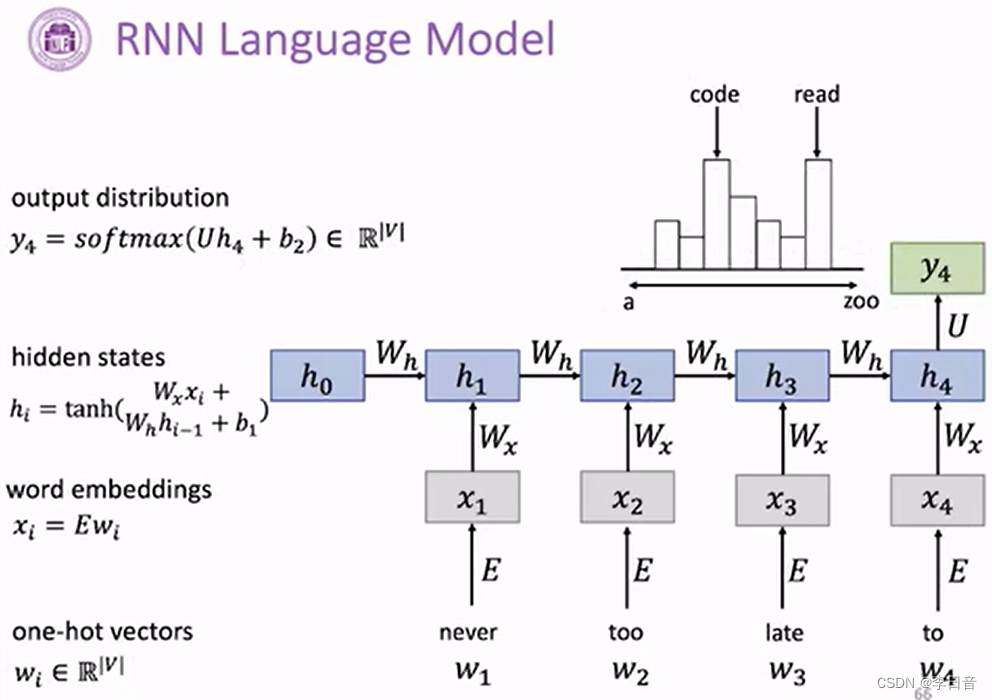
应用场景:序列标注、序列预测、图片描述、文本分类
优点:处理变长数据、模型大小不会随输入增大而增大、参数共享、利用历史信息
缺点:顺序计算时间慢、后面的单元很难获得较早、时间的信息、太多链式的梯度计算–梯度爆炸/消失
变体:GRU/LTSM
核心:计算时保留周围的记忆单元进行数据处理,以捕捉到长距离的依赖性
门控计算单元 GRU
门控机制:对当前信息进行筛选,决定哪些信息会传到下一层。
更新门:当前信息 x i x_i xi和过去隐藏状态 h i − 1 h_{i-1} hi−1的比重问题
重置门:上一层的隐藏状态对当前状态的激活

重置门接近零时, h i h_i hi就和 h i − 1 h_{i-1} hi−1没什么关系了

更新门 z i z_i zi接近零时, h i h_i hi直接由当前输入得到

长短时记忆网络 LSTM
网络结构
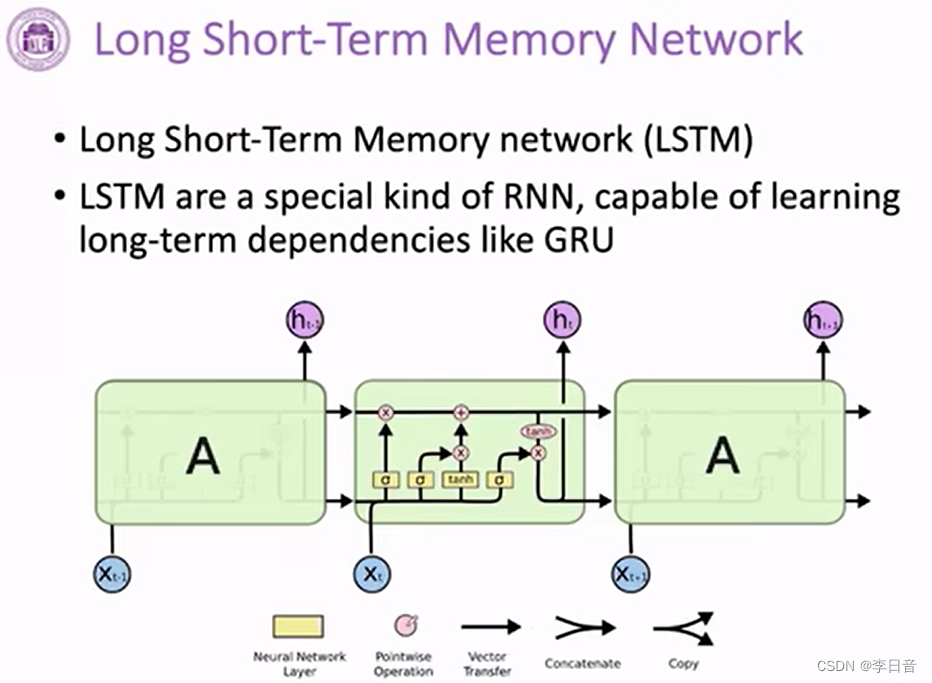
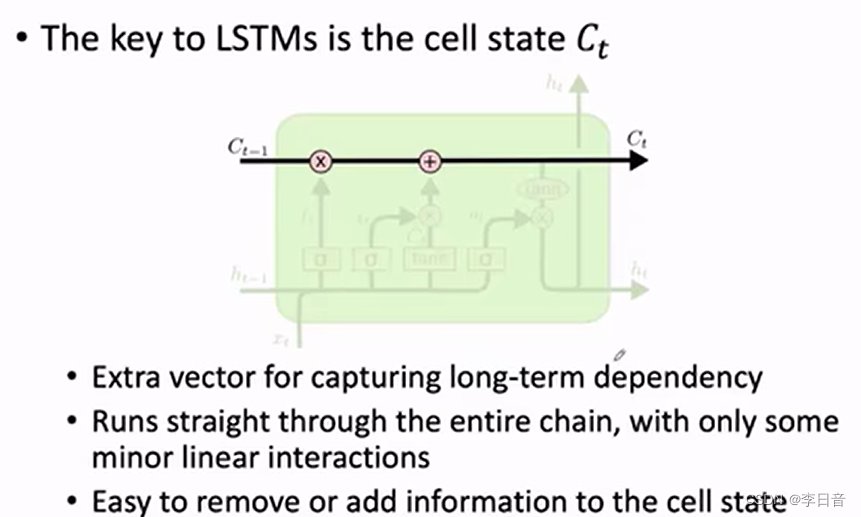
关键改变:增加cell state 学习长期的依赖关系
通过门控添加cell的信息
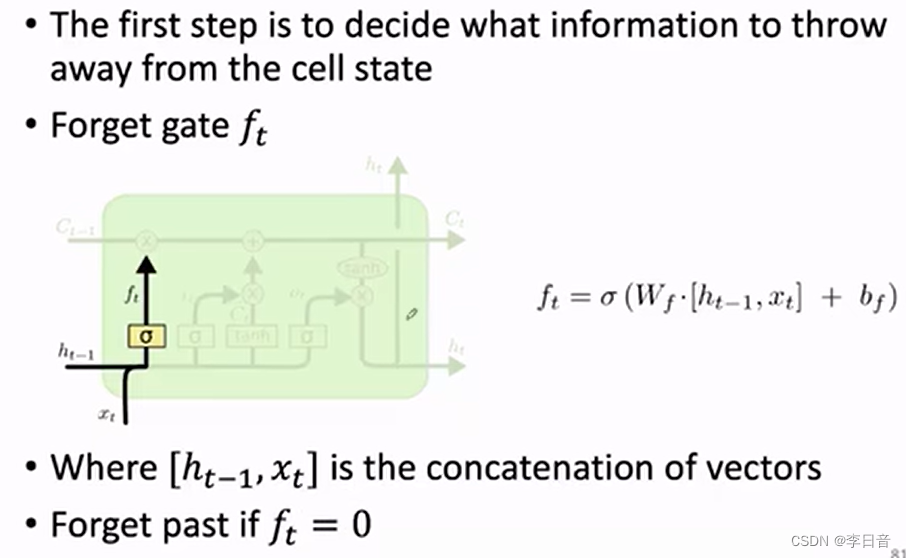
遗忘门
来决定上一个状态有哪些信息可以从cell中移除
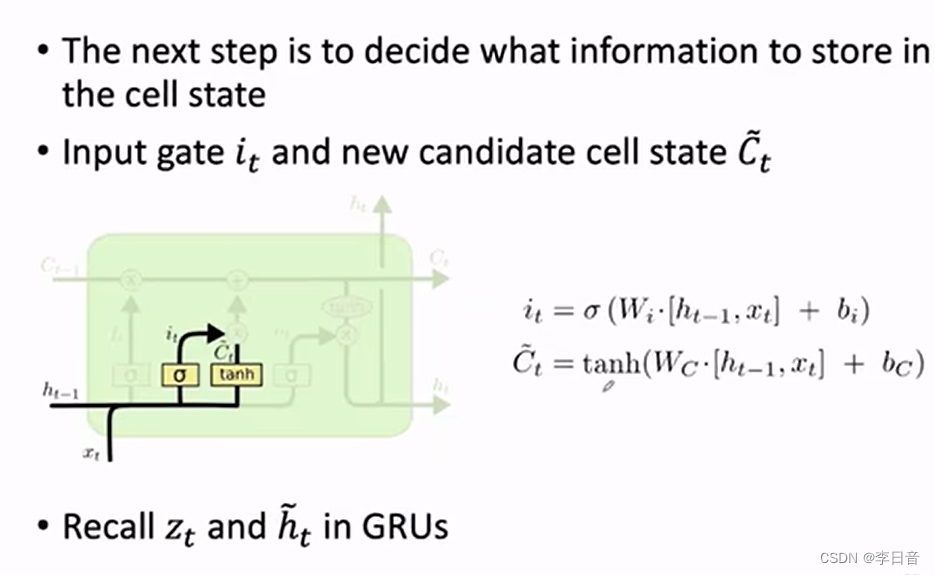
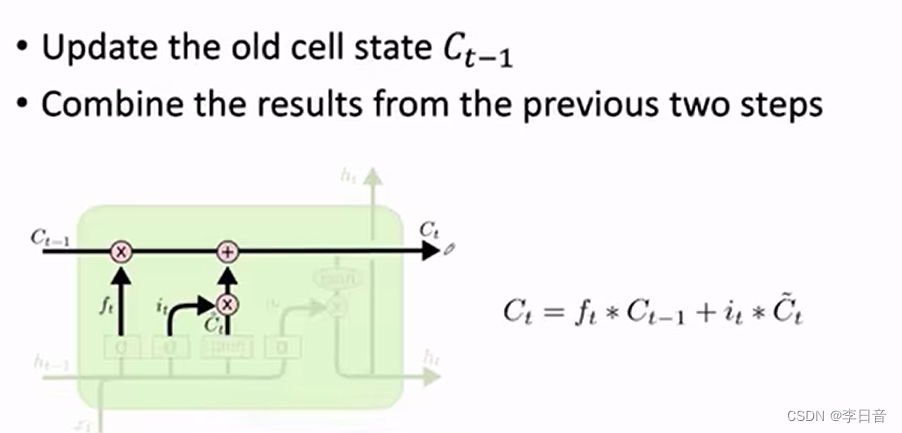
输入门
决定当前信息有哪些可以存到cell中
输出门
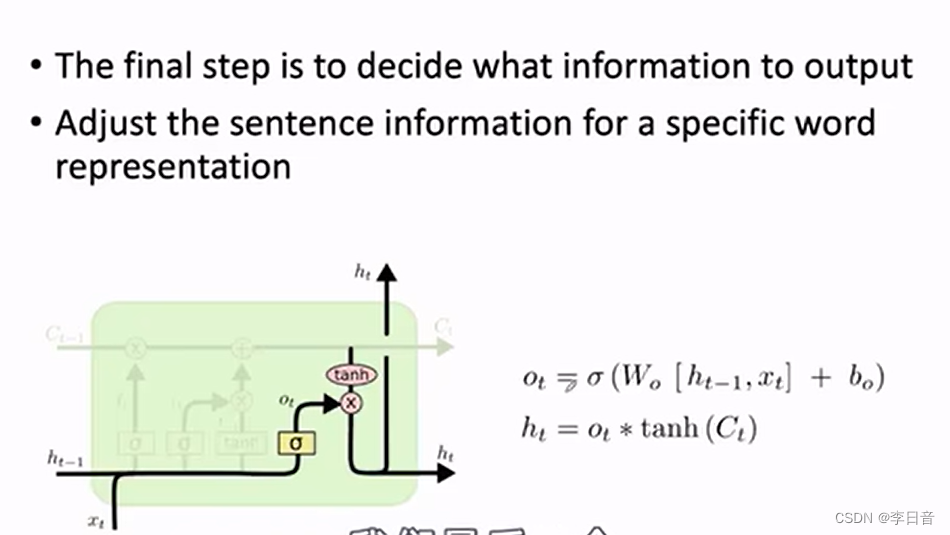
总结:做堆叠或者网络很深时,性能很好。缓解梯度的问题
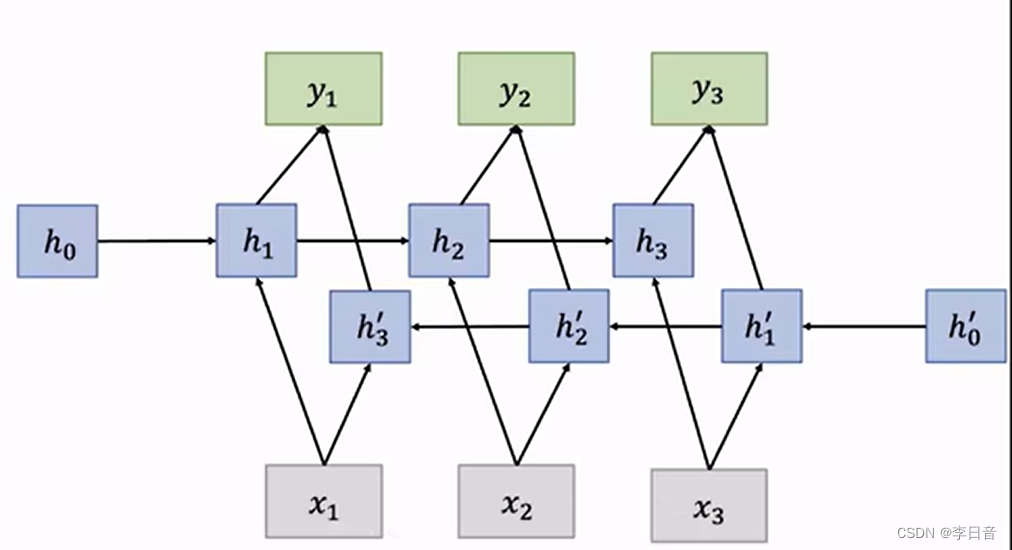
双向RNN
不仅仅取决于过去,还会取决于未来的数据
总结RNN类算法:顺序记忆,但存在梯度问题
卷积神经网络 CNN
图像领域,考虑结构特殊性,也可以用于NLP,如情感分类和关系分类

网络结构:
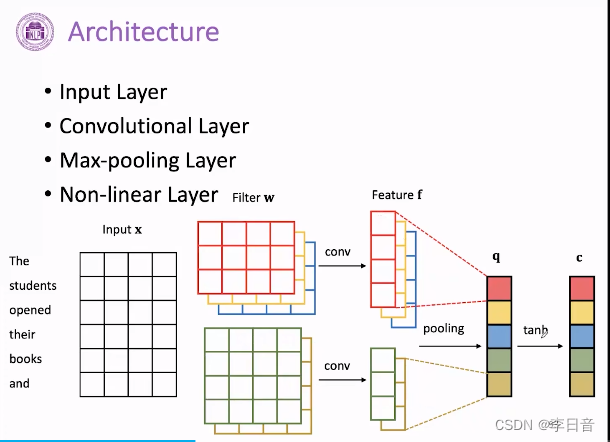
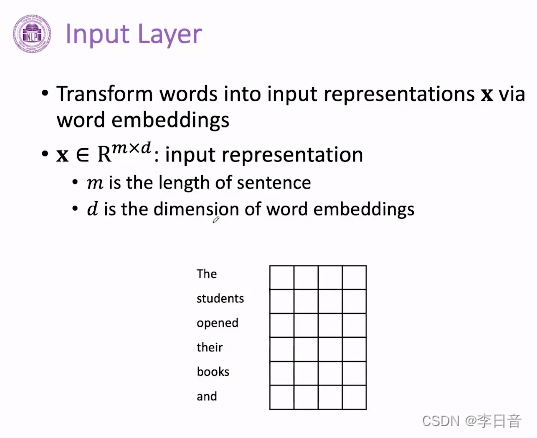
输入层:
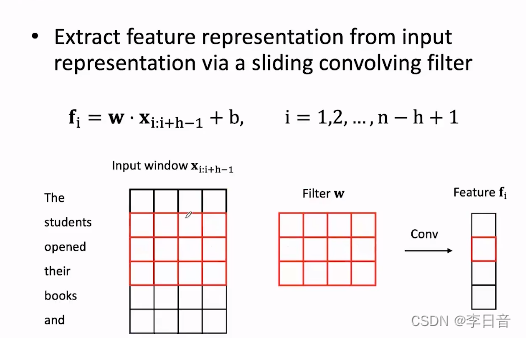
滑动卷积核
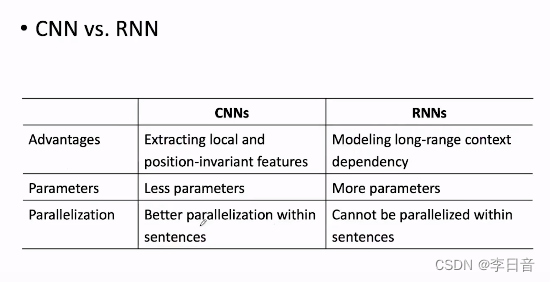
CNN擅长提取局部特征;RNN适用于变长文本
pytorch实战