为啥需要整体方案,直接调用搜索接口取Top1返回不成嘛?要是果真如此Simple&Naive,New Bing岂不是很容易复刻->.->
我们先来看个例子,前一阵火爆全网的常温超导技术,如果想回答LK99哪些板块会涨,你会得到以下搜索答案
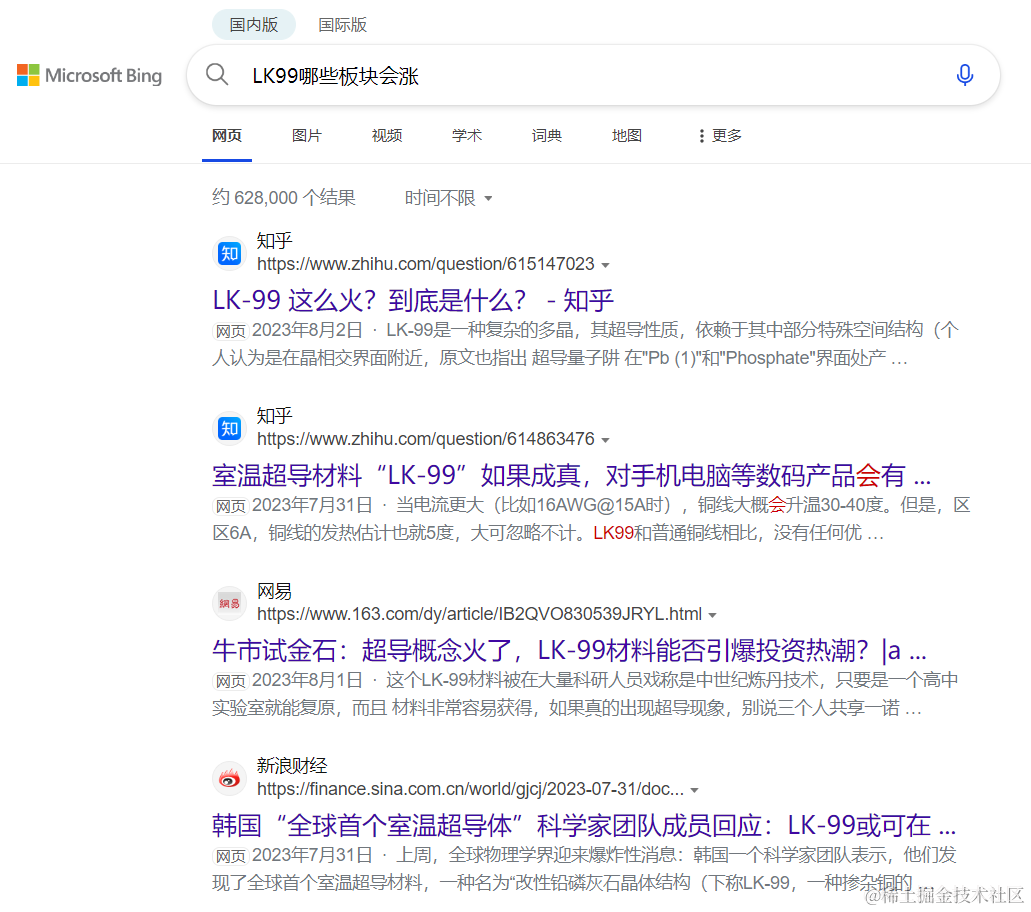
从以上的搜索结果不难发现,Top1答案并不能回答问题,在和搜索引擎交互中几个可能的问题有
- Query:用户的query不适配搜索引擎,导致搜索不到有效内容;或者问题需要通过类似Self Ask的思维链拆解通过多轮搜索来解决
- Ranking:细看langchain的搜索Wrapper,会发现它默认只使用搜索的Top1返回,但是除了传统百科问题,这类问题因为做过优化,Top1往往是最优答案。但其他场景,例如当前问题,第三个内容显然更合适。当前传统搜索引擎并非为大模型使用设计,因此需要后接一些优化排序模块,例如REPLUG论文
- Snippet: Bing的网页标题下面会默认展示150字左右根据query定位的正文摘要内容,也是langchain等框架使用的网页结果。但是不难发现,snippet太短或者定位不准会导致snippet缺乏有效信息
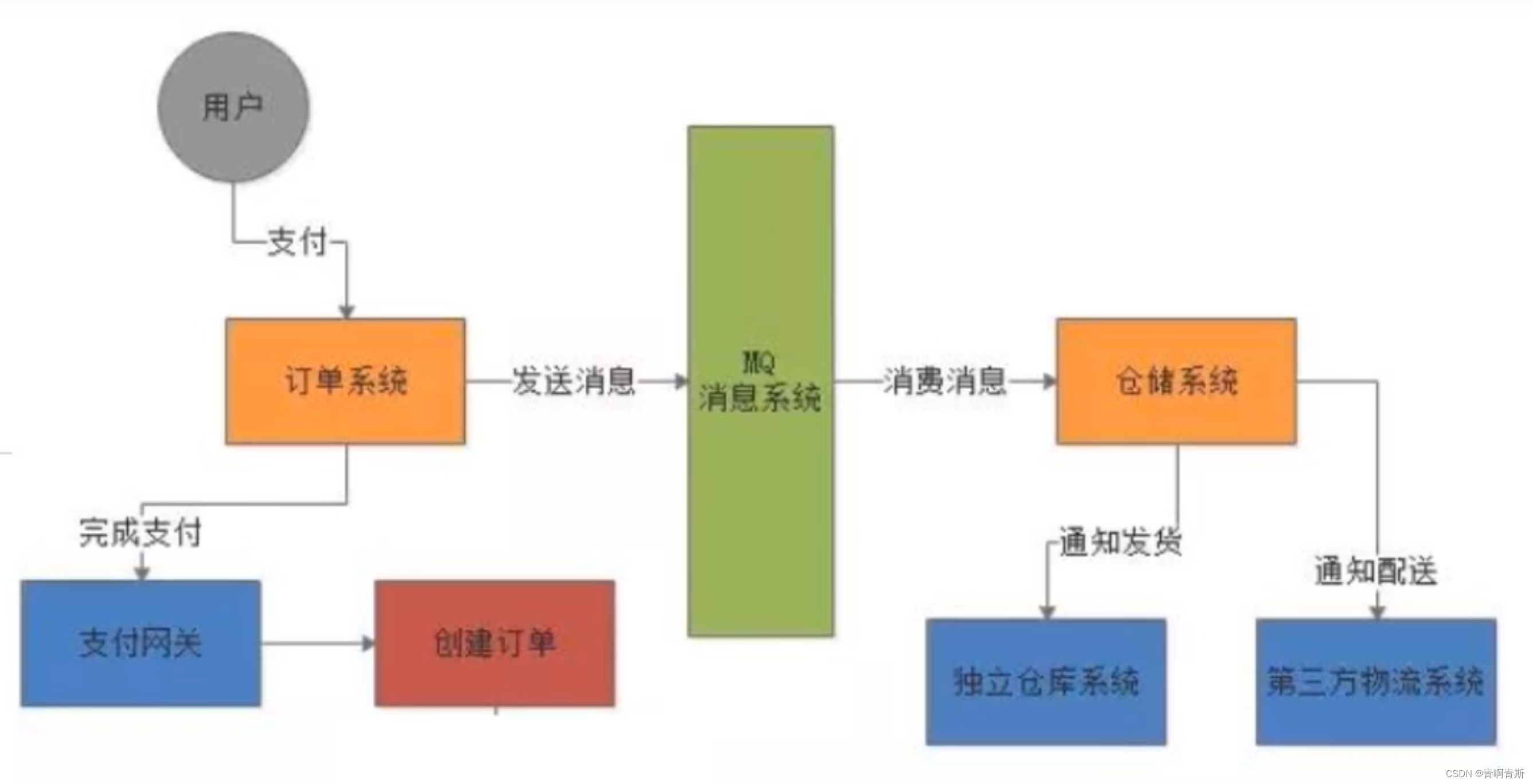
为了解决上述提到的3个主要问题,我们会基于WebGPT,WebGLM,WebCPM的3篇论文,详述如何更有效的和搜索引擎进行交互,来解决长文本开放问答LFQA问题。和搜索引擎的交互主要分成以下4个模块
- Search:生成搜索请求query,或基于结果进行query改写,请求搜索API。类似self-Ask里面的Thought,只不过selfask强调问题拆解,而这里的search还有query改写,追问等功能
- Retrieve:从搜索返回的大段内容中,定位可以回答query的支撑性事实,进行抽取式摘要、生成式摘要。类似React里面的LookUp行为,只不过更加复杂不是简单的定位文字。
- Synthesis: 对多个内容进行组装,输入模型进行推理得到答案
- Action: 针对需要和搜索引擎进行自动化多轮交互的场景,需要预测下一步的行为,是继续搜索,抽取摘要,还是停止搜索,组装内容进行推理等等,对应LLM Agent中的规划模块。其实就是丰富了React/SelfAsk里面的Action,加入了更多和搜索引擎交互的行为,例如继续浏览,翻页等等
虽然论文的发布顺序是webcpm>webglm>webgpt,但考虑webcpm开源了很全面的中文数据哈哈,手动点赞!我会以webcpm作为基准详细介绍,再分别介绍webglm和webgpt的异同点。
webcpm
- paper:WEBCPM: Interactive Web Search for Chinese Long-form Question Answering
- github:https://github.com/thunlp/WebCPM
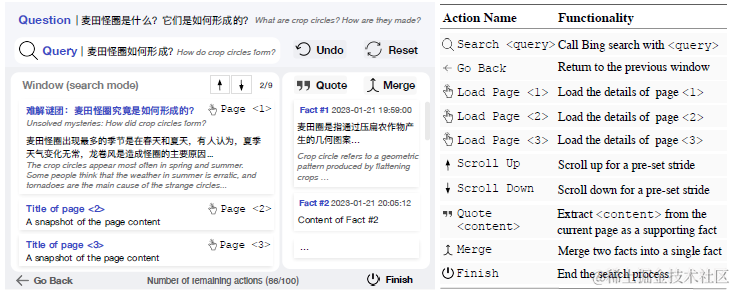
WebCPM其实是这三篇论文中最新的一篇,所以集成了webgpt和webglm的一些方案。构建了通过和搜索引擎进行多轮交互,来完成长文本开放问答(LFQA)的整体方案。它使用的搜索API是Bing。23名标注人员通过和搜索进行多轮交互,来获取回答问题所需的支撑性事实。
webCPM的问题来自Reddit上的英文QA转成中文。之所以使用Reddit而非知乎,百度知道,是因为后两者的答案往往经过很好的处理,直接搜索一轮就能获得很好的答案,降低了多轮搜索的交互难度。人工标注的搜索数据微调10B的CPM模型并在LFQA任务拿到了不错的效果。
WebCPM的整体框架就是上面提到的4个模块,下面我们来分别介绍。强烈建议和源码结合起来看,论文本身写的略简单,哈哈给读者留下了充分的想象空间。
Action:行为规划
首先是行为规划,也就是让模型学习人和搜索引擎交互生成的行为链路。webcpm针对交互式搜索问题,定义了包括搜索,页面加载,页面下滑等以下10个行为。不过个人感觉如果只从解决长文本问答出发,以下行为中的Scroll,load page等操作其实可能可以被优化掉,因为内容的遍历可以通过引入排序模块,和以上的摘要模块来筛选相关和不相关的内容,并不一定要通过Action来实现。这样可能可以进一步简化Action空间,提升效果。

针对行为序列的建模,被抽象为文本分类问题。把当前状态转化为文本表述,预测下一步Action是以上10分类中的哪一个。当前状态的描述包括以下内容
- 最初的问题:question
- 当前的搜索query:title
- 历史Action序列拼接:last_few_actions,消融实验中证明历史Action序列是最重要的,哈哈所以可能可以简化成个HMM?
- 历史全部摘要内容拼接:quotes
- 上一步的搜索界面:past_view, 上一步页面中展示所有内容的标题和摘要拼接的文本
- 当前搜索界面:text, 当前页面中展示所有内容的标题和摘要拼接的文本
- 剩余Action步骤:actions_left
以下为指令样本的构建代码,就是把以上的状态拼接作为input,把下一步Action作为Output
def make_input(self, info_dict, type="action"):context_ids = ""def convert_nothing(info):return "无" if len(info) == 0 else infocontext_ids += "问题:\n" + info_dict["question"] + "\n"context_ids += "摘要:\n" + convert_nothing(info_dict["quotes"]) + "\n"last_few_actions = ""for past_action in info_dict["past_actions"]:if past_action != []:last_few_actions += past_actioncontext_ids += "当前搜索:\n" + convert_nothing(info_dict["title"]) + "\n"context_ids += "上回界面:\n" + convert_nothing(info_dict["past_view"]) + "\n"context_ids += "当前界面:\n" + convert_nothing(info_dict["text"]) + "\n"context_ids += "剩余操作步数:" + str(info_dict["actions_left"]) + "\n"if type == "action":context_ids += "可选操作:"for idx, k in enumerate(self.action2idx):context_ids += self.action2idx[k]if idx != len(self.action2idx) - 1:context_ids += ";"context_ids += "\n"context_ids += "历史操作:" + convert_nothing(last_few_actions) + "\n"if type == "action":context_ids += "下一步操作:"elif type == "query":context_ids += "请生成新的合适的查询语句:"elif type == "abstract":context_ids += "请对当前界面内容摘取和问题相关的内容:"next_action = info_dict["next_action"]return context_ids, next_action
具体分类模型的微调就没啥好说的了。不过这里需要提一下,源码中其实给出了两种webcpm的实现方案。两种方案均开源了数据。
- Interactive方案:对应当前的行为建模,每一步执行什么行为会由Action模型预测得到,同时以下query改写,摘要等模块,也会获得之前所有执行步骤已有的上文输出,进行条件文本生成任务
- pipeline方案:整体行为链路固定依次是,query改写 -> 所有改写query搜索得到Top-K内容 -> 针对每个页面进行摘要抽取 -> 整合所有内容回答问题。 因此Pipeline方案并不需要Action模型,同时以下的摘要改写等模块,也会简化为不依赖上文的文本生成任务
这么说有些抽象,让我们用Query改写来看下以上两种方案的差异,假设用户提问:网页布局都有哪种?一般都用什么布局?
- Interactive:第一个改写query=网页布局种类, 然后搜索+摘要获得网页布局总结性的概述后,第二个query在已有摘要内容的基础上,改写query=网页布局最佳实践, 这样综合两个query的内容就可以回答上述问题
- pipeline:在最初就调用query改写模型生成一堆改写query,例如网页布局种类,网页布局技巧,网页布局模式,网页布局优势。然后全部去调用搜索引擎,再对所有返回结果进行整合。
虽然看上去Interactive似乎能得到更优解,但其实只对明显串行的搜索任务有边际增益,整体没有pipeline模式更加简洁优雅。因为pipeline模型的无条件生成,使得每一步都可以并发处理,更容易落地。并且每个模块可以独立优化,可以相互解耦。因此以下三个模块的介绍,我们都以pipeline方案来进行介绍
Search:query改写
query改写模型,是一个seq2seq的文本生成模型。其实和Self-Ask通过自我提问,来对问题进行拆解的本质相似。改写核心是为了解决两个问题
- Decompose:用户的问题由多个并联、串联的内容组合而成,因此需要对问题进行拆解,得到子query。例如Self-Ask那一章的例子,提问涨幅最高的板块成交量如何?需要拆解成涨幅最高的板块+XX板块成交量
- Rephrase:用户的问题本身不适配搜索引擎,需要改写成更加简洁,关键词更明确的搜素query。例如"微软的new bing上线了,使用体验如何?“可以改写为"new bing使用体验”
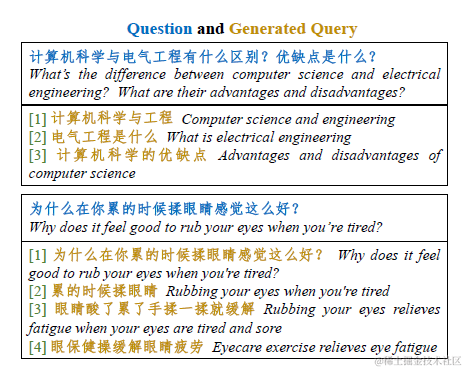
以下为webcpm微调得到的query生成模型的效果,webcpm提供了这部分训练数据,包括一个query和改写得到的多个query
Retriever:摘要抽取
Retriever负责从网页正文中,抽取和Query相关的内容,也就是一个阅读理解/抽取式摘要问题。这样就不需要依赖搜索API直接提供的snippet摘要,可以针对你的场景来设计抽取的长度,以及是整段抽取,还是抽取多个段落组合。
为了降低推理延时,webcpm通过decoder实现了类似span抽取的方案,解码器只解码应当抽取的段落的第一个字和最后一个字。例如
Query = 麦田怪圈是什么?
Content= 麦田怪圈(Crop Circle),是指在麦田或其它田地上,通过某种未知力量(大多数怪圈是人类所为)把农作物压平而产生出来的几何图案。这个神秘现象有时被人们称之为“Crop Formation”。麦田怪圈的出现给了对支持外星人存在论的人们多种看法。
假设应该抽取段落中的第一句话
Fact=麦田怪圈(Crop Circle),是指在麦田或其它田地上,通过某种未知力量(大多数怪圈是人类所为)把农作物压平而产生出来的几何图案
则模型的解码器输出的结果是起始字符:麦-结束字符:案,如果首尾两字能匹配到多端文本,则取最长能匹配到的文本段落。刨了刨代码,发现pipeline和interactive在摘要部分的样本构建方式不同,只有以下互动式的样本构建中采用了以上类span抽取的方案
abstract = "起始字符:" + self.tokenizer.decode(decoded_abstract[: num_start_end_tokens]) + "-结束字符:" + self.tokenizer.decode(decoded_abstract[-num_start_end_tokens: ])
Synthesis:信息聚合
Synthesis负责整合以上search+Retriever得到的多个Fact,拼接作为上文,通过人工标注的答案,来让模型学习如何基于多段事实生成一致,流畅,基于上文内容的长回答。
为了解决模型本身在自动检索过程中会收集到无关信息,而[1]中提到,无关的上文输入会影响推理结果的问题。Webcpm在构建基于多段上文的QA问答指令集时,在人工收集的每个query对应的多个摘要fact的基础上,会从其他样本中随机采样同等量级的无关上文,和原始的事实进行shuffle之后,拼接作为输入,来进行Query+content -> Answer的模型微调。让模型学会区分相关事实和无关事实,并在推理时不去关注无关的信息输入。
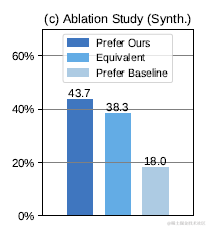
同时论文对比了加入无关Fact,和只使用相关Fact微调后的模型效果差异,如下。只使用相关内容的Baseline模型的偏好率18%显著低于,加入随机无关内容微调后的43.7%。因此加入无关上文训练,确实可以提升模型对噪声上文的判别能力。
在线教程
- 麻省理工学院人工智能视频教程 – 麻省理工人工智能课程
- 人工智能入门 – 人工智能基础学习。Peter Norvig举办的课程
- EdX 人工智能 – 此课程讲授人工智能计算机系统设计的基本概念和技术。
- 人工智能中的计划 – 计划是人工智能系统的基础部分之一。在这个课程中,你将会学习到让机器人执行一系列动作所需要的基本算法。
- 机器人人工智能 – 这个课程将会教授你实现人工智能的基本方法,包括:概率推算,计划和搜索,本地化,跟踪和控制,全部都是围绕有关机器人设计。
- 机器学习 – 有指导和无指导情况下的基本机器学习算法
- 机器学习中的神经网络 – 智能神经网络上的算法和实践经验
- 斯坦福统计学习
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓


人工智能书籍
- OpenCV(中文版).(布拉德斯基等)
- OpenCV+3计算机视觉++Python语言实现+第二版
- OpenCV3编程入门 毛星云编著
- 数字图像处理_第三版
- 人工智能:一种现代的方法
- 深度学习面试宝典
- 深度学习之PyTorch物体检测实战
- 吴恩达DeepLearning.ai中文版笔记
- 计算机视觉中的多视图几何
- PyTorch-官方推荐教程-英文版
- 《神经网络与深度学习》(邱锡鹏-20191121)
- …

第一阶段:零基础入门(3-6个月)
新手应首先通过少而精的学习,看到全景图,建立大局观。 通过完成小实验,建立信心,才能避免“从入门到放弃”的尴尬。因此,第一阶段只推荐4本最必要的书(而且这些书到了第二、三阶段也能继续用),入门以后,在后续学习中再“哪里不会补哪里”即可。

第二阶段:基础进阶(3-6个月)
熟读《机器学习算法的数学解析与Python实现》并动手实践后,你已经对机器学习有了基本的了解,不再是小白了。这时可以开始触类旁通,学习热门技术,加强实践水平。在深入学习的同时,也可以探索自己感兴趣的方向,为求职面试打好基础。

第三阶段:工作应用

这一阶段你已经不再需要引导,只需要一些推荐书目。如果你从入门时就确认了未来的工作方向,可以在第二阶段就提前阅读相关入门书籍(对应“商业落地五大方向”中的前两本),然后再“哪里不会补哪里”。
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓