额……字符串我们是第一次学,给大家铺一些基础的不能再基础的基础,
字符串比较大小
字符串大小的比较,不是以字符串的长度直接决定,而是从最左边第一个字符开始比较,大者为大,小者为小,若相等,则继续按字符串顺序比较后面的字符(比的是ASCII码)
字符串输入
cin
接受一个字符串,遇“空格”、“TAB”、“回车”都结束
cin.getline()
在一(二)维字符数组中,参数一即为字符数组名,参数二为元素个数。
cin.get()
cin.get(字符数组名,接收字符数目)用来接收一行字符串,可以接收空格。
getline()
接受一个字符串可以接受空格,遇换行结束。包含在string头文件中
getchar()
接受一个字符。包含头文件string
gets()
用法与cin.getline()一样只不过gets不带第三个参数。
OK!开始正题,来一道题吧。说一下,字符串三大杀器:Hash,KMP,AC自动机
数字串匹配1
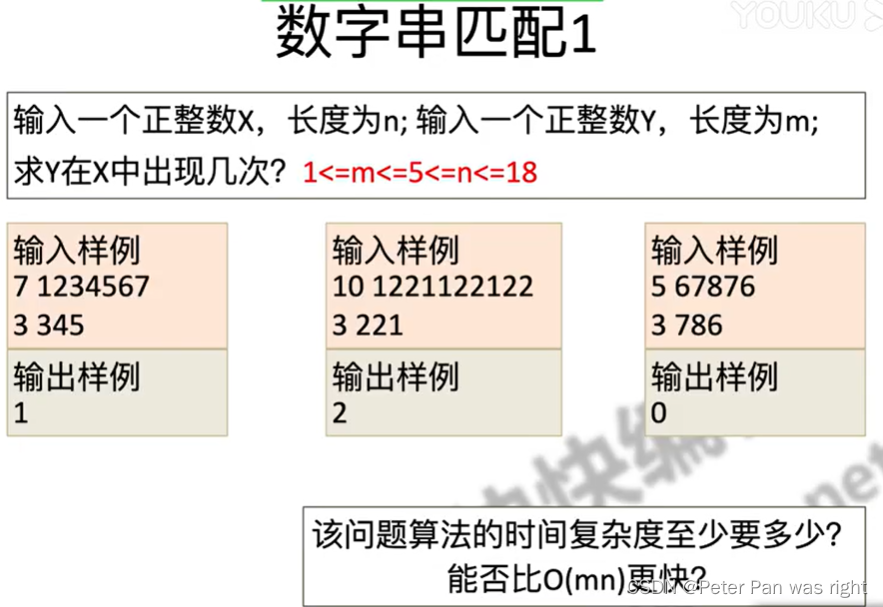
这一题比较简单,但是……也有坑哦
错误代码:
#include <bits/stdc++.h>
using namespace std;
typedef unsigned long long ull;
ull p[18]={1,1e1,1e2,1e3,1e4,1e5,1e6,1e7,1e8,1e9,1e10,1e11,1e12,1e13,1e14,1e15,1e16,1e17};
ull n,m,X,Y,cnt=0;
int main(){cin>>n>>X>>m>>Y;for(ull i=n-m;i>=0;i--)cnt+=(X/p[i]%p[m]==Y);cout<<cnt<<endl;return 0;
}关键:一定要正着循环,因为ull为无符号整数,永远没有负数,i永远>=0。
正确代码:
#include <bits/stdc++.h>
using namespace std;
typedef unsigned long long ull;
ull p[18]={1,1e1,1e2,1e3,1e4,1e5,1e6,1e7,1e8,1e9,1e10,1e11,1e12,1e13,1e14,1e15,1e16,1e17};
ull n,m,X,Y,cnt=0;
int main(){cin>>n>>X>>m>>Y;for(ull i=0;i<=n-m;i--)cnt+=(X/p[i]%p[m]==Y);cout<<cnt<<endl;return 0;
}那么为什么这样一定对呢?
请看下图👇
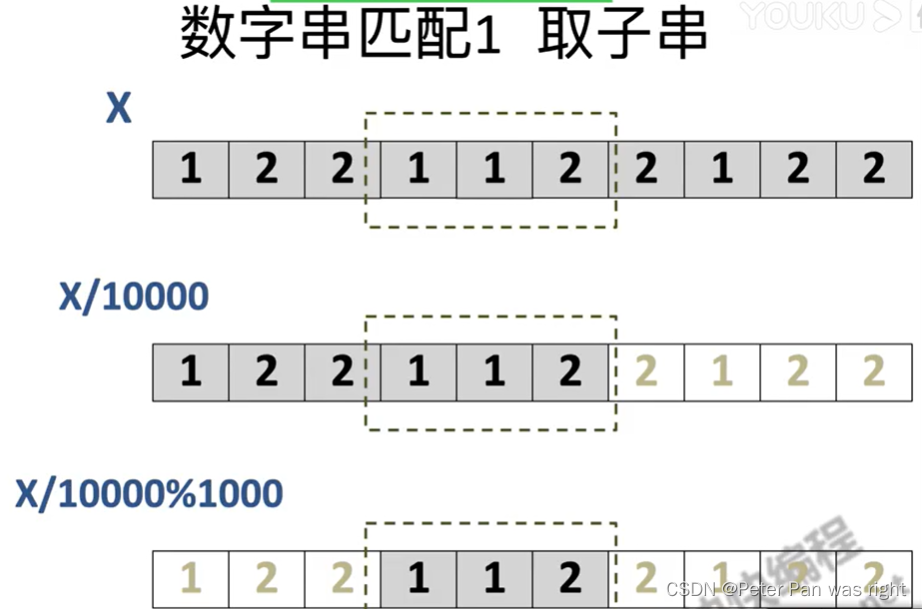
这样懂了吧,这是暴力算法,来看下一题
数字串匹配2

取子串这下子usigned long long已经不够了,可能要……long long long long long long long long!我们每次都要取一个字串,那么现在的问题就是:如何取子串且复杂度低低低低低。
给一幅图,立马懂,不懂我倒立洗头
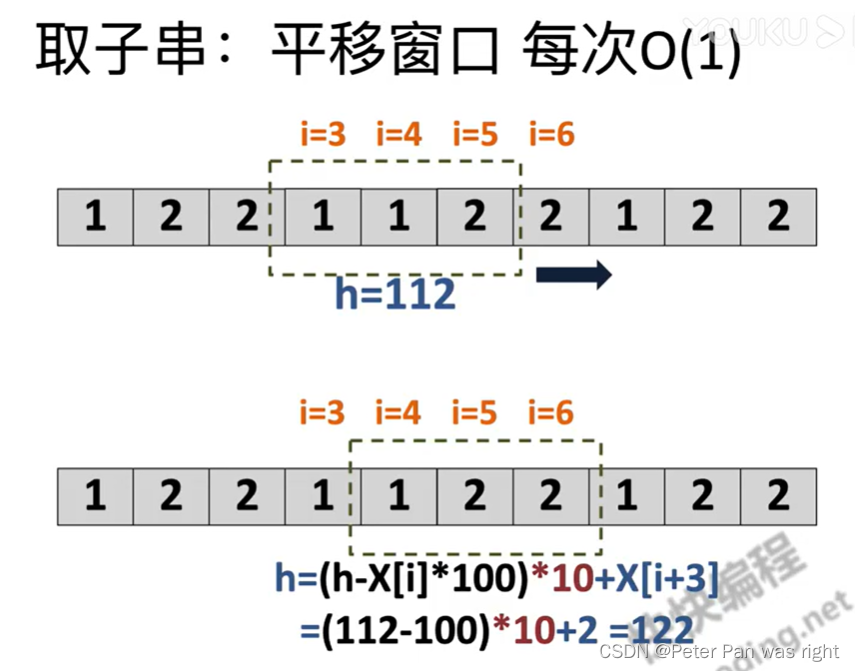
h表示取出来的字串。上图是如何平移窗口,数学知识:位置原理。懂了吗?比较简单。
Hash

那么,哈希的目的是什么:将一个字符串变成一个整数。如果哈希值相等,那么两个字符串就相等。那为什么我们要选一个质数呢?因为防止哈希碰撞。什么是哈希碰撞呢?因为有可能有两个不同的字符串,他们的哈希值相同,我们要避免它。讲了半天,代码呢?
#include <bits/stdc++.h>
#define BASE 131
using namespace std;
typedef unsigned long long ull;
int main(){string s;cin>>s;for(ull i=0;i<s.size();i++)hash=hash*BASE+s[i];cout<<hash<<endl;return 0;
}这就是传说中的“哈希值”!!!提醒一下大家:大家光看这些内容可能很枯燥,建议加上《信息学奥赛一本通—提高篇》食用更佳。
平移窗口
cin>>n>>X>>m>>Y;
ull p[M]={1};
for(ull i=1;i<=m;i++) p[i]=p[i-1]*BASE;
ull hx=0,hy=0;
for(ull i=0;i<m;i++)hx=hx*BASE+X[i],hy=hy*BASE+Y[i];
ull cnt=(hx==hy);
for(ull i=m;i<n;i++){hx=(hx-X[i-m]*p[m-1])*BASE;cnt+=(hx==hy);
}
cout<<cnt<<endl;前缀哈希
主要是前缀和
ull p[M]={1},n,m,hx[N];
cin>>n>>X>>m>>Y;
for(ull i=1;i<=m;i++) p[i]=p[i-1]*BASE;
ull hY=0;
for(ull i=0;i<m;i++)hY=hY*BASE+Y[i];
hX[0]=0;
for(ull i=0;i<m;i++)hX=hX[i-1]*BASE+X[i];
ull cnt=0;
for(ull i=0;i<=n-m;i++){ull hash=hX[i+m]-hX[i]*p[m];cnt+=(hash==hy);
}
cout<<cnt<<endl;拓展:哈希冲突
哈希冲突指有两个不同的字符串,它们的hash指相等。下面的数学讨论请大家选择阅读。
计算哈希冲突的概率
问题可以抽象成这样:给K个随机值,非负而且小于N,他们中至少有个相等的概率是多少?
我们考虑它的反面问题:不相同的概率。对于一个值域为N的Hash值,假设你已经挑选出一个值。之后,剩下N-1个值是不同于第一个值的,因此,对于第二次随机生成不同第一个数的概率为
同理,不相等的概率就是 。好的是,这个值约等于
。好的是,这个值约等于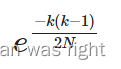 ,好奇的话可以用泰勒公式试一下。那么,原来的问题的概率就是
,好奇的话可以用泰勒公式试一下。那么,原来的问题的概率就是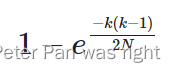 。当然,我们可以把表达式简化一下。
。当然,我们可以把表达式简化一下。
表达式简化
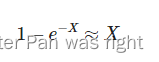 这是一个极限的算式,这个式子当X很小时,误差越小,大家自己推导着试试。那么简化表达式就变成
这是一个极限的算式,这个式子当X很小时,误差越小,大家自己推导着试试。那么简化表达式就变成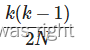 这样,我们就把哈希冲突的概率计算出来了,大家学废了吗?
这样,我们就把哈希冲突的概率计算出来了,大家学废了吗?