目录
一、架构及组件介绍
1.1 Hive底层架构
1.2 Hive组件
1.3 Hive与Hadoop交互过程
二、Hive SQL 编译成MR任务的流程
2.1 HQL转换为MR源码整体流程介绍
2.2 程序入口—CliDriver
2.3 HQL编译成MR任务的详细过程—Driver
2.3.1 将HQL语句转换成AST抽象语法树
词法、语法解析
2.3.2 将AST转换成TaskTree
语义解析
生成逻辑执行计划
优化逻辑执行计划
生成物理执行计划
HQL编译成MapReduce具体原理
JOIN
GROUP BY
DISTINCT
优化物理执行计划
2.3.3 提交任务并执行
一、架构及组件介绍
1) Hive简介
- Hive是Facebook实现的一个开源的数据仓库工具。
- 将结构化的数据文件映射为数据库表,并提供HQL查询功能,将HQL语句转化为MapReduce任务运行
2) Hive本质:将 HQL 转化成 MapReduce 程序
- Hive 处理的数据存储在 HDFS
- Hive 分析数据底层的实现是 MapReduce
- 执行程序运行在 Yarn 上
1.1 Hive底层架构

1.2 Hive组件
- 用户接口:Client
- CLI:shell命令行
- JDBC/ODBC:Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议
- WEBUI:通过浏览器访问Hive
- 元数据:Metastore
- Hadoop
- 驱动器:Driver
- 解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第 三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL 语义是否有误。
- 编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
- 优化器(Query Optimizer):对逻辑执行计划进行优化。
- 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。当下Hive支持MapReduce、Tez、Spark3种执行引擎
Driver驱动器总结:完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,随后执行引擎调用执行。当下Hive支持MapReduce、Tez、Spark3种执行引擎。
1.3 Hive与Hadoop交互过程
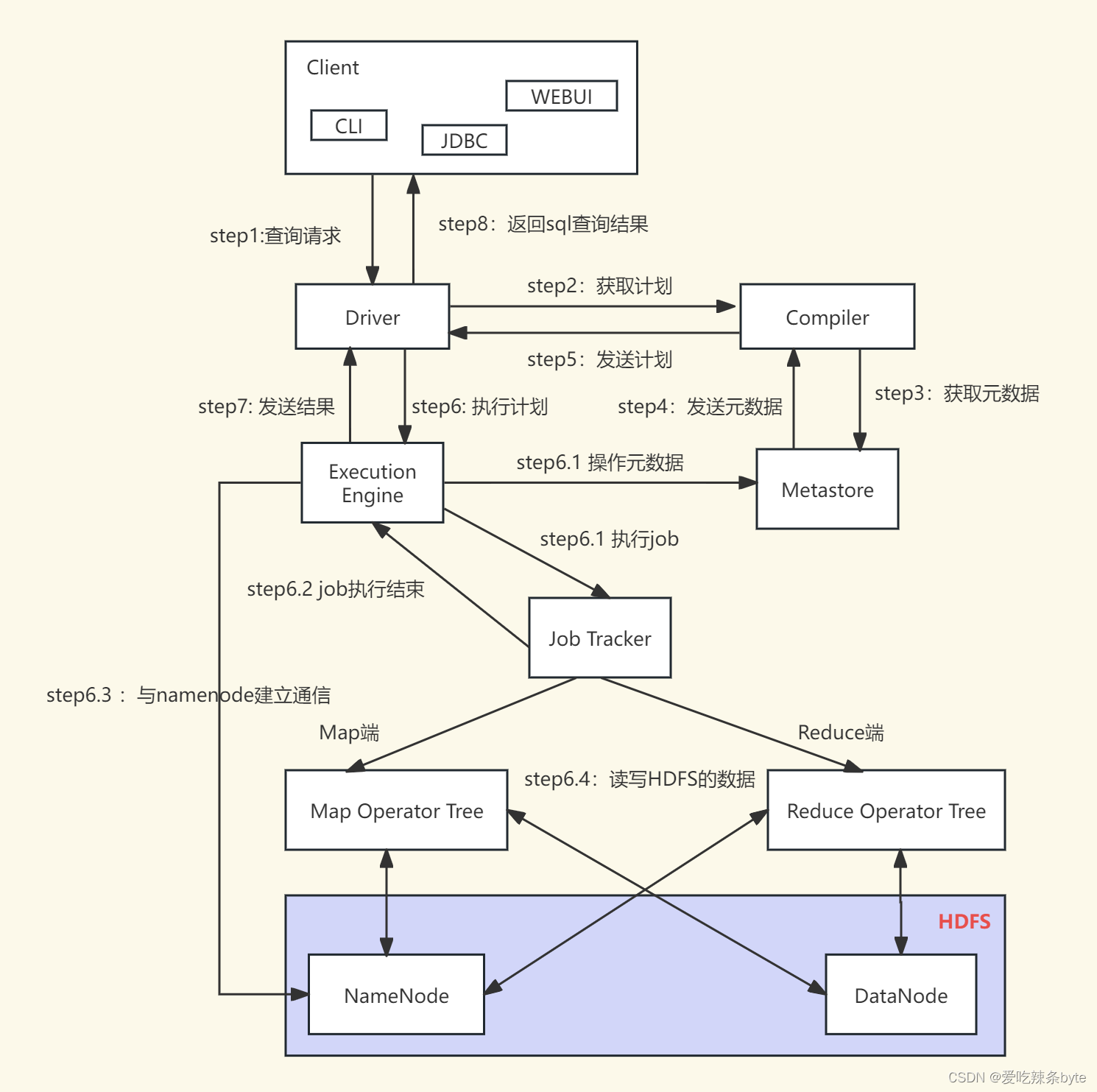
上图的基本流程是:
- 步骤1:Client 客户端调用 Driver的接口;
- 步骤2:Driver驱动器为查询创建会话句柄,并将查询发送到 Compiler(编译器组件)生成执行计划;
- 步骤3和4:编译器从元数据存储库中获取本次查询所需要的元数据;
- 步骤5:编译器生成各个阶段Stage的执行计划,如果是一个MR任务,该执行计划分为两部分:Map Operator Tree(map端的执行计划树)和Reduce Operator Tree(reduce端的执行计划树),再将生成的逻辑执行计划发给Driver;
- 步骤6:Driver将逻辑执行计划发给执行引擎Execution Engine;(将逻辑执行计划转化成具体的物理执行计划,即mr任务)
步骤6.1 / 6.2 /6.3 /6.4:执行引擎将这些阶段Stage的具体执行内容提交给对应的组件。在每个 Task(mapper/reducer) 任务中,从HDFS文件中读取与表相关的数据,并通过算子树依次传递。最终的数据集借助序列化器写入到临时的HDFS文件中。
- 步骤7、8:临时HDFS文件的内容由执行引擎读取后,通过Driver将查询结果发送给Client 客户端
简化版本:
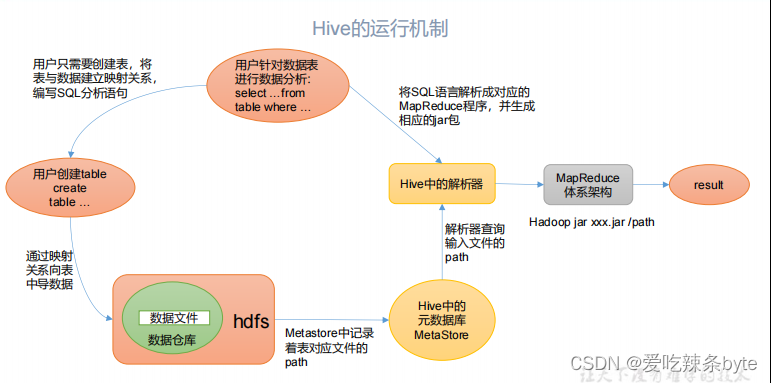
总结:Hive通过给用户提供的一系列交互接口,接收到用户的指令(sql),使用自己的driver,结合元数据(metastore),将这些指令翻译成 mapreduce任务,提交到hadoop中执行,最后将执行返回的结果输出到用户交互接口。
二、Hive SQL 编译成MR任务的流程
2.1 HQL转换为MR源码整体流程介绍

2.2 程序入口—CliDriver
我们执行一个 HQL 语句通常有以下几种方式:
- $HIVE_HOME/bin/hive进入客户端,然后执行HQL;
- $HIVE_HOME/bin/hive -e “hql”;
- $HIVE_HOME/bin/hive -fhive.sql;
- 先开启hivesever2服务端,然后通过JDBC方式连接远程提交HQL。
可以知道我们执行 HQL 主要依赖于 $HIVE_HOME/bin/hive 和 $HIVE_HOME/bin/而在这两个脚本中,最终启动的 JAVA 程序的主类为“ org.apache.hadoop.hive.cli.CliDriver ” ,所以其实 Hive程序的入口就是“CliDriver ”这个类。
2.3 HQL编译成MR任务的详细过程—Driver

2.3.1 将HQL语句转换成AST抽象语法树
-
词法、语法解析
Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将 SQL 转化为抽象语法树 AST Tree;
例如:AST如下图:
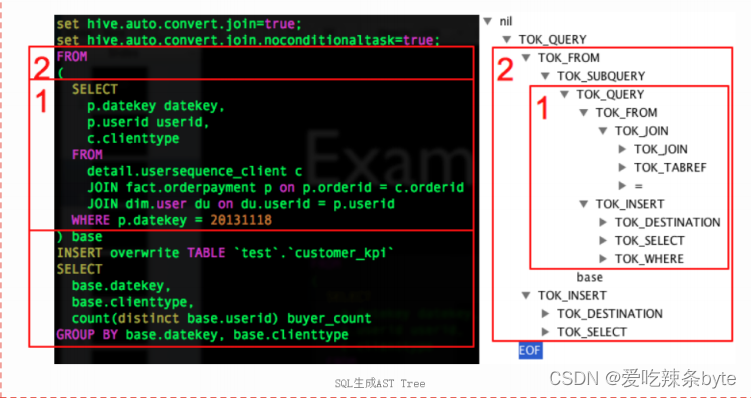
2.3.2 将AST转换成TaskTree
-
语义解析
遍历 AST Tree,抽象出一条SQL最基本组成单元 QueryBlock(查询块),该块包括三个部分:输入源,计算过程,输出。简单而言一个QueryBlock就是一个子查询。
-
生成逻辑执行计划
遍历 QueryBlock,翻译为执行操作树 OperatorTree(操作树,也就是逻辑执行计划);Hive最终生成的MapReduce任务,Map阶段和Reduce阶段均由OperatorTree组成。
基本的操作符包括:
- TableScanOperator
SelectOperator
FilterOperator
JoinOperator
GroupByOperator
ReduceSinkOperator
Operator操作算子在Map Reduce阶段之间的数据传递是一个流式的过程。每一个Operator对一行数据操作之后将数据传递给childOperator计算。
由于Join/GroupBy需要在Reduce阶段完成,所以在生成相应操作的Operator之前都会先生成一个ReduceSinkOperator,将字段组合并序列化为Reduce KeyReduce /value, Partition Key。
-
优化逻辑执行计划
逻辑优化器对OperatorTree(操作树)进行逻辑优化。例如合并不必要的ReduceSinkOperator,减少数据传输及 shuffle 数据量;
Hive中的逻辑查询优化可以大致分为以下几类:
投影修剪
谓词下推
多路 Join
-
生成物理执行计划
遍历 OperatorTree,转换成TaskTree(任务树,即物理执行计划)即MR任务。生成物理执行计划即是将逻辑执行计划生成的OperatorTree转化为MapReduce Job的过程。
HQL编译成MapReduce具体原理
(1) hive.fetch.task.conversion参数
在Hive中,有些简单任务既可以转化为MR任务,也可以Fetch本地抓取,即直接读取table对应的hdfs存储目录下文件得到结果,通过
hive.fetch.task.conversion参数配置。默认情况使用参数more,例如:SELECT、FILTER、LIMIT等简单查找都使用Fetch本地抓取,而其他复杂sql转为MR任务。
(2)转化为MR任务的SQL
需要转换成MR任务的sql通常会涉及到key值的shuffle,例如:join、groupby、distinct等,接下来介绍此三种情况的sql转化。
-
JOIN
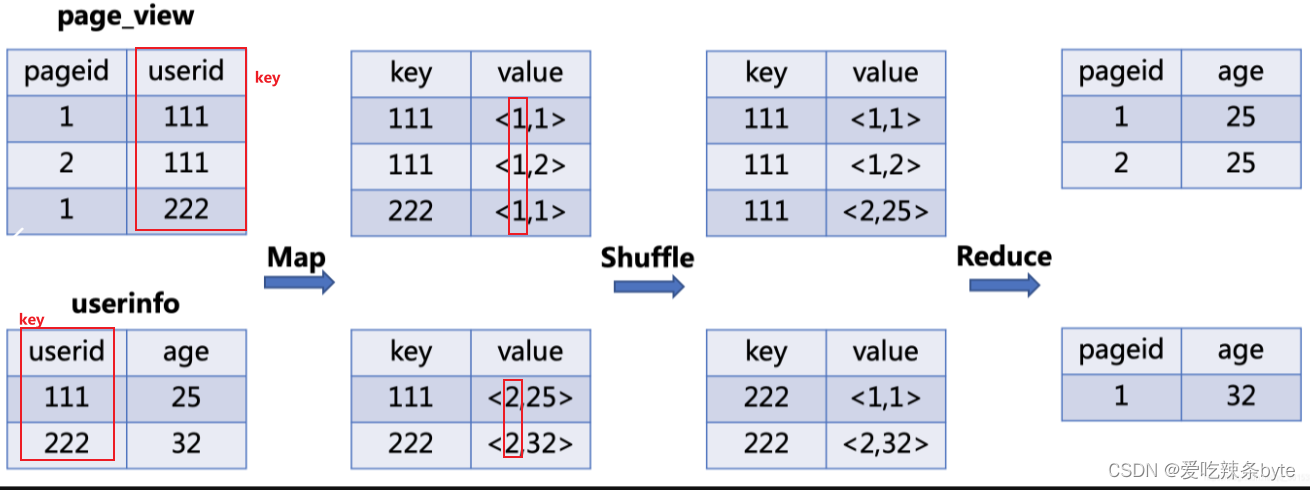
JOIN任务转化为MR任务的流程如下:
- Map: 生成键值对,以join on 条件中的列作为key,以join之后所关心的列作为value值,在value中还会包含表的Tag信息,用于标明此value对应哪张表
- Shuffle: 根据key值进行hash分区, 按照hash值将键值对(key-value)发送到不同的reducer中
- Reduce:Reducer通过Tag来识别不同的表中的数据,根据key值进行join操作
以下列sql为例:
SELECT pageid, age
FROM page_view
JOIN userinfo
ON page_view.userid = userinfo.userid;
sql转化为mr任务流程如下图:
-
GROUP BY
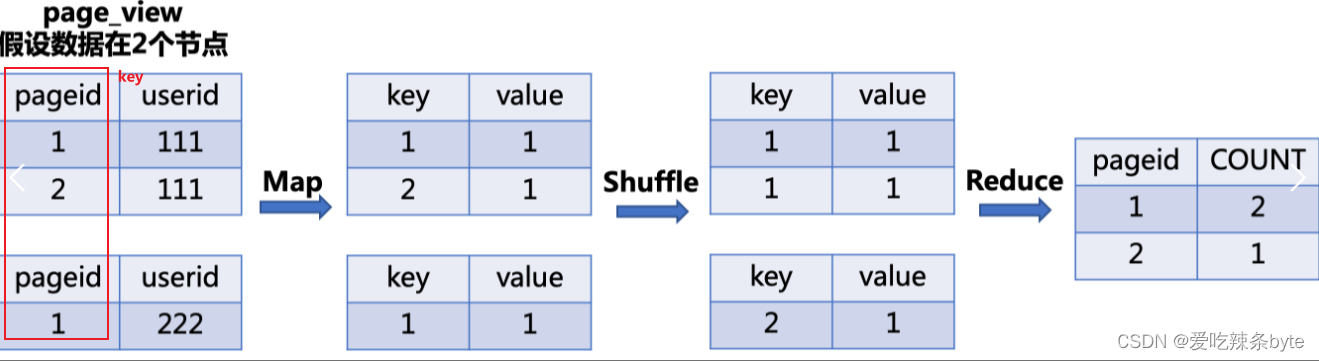
GROUP BY任务转化为MR任务的流程如下:
- Map: 生成键值对,以
GROUP BY条件中的列作为key,以聚集函数的结果作为value- Shuffle: 根据key值进行hash分区, 按照hash值将键值对(key-value)发送到不同的reducer中
- Reduce:根据
SELECT子句的列以及聚集函数进行Reduce
以下列sql为例:
SELECT pageid,COUNT(1) as num
FROM page_view
GROUP BY pageid;
sql转化为mr任务流程如下图:
-
DISTINCT
与GROUP BY操作相同,只是键值对中的value可为空。
以下列sql为例:
SELECT DISTINCT pageid FROM page_view;待补充~
-
优化物理执行计划
物理优化器对进行TaskTree(任务树,即物理执行计划)进行物理优化;
Hive中的物理优化可以大致分为以下几类:
分区修剪(Partition Pruning)
基于分区和桶的扫描修剪(Scan pruning)
在某些情况下,在 mapper端进行 Group By分组的预聚合
在 mapper端执行Join(map join)
如果是简单的select查询,可以设置为本地执行,避免使用MapReduce作业
经过2.3.1 及2.3.2 这六个阶段,HQL就被解析映射成了集群上的 MR任务。
2.3.3 提交任务并执行
- 获取MR临时工作目录
- 定义Partitioner
- 定义Mapper和Reducer
- 实例化Job任务
- 提交Job任务并执行