目录
倒排索引
倒排索引
Elasticsearch的倒排索引是一种数据结构,用于加快基于文本的搜索操作。它的主要优势在于能够快速找到包含特定单词的文档。
倒排索引的构建过程如下:
-
文档分词:将文档内容分割成单独的词(或者更小的词元,如果是中文的话是分词)。
-
创建词典:创建一个包含所有不重复词的列表,也称为词典。
-
创建排序列表:对于词典中的每个词,创建一个排序列表,列出所有包含该词的文档ID。
倒排索引的理解可以通过以下例子来说明:
假设我们有两个文档,每个文档的内容如下:
文档1: "The quick brown fox jumped over the lazy dog."
文档2: "Quick brown foxes leap over lazy dogs in summer."
我们将这些文档发送给Elasticsearch进行索引,它将创建一个倒排索引,如下所示:
词典(terms):
-
Term Doc_1 Doc_2 ------------------------- Quick | | X The | X | brown | X | X dog | X | dogs | | X fox | X | foxes | | X in | | X jumped | X | lazy | X | X leap | | X over | X | X quick | X | summer | | X the | X | ------------------------
排序列表(postings list):
Term Doc_1 Doc_2 ------------------------- brown | X | X dog | X | X fox | X | X in | | X jump | X | X lazy | X | X over | X | X quick | X | X summer | | X the | X | X ------------------------
排序列表(倒排列表)通常包含以下信息:
-
文档ID:包含词的文档的唯一标识符。
-
词频(TF):文档中词出现的次数。
-
位置(Position):词在文档中的位置信息。
-
偏移量(Offset):词在文档中的开始和结束位置。
现在,如果我们想搜索 quick brown ,我们只需要查找包含每个词条的文档:
Term Doc_1 Doc_2 ------------------------- brown | X | X quick | X | ------------------------ Total | 2 | 1
两个文档都匹配,但是第一个文档比第二个匹配度更高。
这就是Elasticsearch倒排索引的基本概念。
分片与副本机制
Elasticsearch 的分片和副本机制是确保集群高可用性和数据安全性的关键。
分片(Shard):
分片是Elasticsearch在集群中分发数据的方式。将大量数据分散到多个分片中,可以提高搜索和其他操作的性能。
副本(Replica):
副本是分片的副本,用于提供高可用性。当主分片(Leader)不可用时,副本分片(Follower)可以被提升为新的主分片。
创建索引时,可以定义分片数和副本数。例如,使用Elasticsearch的REST API创建一个有3个主分片和每个分片有一个副本的索引:
PUT /my_index
{"settings": {"number_of_shards": 3,"number_of_replicas": 1}
}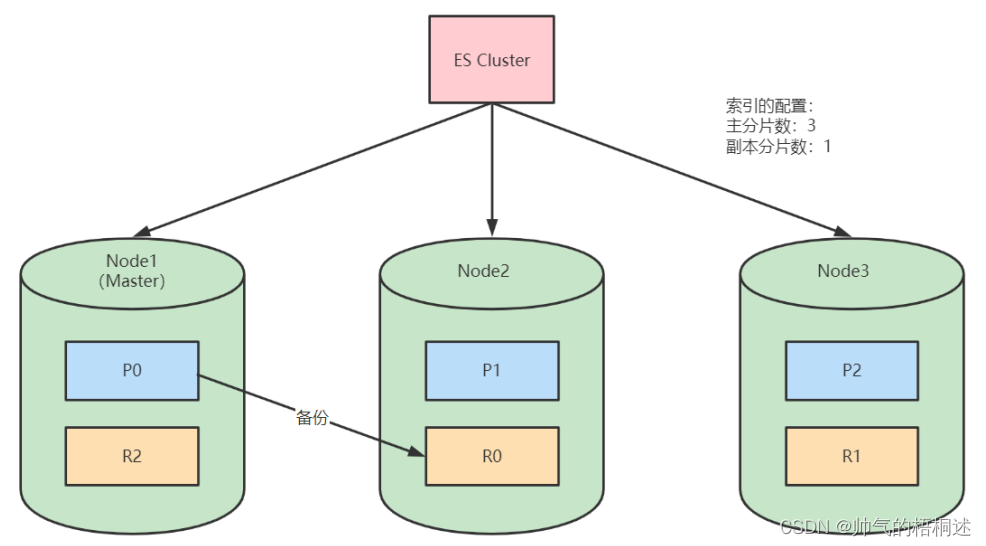 R0、R1、R2为P0、P1、P2的备份副本。
R0、R1、R2为P0、P1、P2的备份副本。
ElasticSearch各版本特性
5.x新特性
- Lucene 6.x, 性能提升,默认打分机制从TF-IDF改为BM 25
- 支持Ingest节点/ Painless Scripting / Completion suggested支持/原生的Java REST客户端Type标记成deprecated, 支持了Keyword的类型
- 性能优化
- 内部引擎移除了避免同一文档并发更新的竞争锁,带来15% - 20%的性能提升
- Instant aggregation,支持分片,上聚合的缓存
- 新增了Profile API
6.x新特性
- Lucene 7.x
- 新功能
- 跨集群复制(CCR)
- 索引生命周期管理
- SQL的支持
- 更友好的的升级及数据迁移
- 在主要版本之间的迁移更为简化,体验升级
- 全新的基于操作的数据复制框架,可加快恢复数据
- 性能优化
- 有效存储稀疏字段的新方法,降低了存储成本
- 在索引时进行排序,可加快排序的查询性能
7.x新特性
- Lucene 8.0
- 重大改进-正式废除单个索引下多Type的支持
- 7.1开始,Security 功能免费使用
- ECK - Elasticseach Operator on Kubernetes
- 新功能
- New Cluster coordination
- Feature——Complete High Level REST Client
- Script Score Query
- 性能优化
- 默认的Primary Shard数从5改为1,避免Over Sharding
- 性能优化, 更快的Top K
8.x新特性
- Rest API相比较7.x而言做了比较大的改动(比如彻底删除_type)
- 默认开启安全配置
- 存储空间优化:对倒排文件使用新的编码集,对于keyword、match_only_text、 text类型字段有效,有3.5%的空间优化提升,对于新建索引和segment自动生效。
- 优化geo_point,geo_shape类型的索引(写入)效率:15%的提升。
- 技术预览版KNN API发布,(K邻近算法),跟推荐系统、自然语言排名相关。

![[计算机网络]---序列化和反序列化](https://img-blog.csdnimg.cn/direct/fd55247bf7494a819f098bbc3cfa6708.png)