首先淘宝需要登录,这一点如果用selenium如何解决,只能手动登录?如果不用selenium,用cookies登录也可。但是验证码又是一个问题,现在的验证码五花八门,难以处理。
我们回到正题,假设你已经登录上淘宝了,接着我们需要找到输入框和搜索按钮,输入“手机”,点击搜索即可,如何找到对应的元素呢?
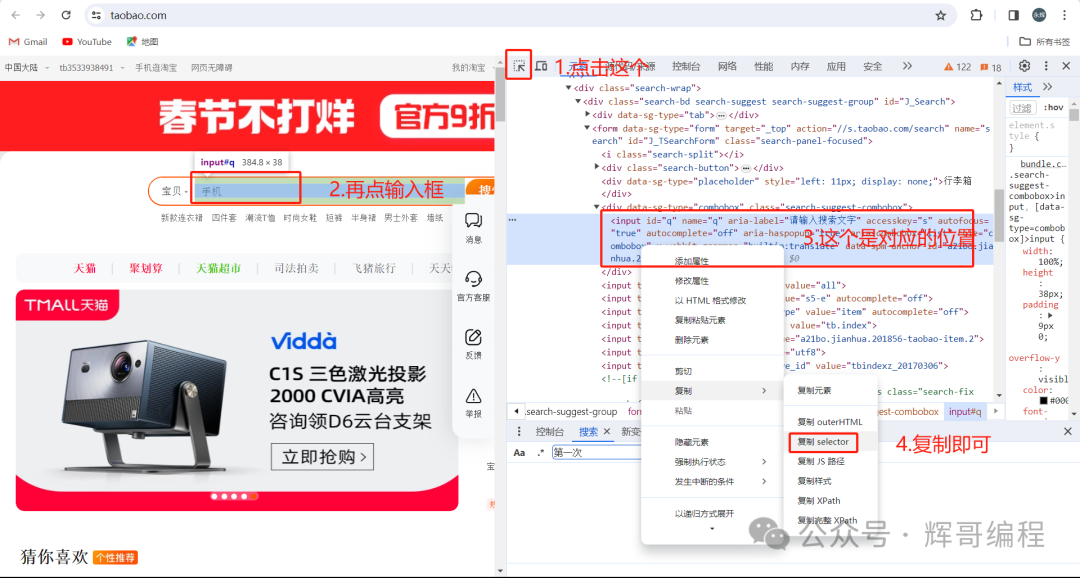
接着来到搜索得到的页面,首先找到父类容器的位置。
items = doc('div.PageContent--contentWrap--mep7AEm > div.LeftLay--leftWrap--xBQipVc > div.LeftLay--leftContent--AMmPNfB > div.Content--content--sgSCZ12 > div > div').items()
这行代码是使用Python的pyquery库来解析HTML并提取特定元素。代码是在doc(一个pyquery对象)中查找符合特定CSS选择器的元素。
这个CSS选择器匹配一个具有特定类名的div元素,该元素是另一个具有特定类名的div元素的直接子元素,以此类推。>符号表示“直接子元素”。
.items()方法是获取所有匹配的元素,并返回一个生成器,可以用于迭代每个匹配的元素。
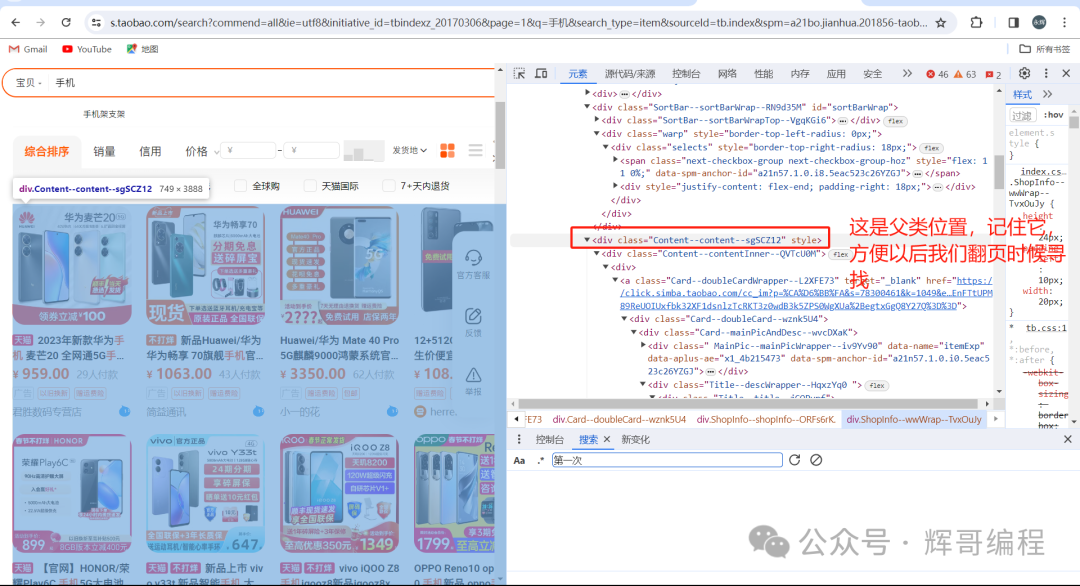
接着运用找输入框和搜索按钮的方法找到你想要爬取内容的位置,下面展示其中一个的例子

title = item.find('.Title--title--jCOPvpf span').text()
这行代码是使用Python的BeautifulSoup库来解析HTML并提取特定元素的文本内容。
item.find(‘.Title–title–jCOPvpf span’)是在item(一个BeautifulSoup对象)中查找具有类名Title–title–jCOPvpf的元素,并且这个元素下的span子元素。
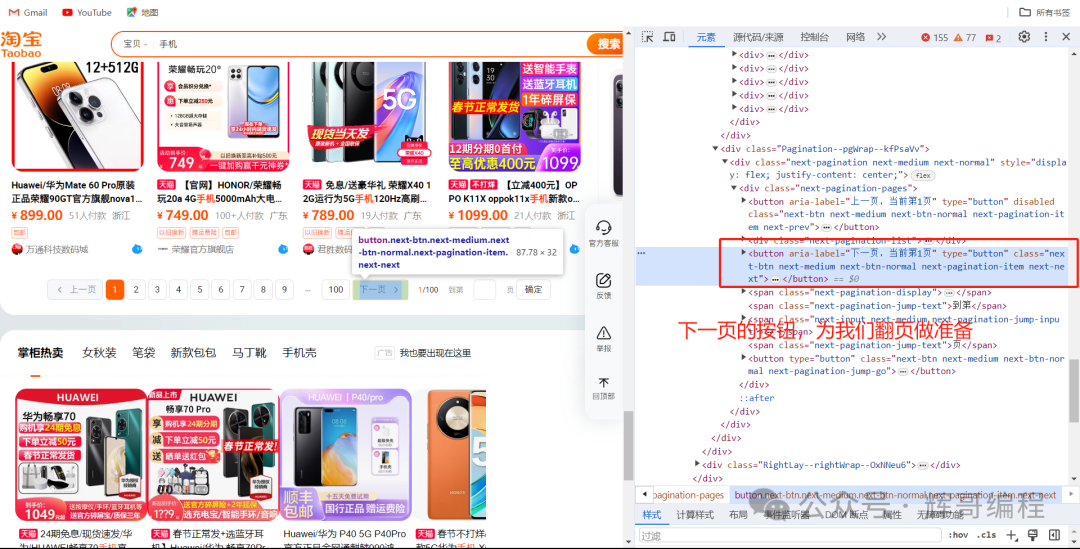
接着找到下一页的按钮,完成翻页的操作!
最后创建数据库,将数据插入即可。
# 删除同名的旧表
drop_table_sql = "DROP TABLE IF EXISTS {}".format(MYSQL_TABLE)
cursor.execute(drop_table_sql)# 创建新表的SQL语句
create_table_sql = """
CREATE TABLE {} (price VARCHAR(255),deal VARCHAR(255),title VARCHAR(255),shop VARCHAR(255),location VARCHAR(255),postFree VARCHAR(255)
)
""".format(MYSQL_TABLE)# 执行SQL语句
cursor.execute(create_table_sql)
最后的结果如下(使用Navicat Premium可视化):
这次共爬取4800件商品。
完整代码如下所示:
import pymysql
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pyquery import PyQuery as pq
import time
import random# 要搜索的商品的关键词
KEYWORD = '手机'
# 数据库中要插入的表
MYSQL_TABLE = 'phone'# MySQL 数据库连接配置,根据自己的本地数据库修改
db_config = {'host': 'localhost','port': 3306,'user': 'root','password': '123456','database': 'myh','charset': 'utf8mb4',
}# 创建 MySQL 连接对象
conn = pymysql.connect(**db_config)
cursor = conn.cursor()# 删除同名的旧表(如果存在)
drop_table_sql = "DROP TABLE IF EXISTS {}".format(MYSQL_TABLE)
cursor.execute(drop_table_sql)# 创建新表的SQL语句
create_table_sql = """
CREATE TABLE {} (price VARCHAR(255),deal VARCHAR(255),title VARCHAR(255),shop VARCHAR(255),location VARCHAR(255),postFree VARCHAR(255)
)
""".format(MYSQL_TABLE)# 执行SQL语句
cursor.execute(create_table_sql)# 提交事务
conn.commit()options = webdriver.ChromeOptions()
# 关闭自动测试状态显示 // 会导致浏览器报:请停用开发者模式
options.add_experimental_option("excludeSwitches", ['enable-automation'])# 把chrome设为selenium驱动的浏览器代理;
driver = webdriver.Chrome(options=options)
# 窗口最大化
driver.maximize_window()# wait是Selenium中的一个等待类,用于在特定条件满足之前等待一定的时间(这里是15秒)。
# 如果一直到等待时间都没满足则会捕获TimeoutException异常
wait = WebDriverWait(driver, 15)# 打开页面后会强制停止10秒,请在此时手动扫码登陆
def search_goods(start_page, total_pages):print('正在搜索: ')try:driver.get('https://www.taobao.com')# 强制停止10秒,请在此时手动扫码登陆time.sleep(10)driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument",{"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""})# 找到搜索输入框input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))# 找到“搜索”按钮submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button')))input.send_keys(KEYWORD)submit.click()# 搜索商品后会再强制停止10秒,如有滑块请手动操作time.sleep(10)# 如果不是从第一页开始爬取,就滑动到底部输入页面然后跳转if start_page != 1 :# 滑动到页面底端driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")# 滑动到底部后停留1-3srandom_sleep(1, 3)# 找到输入页面的表单pageInput = wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[4]/div/div/span[3]/input')))pageInput.send_keys(start_page)# 找到页面跳转的确定按钮,并且点击admit = wait.until(EC.element_to_be_clickable((By.XPATH,'//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[4]/div/div/button[3]')))admit.click()get_goods()for i in range(start_page + 1, start_page + total_pages):page_turning(i)except TimeoutException:print("search_goods: error")return search_goods()
# 进行翻页处理
def page_turning(page_number):print('正在翻页: ', page_number)try:# 找到下一页的按钮submit = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="sortBarWrap"]/div[1]/div[2]/div[2]/div[8]/div/button[2]')))submit.click()# 判断页数是否相等wait.until(EC.text_to_be_present_in_element((By.XPATH, '//*[@id="sortBarWrap"]/div[1]/div[2]/div[2]/div[8]/div/span/em'), str(page_number)))get_goods()except TimeoutException:page_turning(page_number)
#获取每一页的商品信息;
def get_goods():# 获取商品前固定等待2-4秒random_sleep(2, 4)html = driver.page_sourcedoc = pq(html)# 提取所有商品的共同父元素的类选择器items = doc('div.PageContent--contentWrap--mep7AEm > div.LeftLay--leftWrap--xBQipVc > div.LeftLay--leftContent--AMmPNfB > div.Content--content--sgSCZ12 > div > div').items()for item in items:# 定位商品标题title = item.find('.Title--title--jCOPvpf span').text()# 定位价格price_int = item.find('.Price--priceInt--ZlsSi_M').text()price_float = item.find('.Price--priceFloat--h2RR0RK').text()if price_int and price_float:price = float(f"{price_int}{price_float}")else:price = 0.0# 定位交易量deal = item.find('.Price--realSales--FhTZc7U').text()# 定位所在地信息location = item.find('.Price--procity--_7Vt3mX').text()# 定位店名shop = item.find('.ShopInfo--TextAndPic--yH0AZfx a').text()# 定位包邮的位置postText = item.find('.SalesPoint--subIconWrapper--s6vanNY span').text()result = 1 if "包邮" in postText else 0# 构建商品信息字典product = {'title': title,'price': price,'deal': deal,'location': location,'shop': shop,'isPostFree': result}save_to_mysql(product)
# 在 save_to_mysql 函数中保存数据到 MySQL
def save_to_mysql(result):try:sql = "INSERT INTO {} (price, deal, title, shop, location, postFree) VALUES (%s, %s, %s, %s, %s, %s)".format(MYSQL_TABLE)print("sql语句为: " + sql)cursor.execute(sql, (result['price'], result['deal'], result['title'], result['shop'], result['location'], result['isPostFree']))conn.commit()print('存储到MySQL成功: ', result)except Exception as e:print('存储到MYsql出错: ', result, e)
# 强制等待的方法,在timeS到timeE的时间之间随机等待
def random_sleep(timeS, timeE):# 生成一个S到E之间的随机等待时间random_sleep_time = random.uniform(timeS, timeE)time.sleep(random_sleep_time)
# 在 main 函数开始时连接数据库
def main():try:pageStart = int(input("输入您想开始爬取的页面数: "))pageAll = int(input("输入您想爬取的总页面数: "))search_goods(pageStart, pageAll)except Exception as e:print('main函数报错: ', e)finally:cursor.close()conn.close()#启动爬虫
if __name__ == '__main__':main()
请大家关注一下我的公众号。