Python二级考试笔记【源源老师】
01. 字符串
1. 常规功能合集
字符串本身有一些功能,有些之前运用过,这里总结如下:
# 功能一:判断字符串类型
print(type("Hello"))
print(str(123)) # 转换# 功能二:连接字符段片段
a = "hello"
b = "python!"
print(a + b) # 没有空格
print(a, b) # 包含一个空格 # 功能三:重复字符
c = "^_^"
print(c * 3) #结果: ^_^^_^^_^2. 字符串特性
# 将字符串理解为列表,可以使用切片,循环等功能
# 【但是注意】:列表中的方法和工具不一定都能用d = "abcdefghijklmn"
print(d[2:8]) #cdefgh
print(d[2:8:2]) #ceg
print(len(d)) #14
for i in d:print(i, end="|") #a|b|c|d|e|f|g|h|i|j|k|l|m|n|
3. 格式化数据
之前已经学习过%d、%f、%s等格式化输出的方式:
name = "小明"
age = 3.33
weight = 1.23456
print("我的名字叫%s,今年%d岁了,身高%.2f米"%(name, age, weight)) #我的名字叫小明,今年3岁了,身高1.23米
4. 字符串常用方法
| 方法名 | 返回值说明 |
|---|---|
| .replace(s1, s2) | 将字符串中的s1替换成s2后生成新的字符串 |
| str.split(s) | 通过字符串 s 来分割字符串,分割后形成一个字符串列表 |
| s.join(str) | 将字符串中的元素以指定字符s连接生成新的字符串 |
| .lower() | 将字符串全部转换为小写 |
| .upper() | 将字符串全部转换为大写 |
| .find(s) | 判断是否包含子字符串,存在返回下标索引,不存在返回-1 |
| .index(s) | 判断是否包含子字符串,存在返回下标索引,不存在直接报错 |
| .count(s) | 统计子字符串出现的次数 |
| .format() | 格式化匹配字符串 |
# replace替换
a = 'Hello Jack'
b = a.replace('Jack', 'Mike')
print(a) # Hello Jack
print(b) # Hello Mike# split切割
a = 'Hello, Jack'
b = a.split(',')
print(a) # Hello, Jack
print(b) # ['Hello', ' Jack']# join连接
a = 'Hello'
b = '-'.join(a)
print(a) # Hello
print(b) # H-e-l-l-o# upper、lower大小写转换
a = 'Hello'
b = a.upper()
c = a.lower()
print(a) # Hello
print(b) # HELLO
print(c) # hello# find查找
a = 'Happy'
b = a.find('p')
c = a.find('q')
print(b) # 2 【有多个相同的p字符串默认返回第一个的索引】
print(c) # -1# index查找
a = 'Happy'
b = a.index('p')
print(b) # 2
c = a.index('q') # 报错# count计数
a = 'Happy'
b = a.count('p')
c = a.count('p',3) #【有第二个参数,则表示从这个位置开始往后查找计数】
print(b) # 2
print(c) # 1 # format格式化匹配字符串
s = '{} is a {}'.format('Mike', 'boy')
print(s) # Mike is a boya = 'Mike'
b = 'boy'
s = '{0} is a {1}'.format(a,b) #通过索引匹配
print(s) # Mike is a boys = '{name} is a {sex}'.format(name='Mike',sex='boy') #通过参数名匹配
print(s) # Mike is a boy
02. 列表(list)
1. 创建列表
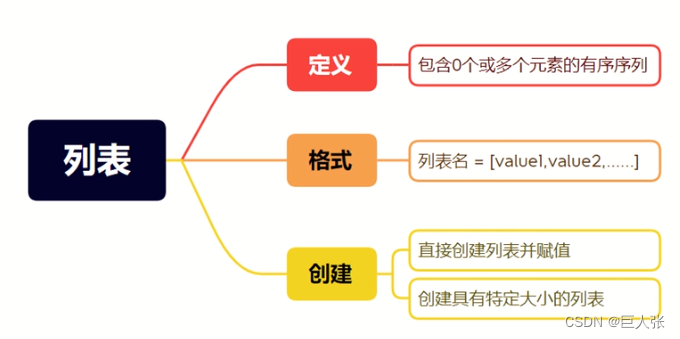
- 列表(list)是一种有序的容器,放入list中的元素,将会按照一定顺序排列。创建list的方式非常简单,使用中括号[]把需要放在容器里面的元素括起来,就定义了一个列表。
L = ['Alice', 66, 'Bob', True, 'False', 100]
2. 访问元素
- 列表中的元素既可以使用正向索引访问,也可以使用反向索引访问,正向索引从0开始,反向索引从-1开始。
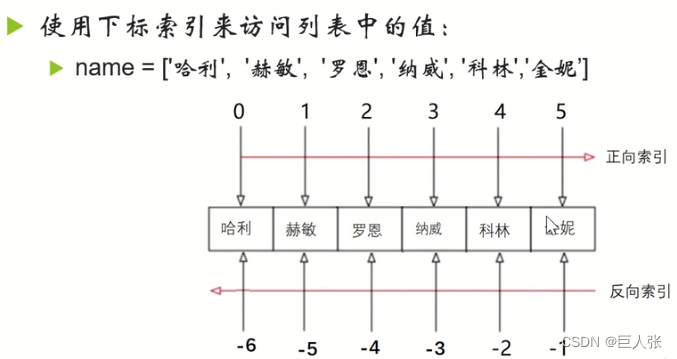
L = ['Alice', 66, 'Bob', True, 'False', 100]#### 访问元素
print(L[0]) #Alice
# print(L[6]) #错误:越界了
print(L[-1]) #100
3. 添加元素
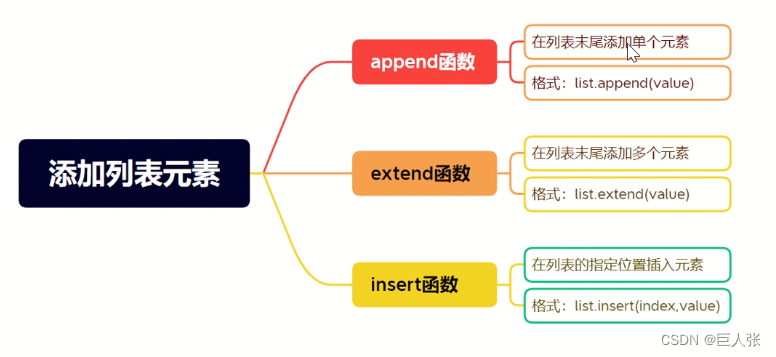
L = ['Alice', 66, 'Bob', True, 'False', 100]#### 添加元素
L.append('LiMing') #末尾追加
print(L) #['Alice', 66, 'Bob', True, 'False', 100, 'LiMing']
L.insert(3,99)
print(L) #['Alice', 66, 'Bob', 99, True, 'False', 100, 'LiMing']
L.extend(['False',33])
print(L) #['Alice', 66, 'Bob', 99, True, 'False', 100, 'LiMing', 'False', 33]
4. 删除元素
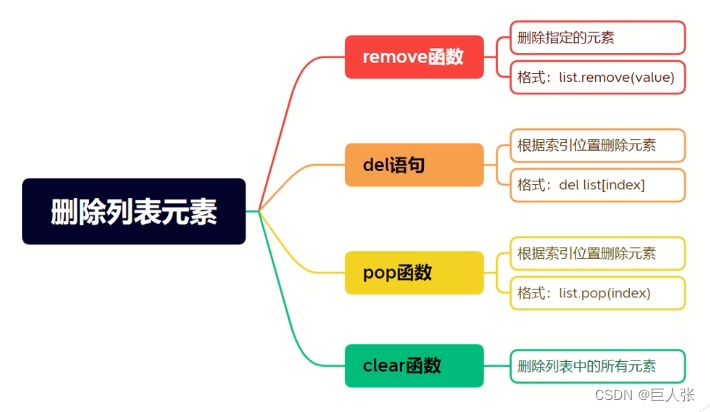
L = ['Alice', 66, 'Bob', 99, True, 'False', 100, 'LiMing', 'False', 33]#### 删除元素
L.remove(99)
print(L) #['Alice', 66, 'Bob', True, 'False', 100, 'LiMing', 'False', 33]
del L[2]
print(L) #['Alice', 66, True, 'False', 100, 'LiMing', 'False', 33]
L.pop(2)
print(L) #['Alice', 66, 'False', 100, 'LiMing', 'False', 33]
L.clear()
print(L) #[]
5. 列表切片
- list[start : end] 访问的是从索引start开始,一直到索引end的元素,但不包括索引end所在的元素
- list[start: ] 访问的是从索引start开始,一直到列表结束的元素
- list[: end] 访问的是从索引0开始,一直到索引end的元素,但不包括索引end所在的元素
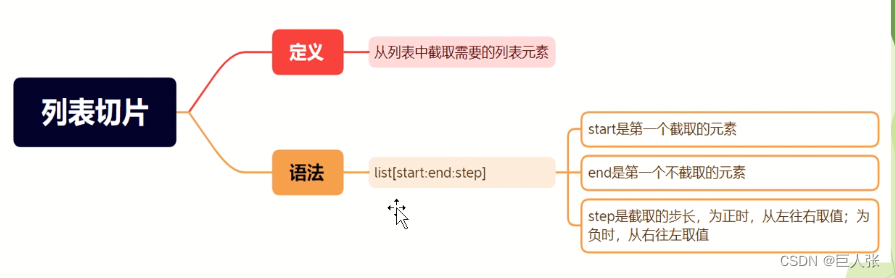
L = ['Alice', 66, 'Bob', True, 'False', 100]#### 列表切片
print(L[1:5]) #[66, 'Bob', True, 'False']
print(L[0:5:2]) #['Alice', 'Bob', 'False']
print(L[-5:-1:3]) #[66, 'False']
6. 元素个数

L = ['Alice', 66, 'Bob', True, 'False', 100]#### 元素个数
print(len(L)) #6
print(L.count(100)) #1
7. 列表运算符
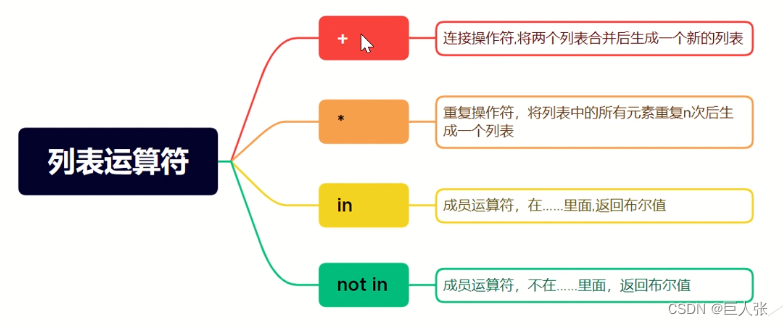
#### 列表运算符
L1 = ['Alice', 66, 'Bob']
L2 = [True, 'False', 100]
print(L1+L2) #['Alice', 66, 'Bob', True, 'False', 100]
print(L1*2) #['Alice', 66, 'Bob', 'Alice', 66, 'Bob']
print(100 in L2) #True
print(True not in L2) #False
8. 拷贝列表

#### 拷贝列表#### 赋值操作
L1 = ['Alice', 66, 'Bob']
L2 = L1
L1.append('AA')
print(L1) #['Alice', 66, 'Bob', 'AA']
print(L2) #['Alice', 66, 'Bob', 'AA']
L2.append('BB')
print(L1) #['Alice', 66, 'Bob', 'AA', 'BB']
print(L2) #['Alice', 66, 'Bob', 'AA', 'BB']
##原因:L1和L2的地址一样
print(id(L1)) #1986677652992 [电脑随机生成的]
print(id(L2)) #1986677652992#### copy操作
L1 = ['Alice', 66, 'Bob']
L2 = L1.copy()
L1.append('AA')
print(L1) #['Alice', 66, 'Bob', 'AA']
print(L2) #['Alice', 66, 'Bob']
L2.append('BB')
print(L1) #['Alice', 66, 'Bob', 'AA']
print(L2) #['Alice', 66, 'Bob', 'BB']
9. 列表排序

#### 列表排序L1 = ['Alice', 66, 'Bob']
L1.reverse()
print(L1) #['Bob', 66, 'Alice']
# 切片反转
print(L1[::-1]) #['Alice', 66, 'Bob']# 升序
L2 = [1, 66, 33, 16]
L2.sort()
print(L2) #[1, 16, 33, 66]
10. 列表转换

#### 列表转换【list函数】
a = 'python'
print(list(a)) #['p', 'y', 't', 'h', 'o', 'n']
b = 123
res = str(b)
print(res) #字符串123
L = list(res)
print(L) #['1', '2', '3']
11. 遍历列表
- 列表的遍历,我们可以使用for in 循环,或者搭配range函数一起都可以。

#### 【range函数】#### 遍历数字
for i in range(4):print(i) #0 1 2 3
for i in range(0, 4):print(i) #0 1 2 3
for i in range(0, 4, 2):print(i) #0 2#### for in遍历列表
L = ['10', '20', '30']
for i in L:print(i) # #10 20 30#### range遍历列表
L = ['10', '20', '30']
for i in range(len(L)):print(L[i]) #10 20 30
12. 其他函数

### 其他函数
list = [1,2,3,4]
print(min(list)) #1
print(max(list)) #4
print(sum(list)) #10list = ['aaa','bbb','ccc']
print(min(list)) #aaa
print(max(list)) #ccc
print(sum(list)) #报错
03. 元祖(tuple)
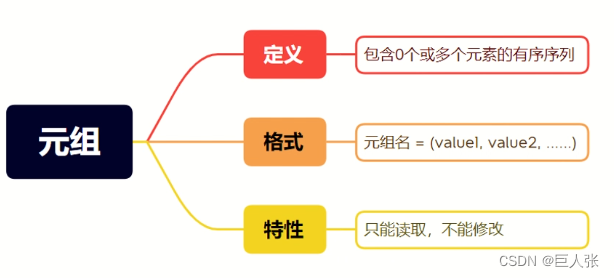
1. 创建元组
# 创建一个空元组
T = ()# 创建单个元素的元组
T = (1,) #【注意】:如果不加逗号,会变为整数类型# 创建多个元素的元组
T = (1, 2, 2, 3, 3)
2. 访问元素
- 和列表一样,元组中的元素既可以使用正向索引访问,也可以使用反向索引访问,正向索引从0开始,反向索引从-1开始。
T = ('Alice', 'Bob', 'Candy', 'David', 'Ellena')# 通过下标的方式访问元素
print(T[0]) # ==> Alice
print(T[4]) # ==> Ellena
print(T[-2]) # ==> David# 切片访问(和列表一样)
print(T[1:3]) # ==> ('Bob', 'Candy')
3. 元组的特性(不可删除)
- 元组和列表不一样的是,元组中的每一个元素都不可被改变,无法修改删除或者添加,而列表是可以的。所以我们也可以称,元组是只读的列表。
T = ('Alice', 'Bob', 'Candy', 'David', 'Ellena')# 不允许替换元素
T[1] = 'Boby' # 报错# 不允许删除元素
del T[1] # 报错# 不允许添加元素
T[5] = 'Mike' # 报错
【扩展】:以上元组的特性,针对的是元组中仅包含基础数据类型(数字类型、布尔类型、字符串类型)的元素,对于组合数据类型的元素,我们是可以改变这个组合数据类型中的某个值的。
T = (1, 'CH', [3, 4])
L = T[2]
print(L) # ==> [3, 4]
# 尝试替换L中的元素
L[1] = 40
print(L) # ==> [3, 40]
print(T) # ==> (1, 'CH', [3, 40])
4. 元组运算符
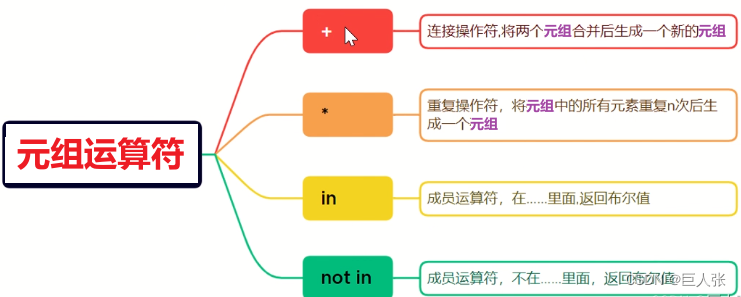
- 元组的运算符和列表都是一样的
#### 列表运算符
T1 = ('Alice', 66, 'Bob')
T2 = (True, 'False', 100)
print(T1+T2) #('Alice', 66, 'Bob', True, 'False', 100)
print(T1*2) #('Alice', 66, 'Bob', 'Alice', 66, 'Bob')
print(100 in T2) #True
print((100) in T2) #True
print(True not in T2) #False
5. 元组和列表相互转换
L = ['Alice', 'Bob', 'Candy', 'David', 'Ellena']
T = tuple(L)
print(T) # ==> ('Alice', 'Bob', 'Candy', 'David', 'Ellena')
L2 = list(T)
print(L2) # ==> ['Alice', 'Bob', 'Candy', 'David', 'Ellena']
6. 遍历元祖
- 元组的遍历和列表一致;
#### for in遍历元组
T = ('Alice', 'Bob', 'Candy', 'David', 'Ellena')
for i in T:print(i, end="|") # Alice|Bob|Candy|David|Ellena|#### range遍历元组
T = ('Alice', 'Bob', 'Candy', 'David', 'Ellena')
for i in range(len(T)):print(T[i], end="|") # Alice|Bob|Candy|David|Ellena|
7. 其他函数
| count | 用来统计元组中某个元素出现的次数 |
|---|---|
| index | 返回指定元素的下标,当一个元素多次重复出现时,则返回第一次出现的下标位置,如果没有该元素,会直接报错 |
| min | 查找最小值 |
| max | 查找最大值 |
| sum | 求和 |
T = (1, 1, 2, 2, 3, 3, 1, 3, 5, 7, 9)
print(T.count(1)) # ==> 3
print(T.count(5)) # ==> 1
print(T.count(10)) # ==> 0print(T.index(9)) # ==> 10
print(T.index(5)) # ==> 8
print(T.index(1)) # ==> 0 # 多次出现,返回第一次出现的位置
# print(T.index(100)) # ==> 报错print(min(T)) # ==> 1
print(max(T)) # ==> 9
print(sum(T)) # ==> 37
04. 字典(dict)
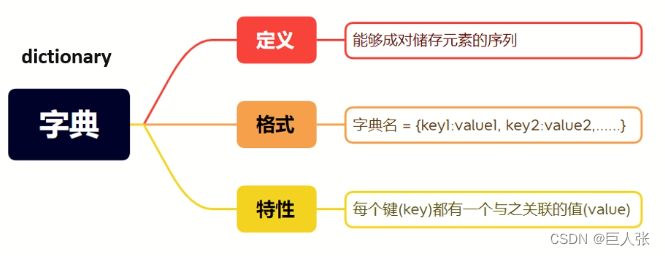
1. 创建元素
字典的核心就是:配对!即:键值对(key:value)!就是将列表中的下标索引进行自定义设计;
# 字典创建的语法,通过 花括号 以及 key:value 的方式构成:
字典变量 = {key:value,key:value...}
d = {'Alice': 45,'Bob': 60,'Candy': 75,'David': 86,'Ellena': 49,'Gaven': 86
}
print(d['Bob']) # ==> 60
print(d['Alice']) # ==> 45
print(d['Dodo']) # 报错,不存在# get方法读取【推荐】
# print(d.get('Dodo')) # ==> None 【dict本身提供get方法,把key当作参数传递给get方法,
# 就可以获取对应的value,当key不存在时,也不会报错,而是返回None】2. 访问元素
| 方法名 | 说明 |
|---|---|
| .get(key) | 返回key对应的值,当key不存在时,返回None |
| dict[key] | 返回key对应的值,当key不存在时,会报错 |
d = {'Alice': 45,'Bob': 60,'Candy': 75,'David': 86,'Ellena': 49,'Gaven': 86
}# get方法读取【推荐】
print(d['Bob']) # ==> 60
print(d.get('Dodo')) # ==> None# 直接通过索引key读取
print(d['Bob']) # ==> 60
print(d['Alice']) # ==> 45
print(d['Dodo']) # 报错,不存在
3. 增加元素
增加字典元素只需要添加一个key,再写上对应的value值就可以;如果新增的key重复,value值会被替换。
d = {'Alice': 45,'Bob': 60,'Candy': 75,'David': 86,'Ellena': 49
}d['Dodo'] = 88
d['Alice'] = 100 # 因为Alice存在,所以它的值会被替换成100
print(d) # {'Alice': 100, 'Bob': 60, 'Candy': 75, 'David': 86, 'Ellena': 49, 'Dodo': 88}
4. 删除元素
| 方法名 | 说明 |
|---|---|
| .pop(key) | 指定需要删除的元素的key,当key不存在时,会引起错误 |
| .clear() | 清除所有元素 |
d = {'Alice': 45,'Bob': 60,'Candy': 75,'David': 86,'Ellena': 49
}
#使用pop删除字典元素
d.pop('Alice')
print(d) #{'Bob': 60, 'Candy': 75, 'David': 86, 'Ellena': 49}#使用clear清除所有元素
d.clear()
print(d) #{}
5. 字典的特性
字典的一个重要特性:key不可变。key可以是数字、字符串、元组,但不能是列表,因为列表是可变的。
d = {'Alice': 45,'Bob': 60,'Candy': 75,'David': 86,'Ellena': 49
}
key = (1, 2, 3) # 以tuple作为key
d[key] = True
print(d) # {'Alice': 45, 'Bob': 60, 'Candy': 75, 'David': 86, 'Ellena': 49, (1, 2, 3): True}
key2 = [1, 2, 3]
d[key2] = True # 报错,列表不能作为key
6. 遍历字典
- 遍历dict有两种方法, 第一种是遍历dict的所有key,并通过key获得对应的value。
d = {'Alice': 45,'Bob': 60,'Candy': 75,'David': 86,'Ellena': 49
}
for key in d: value = d[key]print(key, value)#以上输出的结果:
'''
Alice 45
Bob 60
Candy 75
David 86
Ellena 49
'''
- 第二种方法是通过dict提供的items()方法
d = {'Alice': 45,'Bob': 60,'Candy': 75,'David': 86,'Ellena': 49
}
for key, value in d.items():print(key, value)#以上输出的结果:
'''
Alice 45
Bob 60
Candy 75
David 86
Ellena 49
'''
7. 其他函数
| 方法名 | 说明 |
|---|---|
| len(dict) | 计算字典元素的个数,即key的总数 |
| str(dict) | 输出字典的字符串表示 |
| type(dict) | 输入字典,会返回字典类型 |
d = {'Alice': 45,'Bob': 60,'Candy': 75,'David': 86,'Ellena': 49
}
print(len(d)) #5
print(str(d)) #转为字符串类型:{'Alice': 45, 'Bob': 60, 'Candy': 75, 'David': 86, 'Ellena': 49}
print(type(d)) #<class 'dict'>
{'Alice': 45, 'Bob': 60, 'Candy': 75, 'David': 86, 'Ellena': 49}
05. 集合(set)
1. 创建集合
集合的创建,大体上分为两种:
- 使用{}直接创建,将元素放在{}中,注意集合{}不能为空,否则会默认创建的是一个空字典;
- 使用set()函数来创建一个集合。
# 1.直接使用集合字面量
my_set1 = {1, 2, 3, 4, 5, 1}
print(my_set1) #{1, 2, 3, 4, 5} #自动去掉重复元素,以下雷同# 2.使用列表来初始化集合
my_list = [1, 2, 3, 4, 5, 1]
my_set2 = set(my_list)
print(my_set2) #{1, 2, 3, 4, 5}# 4.使用元组来初始化集合
my_tuple = (1, 2, 3, 4, 5, 1)
my_set3 = set(my_tuple)
print(my_set3) #{1, 2, 3, 4, 5}# 5.不必要的冗余写法,相当于集合中又套了一个{}
my_set4 = set({1, 2, 3, 4, 5, 1})
print(my_set4) #{1, 2, 3, 4, 5}
2. 添加元素
| 方法名 | 返回值说明 |
|---|---|
| .add() | 往集合中逐个添加元素 |
| .update() | 往集合中批量添加元素 |
name_set = set(['Alice', 'Bob'])
name_set.add('Gina') #add:逐个添加
print(name_set) # ==> {'Bob', 'Alice', 'Gina'}my_list = ['Hally', 'Isen']
name_set.update(my_list) #update:批量添加
print(name_set) # ==> {'Isen', 'Gina', 'Bob', 'Alice', 'Hally'}
3. 删除元素
| 方法名 | 返回值说明 |
|---|---|
| .remove() | 删除集合中的元素 |
| .pop() | 删除集合中的第一个元素 |
| .clear() | 清空集合中的元素 |
name_set = set(['Jenny', 'Ellena', 'Alice', 'Bob'])
name_set.remove('Jenny')
print(name_set) # {'Bob', 'Ellena', 'Alice'} 【注意】:删除Jenny这个元素后,集合中的元素是随机摆放的,所以后面使用pop删除首个元素,可能得到的结果是不一致的name_set.pop()
print(name_set) # {'Ellena', 'Alice'}name_set.clear()
print(name_set) #set()
4. 判断元素是否存在
由于set里面的元素是没有顺序的,因此我们不能像list那样通过索引来访问。访问set中的某个元素实际上就是判断一个元素是否在set中,这个时候我们可以使用in来判断某个元素是否在set中。
s = set([1, 4, 3, 2, 5, 4, 2, 3, 1])
print(1 in s) #True
print(6 in s) #False
5. 集合的特性
-
set里面的元素不允许重复。【如果重复了,会自动进行去重处理】
-
set里面的元素没有顺序。
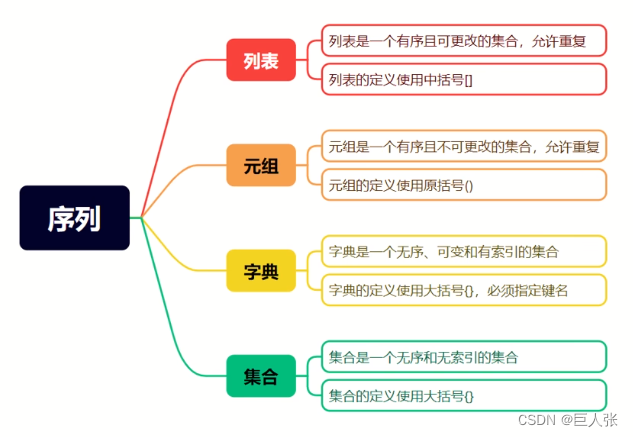
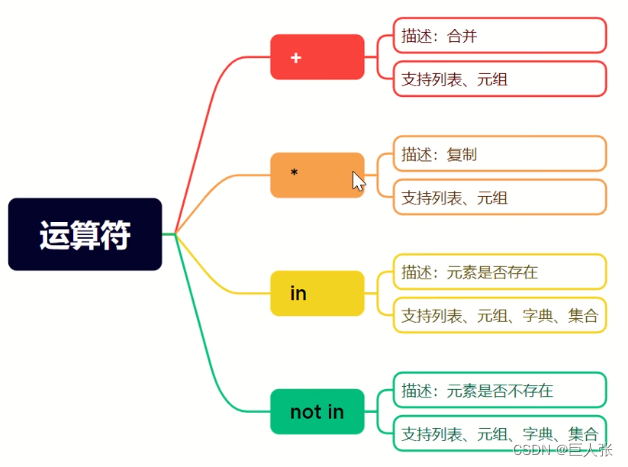
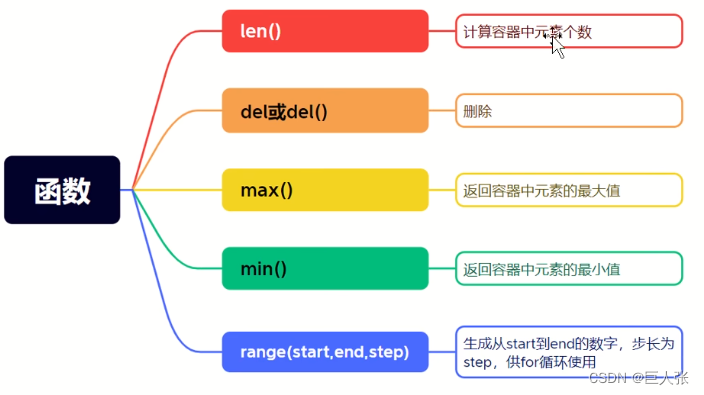
06. 序列(总结篇)
07. if 条件判断
1. if…单一条件
假设你一周七天中只有周一才能穿新衣服,那么就需要 if语句 中 单一条件判断:
- 单一条件判断的if语句格式如下:
if 条件判断:条件满足时,执行
# 注意1:判断的数值需要转换为整数再判断
# 注意2:a == 1由于习惯或方式,可以加上括号(a == 1)
# 注意3:if条件判断内的语句,需要用Tab键缩进才能识别
a = int(input("请输入今天星期几,1-7之间:"))
if a == 1:print("今天穿新衣")
2. if…else分支
单一if语句比较高冷,如果未满足条件,它就不理你了;而else分支则可爱许多;
- else分支条件判断的if语句格式如下:
if 条件判断:条件满足时,执行
else:条件不满足时,执行
# 注意1:else后面有冒号,表示结束
# 注意2:else需要和if在同一垂直位对齐,否则报错
if a == 1:print("今天穿新衣")
else:print("今天无法穿新衣")
08. 多重嵌套
1. elif…多重分支
年龄决定一个人当前的状态,8岁到80岁,你都在干什么?此时需要elif多重分支:
if 条件判断:条件满足时,执行
elif 条件判断:条件满足时,执行
...
# 8-25之间:求学阶段
# 26-60之间:工作阶段
# 大于60:退休阶段
a= int(input("请输入你的年龄:8-80之间:"))
if a >= 8 and a <=25:print("我在上学!")
elif a >=26 and a<=60:print("我在工作!")
elif a > 60:print("我在退休!")
else:print("这个年龄,尚未被统计!")
2. if…嵌套判断
难道大于60岁就真的可以退休了吗?真实情况显然不是这样的,我们还需要具体判断:
...
elif a > 60:# 如果爷爷有大伯,二伯和我爸# 且,我还有姐姐和弟弟# 再且,大伯、二伯每家还有三个# 为了存压岁钱,也无法退休呢!b = int(input("请输入子孙的数量,1-9之间:"))if b >= 7 and b <=9:print("退休后打两份工")elif b >= 4 and b <=6:print("退休后打一份工")elif b <= 3:print("退休中!")
...
09. while循环
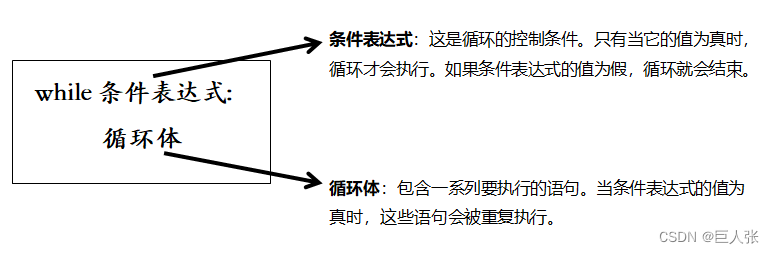
1. 认识while循环
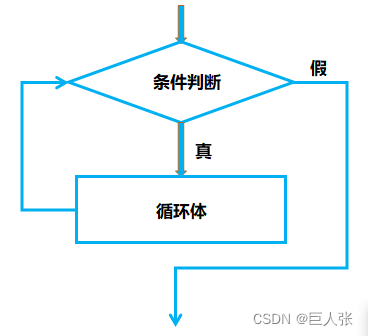
(1)while循环简介
- while循环是一种条件控制循环,只要给定的条件为真,循环就会持续执行。它通常用于重复执行一个任务,直到条件不再满足,跳出循环。
(2)while循环示意图
(3)while循环语法
2. while常规循环
- 需求:输出1~3之间所有的整数,并用“|”分隔开
i = 1 # 初始化变量1
while i <= 3: # 如果变量小于等于3,则执行下面的循环体print(i, end="|")i += 1 # 当执行完毕,自增1
# 以上循环最终结果:1|2|3| ------------------------------------
这里我们依次拆解while循环的过程:
第一次循环:i = 1i <= 3 条件成立print(i, end="|") ---> 结果:输出1|i += 1,相当于 i = 2
第二次循环:i = 2 因为第一次循环结束后i已经变为2了i <= 3 条件成立print(i, end="|") ---> 结果:输出1|2|i += 1,相当于 i = 3
第三次循环:i = 3 i <= 3 条件成立print(i, end="|") ---> 结果:输出1|2|3|i += 1,相当于 i = 4
第四次循环:i = 4 i <= 3 条件不成立,循环终止
------------------------------------
- 需求:计算1到3之间所有整数的和
i = 1 # 初始化变量1
sum = 0 #初始化求和变量,用于统计最终的结果
while i <= 3: # 如果变量小于等于3,则执行下面的循环体sum += i # 累加i += 1 # i自增1
print(sum) # 6------------------------------------
这里我们依次拆解while循环的过程:
第一次循环:i = 1sum = 0i <= 3 条件成立sum += i 相当于sum = sum+i = 0+1i += 1,相当于 i = 2
第二次循环:i = 2 sum = 0+1i <= 3 条件成立sum += i 相当于sum = sum+i = 0+1+2i += 1,相当于 i = 3
第三次循环:i = 3 sum = 0+1+2i <= 3 条件成立sum += i 相当于sum = sum+i = 0+1+2+3i += 1,相当于 i = 4
第四次循环:i = 4 sum = 0+1+2+3i <= 3 条件不成立,循环终止,最终sum = 6
------------------------------------
3. while死循环
- while循环除了普通的循环,有时候也会出现死循环的情况,比如:
# 只要判断表达式永远为True,则不停的执行
while True:print(1)
# 以上代码会不停的输出1的值,因为条件始终是成立的,所以循环会一直执行,也就出现了所谓的死循环,这时候计算机会卡死,性能消耗太大了;但是,死循环也不是一无是处,我们可以利用死循环的特性,结合break语句,帮助我们做一些特殊的处理,后面我们会讲到。
10. for循环
1. 认识for循环
(1)for循环简介
- 在Python中,
for循环是一种用于遍历序列(如列表、元组、字典、字符串)或其他可迭代对象(如range对象等)的控制流语句。
(2)for循环示意图
(3)for循环语法
for 变量 in 序列:循环体
【注】:在这个结构中,变量是一个临时变量,用于获取序列中的每一个元素。循环体会针对序列中的每个元素各执行一次。
2. for循环示例
- 需求:输出1~3之间所有的整数,并用“|”分隔开
for i in range(1,4): # 使用range函数生成一个从1到3的整数序列: [1,2,3]print(i, end="|")# 结果:1|2|3|------------------------------------
这里我们依次拆解for循环的过程:
第一次循环:i = 1 【range生成的第一个数】print(i, end="|") ---> 结果:输出1|
第二次循环:i = 2 【range生成的第二个数】print(i, end="|") ---> 结果:输出1|2|
第三次循环:i = 3 【range生成的第三个数】print(i, end="|") ---> 结果:输出1|2|3|
------------------------------------
- 需求:计算1到3之间所有整数的和
sum = 0 #初始化求和变量,用于统计最终的结果
for i in range(1,4):sum += i # 累加
print(sum) # 6------------------------------------
这里我们依次拆解for循环的过程:
第一次循环:sum = 0 i = 1 【range生成的第一个数】sum += i,即sum = sum + i = 0+1
第二次循环:sum = 0+1i = 2 【range生成的第二个数】sum += i,即sum = sum + i = 0+1+2
第三次循环:sum = 0+1+2i = 3 【range生成的第三个数】sum += i,即sum = sum + i = 0+1+2+3 = 6
------------------------------------
11. 退出循环
1. break退出整体循环
break语句的作用:立即退出整个循环;
- 需求:输出1~10之间所有的整数,并用“|”分隔开
for i in range(1, 11):print(i, end="|")
#最终结果:1|2|3|4|5|6|7|8|9|10|
假如我们给出的序列为range(1, 11) ,依旧是111的序列,但是我们只想要输出13之间的整数,该怎么做呢?此时,我们就可以使用break语句了。
for i in range(1, 11):print(i, end="|")if i == 3:break
#最终结果:1|2|3|------------------------------------
这里我们依次拆解for循环的过程:range范围[1,2,3,4,5,6,7,8,9,10]
第一次循环:i = 1 【range生成的第一个数】print(i, end="|") ---> 结果:输出1|if i == 3: 条件不成立,break语句不执行,循环继续break
第二次循环:i = 2 【range生成的第二个数】print(i, end="|") ---> 结果:输出1|2|if i == 3: 条件不成立,break语句不执行,循环继续break
第三次循环:i = 3 【range生成的第三个数】print(i, end="|") ---> 结果:输出1|2|3|if i == 3: 条件成立,进入下面的break语句,立即停止整个循环,所以最终结果为:1|2|3|break
------------------------------------
2. continue退出当前循环
continue语句的作用:终止当前循环;
沿用上面的例子,假如我们给出的序列为range(1, 11) ,依旧是111的序列,现在我们的需求是输出110之间所有的整数,但不想要3这个整数,该如何做呢?此时,我们就可以使用continue语句了。
for i in range(1, 11):# 注意:这里continue必须在输出语句前面执行,否则白搭if i == 3:continueprint(i, end="|")
#最终结果:1|2|4|5|6|7|8|9|10|------------------------------------
这里我们依次拆解for循环的过程:range范围[1,2,3,4,5,6,7,8,9,10]
第一次循环:i = 1 【range生成的第一个数】 if i == 3: 条件不成立,continue语句不执行,循环继续continue print(i, end="|") ---> 结果:输出1|
第二次循环:i = 2 【range生成的第二个数】if i == 3: 条件不成立,continue语句不执行,循环继续continue print(i, end="|") ---> 结果:输出1|2|
第三次循环:i = 3 【range生成的第三个数】 if i == 3: 条件成立,进入下面的continue语句,会跳过本次循环,但是下面的循环仍会继续continue print(i, end="|") ---> 结果:输出1|2|
第四次循环:i = 4 【range生成的第四个数】 if i == 3: 条件不成立,continue语句不执行,循环继续continue print(i, end="|") ---> 结果:输出1|2|4|
以下循环依次类推:......最终结果:结果:1|2|4|5|6|7|8|9|10|
------------------------------------
待补充:
12.for循环嵌套、while循环嵌套、条件和循环的嵌套