【图像分割 2023】BRAU-Net++
论文题目:BRAU-Net++: U-Shaped Hybrid CNN-Transformer Network for Medical Image Segmentation
中文题目:
论文链接:[2401.00722] BRAU-Net++: U-Shaped Hybrid CNN-Transformer Network for Medical Image Segmentation (arxiv.org)
论文代码:
论文团队:重庆理工大学
发表时间:
DOI:
引用:
引用数:
摘要
准确的医学图像分割对于临床量化、疾病诊断、治疗计划等诸多应用至关重要。基于卷积和基于变换的u型结构在各种医学图像分割任务中都取得了显著的成功。前者可以有效地学习图像的局部信息,但需要更多的图像特定于卷积运算固有的归纳偏差。后者可以利用自注意在不同的特征尺度上有效地捕获远程依赖关系,但随着序列长度的增加,它通常会遇到二次计算和内存需求的挑战。为了解决这一问题,通过在一个精心设计的u型架构中整合这两种范式的优点,我们提出了一种有效的混合CNN-Transformer网络,命名为brau - net++,用于精确的医学图像分割任务。具体而言,BRAU-Net++以双层路由关注为核心构建块,设计了u型编码器和解码器结构,编码器和解码器都是分层构建的,从而在学习全局语义信息的同时降低了计算复杂度。
此外,该网络通过引入采用卷积运算的通道-空间注意来重组跳跃连接,以最小化局部空间信息损失,放大多尺度特征的全局维度交互作用。在三个公共基准数据集上的大量实验证明了我们的推荐的方法在几乎所有评估指标下都优于其他最先进的方法,包括其基线:BRAU-Net。我们在突触多器官分割、ISIC-2018 Challenge和CVC-ClinicDB上的平均Dice-Similarity Coefficient (DSC)分别为82.47、90.10和92.94,在ISIC-2018 Challenge和CVC-ClinicDB上的mIoU分别为84.01和88.17。代码将在GitHub上提供
1. 介绍
精确的、鲁棒的医学图像分割在计算机辅助诊断系统中起着至关重要的作用,特别是在图像引导的临床手术、疾病诊断、治疗计划和临床量化等方面[1],[2],[3]。
医学图像分割通常被认为与自然图像分割本质相同[4],其相应的技术往往来源于自然图像分割[5]。两个群体的共同之处在于,他们都以手动或全自动的方式提取图像的准确兴趣区域(roi)作为研究目标。得益于深度学习技术,自然图像视觉中的分割任务取得了令人瞩目的成绩。
但与自然图像分割不同,医学图像分割对异常、器官等roi的分割结果要求更加准确,快速识别病变边界,准确评估病变程度。这是因为在临床实践中,医学图像中细微的分割错误会导致临床设置中的用户体验不佳,并增加后续计算机辅助诊断的风险[6]。此外,在各种成像方式中,手动描绘病变及其边界需要大量的努力,这非常耗时,甚至不切实际,并且最终的分割可能受到临床医生的偏好和专业知识的影响[7],[45]。因此,我们认为开发智能和强大的技术来高效准确地分割医学图像中的病变区域或器官是至关重要的。
随着深度学习的发展以及广泛而有前景的应用,人们提出了许多基于卷积运算的医学图像分割方法来分割特定目标医学图像中的物体。在这些方法中,U-Net[8]和全卷积网络(fully convolutional network, FCN)[9]等ushashape编码器-解码器架构在医学图像分割中占据主导地位。后续的各种变体如U-Net++[6]、U-Net 3+[10]、Attention U-Net[11]、3D U-Net[12]、V-Net[13]等也被开发用于各种医学成像方式的图像和体积分割,并在心脏分割、多器官分割、息肉分割等广泛的医学应用中取得了突出的成功。这些基于CNN的方法的优异表现证明了CNN具有很强的语义信息学习能力。
但是由于卷积操作的固有局部性,它在显式捕获远程依赖关系时经常显示出局限性。一些研究试图通过使用亚特罗斯卷积层[14]、[15]、自注意机制[16]、[17]和图像金字塔[18]来解决这个问题。然而,这些方法并不能显著提高远程依赖关系的建模能力。
近年来,受transformer在自然语言处理(natural language processing, NLP)[19]领域取得巨大成功的启发,许多研究尝试将transformer应用于视觉领域[20],[21],[22],[23]。这些工作在各种视觉任务上取得了一致的改进,这表明视觉转换器在视觉领域具有巨大的潜力。
在这些工作中,一个热门的话题是如何通过改进核心构建块,即注意力来提高模型的性能。作为视觉转换器的核心组成部分,注意力是捕捉长期依赖关系的有力工具。
然而,香草注意是一种完整的注意机制,它计算跨所有空间位置的成对令牌亲和性,因此它具有很高的计算复杂性并导致大量内存占用[24]。为了缓解这个问题,一些作品尝试将稀疏关注应用于视觉转换,其中每个查询令牌只关注键和值令牌的一部分,而不是整个序列[25]。为此,研究人员探索了几种手工制作的稀疏图案,如将注意力限制在局部窗口[23]、扩张窗口[26]、[27]或轴向条纹[28]。在医学图像视觉界,也有很多研究将Transformer引入到医学图像分割任务中,如nnFormer[29]、UTNet[30]、TransUNet[1]、TransCeption[3]、HiFormer[32]、FocalUNet[33]、MISSFormer[34]。然而,据我们所知,很少有作品考虑将稀疏性思想引入这一领域,其中代表性的作品包括SwinUnet[35]和门控轴向UNet (MedT)[36]。但是这些稀疏注意机制以手工制作的方式合并或选择稀疏模式。因此,这些模式是查询无关的。
也就是说,它们由所有查询共享。将动态和查询感知稀疏性应用于医学图像分割仍然是一个很大的未知领域
这些问题促使我们探索一种全自动的高级分割算法,能够根据医学图像的性质产生有效的分割结果,从而造福于更多的图像引导医学应用。最近,受BiFormer[24]成功将稀疏注意力应用于视觉转换器[37]的启发,我们提出了BRAU-Net++,以利用用于医学图像分割的Transformer。据我们所知,BRAU-Net++是第一个考虑将动态稀疏注意合并到CNN-Transformer架构中的混合模型。BRAU-Net++也是在BRAU-Net基础上发展而来的[38],采用BiFormer块构建u型纯Transformer网络结构,采用跳接方式进行耻骨联合-胎头分割。与swan - unet[35]和BRAU-Net[38]类似,网络结构的主要组成部分包括编码器、瓶颈、解码器和跳过连接。编码器、瓶颈和解码器都是基于BiFormer的核心构建块[24]:双层路由关注,有效地模拟了远程依赖关系,节省了计算和内存。同时,在全局注意机制的激励下[39],我们重新设计了跳跃连接,通过卷积运算加入通道空间注意,旨在最小化局部空间信息损失,放大多尺度特征的全局维度相互作用。此外,类似于[24],[26],[40],[41],所提出的架构利用深度卷积隐式编码位置信息。在Synapse多器官分割[56]、ISIC2018 Challenge[42]、[43]和CVC-ClinicDB[44]三个公开的医学图像数据集上进行的大量实验表明,该方法取得了良好的性能和鲁棒的泛化能力
本文的主要贡献如下:
- 1)引入了一种u型混合CNN-Transformer网络,该网络以双层路由关注为核心构建块,设计了编码器-解码器结构,其中编码器和解码器都是分层构建的,从而有效地学习局部-全局语义信息,同时降低了计算复杂度。
- 2)利用通道-空间注意机制对传统的跳跃连接进行了重新设计,提出了通道-空间注意的跳跃连接(SCCSA),旨在增强通道和空间两方面的跨维交互,补偿下采样造成的空间信息损失。
- 3)验证了BRAU-Net++在三个常用数据集上的有效性:Synapse多器官分割、ISIC-2018 Challenge和CVC-ClinicDB数据集。结果表明,所提出的BRAUNet++在几乎所有评估指标下都比其他最先进的(SOTA)方法表现出更好的性能。
本文的其余部分组织如下。第二节回顾前人的相关工作。第三节详细说明了我们的方法、主要构建模块和培训程序。第四节介绍了我们的实验设置。第五节报告了实验细节和结果。第六节对实验结果和发现进行了讨论和说明,最后,第七节给出了我们的结论。
2. 相关工作
2.1 U型网络
- 基于cnn的医学图像分割u型架构:该范式的主要技术包括UNet[8]和FCN[9],以及随后的变体[6],[10],[11],[12],[13],其中一些分别被引入到二维或三维医学图像分割社区中。由于u型结构的简单性和优越的性能,在二维医学图像分割领域不断出现各种类似UNet的方法,如U-Net+[6]、UNet 3+[10]、dcau - net[46]等。3D医学图像分割领域也引入了其他方法,如3D- unet[12]、V-Net[13]。该方法采用一系列卷积池操作来设计其编码器和解码器。由于其强大的表征能力,该范式在广泛的医学应用中取得了巨大的成功。关于U-Net及其变体应用于医学图像分割的更多作品,可参考相关综述文献[47],[48]。
- 基于Transformer的医学图像分割u型架构:最初的Transformer架构是针对机器翻译任务提出的[19],并且已经成为自然语言处理(NLP)问题的事实上的标准。后续的工作对变压器在计算机视觉中的应用做了更多的尝试。近年来,研究人员尝试开发纯变压器或混合变压器来进行医学图像分割。文献[35]提出了一种纯转换器,即swan - unet,用于医学图像分割,其中将原始图像的标记化补丁而不是CNN特征映射馈送到架构中进行局部全局语义特征学习。在[1]中,一种CNNTransformer混合模型TransUNet利用CNN特征的详细高分辨率空间信息和变压器编码的全局上下文来实现卓越的分割性能。与TransUNet类似,UNETR[49]和Swin UNETR[50]在编码器中使用变压器,并使用卷积解码器生成分割图。这些工作使用完全注意或静态稀疏注意来计算两两令牌关联。与这些方法不同的是,我们引入了动态稀疏关注来选择最相关的标记,并将原始图像中的标记化补丁作为网络的输入。因此,信息不会因为较低的分辨率而丢失。同时,我们将卷积运算应用到跳跃连接中,以增强多尺度特征的全局维度交互作用。
2.2 稀疏注意机制
已经引入了稀疏连接模式[37]来解决香草注意机制的计算和记忆复杂性。稀疏注意在视觉变换中越来越受到关注[23]、[25]、[26]、[27]、[28]。
在Swin Transformer[23]中,将注意力限制在不重叠的局部窗口上,并引入了移位窗口操作以促进相邻窗口之间的窗口间通信。因此,这种关注是手工制作的,它是基于本地窗口的。随后的研究也引入了各种人工设计的稀疏模式,如膨胀窗[26]、[27]或十字形窗[31]。近年来,基于动态令牌稀疏性的高效视觉转换器取得了很大的成功。在[51]中,通过分层修剪动态选择要传递到下一层的令牌数量来实现推理的加速。在[25]、[24]中,他们分别提出了四叉树关注和双层路由关注,以从粗到精的方式实现自适应查询的稀疏性。不同之处在于双层路由关注旨在定位几个最相关的键值对,而四叉树关注构建一个令牌金字塔并组装来自不同粒度级别的信息。在这项工作中,我们尝试以BiFormer块为基本单元,构建一个带有SCCSA模块的u型编解码器架构,用于医学图像分割。
2.3 通道空间注意力
计算机视觉中注意机制的研究取得了很大进展,其中通道注意和空间注意是两个重要的研究方向。
频道关注关注的是CNN频道的信息。例如,SENet[52]自适应地重新校准通道特征响应,以增强网络的判别能力。另一方面,空间注意力集中在相关的空间区域。例如,STN[53]可以对空间中的各种变形数据进行变换,自动捕捉重要的区域特征。在这些个体成功的基础上,CBAM[54]将渠道注意和空间注意以串联的方式结合起来,共同捕捉渠道和空间位置之间的复杂依赖关系。
受全局注意机制[39]的启发,我们利用通道空间注意重新设计跳跃连接,增强通道空间维度的交互性,弥补下采样造成的空间信息损失
3. 方法
在本节中,我们首先简要概述双层路由注意(BRA)。然后,我们描述了提出的BRAU-Net++的总体架构。最后,我们介绍了BiFormer块和跳过连接通道空间注意模块(SCCSA)。
3.1 预备知识:双级路由注意
双层路由注意(BRA)是一种动态的、查询感知的稀疏注意机制,其核心思想是在粗粒度区域级别过滤掉语义上最不相关的键值对,只保留最相关路由区域的一小部分用于细粒度令牌到令牌的注意。与其他手工制作的静态稀疏注意机制[23],[31],[55]相比,BRA容易产生模型的远程依赖。在这一点上,它类似于香草的注意。但BRA的复杂性要低得多,为 O ( ( H W ) 4 3 ) O((HW)^{\frac43}) O((HW)34),而香草注意力的复杂性为 O ( ( H W ) 2 ) O((HW)^{2}) O((HW)2) [24]
1)区域划分与线性投影:将二维输入特征图 X ∈ R H × W × C \mathbf{X}\in\mathbb{R}^{H\times W\times C} X∈RH×W×C划分为S×S个不重叠的区域,得到每个区域的特征维数 H W S 2 \frac{HW}{S^{2}} S2HW。随后,根据得到的特征映射 X r ∈ R S 2 × H W S 2 × C \mathbf{X}^r\in \mathbb{R}^{S^{2}\times\frac{HW}{S^{2}}\times C} Xr∈RS2×S2HW×C,可以通过线性投影得到查询、键、值 Q , K , V ∈ R S 2 × H W S 2 × C \mathbf{Q},\mathbf{K},\mathbf{V}\in\mathbb{R}^{S^{2}\times\frac{HW}{S^{2}}\times C} Q,K,V∈RS2×S2HW×C:
Q = X r W q , K = X r W k , V = X r W v . \mathbf{Q}=\mathbf{X}^r\mathbf{W}^q,\mathbf{K}=\mathbf{X}^r\mathbf{W}^k,\mathbf{V}=\mathbf{X}^r\mathbf{W}^v. Q=XrWq,K=XrWk,V=XrWv.
式中, W q , W k , W v ∈ R C × C \mathbf{W}^q,\mathbf{W}^k,\mathbf{W}^v\in\mathbb{R}^{C\times C} Wq,Wk,Wv∈RC×C分别为查询、键、值的线性投影权重矩阵。
2)区域到区域路由:首先计算每个区域的Q和K的平均值,得到区域级查询和键, Q r , K r ∈ R S 2 × C \mathbf{Q}^r,\mathbf{K}^r\in\mathbb{R}^{S^2\times C} Qr,Kr∈RS2×C。
接下来,区域到区域的邻接矩阵, A r ∈ R S 2 × S 2 \mathbf{A}^r\in\mathbb{R}^{S^2\times S^2} Ar∈RS2×S2,通过应用 Q r \mathbf{Q}^r Qr和转置 K r \mathbf{K}^r Kr之间的矩阵乘法得到。最后,关键步骤是通过路由索引矩阵 I r ∈ N S 2 × k \mathbf{I}^r\in\mathbb{N}^{S^2\times k} Ir∈NS2×k,使用逐行top-k运算符:topkIndex(),仅为每个查询区域保留top-k个最相关的区域。区域到区域路由可表示为:
A r = Q r ( K r ) T . I r = topkIndex ( A r ) . \begin{gathered}\mathbf{A}^r=\mathbf{Q}^r(\mathbf{K}^r)^T.\\\mathbf{I}^r=\operatorname{topkIndex}(\mathbf{A}^r).\end{gathered} Ar=Qr(Kr)T.Ir=topkIndex(Ar).
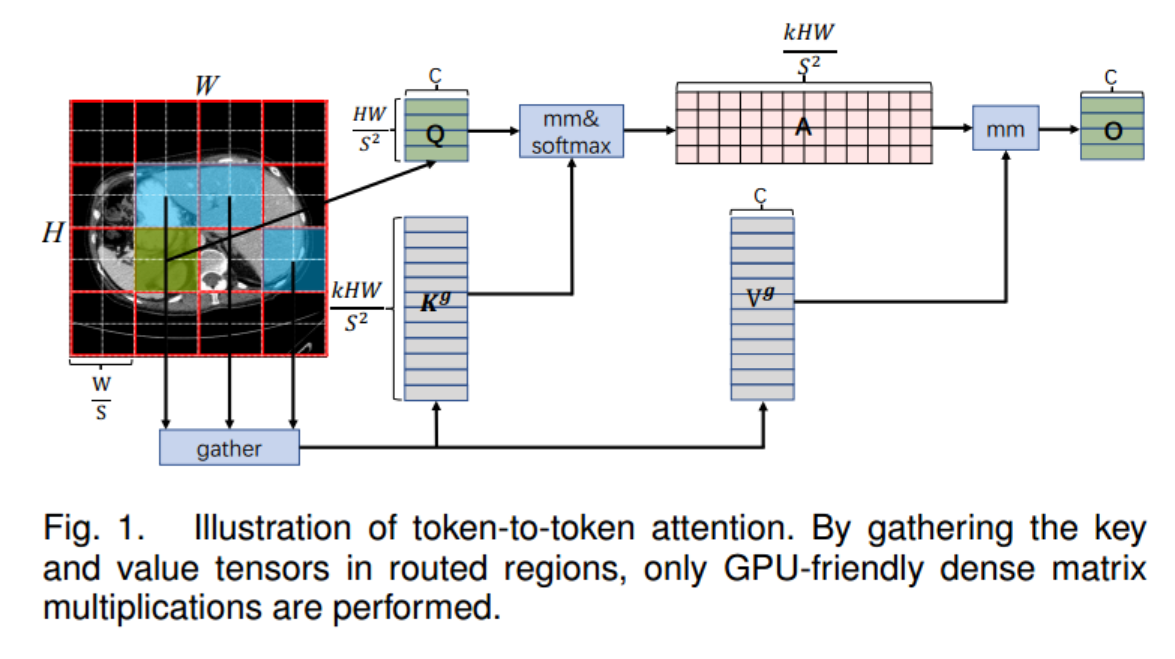
3)Token-to-Token注意:由于路由区域可能在空间上分散在整个特征映射上,因此需要收集路由区域中的键和值张量。然后对这些键值张量应用细粒度令牌对令牌的关注。该过程如图1所示,可表述为:
K g = g a t h e r ( K , I r ) , V g = g a t h e r ( V , I r ) . O = s o f t m a x ( Q ( K g ) T C ) V g + L C E ( V ) . \begin{aligned}\mathbf{K}^g&=\mathrm{gather}(\mathbf{K},\mathbf{I}^r),\mathbf{V}^g=\mathrm{gather}(\mathbf{V},\mathbf{I}^r).\\\mathbf{O}&=\mathrm{softmax}(\frac{\mathbf{Q}(\mathbf{K}^g)^T}{\sqrt{C}})\mathbf{V}^g+\mathrm{LCE}(\mathbf{V}).\end{aligned} KgO=gather(K,Ir),Vg=gather(V,Ir).=softmax(CQ(Kg)T)Vg+LCE(V).
其中, K g , V g ∈ R k H W × C \mathbf{K}^g,\mathbf{V}^g~\in~\mathbb{R}^{kHW\times C} Kg,Vg ∈ RkHW×C是集合键值张量。函数LCE(·)是使用深度卷积参数化的。
3.2 体系结构概述
BRAU-Net++的总体架构如图所示。
2(一个)。BRAU-Net++包括编码器、解码器、瓶颈和SCCSA模块。对于编码器,给定大小为H × W × 3的医学图像输入,将医学图像分割成重叠的小块,通过小块嵌入将每个小块的特征维度投影到任意维度(定义为C)。转换后的补丁令牌通过多个BiFormer块和补丁合并层来生成分层特征表示。具体来说,采用补丁合并来降低特征映射的分辨率和增加维度,采用BiFormer块来学习特征表示。对于瓶颈,特征映射的分辨率和维数保持不变。启发利用U-Net[8]和swan - unet[35],我们设计了一个基于对称变压器的译码器,该译码器由BiFormer块和patch扩展层组成。斑块扩展层负责上采样和降维。通过SCCSA模块将提取的上下文特征与编码器的多尺度特征融合,弥补了下采样造成的空间信息丢失,放大了全局维度的相互作用。最后一个补丁扩展层进行4倍上采样,恢复特征图的原始分辨率H × W,然后使用线性投影层生成像素级分割预测。
我们将在下面详细说明每个区块。
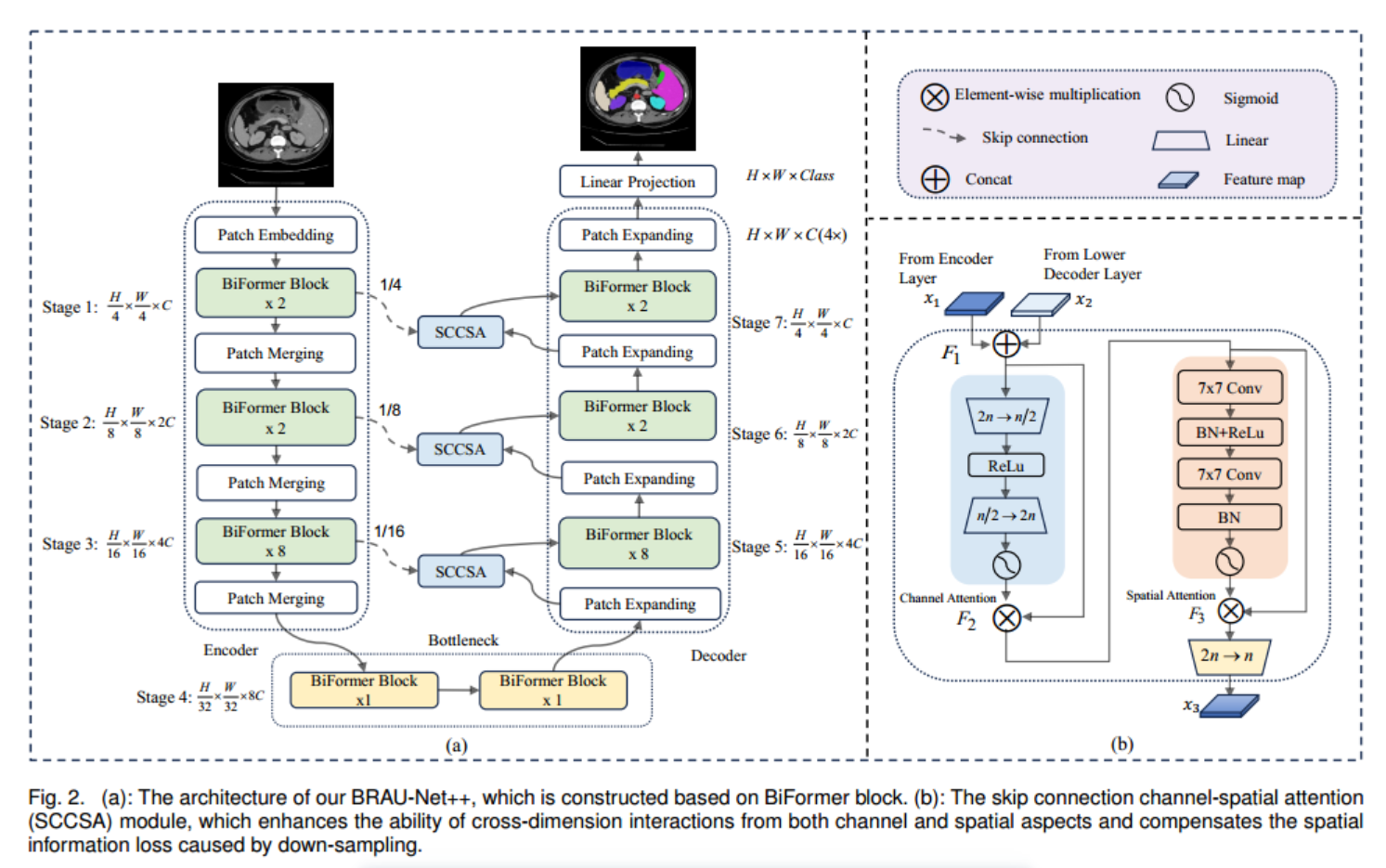
3.3 BiFormer Block
构建块的核心是双层路由注意(BRA)。如图3所示,BiFormer块在开始时由一个3×3深度卷积、2个LayerNorm (LN)层、一个BRA模块、3个残差连接和一个扩展比为e = 3的2层MLP组成。3×3深度卷积可以隐式编码相对位置信息。BiFormer块可以表示为:
z ^ l − 1 = D W ( z l − 1 ) + z l − 1 , z ^ l = B R A ( L N ( z ^ l − 1 ) ) + z ^ l − 1 , z l = M L P ( L N ( z ^ l ) ) + z ^ l , \begin{aligned}\hat{z}^{l-1}&=DW(z^{l-1})+z^{l-1},\\[1ex]\hat{z}^l&=BRA(LN(\hat{z}^{l-1}))+\hat{z}^{l-1},\\[1ex]z^l&=MLP(LN(\hat{z}^l))+\hat{z}^l,\end{aligned} z^l−1z^lzl=DW(zl−1)+zl−1,=BRA(LN(z^l−1))+z^l−1,=MLP(LN(z^l))+z^l,
其中z´l−1,z´l和z l分别表示第1块的深度卷积、BRA模块和MLP模块的输出。
3.4 编码器
编码器采用三级金字塔结构分层构建。具体而言,在阶段1中使用由两个3×3卷积层组成的补丁嵌入层,在阶段1 - 3中使用带有3×3卷积层的补丁合并层,以降低输入空间分辨率,同时增加通道数量。如图2所示,在阶段1中,具有h4 × w4和C通道分辨率的标记化输入被馈送到两个连续的BiFormer块中以执行表示学习。阶段2-3中的标记化输入也以类似的方式执行。
补丁合并层执行2倍的下采样,使标记数量减少一半,并将特征维度增加2倍。
3.5 解码器
与编码器类似,解码器也是基于BiFormer块构建的。受swan - unet[35]的启发,我们也采用patch expansion layer对解码器中提取的深度特征进行上采样。patch expansion layer主要用于将feature map重塑为更高分辨率的feature map,即将feature map的分辨率提高2倍,将feature map的维数降低一半。最后一层进行4倍上采样,输出分辨率为H × W的特征图,用于预测像素级分割。
3.6 跳跃连接
与使用单一注意机制相比,通道注意和空间注意的结合可以增强模型捕捉更广泛的上下文特征的能力。
受[39]的启发,我们考虑将顺序通道空间注意机制应用于跳跃连接,因此提出了跳跃连接通道空间注意,简称SCCSA。SCCSA模块可以有效补偿下采样造成的空间信息损失,增强解码器各层多尺度特征的全局维度交互,从而在生成输出掩模的同时恢复细粒度细节。如图2(b)所示,SCCSA模块包括一个通道注意子模块和一个空间注意子模块。具体来说,我们首先通过连接编码器和解码器的输出来推导F1∈R h×w×2n。然后,信道注意子模块使用约简比为e = 4的多层感知器(MLP)的编码器-解码器结构放大跨维信道空间依赖性。我们使用两个7×7卷积层,以相同的信道注意缩减比e来关注空间信息子模块。给定输入特征映射x1, x2∈R h×w×n,则中间状态F1, F2, F3,则输出x3定义为:
F 1 = C o n c a t ( x 1 , x 2 ) , F_1=Concat(x_1,x_2), F1=Concat(x1,x2),
F 2 = σ ( F C ( R e L u ( F C ( F 1 ) ) ) ⊗ F 1 , F_2=\sigma(FC(\mathrm{Re}Lu(FC(F_1)))\otimes F_1, F2=σ(FC(ReLu(FC(F1)))⊗F1,
F 3 = σ ( C o n v ( Re L u ( B N ( C o n v ( F 2 ) ) ) ) ) ⊗ F 2 , F_3=\sigma(Conv(\text{Re}Lu(BN(Conv(F_2)))))\otimes F_2, F3=σ(Conv(ReLu(BN(Conv(F2)))))⊗F2,
x 3 = F C ( F 3 ) . x_{3}=FC(F_{3}). x3=FC(F3).
3.7 损失函数
在训练过程中,对于Synapse数据集,我们采用混合损失,结合骰子损失和交叉熵损失来解决与类不平衡相关的问题。对于ISIC2018和CVC-ClinicDB数据集,我们使用骰子损失来优化我们的模型。骰子损失(lice)、交叉熵损失(Lce)和混合损失(L)定义如下:
L d i c e = 1 − ∑ k K 2 ω k ∑ i N p ( k , i ) g ( k , i ) ∑ i N p 2 ( k , i ) + ∑ i N g 2 ( k , i ) , \mathcal{L}_{dice}=1-\sum_k^K\frac{2\omega_k\sum_i^Np(k,i)g(k,i)}{\sum_i^Np^2(k,i)+\sum_i^Ng^2(k,i)}, Ldice=1−k∑K∑iNp2(k,i)+∑iNg2(k,i)2ωk∑iNp(k,i)g(k,i),
L c e = − 1 N ∑ i = 1 N G ( k , i ) ⋅ log ( P ( k , i ) ) + ( 1 − G ( k , i ) ) ⋅ log ( 1 − P ( k , i ) ) , L = λ L d i c e + ( 1 − λ ) L c e , \begin{aligned} \mathcal{L}_{ce}& =-{\frac{1}{N}}\sum_{i=1}^{N}G(k,i)\cdot\log(P(k,i)) \\ &+(1-G(k,i))\cdot\log(1-P(k,i)), \\ &\mathcal{L}=\lambda\mathcal{L}_{dice}+(1-\lambda)\mathcal{L}_{ce}, \end{aligned} Lce=−N1i=1∑NG(k,i)⋅log(P(k,i))+(1−G(k,i))⋅log(1−P(k,i)),L=λLdice+(1−λ)Lce,
其中N为像素个数,G(k, i)∈(0,1),P(k, i)∈(0,1)分别表示k类的真值标签和生成概率。K为类数,滑K ωk = 1为所有类的权值和。λ是平衡lice和Lce影响的加权因子。在我们的研究中,ωk和λ分别被经验地设置为1 K和0.6。算法1总结了我们的BRAU-Net++的训练过程