快照及克隆
什么是快照
快照是数据存储的某一时刻的状态记录,也就是把虚拟机当前的状态保存下来(快照不是备份,快照保存的是状态,备份保存的是副本)
快照优点
速度快,占用空间小
快照工作原理
在了解快照原理前,首先需要知道两个概念:索引/数据和差分盘
索引和数据(index node / data block)
首先要了解,每一个文件系统都是有两部分组成的:索引和数据(index node / data block),
索引有时候也称为元数据metadata,如图:

index node 有时候也称为metadate(元数据),也叫元素,它是描述数据的数据,比如文件的名字,文件的大小,文件的权限,文件的指针(指针指向文件在硬盘上的物理位置)
所以,快照也叫:基于索引的快照(快照中只包含虚拟机磁盘文件的元数据,不包含真实的文件内容),元数据中只保存文件的描述信息和文件的指针,一个元数据占用256字节的空间大小,查找文件时,先读取文件的元数据,通过元数据的指针找到文件在硬盘的物理位置,从而找到文件。
总结一下:
metadate(元数据):文件的描述信息(文件的名字、大小、时间等及文件的指针:真实的物理数据在硬盘上的位置)
data block:真实的文件
举个不是太恰当的例子:比如有一张图片,放在硬盘上第三行第五列这个小格子内,我们想要打开这个文件,首先操作系统要先找到这个文件的索引(元数据metadate),我们这时可以看到这个文件名字叫“123.jpg”,大小是1MB等信息,当我们打开这个文件时,通过matedate中的指针,该指针指向了硬盘上第三行第五列这个小格子,操作系统找到这个小格子里的文件,从而可以打开文件让我们看到这个图片
差分盘
差分盘是一种与基础盘关联的磁盘类型,它记录了基础盘和自身之间的差异。具体来说,差分盘只存储了对基础盘的修改或增量数据,而不保存基础盘上已存在的数据。
创建快照其实就是创建了一块差分盘,当创建快照时,基础磁盘会置于只读状态,差分盘(快照空间)中会保留基础磁盘的索引信息,所以ROW快照后,虚拟机所有对磁盘的增删改查操作都会重定向到差分盘,从而不影响基础磁盘中已有的数据
计算快照(旧)
功能介绍
虚拟化计算层是基于KVM来实现的,KVM采用的是qcow2的磁盘格式,qcow2支持的快照方式为cow(写时复制),KVM在虚拟化计算层给qcow2打快照的时候,会将生成的快照空间一起保存在原有的qcow2文件中,在删除或恢复快照的时候调用底层的文件系统指令来清理qcow2文件中的快照空间
cow快照在写入(修改)数据时,IO会被放大三倍,更加消耗存储的IO性能,即需要将要修改的数据读出来,写到快照空间内,然后再将新的数据覆盖写到原位置,这样会带来写惩罚:一次写带来了更多的读操作
注意事项
1. 性能影响是因为KVM支持的COW快照技术导致的,打完快照之后数据写入的时候会放大IO(消耗存储的IO性能,新增数据不会对性能产生影响,修改数据时才会影响性能)
2. KVM的快照方案中,快照数据保存在原有的qcow2文件中,如果要满足删除快照对qcow2文件内快照区域进行清理,需要调用底层文件系统指令(如果底层使用ext3,ext4的文件系统,那就可以通过调用KVM的指令,来清除qcow2文件中的快照空间)
3. 深信服超融合使用的是自己开发的aSAN虚拟存储,aSAN文件系统的底层指令不支持删除qcow2文件中的快照空间,所以只能删除快照的索引数据
存储快照
深信服aSAN文件系统无法删除qcow2文件中的快照空间,为了解决这个问题,aSAN开发出了存储快照
存储快照就是在打快照的时候生成的快照空间,写在一个单独的qcow2文件里,而不是放在原来的qcow2文件里
存储快照在清理快照空间的时候,只需要将生成的qcow2文件删除掉即可
采用基于存储的快照方式
1. 采用ROW快照技术,减小对虚拟机性能的影响
2. aSAN底层支持删除快照时释放空间
注意事项
1. 存储快照只能存在于虚拟存储上,外置存储的虚拟机会使用老版本的快照方式
2. 两主机场景不支持存储快照及相关功能,包括快速克隆
COW快照原理(旧)
COW又叫写时复制(新增数据不会对性能产生影响,修改数据时才会影响性能)
1. 创建快照的时候,COW会为原虚拟磁盘创建一张数据指针表,用于保存原虚拟磁盘的物理指针
2. 然后在创建一张新的指针表,作为快照空间的指针表,快照空间的指针表会占用一部分的存储空间,用于保存快照后原虚拟磁盘中被更新的原数据
3. 当虚拟机要删改数据的时候,先将数据写到缓存里等待,等待存储系统先将删改的原数据复制到快照空间里,然后再将缓存中的数据覆盖写到原虚拟磁盘中的位置
4. 最后将虚拟磁盘和快照空间的数据指针对应写到一张映射表里
简单总结:
数据写入时,直接写到虚拟磁盘内,数据修改时,先把要修改的数据读出来,然后将读出来的数据写到快照空间内,然后把修改后的数据覆盖写入到虚拟磁盘原位置中,最后将虚拟磁盘和快照空间的数据指针保存到映射表中
快照后,数据写入(修改)流程
1. 在对虚拟机创建快照时,系统会生成一个动态增长的新磁盘文件(即快照空间)
2. 快照创建完成后,修改原数据时会先将原磁盘数据复制到快照空间里,然后再将缓存里的数据写到原磁盘文件中,最后将原虚拟磁盘和快照空间逻辑地址的对应关系写到映射表
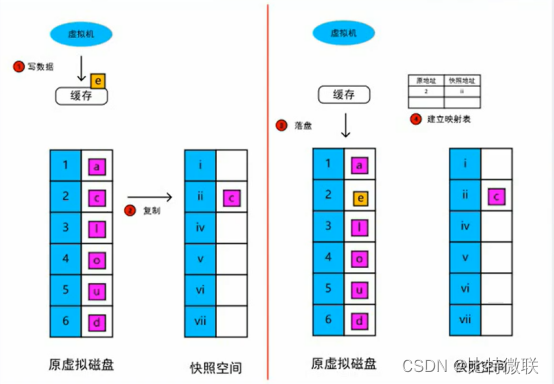
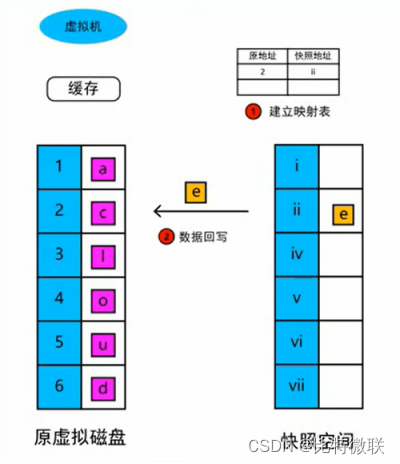
快照在写入数据时,为什么会放大IO?
如图,图上的蓝色部分是数据指针,白色部分是指针对应的存储空间,紫色和黄色表示的是数据块
此时,虚拟机要将【2】这里的数据块【c】修改为数据块【e】,【e】首先会被写到缓存里,存储系统将原来的【c】读出来,然后再复制到快照空间的【ii】位置,此时,数据经历了一次读和一次写。然后再将缓存里的数据【e】覆盖写到原虚拟磁盘,此时io又经历了一次写。
所以,快照后,数据IO会经历一次读和两次写,假设这个数据块是1KB,这已经有了3KB的数据量了,原本1KB的数据IO变为了3KB的数据IO,所以快照后写入数据会放大数据IO量
写入映射表的操作是写入地址指针,这个数据是非常小的,可以忽略掉
快照后数据读取流程
快照创建后,虚拟机读取数据时直接从原虚拟磁盘读取

虚拟机读取数据时,直接根据原虚拟磁盘的指针表读取即可,不用查询映射表和快照空间了,因为修改的数据都保存在原虚拟磁盘里了
如图,在原虚拟磁盘里,e已经是最新的数据了,所以在读的时候,只需要顺序的将aeioud读出来即可
快照恢复流程
快照恢复时,根据映射表将快照空间里的数据回写到原虚拟磁盘,然后删除快照空间
恢复快照后,原磁盘空间是打快照时的旧数据状态,快照删除后,虚拟机是新数据状态
1. 首先根据映射表,找到快照空间上的数据在原虚拟磁盘所对应的位置
2. 然后将数据回写到原虚拟磁盘上,覆盖掉修改后的数据,每一次回写的动作都会进行一次数据的读和数据的写
3. 数据全部回写完成后,再将快照空间和映射表删除掉

快照删除流程
删除快照时,直接删除快照空间以及地址映射表,即可保证当前虚拟机是最新数据的状态(快照内旧的数据也会跟着一起删除)

ROW快照原理(写时重定向)
快照后,数据写入流程
1. 在对虚拟机创建快照时,系统会将虚拟磁盘置为只读,并生成一个动态增长的新磁盘(即快照空间)
2. 快照创建完成后,该虚拟机的所有新增数据和对原数据的修改都写入到新生成的快照空间,并将原虚拟磁盘和快照空间逻辑地址的对应关系写入映射表
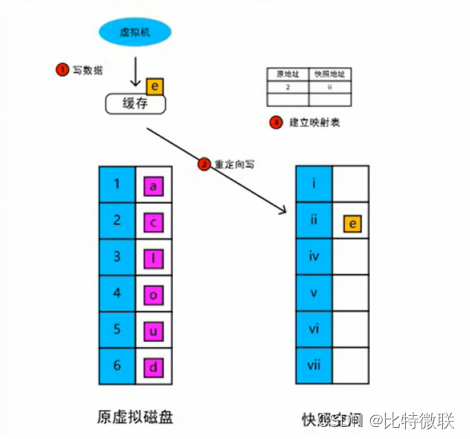
1. 在创建快照时,ROW首先会为原虚拟磁盘创建一张数据指针表,用于保存原虚拟磁盘的物理指针,如上图,蓝色的1-6即原虚拟磁盘的指针,然后将这张指针表的存储空间置为只读模式
2. 再创建一块空的指针表(上图右侧蓝色部分),作为快照空间的数据指针表,他会占用一部分存储空间,用于保存快照后更新的数据,在aSAN上,这块存储空间是动态分配的,并没有一个起始的默认大小,最大不会超过虚拟机配置的磁盘大小
3. 当要对原虚拟磁盘的数据进行删改时,会将删改后的数据写入到快照空间内,然后将原虚拟磁盘的地址指针和快照空间的地址指针对应的写到映射表里
4. 可以看到,ROW在写入的时候只有一次写入操作,只是进行了写、映射表的操作,记录地址的操作影响非常小,是可以忽略掉的
快照后数据读取流程
1. 若读取的数据是快照创建之前已有的数据,且创建快照后未进行修改,则从源虚拟磁盘读取
2. 若读取的数据是快照创建之后增/改的数据,则从快照空间读取
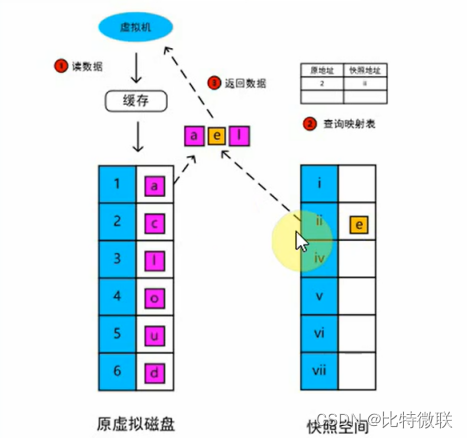
ROW在读数据时会有查询映射表的过程,是对地址指针的查询比起指针写入的影响会大一些,比起数据块的操作(覆盖写入)还是会小很多
快照恢复流程
快照恢复是要回到打快照时旧数据的状态,ROW的旧数据都保存在原虚拟磁盘里,所以快照恢复的时候直接删除快照空间和映射表即可

为什么快照恢复的时候要关闭虚拟机呢?
虚拟机运行的过程中,内存中的数据是会持续的往磁盘中写的,而快照恢复的过程中会对磁盘做回滚操作,不可能做到在新数据写入的同时还能回滚旧数据的
举个直观的例子,现在有一台虚拟机刚装好系统打了个快照然后安装了微信和QQ软件,在正常使用这些软件的时候,突然电脑中毒了,此时想要对虚拟机恢复快照,如果不关闭虚拟机,这些软件会一直向磁盘写数据,占用磁盘上的数据块,而恢复快照是要将这些软件整个给擦除掉,这时候就会发生冲突,现在的快照技术基本上都会将虚拟机重启,不然达不到快照恢复的目的了
快照删除流程
快照删除时,依照映射表将快照空间的数据进行回写,然后删除快照空间
由此可见,COW和ROW的快照删除正好相反,因为COW原虚拟磁盘记录的是新的数据状态,而ROW的原虚拟磁盘记录的是旧的数据状态
COW与ROW对比
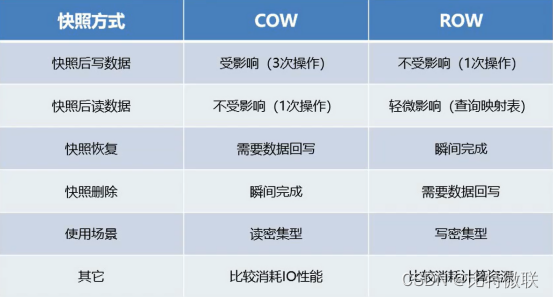
读密集型应用:web应用
写密集型应用:数据库应用
删除快照的四种情况
第一种情况
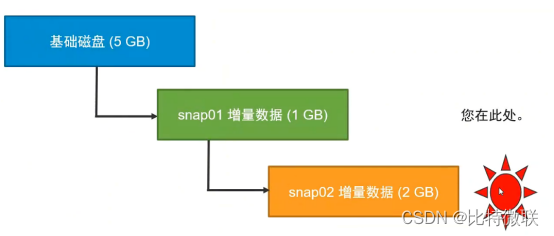
如图,虚拟机当前所处的位置为snap02,当删除snap01的快照时,snap01快照内的增量数据会合并到基础磁盘
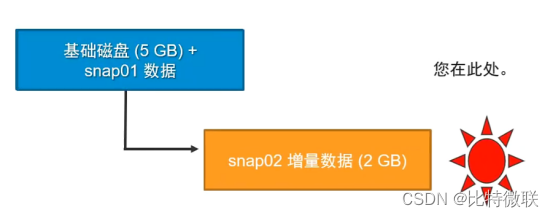
第二种情况
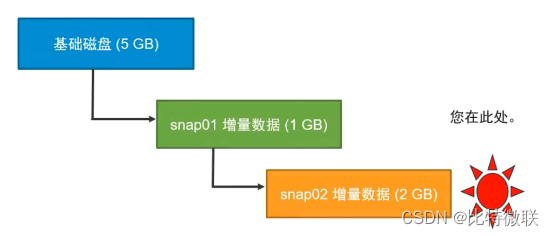
虚拟机当前在snap02的位置,当删除snap02的快照时,snap02内的增量数据会合并到快照1

第三种情况
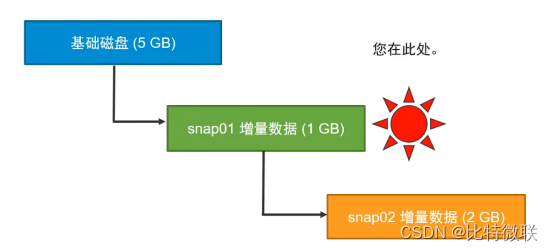
虚拟机当前在snap01的快照位置,删除snap02的快照,snap02的快照会直接删除,无需合并

第四种情况
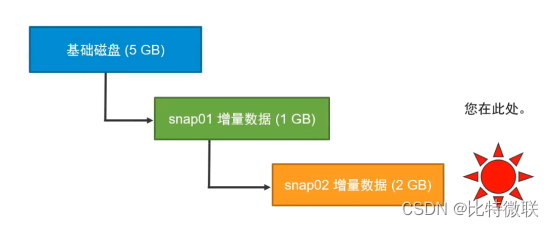
当前在snap02的快照位置,此时删除所有快照,snap02及以上位置快照内的增量数据都会合并到基础磁盘

ROW删除快照总结
- 删除当前位置的快照时,该快照内的增量数据会合并到母盘中
- 删除当前位置后面的快照时,后面位置快照空间内的数据会被直接删除,无需合并
快照删除问题
为什么创建快照后,在虚拟机内删除原本属于母盘的文件,快照还能恢复呢?(比如为什么把虚拟机格式化了后,快照还能恢复呢)
因为创建快照后,会将母盘置为只读模式,而快照是基于索引的快照,子盘中保存了母盘所有文件的索引,而快照后虚拟机所有的读写都来自子盘,当删除原本保存在母盘中的文件时,实际上并非真正的将文件删除,只是删除了快照中指向这个文件的索引,所以即使将文件删除,快照也能将该文件恢复
如果创建了多个快照空间,数据增删改查会怎样?
假设创建了两个快照,当前所处的位置在快照2,此时,图片上的原虚拟磁盘就是快照1,快照空间就是快照2,数据写入会写入到快照2所在的差分盘,数据读取也会从快照2内去读取,相当于是,快照1实际上是原虚拟磁盘的差分盘,但是又打了一个快照2,此时,快照1就相当于是快照2的母盘,快照2就是快照1的差分盘
一致性快照与内存快照
内存快照
保存内存的状态,可以保存内存当前的状态,但是占用磁盘空间大,如果虚拟机内存大小是8GB,那么在打内存快照时,8GB内存不管用没用完,内存快照都会将8GB的内存写入到快照
内存快照拍摄完成后,恢复快照会回到打快照那一刻的状态,也就是开机状态
注意:内存是实时变化的,内存快照只保留打快照那一刻的内存状态,后面的它不管
一致性快照
在创建快照前,强制将脏页写回硬盘,再创建快照,类似于执行了一条sync的命令后再打快照,虚拟机需要安装tools
一致性快照拍摄完成后,保留硬盘当前的状态,恢复快照后,虚拟机自动重新开机
什么是脏页
脏页也叫脏数据,数据在写入时,并不是直接写到硬盘,而是先写入到内存中,在内存中整合后再写到硬盘,已经在内存中改变还没有写到硬盘的数据叫脏数据
内存中的脏数据有30秒存活时间,30秒后数据会被写到硬盘
为什么需要延时30秒再写入硬盘:这样可以防止瞬间的高IO将磁盘占用率打满的情况
查看脏数据存活时间
sysctl -a | grep dirty
【vm.dirty_expire_centisecs = 3000】就是脏数据的存活时间,单位:百分之一秒

实时监控脏页:watch -n 1 'cat /proc/meminfo | grep Dirty',可以看到,当前有40KB的脏数据
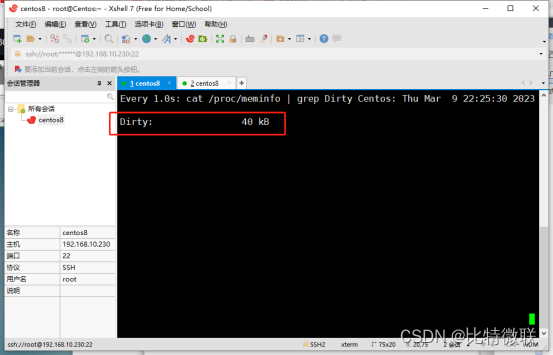
脏数据测试
首先查看当前系统的脏数据大小
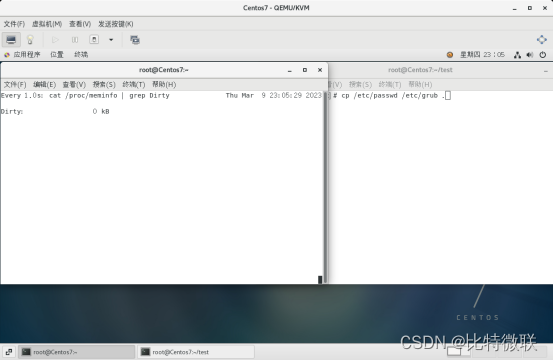
首先我们拷贝两个文件到家目录的test文件夹下,可以看到,脏数据变大了
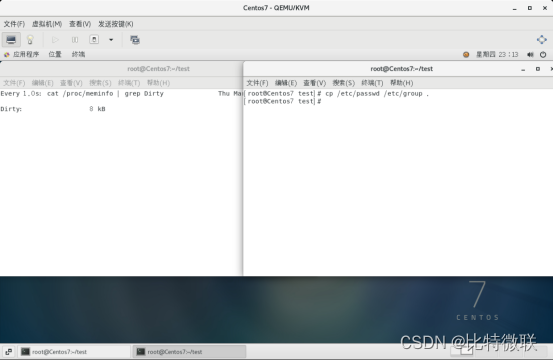
这时,我们在30秒内关闭虚拟机电源(非正常关机,正常关机的话脏数据会被写到硬盘),然后再开机,查看那两个文件是否已写入到硬盘,可以看到,数据并没有写到硬盘

执行sync命令可以强制将脏数据写到硬盘,可以看到,执行完sync后,脏页数据直接变为0kB了,此时就算在30秒内关闭虚拟机电源,数据也会被写到硬盘

差分盘体验
首先查看虚拟机的ID号和所属主机,ID号可以理解为系统给这个虚拟机起的名字,可以看到,这台虚拟机运行在CNA01上的
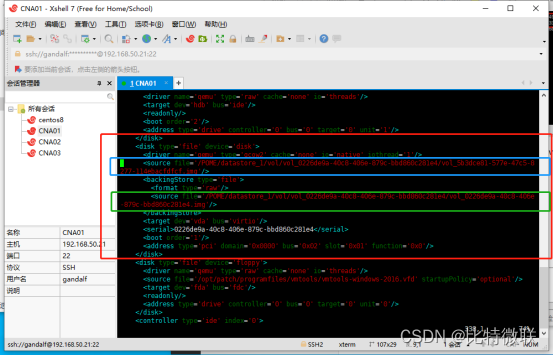
登录CNA01,进去KVM的配置目录 /etc/libvirt/qemu,可以看到这台虚拟机的配置文件
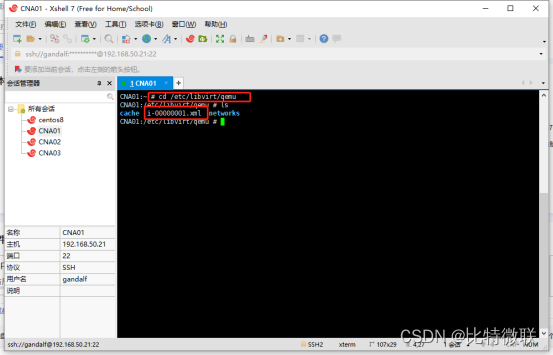
查看这个配置文件,找到虚拟机虚拟磁盘所处的目录,找到如图这一段</disk>开头,</disk>结尾,这一块括起来的中可以看到虚拟机虚拟磁盘文件所处的目录(蓝色框选出来的)
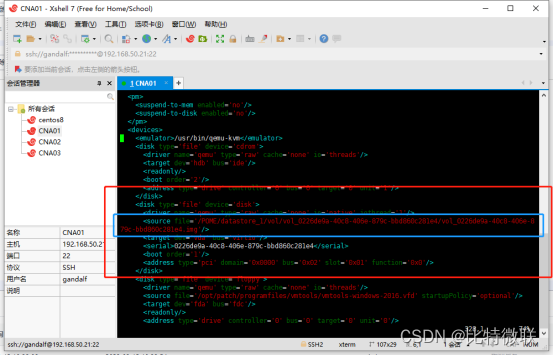
进入这个目录,可以看到虚拟机的虚拟磁盘
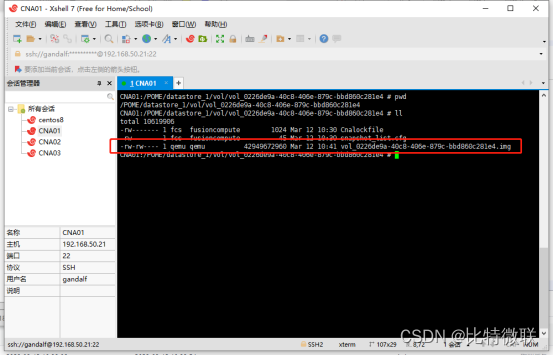
此时,我们给虚拟机打个快照
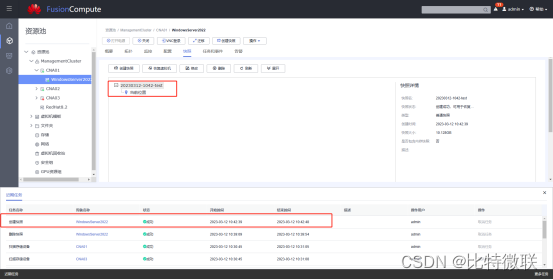
再看一下虚拟机虚拟磁盘所在目录,可以看到,虚拟机多了一块虚拟磁盘,这块虚拟磁盘就是差分盘,差分盘初始大小一般不会超过16MB,这16M中保存了母盘的文件索引
但是有个问题,所有的新数据都是写在快照后的差分盘中的,那虚拟机是怎么知道要往这块盘中写数据的呢
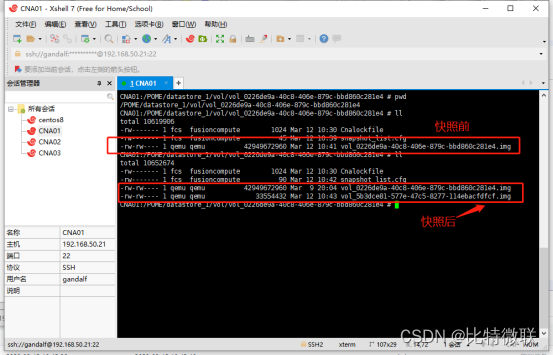
我们再来看一下虚拟机的配置文件(/etc/libvirt/qemu/xxxx.xml)
可以看到,当前虚拟机使用的磁盘就是刚刚的那块差分盘(蓝色),还可以看到这块差分盘的母盘(绿色),所以,虚拟机会把所有的新数据写入差分盘
此时所有的读写操作都是在这块差分盘中进行的,所以母盘对于虚拟机来说是只读模式
克隆
克隆分为链接克隆和完整克隆,完整克隆就是将虚拟机配置文件及磁盘文件(vmid会更改)完整复制,克隆出来的虚拟机与源虚拟机独立存在。
全量克隆:
全量克隆是指对原虚拟机数据进行一份完整的复制,数据复制完成后,克隆出来的虚拟机才能开机,克隆出来的虚拟机和原虚拟机是完全独立的,原虚拟机损坏不影响全量克隆出来的虚拟机
全量克隆特点:
- 克隆出来的虚拟机需要等数据复制完成之后才可以启动,时间取决于源虚拟机数据量大小
- 全量克隆出来的的虚拟机数据始终保持独立
- 克隆完成后虚拟机性能无任何影响
链接克隆使用的就是快照技术,同样会复制虚拟机的配置文件,但会生成差分盘作为克隆后虚拟机的磁盘,链接克隆的虚拟机依赖源虚拟机的磁盘文件。链接克隆的特点和全量克隆相反
克隆的作用
- 业务变更失败方便回退
- 业务测试(在测试业务时,如果新搭建测试环境场景有可能耗时较长,或和当前环境有差别,所以可以选择克隆来完全模拟测试环境)
- 改变磁盘模式等
虚拟机在克隆的时候,会自动创建一个快照
因为在克隆过程中,原虚拟机数据会持续变化,克隆时会自动生成快照,克隆是从快照中克隆,从而保持数据的一致性,当克隆完成后,系统会自动删除快照,快照中的数据会自动还原到基础磁盘中
模板
模板作用
- 批量部署虚拟机
- 制作模板流程:
- 安装OS,安装tools
- 安装所需的应用程序
- 将IP地址设置为DHCP方式
- 去除个性化信息(MAC地址,计算机名,SID)
WINDOWS自带去除个性化信息的程序 C:\Windows\System32\Sysprep\sysprep.exe
选择进入系统全新体验,勾选通用,选择关机,如果选择重新启动又会生成个性化 信息
- 虚拟机关机后,制作为模板
- 转换为模板:如,将虚拟机磁盘vhd格式转换为vhdx格式,源虚拟机不存在(模板也可以转换为虚拟机)
- 克隆为模板:通过该虚拟机创建一个新的模板,源虚拟机继续存在
- 导出为模板,将虚拟机导出为模板文件,方便导入到其他系统或留作备份