提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 1.Java 读写 ClickHouse API
- 1.1 首先需要加入 maven 依赖
- 1.2 Java 读取 ClickHouse 集群表数据
- JDBC--01--简介
- ClickHouse java代码
- 1.3 Java 向 ClickHouse 表中写入数据
- 2.Spark 写入 ClickHouse API
- 2.1 导入依赖
- 2.2 代码编写
- 3.Flink 写入 ClickHouse API
- 3.1 Flink 1.10.x 之前版本使用 flink-jdbc,只支持 Table API
- 3.2 Flink 1.11.x 之后版本使用 flink-connector-jdbc,只支持DataStream API
1.Java 读写 ClickHouse API
1.1 首先需要加入 maven 依赖
<!-- 连接 ClickHouse 需要驱动包-->
<dependency><groupId>ru.yandex.clickhouse</groupId><artifactId>clickhouse-jdbc</artifactId><version>0.2.4</version>
</dependency>
1.2 Java 读取 ClickHouse 集群表数据
JDBC–01–简介
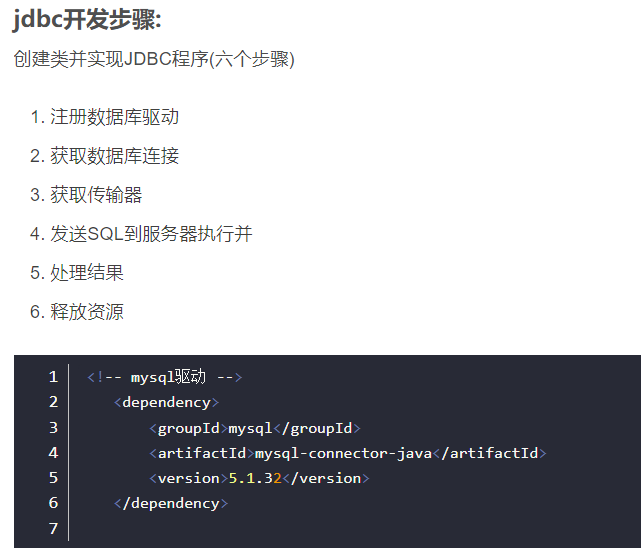
public class Test01 {public static void main(String[] args) throws Exception {//1.注册数据库驱动Class.forName("com.mysql.jdbc.Driver");//2.获取数据库连接Connection conn = DriverManager.getConnection( "jdbc:mysql://localhost:3306/jt_db?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf8","root", "root");//3.获取传输器Statement stat = conn.createStatement();//4.发送SQL到服务器执行并返回执行结果String sql = "select * from account";ResultSet rs = stat.executeQuery( sql );//5.处理结果while( rs.next() ) {int id = rs.getInt("id");String name = rs.getString("name");double money = rs.getDouble("money");System.out.println(id+" : "+name+" : "+money);}//6.释放资源rs.close();stat.close();conn.close();System.out.println("TestJdbc.main()....");}}ClickHouse java代码
import ru.yandex.clickhouse.BalancedClickhouseDataSource;
import ru.yandex.clickhouse.ClickHouseConnection;
import ru.yandex.clickhouse.ClickHouseStatement;
import ru.yandex.clickhouse.settings.ClickHouseProperties;import java.sql.ResultSet;
import java.sql.SQLException;public class test01 {public static void main(String[] args) throws SQLException {ClickHouseProperties props = new ClickHouseProperties();props.setUser("default");props.setPassword("");//1.注册数据库驱动配置BalancedClickhouseDataSource dataSource = new BalancedClickhouseDataSource("jdbc:clickhouse://node1:8123,node2:8123,node3:8123/default", props);//2.获取数据库连接ClickHouseConnection conn = dataSource.getConnection();//3.获取传输器ClickHouseStatement statement = conn.createStatement();//4.发送SQL到服务器执行并ResultSet rs = statement.executeQuery("select id,name,age from test");//5.处理结果while (rs.next()) {int id = rs.getInt("id");String name = rs.getString("name");int age = rs.getInt("age");System.out.println("id = " + id + ",name = " + name + ",age = " + age);}//6.释放资源conn.close();statement.close();rs.close();}
}1.3 Java 向 ClickHouse 表中写入数据
package com.cy.demo;import ru.yandex.clickhouse.BalancedClickhouseDataSource;
import ru.yandex.clickhouse.ClickHouseConnection;
import ru.yandex.clickhouse.ClickHouseStatement;
import ru.yandex.clickhouse.settings.ClickHouseProperties;import java.sql.ResultSet;
import java.sql.SQLException;public class test01 {public static void main(String[] args) throws SQLException {ClickHouseProperties props = new ClickHouseProperties();props.setUser("default");props.setPassword("");//1.注册数据库驱动配置BalancedClickhouseDataSource dataSource = new BalancedClickhouseDataSource("jdbc:clickhouse://node1:8123/default", props);//2.获取数据库连接ClickHouseConnection conn = dataSource.getConnection();//3.获取传输器ClickHouseStatement statement = conn.createStatement();//4.发送SQL到服务器执行并statement.execute("insert into test values (100,'王五',30)");//可以拼接批量插入多条//6.释放资源conn.close();statement.close();rs.close();}
}
2.Spark 写入 ClickHouse API
- SparkCore 写入 ClickHouse,可以直接采用写入方式。下面案例是使用 SparkSQL 将结果存入 ClickHouse对应的表中。在 ClickHouse 中需要预先创建好对应的结果表
2.1 导入依赖
<!-- 连接 ClickHouse 需要驱动包--><dependency><groupId>ru.yandex.clickhouse</groupId><artifactId>clickhouse-jdbc</artifactId><version>0.2.4</version><!-- 去除与 Spark 冲突的包 --><exclusions><exclusion><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId></exclusion><exclusion><groupId>net.jpountz.lz4</groupId><artifactId>lz4</artifactId></exclusion></exclusions></dependency><!-- Spark-core --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.3.1</version></dependency><!-- SparkSQL --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>2.3.1</version></dependency><!-- SparkSQL ON Hive--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.11</artifactId><version>2.3.1</version></dependency>
2.2 代码编写
val session: SparkSession =
SparkSession.builder().master("local").appName("test").getOrCreate()
val jsonList = List[String](
"{\"id\":1,\"name\":\"张三\",\"age\":18}",
"{\"id\":2,\"name\":\"李四\",\"age\":19}",
"{\"id\":3,\"name\":\"王五\",\"age\":20}"
)
//将 jsonList 数据转换成 DataSet
import session.implicits._
val ds: Dataset[String] = jsonList.toDS()
val df: DataFrame = session.read.json(ds)
df.show()
//将结果写往 ClickHouse
val url = "jdbc:clickhouse://node1:8123/default"
val table = "test"
val properties = new Properties()
properties.put("driver", "ru.yandex.clickhouse.ClickHouseDriver")
properties.put("user", "default")
properties.put("password", "")
properties.put("socket_timeout", "300000")
df.write.mode(SaveMode.Append).option(JDBCOptions.JDBC_BATCH_INSERT_SIZE, 100000).jdbc(url,
table, properties)
3.Flink 写入 ClickHouse API
- 可以通过 Flink 原生 JDBC Connector 包将 Flink 结果写入 ClickHouse 中,Flink 在1.11.0 版本对其 JDBC Connnector 进行了重构:
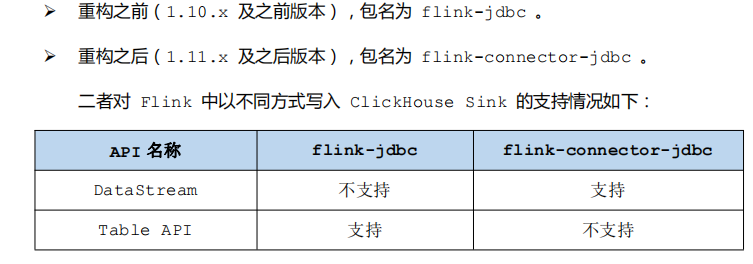
3.1 Flink 1.10.x 之前版本使用 flink-jdbc,只支持 Table API
- maven 中需要导入以下包:
<!--添加 Flink Table API 相关的依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.9.1</version>
</dependency>
<!--添加 Flink JDBC 以及 Clickhouse JDBC Driver 相关的依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-jdbc_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.2.4</version>
</dependency>
- 代码:
/**
* 通过 flink-jdbc API 将 Flink 数据结果写入到 ClickHouse 中,只支持 Table API
*
* 注意:
* 1.由于 ClickHouse 单次插入的延迟比较高,我们需要设置 BatchSize 来批量插入数据,提高性能。
* 2.在 JDBCAppendTableSink 的实现中,若最后一批数据的数目不足 BatchSize,则不会插入剩余数
据。
*/
case class PersonInfo(id:Int,name:String,age:Int)
object FlinkWriteToClickHouse1 {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度为 1,后期每个并行度满批次需要的条数时,会插入 click 中
env.setParallelism(1)
val settings: EnvironmentSettings =
EnvironmentSettings.newInstance().inStreamingMode().useBlinkPlanner().build()
val tableEnv: StreamTableEnvironment = StreamTableEnvironment.create(env,settings)
//导入隐式转换
import org.apache.flink.streaming.api.scala._
//读取 Socket 中的数据
val sourceDS: DataStream[String] = env.socketTextStream("node5",9999)
val ds: DataStream[PersonInfo] = sourceDS.map(line => {
val arr: Array[String] = line.split(",")
PersonInfo(arr(0).toInt, arr(1), arr(2).toInt)
})
//将 ds 转换成 table 对象
import org.apache.flink.table.api.scala._
val table: Table = tableEnv.fromDataStream(ds,'id,'name,'age)
//将 table 对象写入 ClickHouse 中
//需要在 ClickHouse 中创建表:create table flink_result(id Int,name String,age Int) engine =
MergeTree() order by id;
val insertIntoCkSql = "insert into flink_result (id,name,age) values (?,?,?)"
//准备 ClickHouse table sink
val sink: JDBCAppendTableSink = JDBCAppendTableSink.builder()
.setDrivername("ru.yandex.clickhouse.ClickHouseDriver")
.setDBUrl("jdbc:clickhouse://node1:8123/default")
.setUsername("default")
.setPassword("")
.setQuery(insertIntoCkSql)
.setBatchSize(2) //设置批次量,默认 5000 条
.setParameterTypes(Types.INT, Types.STRING, Types.INT)
.build()
//注册 ClickHouse table Sink,设置 sink 数据的字段及 Schema 信息
tableEnv.registerTableSink("ck-sink",
sink.configure(Array("id", "name", "age"),Array(Types.INT, Types.STRING, Types.INT)))
//将数据插入到 ClickHouse Sink 中
tableEnv.insertInto(table,"ck-sink")
//触发以上执行
env.execute("Flink Table API to ClickHouse Example")
}
}
3.2 Flink 1.11.x 之后版本使用 flink-connector-jdbc,只支持DataStream API
- 在 Maven 中导入以下依赖包
<!-- Flink1.11 后需要 Flink-client 包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.11.3</version>
</dependency>
<!--添加 Flink Table API 相关的依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>1.11.3</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>1.11.3</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.11.3</version>
</dependency>
<!--添加 Flink JDBC Connector 以及 Clickhouse JDBC Driver 相关的依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>1.11.3</version>
</dependency>
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.2.4</version>
</dependency>
- 代码
/**
* Flink 通过 flink-connector-jdbc 将数据写入 ClickHouse ,目前只支持 DataStream API
*/
object FlinkWriteToClickHouse2 {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度为 1
env.setParallelism(1)
import org.apache.flink.streaming.api.scala._
val ds: DataStream[String] = env.socketTextStream("node5",9999)
val result: DataStream[(Int, String, Int)] = ds.map(line => {
val arr: Array[String] = line.split(",")
(arr(0).toInt, arr(1), arr(2).toInt)
})
//准备向 ClickHouse 中插入数据的 sql
val insetIntoCkSql = "insert into flink_result (id,name,age) values (?,?,?)"
//设置 ClickHouse Sink
val ckSink: SinkFunction[(Int, String, Int)] = JdbcSink.sink(
//插入数据 SQL
insetIntoCkSql,
//设置插入 ClickHouse 数据的参数
new JdbcStatementBuilder[(Int, String, Int)] {
override def accept(ps: PreparedStatement, tp: (Int, String, Int)): Unit = {
ps.setInt(1, tp._1)
ps.setString(2, tp._2)
ps.setInt(3, tp._3)
}
},
//设置批次插入数据
new JdbcExecutionOptions.Builder().withBatchSize(5).build(),
//设置连接 ClickHouse 的配置
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withDriverName("ru.yandex.clickhouse.ClickHouseDriver")
.withUrl("jdbc:clickhouse://node1:8123/default")
.withUsername("default")
.withUsername("")
.build()
)
//针对数据加入 sink
result.addSink(ckSink)
env.execute("Flink DataStream to ClickHouse Example")
}
}