【大模型 数据增强】LLMAAA:使用 LLMs 作为数据标注器
- 提出背景
- 算法步骤
- 1. LLM作为活跃标注者(LLMAAA)
- 2. k-NN示例检索与标签表述化
- 3. 活跃学习策略
- 4. 自动重权技术
- LLMAAA 框架
- 1. LLM Annotator
- 2. Active Acquisition
- 3. Robust Training
- 总结
- LLMAAA = 提示工程优化 + 活跃数据获取策略 + 鲁棒训练机制
提出背景
论文:https://arxiv.org/pdf/2310.19596.pdf
代码:https://github.com/ridiculouz/LLMAAA
以医学文献的实体识别为例,假设我们需要从医学论文中自动识别出药物名称、疾病和治疗方法等实体。
这些实体对于构建医学知识库、推进药物发现和支持临床决策等方面至关重要。
然而,手动标注这些实体通常是时间消耗大且成本高昂的,特别是考虑到专业知识的需求。
在这种情况下,LLMAAA 能自动化标注数据。
-
数据准备:
- 收集一批未标注的医学研究文献。
-
提示工程:
- 设计提示指令,告诉LLM如何识别文本中的医学实体。
- 例如:“识别以下段落中所有的药物名称和疾病”。
-
活跃学习样本选择:
- 使用活跃学习算法从大量未标注的文献中选择最有可能包含重要实体的段落。
-
LLM生成伪标注:
- 利用LLM和设计好的提示对选中的段落进行伪标注。
-
自动重权和微调:
- 应用自动重权技术,根据LLM标注的可信度调整每个标注样本的权重。
- 使用伪标注的数据微调一个特定于实体识别的模型。
-
人工审核和模型迭代:
- 人工审核一小部分LLM生成的伪标注,以评估和改进标注质量。
- 基于人工审核的结果迭代改进提示和微调模型。
-
模型应用:
- 将训练好的模型应用于新的医学文献集合,自动提取相关实体,支持进一步的医学研究和分析。
通过这个过程,LLMAAA框架能够有效地减少手动标注所需的专业人力和时间,同时提高了数据标注的覆盖率和质量,加速了医学知识的整理和应用。
算法步骤
LLMAAA框架结合了活跃学习和大型语言模型(LLM)的能力来自动化数据标注的过程。
1. LLM作为活跃标注者(LLMAAA)
这个过程的目的是让LLM在数据标注中起到积极作用,而不是被动地对大量数据进行标注。
- 活跃数据获取:通过活跃学习机制,系统会评估哪些未标注的数据最有可能提升模型的性能。
- 生成伪标签:一旦确定了哪些数据最有价值,LLM会对这些数据生成伪标签,作为初始的标注结果。
活跃学习让模型在训练过程中有选择性地识别哪些数据最有价值,即对于改善模型性能最有帮助的数据。
活跃学习尤其适用于标注数据稀缺或标注成本高昂的场景。
活跃学习算法通常步骤:
-
选择样本:算法从未标注的数据池中选择一批样本。这些样本是基于某种标准挑选的,比如模型对它们的预测不确定性很高,或者样本能够最大程度地增加模型的多样性。
-
人工标注:这些选定的样本将被人工标注。在一些情况下,可以使用半自动的方法,先由机器生成伪标签,然后由人类专家进行验证和修正。
-
更新模型:一旦样本被标注,模型就用这些新数据进行更新训练。
-
迭代:上述过程反复进行,每次迭代都选择新的样本进行标注和训练,直到模型性能达到满意的水平或者资源耗尽。
活跃学习的优势在于它可以显著减少所需进行手动标注的数据量,从而节约时间和成本,同时在很多情况下还能保持或提高模型的性能。
2. k-NN示例检索与标签表述化
在标注过程中,为了提高LLM生成的标注质量,可以使用以下方法:
- k-NN示例检索:选取与当前需要标注的数据点在内容上最接近的k个已标注的示例,这有助于LLM更好地理解上下文和预期的输出格式。
- 标签表述化:将抽象的标签(如类别代码)转换成自然语言描述。例如,在医学影像标注中,将“肿瘤”标签转换为详细的描述,如“圆形阴影在右上肺叶”。
假设我们的目标是自动标注一组胸部X光图像,识别图中是否存在肺部疾病,如肺炎、肿瘤等。这个任务对于支持医生快速诊断至关重要。
步骤1: k-NN示例检索
- 创建示例数据库:首先,收集一批已经由放射科医生手动标注的胸部X光图像。这些图像被标注了不同的肺部疾病类型,包括肺炎、肿瘤等。
- 计算相似度:对于每张待标注的X光图像,系统利用图像处理算法(如基于深度学习的特征提取)计算其与示例数据库中每张图像的相似度。
- 选择最接近的示例:基于相似度评分,为每张待标注的图像选择k个最相似的已标注图像作为参考。
步骤2: 标签表述化
- 标签转换为描述:对于示例数据库中的每种肺部疾病标签,创建详细的自然语言描述。例如,肿瘤标签对应的描述可能是“图像中显示了肺部的不规则圆形阴影,边界清晰,可能是肿瘤的迹象”。
- 利用描述进行标注:当LLM对待标注的X光图像进行分析时,将这些自然语言描述作为提示,引导模型生成更精确的诊断标注。
假设有一张待标注的胸部X光图像显示了右上肺叶的圆形阴影。
通过k-NN示例检索,系统找到了几张具有相似特征的已标注图像,这些图像被标注为显示肿瘤存在。
接着,利用标签表述化技术,LLM得到提示:“如果图像中显示肺部的不规则圆形阴影,请标注为肿瘤。”
依据这些信息,LLM预测待标注图像显示的是肿瘤。
通过这种方式,k-NN示例检索和标签表述化技术共同提高了LLM在医学影像标注任务上的性能,帮助模型以更人性化、更准确的方式理解和描述医学图像中的病变,从而为医生的诊断提供辅助信息。
3. 活跃学习策略
活跃学习策略是整个框架的核心,它决定了哪些数据被选中进行标注以提高模型的性能。
活跃学习让模型在训练过程中有选择性地识别哪些数据最有价值,即对于改善模型性能最有帮助的数据。
那什么是最有帮助的数据:
- 不确定性最大化
- 多样性最大化
-
不确定性最大化(特征1)
- 描述:选择那些模型预测结果最不确定的样本。
- 这些样本往往能为模型提供最多的信息,因为模型对它们的预测缺乏信心,学习这些样本能显著提升模型的性能。
- 实施方法:计算每个样本的预测不确定性(例如,通过概率分布的熵值)并选择不确定性最高的样本进行标注。
-
多样性最大化(特征2)
- 描述:确保选中的样本集在特征空间上具有广泛的覆盖范围。
- 这样做可以让模型接触到数据分布的不同区域,增强其泛化能力。
- 实施方法:采用聚类算法(如k-means)对未标注的数据进行聚类,然后从每个聚类中选择代表性样本,或者直接基于特征空间的分布来选择样本,以保证样本的多样性。
- 代表性样本选择(隐藏特征)
- 描述:除了考虑不确定性和多样性外,还需要考虑样本的代表性,即选择那些能够代表数据整体分布的样本。
- 实施方法:结合不确定性和多样性指标,使用加权方法来评估每个样本的综合价值,确保选中的样本既有高不确定性,又能代表数据的整体分布。
4. 自动重权技术
由于伪标签可能包含噪声,需要一种方法来减少这些标注错误对模型训练的影响。
- 元学习优化:自动重权技术通过元学习框架来优化标注样本的权重。模型在小规模的验证集上测试,以评估哪些数据点的标注最可能是错误的。
- 权重调整:根据验证集上的性能,自动调整每个数据点在训练过程中的权重,从而减少噪声数据的影响。
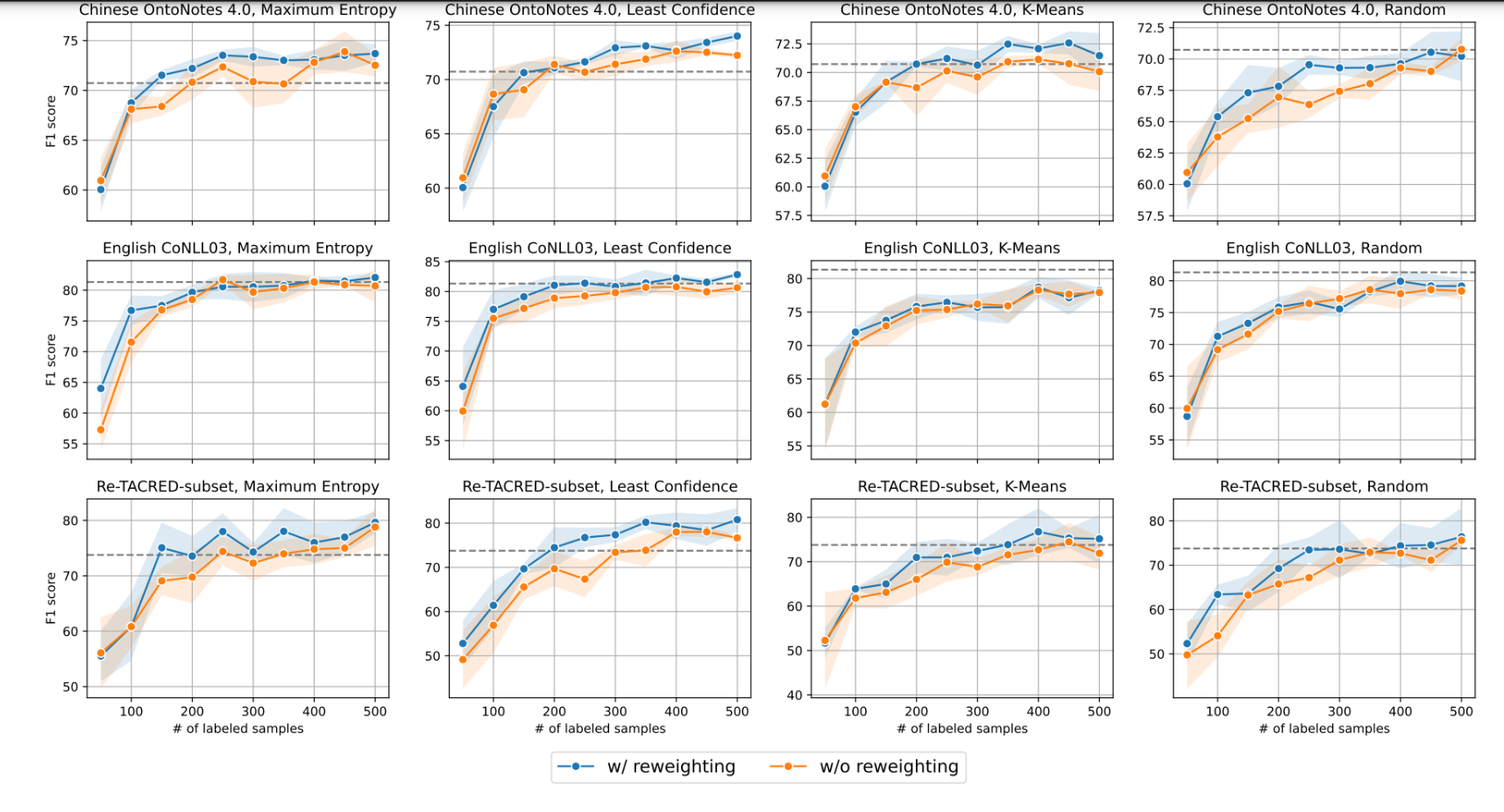
使用重权技术(w/ reweighting)与不使用重权技术(w/o reweighting)时的F1分数变化。
虚线代表了使用传统提示方法的性能。
可以看出,使用自动重权技术通常会带来性能的提升。
LLMAAA 框架
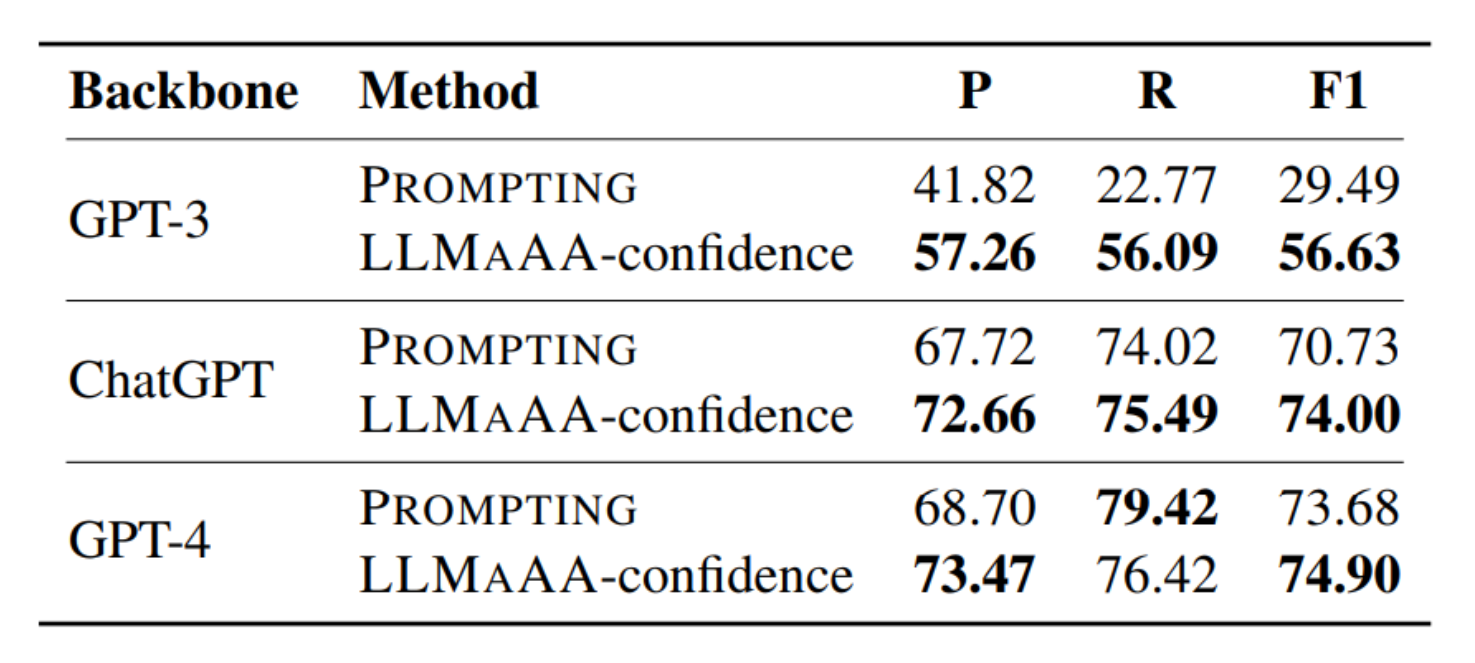
使用不同版本的大型语言模型(如GPT-3, ChatGPT, GPT-4)进行中文OntoNotes 4.0数据集上的命名实体识别(NER)任务时,LLMAAA框架与传统提示方法(PROMPTING)的性能对比。
表格中的"P", “R”, "F1"分别代表精确度(Precision)、召回率(Recall)、和F1分数,这些是衡量模型性能的标准指标。
LLMAAA框架在提高F1分数方面表现出明显优势,这表明了它在标注数据时的高效性和准确性。
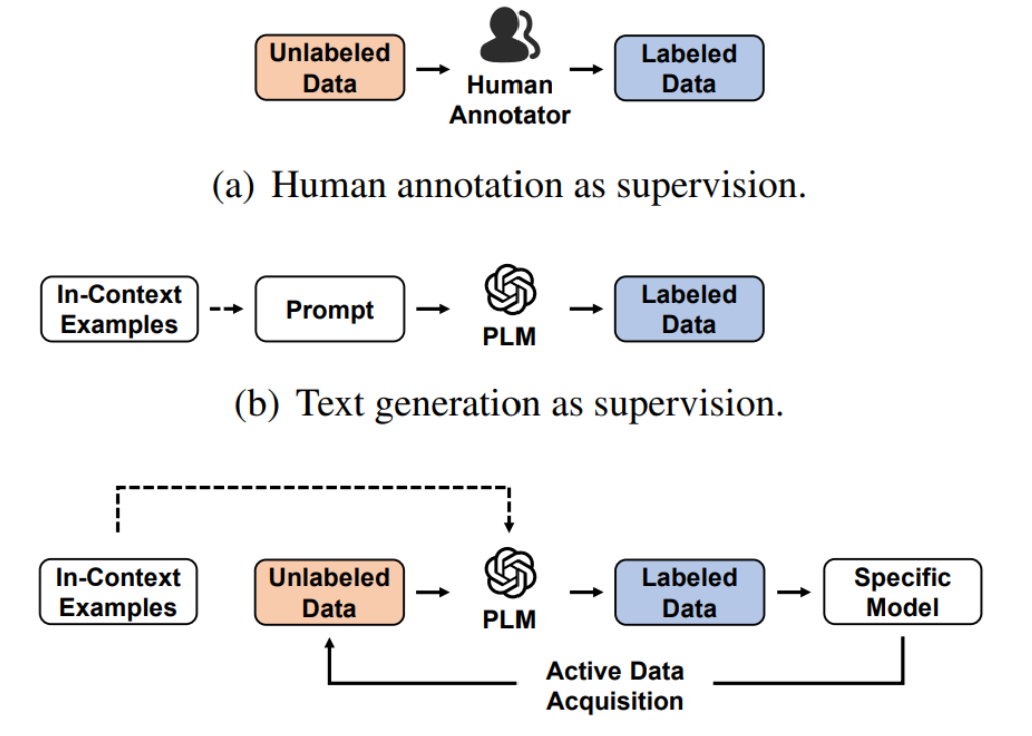
这张图,它比较了LLMAAA与其他框架的不同:
-
(a) Human annotation as supervision:这个部分展示了传统的人工注释流程,即人类注释者将未标注数据转换为标注数据。
-
(b) Text generation as supervision:这个部分显示了一个使用语言模型进行文本生成作为监督的过程。这里,给定上下文示例和提示,预训练的语言模型(PLM)生成标注数据。
-
© LLMAAA: Active LLM annotation as supervision:此部分具体展示了LLMAAA框架的流程。
这个过程利用活跃数据获取来指导语言模型注释未标注数据,生成的标注数据随后用于训练特定任务模型。这个框架强调了用于提高效率的活跃学习元素,减少了人类努力的需要。
两幅图表共同强调了LLMAAA方法相比传统人工注释和简单的文本生成方法,能够有效提升数据注释的效率和质量,同时减少对人工注释的依赖。
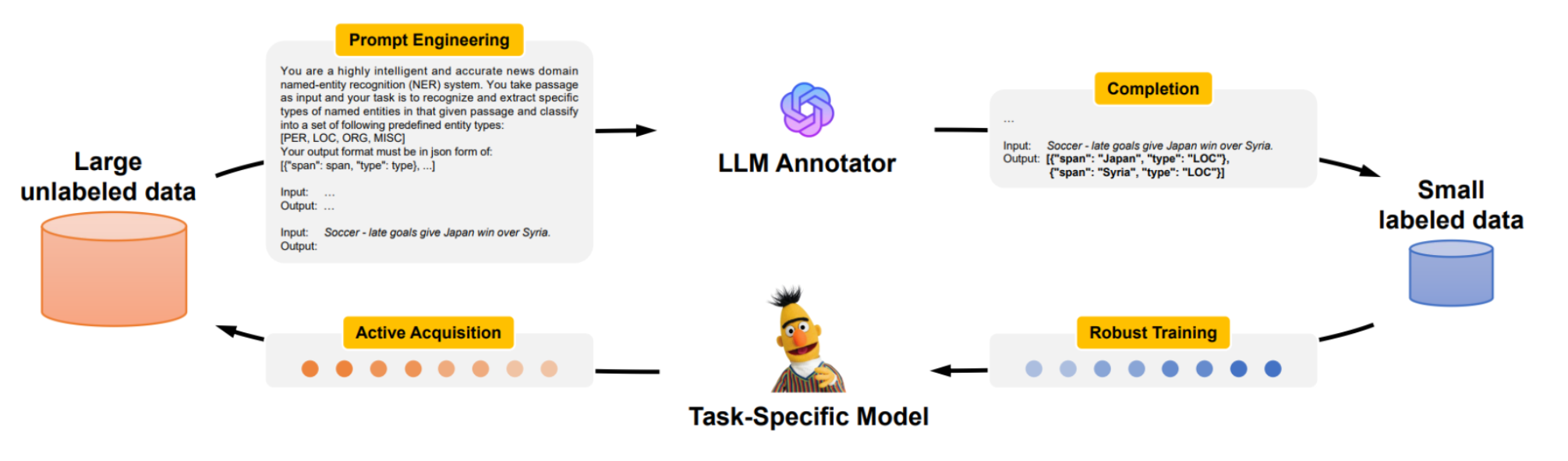
此图展示了LLMAAA(LLM作为活跃注释者)的整体架构和工作流程,它主要由以下三个部分组成:
-
LLM Annotator:这个部分说明了如何利用提示工程来优化LLM的注释器,使其能够生成伪标签。
提示工程:利用精心设计的提示来优化LLM的输出,使其能够针对特定任务生成高质量的伪标签。
上下文示例利用:通过提供相关的上下文示例来辅助LLM更好地理解任务需求和数据特点。
-
Active Acquisition:这个部分描述了一种有效的数据选择机制。
数据价值评估:对大量未标注的数据进行评估,识别出对模型性能提升最有帮助的数据。
策略性数据选择:基于模型的不确定性或数据的多样性来选择最有价值的数据进行标注,而不是随机选择。
-
Robust Training:最后,它强调了自动重权技术以确保在噪声标签存在的情况下也能进行稳健的学习。
这样的训练过程考虑到了标签质量可能不一,且通过重权技术调整学习过程,减少噪声的影响。
自动重权技术:利用元学习框架对标注样本的权重进行动态调整,以应对标注中的噪声问题。
标签质量适应性学习:根据模型在验证集上的表现来调整权重,优先训练那些标注质量高的数据。
举个例子。
目标是使用LLMAAA框架自动标注医学影像数据集,如X射线或MRI扫描图像,以识别出不同类型的病变(比如肿瘤、骨折等)。
1. LLM Annotator
- 提示工程:设计提示来指导LLM识别和标注医学影像中的特定病变。例如,提示可能是“在这张X射线图像中识别所有可见的肿瘤,并描述它们的位置和大小”。
- 上下文示例利用:提供一些已经由医学专家标注的影像作为示例。这些示例帮助LLM理解肿瘤在医学影像中的典型外观和如何准确描述它们的位置和大小。
2. Active Acquisition
- 数据价值评估:使用一个初始的、简单的医学影像分析模型来评估未标注影像的价值。挑选出这个模型最不确定的影像,即那些模型难以判断病变类型的影像。
- 策略性数据选择:选择这些高不确定性的影像进行LLM标注,因为这些影像提供了最大的学习机会,有助于快速提升模型性能。
3. Robust Training
- 自动重权技术:在得到LLM标注的影像后,可能存在一些标注错误或不准确的情况。使用自动重权技术,根据一个小的、已经由医学专家准确标注的验证集来动态调整每张影像的权重。这样可以减少错误标注的影响。
- 标签质量适应性学习:如果模型在验证集上对某些LLM标注的影像表现不佳,这些影像的权重会被降低,从而优先训练那些标注质量更高的数据。
在实际应用中,这个过程可以帮助医学影像分析系统快速学习和适应新的、未见过的病变类型,特别是在数据标注资源有限的情况下。
例如,如果新出现了一种肿瘤类型,系统可以通过上述流程迅速集成这类肿瘤的识别能力,从而提升整个医学影像分析系统的准确性和鲁棒性。
总结
LLMAAA = 提示工程优化 + 活跃数据获取策略 + 鲁棒训练机制
-
提示工程优化(Prompt Engineering Optimization)
- 特征1:任务定制提示 - 设计与特定任务紧密相关的提示,来引导LLM的输出。
- 特征2:上下文示例 - 提供与任务相关的上下文示例,辅助LLM理解任务目标。
-
活跃数据获取策略(Active Data Acquisition Strategy)
- 特征1:数据价值评估 - 使用算法评估未标注数据的价值,以确定哪些数据可能最有助于提高模型性能。
- 特征2:策略性样本选择 - 基于价值评估选择样本,而不是随机选择,确保标注工作集中在可能带来最大性能提升的数据上。
-
鲁棒训练机制(Robust Training Mechanism)
- 特征1:自动重权技术 - 在训练过程中应用元学习算法自动调整数据样本的权重,以解决伪标签噪声问题。
- 特征2:标签质量适应性学习 - 调整权重以偏好那些与验证集上高质量标注一致的样本,优化模型对于高质量数据的学习。