Pandas:DataFrame的完整指南
Pandas是Python中最流行的数据处理库之一,而其中的DataFrame对象是数据处理的核心。DataFrame为我们提供了一个强大而灵活的数据结构,使得数据的清洗、分析和可视化变得更加简便。在本文中,我们将深入探讨Pandas DataFrame对象的基础知识,并提供实际代码示例和详细解析,帮助读者更好地理解和运用DataFrame。

1. DataFrame简介
DataFrame是一种二维的表格型数据结构,类似于电子表格或SQL表。它由行和列组成,每列可以是不同的数据类型。Pandas中的DataFrame可以看作是由多个Series组成的字典,每个Series共享同一个索引。
代码示例1: 创建DataFrame
import pandas as pd# 创建一个简单的DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['New York', 'San Francisco', 'Los Angeles']}df = pd.DataFrame(data)
print(df)
代码解析1:
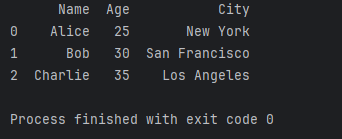
以上代码创建了一个包含姓名、年龄和城市的简单DataFrame。我们使用了Pandas的DataFrame构造函数,并将一个包含字典的数据结构传递给它。结果是一个美观的表格,每列都有对应的列名。
2. 基本操作
DataFrame提供了丰富的基本操作,包括索引、切片、过滤和排序等功能,使得我们可以高效地对数据进行处理。
代码示例2: DataFrame基本操作
# 选择一列
ages = df['Age']# 选择多列
subset = df[['Name', 'City']]# 使用条件过滤行
filtered_df = df[df['Age'] > 30]# 按特定列排序
sorted_df = df.sort_values(by='Age')# 添加新列
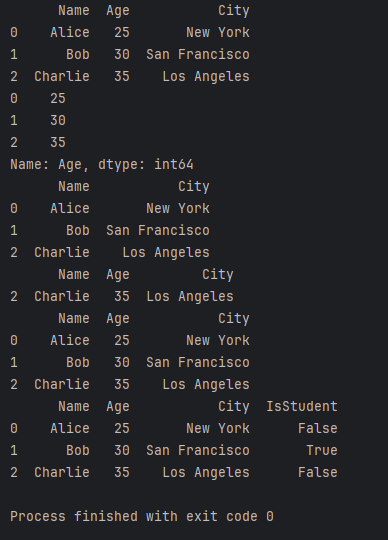
df['IsStudent'] = [False, True, False]print(ages)
print(subset)
print(filtered_df)
print(sorted_df)
print(df)
代码解析2:
以上代码演示了一些常见的DataFrame操作。我们可以通过列名选择特定列,也可以使用条件过滤行。此外,DataFrame还支持按列进行排序,并且可以轻松地添加新列。
3. 数据清洗
在现实应用中,数据往往不够干净。Pandas提供了许多功能来处理缺失值、重复数据和异常值。
代码示例3: 数据清洗
# 添加缺失值
df.loc[1, 'Age'] = None# 删除含有缺失值的行
df_cleaned = df.dropna()# 填充缺失值
df_filled = df.fillna({'Age': df['Age'].mean()})# 删除重复行
df_no_duplicates = df.drop_duplicates()print(df_cleaned)
print(df_filled)
print(df_no_duplicates)
代码解析3:
上述代码展示了如何处理缺失值、填充缺失值、以及去除重复行。这些功能在数据清洗过程中非常实用,确保我们的数据质量得到维护。
4. 数据分组和聚合
Pandas提供了强大的分组和聚合功能,使得我们可以对数据进行更高层次的分析。
代码示例4: 数据分组和聚合
# 按城市分组,并计算每个城市的平均年龄
grouped_df = df.groupby('City')['Age'].mean()# 多个聚合操作
agg_df = df.groupby('City').agg({'Age': ['mean', 'min', 'max'], 'IsStudent': 'sum'})print(grouped_df)
print(agg_df)
代码解析4:
上述代码展示了如何使用groupby方法进行数据分组,以及如何对每个分组应用不同的聚合操作。这使得我们能够更深入地了解数据的特征和统计信息。
通过本文的介绍,读者将对Pandas DataFrame的基础知识有了全面的了解。DataFrame不仅提供了对数据的灵活处理能力,而且在数据分析和可视化中发挥了关键作用。深入研究DataFrame的基础知识,将为进一步探索数据科学和机器学习打下坚实基础。希望本文能够对读者有所启发,提升在数据处理领域的技能水平。
5. 数据可视化
Pandas DataFrame结合其他可视化库,如Matplotlib和Seaborn,提供了强大的数据可视化功能,帮助用户更直观地理解数据分布和趋势。
代码示例5: 数据可视化
import matplotlib.pyplot as plt
import seaborn as sns# 创建一个简单的DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['New York', 'San Francisco', 'Los Angeles']}df = pd.DataFrame(data)# 绘制年龄分布直方图
plt.figure(figsize=(8, 5))
sns.histplot(df['Age'], bins=20, kde=True, color='skyblue')
plt.title('Age Distribution')
plt.xlabel('Age')
plt.ylabel('Count')
plt.show()
代码解析5:
上述代码展示了如何使用Matplotlib和Seaborn进行简单的数据可视化。我们绘制了年龄分布的直方图,以便更好地理解数据的分布情况。
6. 数据读取与存储
Pandas支持多种数据格式的读取和存储,包括CSV、Excel、SQL等,使得数据的导入和导出变得非常方便。
代码示例6: 数据读取与存储
# 将DataFrame保存为CSV文件
df.to_csv('data.csv', index=False)# 从CSV文件读取数据
df_read = pd.read_csv('data.csv')print(df_read)
代码解析6:
上述代码演示了如何将DataFrame保存为CSV文件,并从CSV文件读取数据。这对于在不同项目和平台之间共享数据非常有用。
通过深入学习Pandas DataFrame的基础知识,我们可以更好地应对数据处理和分析的挑战。从创建和操作DataFrame到数据清洗、分组聚合,再到数据可视化和文件读写,这些都是数据科学家和分析师日常工作中不可或缺的技能。希望本文的代码示例和解析能够帮助读者更加深入地理解Pandas DataFrame,并在实际项目中灵活应用这些技能。
7. 索引操作和重塑
DataFrame中的索引操作是非常重要的,它允许我们按照不同的方式组织和访问数据。同时,重塑操作可以改变数据框的形状,使得数据更适合特定的分析需求。
代码示例7: 索引操作和重塑
# 设置新的索引
df.set_index('Name', inplace=True)# 重置索引
df_reset = df.reset_index()# 堆叠和展开数据
stacked_df = df.stack()
unstacked_df = stacked_df.unstack()print(df)
print(df_reset)
print(stacked_df)
print(unstacked_df)
代码解析7:
上述代码演示了如何设置新的索引、重置索引,以及如何使用stack和unstack方法进行数据的堆叠和展开。这对于处理多层次索引和多维数据非常有用。
8. 合并和连接数据框
在实际数据处理中,常常需要将多个数据框合并或连接在一起,以便进行更全面的分析。
代码示例8: 合并和连接数据框
# 创建第二个数据框
data2 = {'Name': ['David', 'Eva', 'Frank'],'Salary': [50000, 60000, 70000]}df2 = pd.DataFrame(data2)# 合并数据框
merged_df = pd.merge(df, df2, on='Name', how='inner')print(merged_df)
代码解析8:
上述代码展示了如何使用merge函数按照指定的列将两个数据框合并。参数on指定了合并的列,而参数how指定了合并的方式,这里使用了内连接(inner join)。
通过学习索引操作、重塑、以及合并和连接数据框,我们能够更加灵活地处理不同形状和来源的数据,为复杂的数据分析任务提供了便利。
9. 时间序列数据处理
Pandas在处理时间序列数据时也表现出色。DataFrame提供了丰富的时间处理功能,使得对时间序列数据的分析和操作变得更加便捷。
代码示例9: 时间序列数据处理
# 创建包含日期的DataFrame
date_rng = pd.date_range(start='2024-01-01', end='2024-01-05', freq='D')
time_series_df = pd.DataFrame(date_rng, columns=['date'])# 添加随机数据
time_series_df['value'] = [10, 15, 20, 18, 25]# 将日期列设置为索引
time_series_df.set_index('date', inplace=True)# 按月份进行重采样
monthly_resampled = time_series_df.resample('M').mean()print(time_series_df)
print(monthly_resampled)
代码解析9:
上述代码演示了如何使用Pandas处理时间序列数据。我们首先创建了一个包含日期的DataFrame,然后将日期列设置为索引。最后,通过resample方法按月份对数据进行重采样,计算每月的均值。
10. 使用Apply函数进行自定义操作
Pandas的apply函数是一种强大的工具,允许我们对数据框的行或列应用自定义函数,从而实现更灵活的数据处理。
代码示例10: 使用Apply函数进行自定义操作
# 创建包含数字的DataFrame
numeric_df = pd.DataFrame({'A': [1, 2, 3, 4],'B': [5, 6, 7, 8],'C': [9, 10, 11, 12]
})# 定义一个自定义函数,计算每列的平方和
def square_sum(column):return sum(column**2)# 对每列应用自定义函数
result = numeric_df.apply(square_sum)print(numeric_df)
print(result)
代码解析10:
以上代码演示了如何使用apply函数对每列应用自定义函数,计算每列的平方和。这种灵活性使得我们可以更自由地定义数据处理逻辑,适应不同的分析需求。
通过学习时间序列数据处理和使用apply函数进行自定义操作,我们能够更好地处理特殊类型的数据和实现个性化的数据分析。
总结:Pandas DataFrame 数据处理之路
本文全面总结了Pandas DataFrame的关键知识点,为数据科学家和分析师提供了强大的工具和技巧。以下是我们的主要收获:
-
基础知识概览: 通过学习DataFrame的基本概念,我们了解了如何创建、操作DataFrame,并通过实例演示了其优雅的数据存储和展示能力。
-
数据操作技巧: 我们探讨了DataFrame的基本操作,包括索引、切片、过滤、排序等,为数据的灵活处理提供了丰富的手段。
-
数据清洗与处理: 介绍了数据清洗的重要性,展示了处理缺失值、重复数据、异常值等常见问题的方法,确保数据质量得到维护。
-
数据分组与聚合: 通过分组和聚合操作,我们能够更高层次地分析数据,洞察数据的特征和统计信息。
-
数据可视化: 结合Matplotlib和Seaborn,我们展示了如何使用DataFrame进行数据可视化,更直观地理解数据的分布和趋势。
-
数据读取与存储: 学习了如何将DataFrame保存为不同格式的文件,以及如何从这些文件读取数据,便于数据在不同环境中的传递和共享。
-
索引操作与重塑: 通过索引操作和重塑,我们能够更好地组织和访问数据,处理多层次索引和多维数据。
-
合并和连接数据框: 介绍了合并和连接不同数据框的方法,实现对数据的更全面分析。
-
时间序列数据处理: 学习了如何处理时间序列数据,包括创建日期索引、重采样等操作,应对不同形式的时间数据。
-
Apply函数的灵活应用: 通过
apply函数,我们可以实现对数据的自定义操作,提供更灵活的数据处理手段。
这篇总结为读者提供了全面的Pandas DataFrame使用指南,希望能够在数据科学和数据分析的实践中发挥巨大的帮助。通过掌握这些技能,读者将更自如地处理和分析各种数据,为解决实际问题提供强有力的支持。