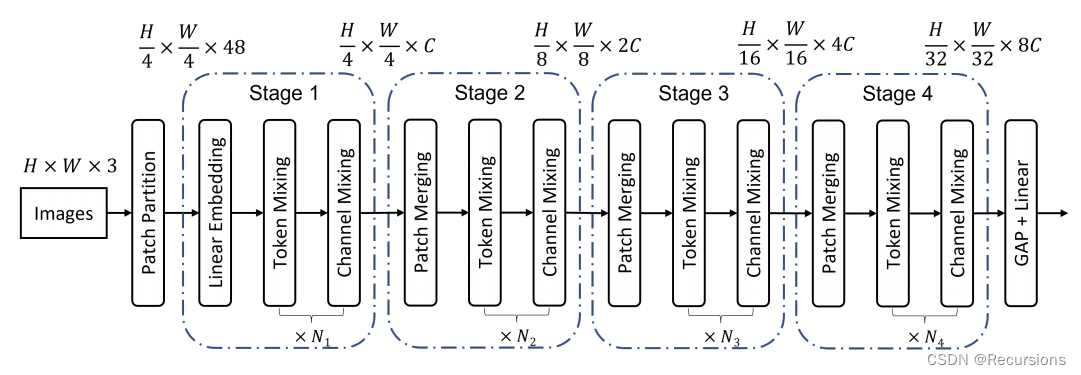
 上图展示了本文网络的整体架构。与ViT、MLP-Mixer和Swin Transformer类似,空间分辨率为H×W的输入图像被分割为不重叠的patch。作者在网络中采用了4×4的patch大小,每个patch被reshape成一个48维的向量,然后由一个线性层映射到一个c维embedding
上图展示了本文网络的整体架构。与ViT、MLP-Mixer和Swin Transformer类似,空间分辨率为H×W的输入图像被分割为不重叠的patch。作者在网络中采用了4×4的patch大小,每个patch被reshape成一个48维的向量,然后由一个线性层映射到一个c维embedding
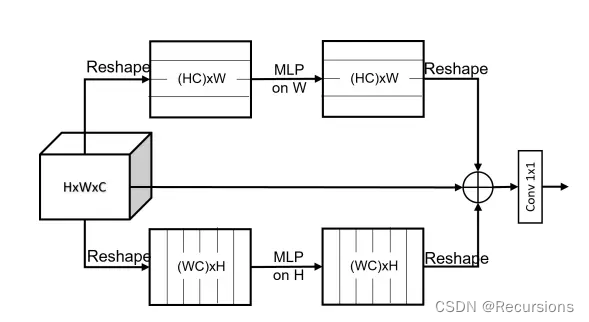
import torch, os, datetime
from torch import nnclass sMLPBlock(nn.Module):def __init__(self, h=224, w=224, c=3):super().__init__()self.proj_h = nn.Linear(h, h)self.proj_w = nn.Linear(w, w)self.fuse = nn.Linear(3 * c, c)def forward(self, x):x_h = self.proj_h(x.permute(0, 1, 3, 2)).permute(0, 1, 3, 2)x_w = self.proj_w(x)x_id = xx_fuse = torch.cat([x_h, x_w, x_id], dim=1)out = self.fuse(x_fuse.permute(0, 2, 3, 1)).permute(0, 3, 1, 2)return outif __name__ == '__main__':input = torch.randn(2, 3, 224, 224)smlp = sMLPBlock(h=224, w=224)out = smlp(input)print(out.shape)