一:概念
在应用的开发过程中,由于初期数据量小,开发人员写SQL语句时更重视功能上的实现,但是当应用系统正式上线后,随着生产数据量的急剧增长,很多SQL语句开始逐渐暴露出性能问题,对生产的影响也越来越大,此时在这些有问题的SQL语句就成为整个系统性能的瓶颈,因此我们必须要对它们进行优化。
MySQL的优化方式有很多,大致我们可以从以下几点来优化MySQL:从设计上优化;从查询上优化;从索引上优化;从存储上优化;
二:查看SQL执行频率

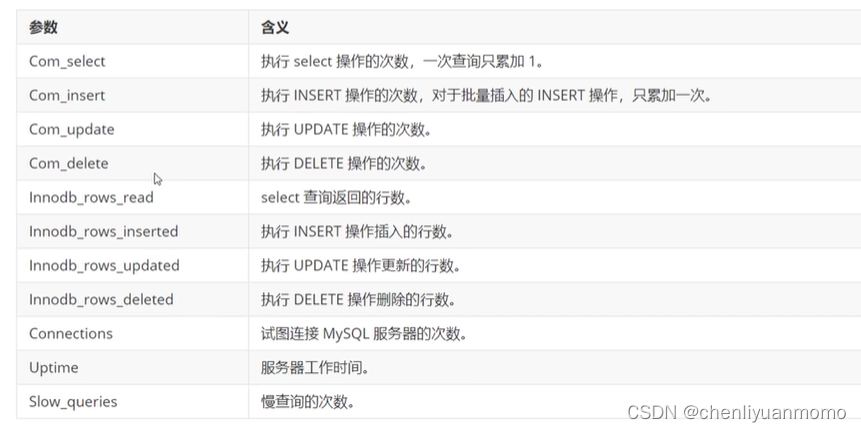
-- 查看当前会话SQL执行类型的统计信息
show session status like 'Com_______';-- 查看全局(自从上次MySQL服务器启动至今)执行类型的统计信息
show global status like 'Com_______';-- 查看针对InnoDB引擎的统计信息
show status like 'Innodb_rows_%';三:定位低效率执行SQL
可以通过以下两种方式定位执行效率较低的SQL语句
(1)慢查询日志:
通过慢查询日志定位那些执行效率较低的SQL语句。

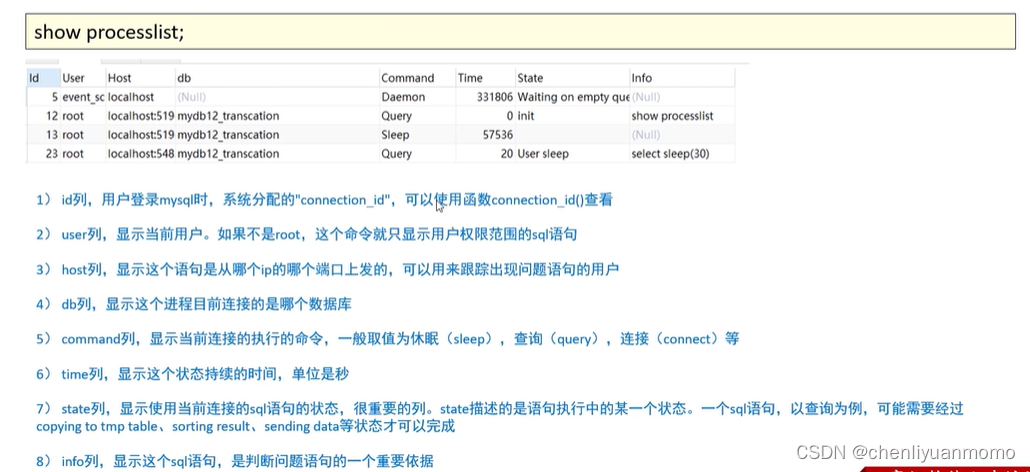
(2)show processlist:
该命令查看当前MySQL在进行的线程,包含线程的状态,是否锁表等,可以实时地查看SQL的执行情况,同时对一些锁表进行优化。
四:explain分析执行计划
(1)概述

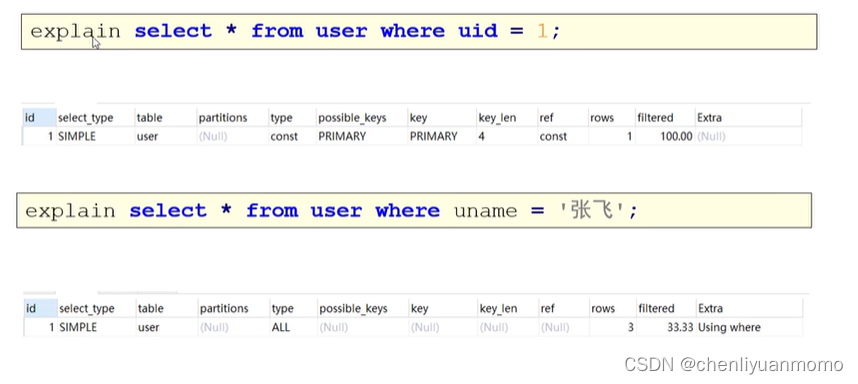

(2)id
id字段是select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。id情况有三种:
<1> id相同
表示加载表的顺序是从上到下
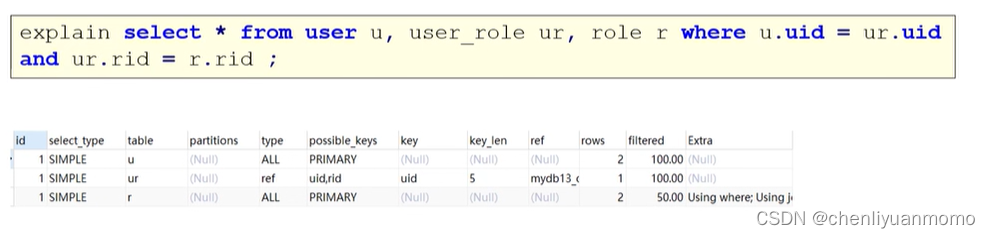
<2>id 不同
id值越大,优先级越高,越先被执行
explain select * from role where rid = (select rid from user_role where uid = (select uid from user where uname = '张飞'));
<3>id有相同,也有不同,同时存在
id相同的可以认为是一组,从上往下顺序执行;在所有的组中,id的值越大,优先级越高,越先执行。
explain select * from role r,(select * from user_role ur where ur.uid = (select uid from user where uname = '张飞')) t where r.rid = t.rid;

(3)select_type

(4)type

-- NULL 不访问任何表,任何索引,直接返回结果
explain select now();
explain select rand();-- system 查询系统表,表示直接从内存读取数据,不会从磁盘读取,但是5.7及以上版本不再显示system,直接显示ALL
explain select * from mysql.tables_priv;-- const查询列为主键或者是唯一索引
explain select * from user where uid = 2;-- 该列为主键列-- range:范围查询
explain select * from user where id > 2;-- index :把索引列的全部数据都扫描一遍
explain select id from user;-- index
explain select * from user;-- all
(5)其他指标字段

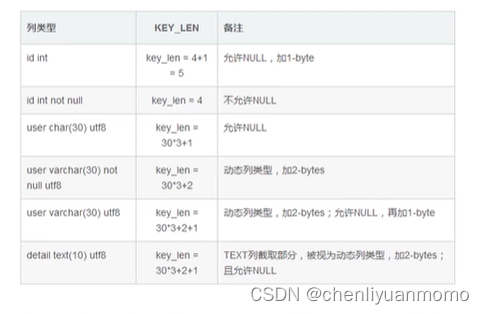

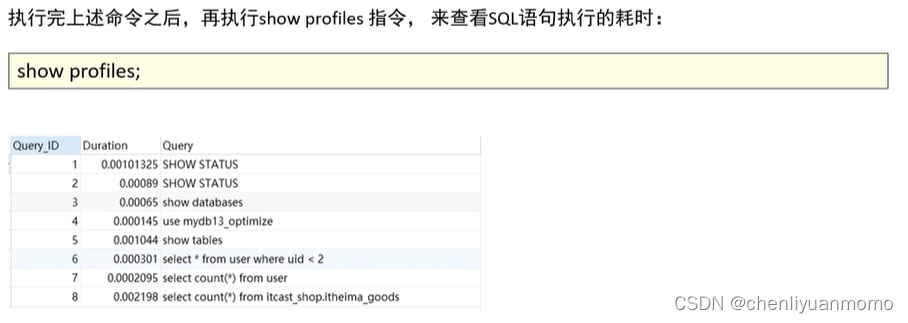
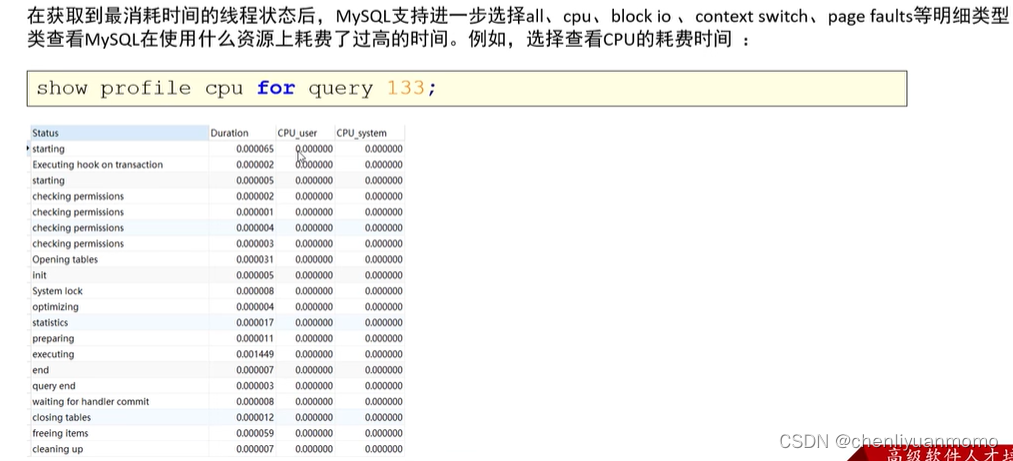
五:show profile分析SQL
MySQL从5.0.37版本开始增加了对 show profiles 和 show profile 语句的支持,show profiles能够在做SQL优化时帮助我们了解时间都耗费到哪去了。




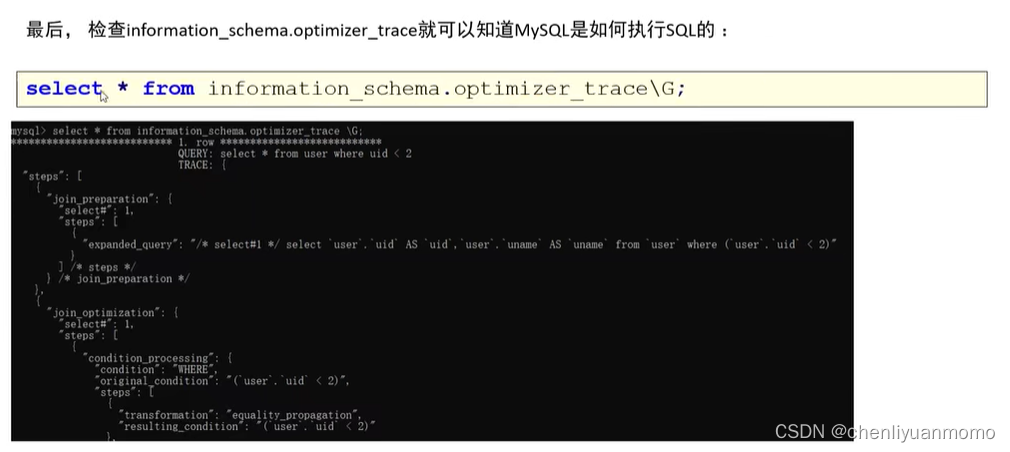
六:trace分析优化器执行计划
MySQL 5.6提供了对SQL的跟踪trace,通过trace文件能够进一步了解为什么优化器选择A计划,而不是选择B计划

七:使用索引优化
索引是数据库优化最常用也是最重要的手段之一,通过索引通常可以帮助用户解决大多数的MySQL的性能优化问题。
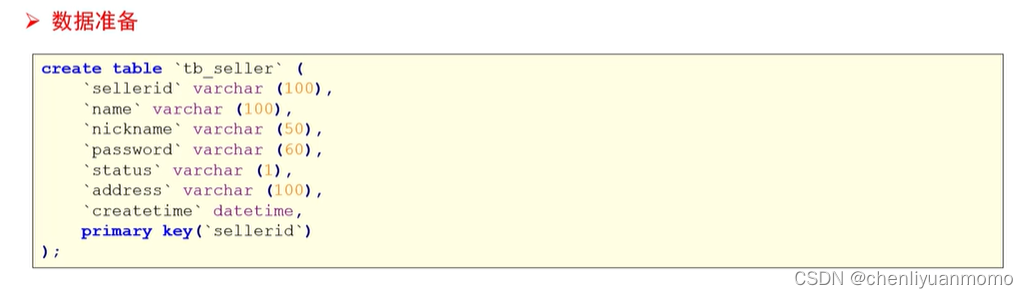
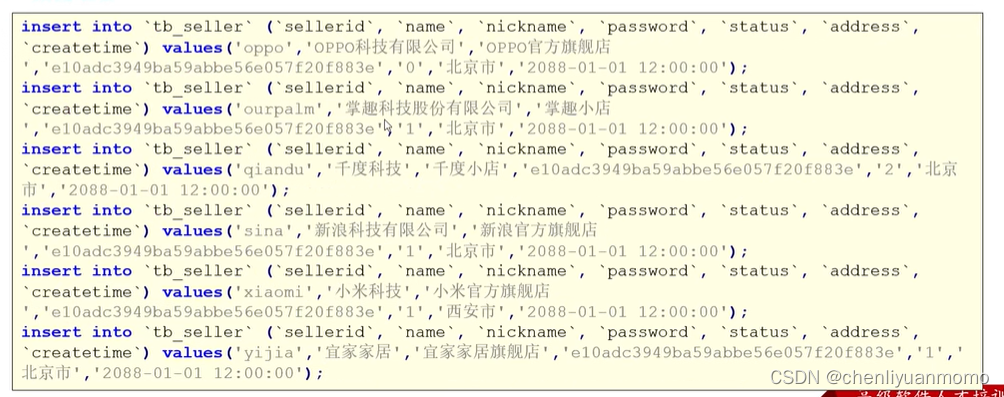
(1)数据准备

(2)避免索引失效应用--全值匹配
该情况下,索引生效,执行效率高(条件字段与索引字段完全匹配,匹配成功即可)

(3)避免索引失效应用--最左前缀法制
该情况下,索引生效,执行效率高

-- 违背最左法则,索引失效
explain select * from tb_seller where status = '1';-- null-- 如果符合最左法则,但是出现跳跃某一列,只有最左列索引生效
explain select * from tb_seller where name = '小米科技' and address = '北京市';(4)避免索引失效应用--其他匹配原则
该情况下,索引生效,执行效率高


using index:使用覆盖索引的时候就会出现
using where:在查找使用索引的情况下,需要回表去查询所需的数据
using index condition:查找使用了索引,但是需要回表查询数据
using index;using where:查找使用了索引,但是需要的数据都能在索引列中能找到,所以不需要回表查询数据
用or分割开的条件,如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及到的索引都不会被用到
-- 1.以%开头的like模糊查询,索引失效
explain select * from tb_seller where name like '科技%';-- 用索引
explain select * from tb_seller where name like '%科技';-- 不用索引
explain select * from tb_seller where name like '%科技%';-- 不用索引-- 弥补不足,不用*,使用索引列
explain select name from tb_seller where name like '%科技%';-- 2.如果MySQL评估使用索引比全表更慢,则不使用索引
-- 这种情况是由数据本身的特点来决定的
explain select * from tb_seller where address = '北京市';-- 没有使用索引(数据量远远超过一半)
explain select * from tb_seller where address = '西安市';-- 没有使用索引(数据量远远少于一半)-- 3.is null ,is not null 有时有效,有时无效
-- 由数据本身决定,若为null的数据多,则is null有效 is not null无效
explain select * from tb_seller where nick is null;-- 索引有效
explain select * from tb_seller where nick is not null;-- 索引无效-- 4.in 走索引,not in 索引失效
-- 普通索引
explain select * from tb_seller where nickname in ('阿里小店','百度小店');-- 使用索引
explain select * from tb_seller where nickname not in ('阿里小店','百度小店');-- 不使用索引-- 主键索引
explain select * from tb_seller where sellerid in ('alibaba','baidu');-- 使用索引
explain select * from tb_seller where sellerid not in ('alibaba','baidu');-- 使用索引-- 5.单列索引和复合索引,尽量使用复合索引
-- 如果一张表有多个单列索引,即使where中都使用了这些索引列,则只有一个最优索引生效八:SQL优化
(1)大批量插入数据
当使用load命令导入数据的时候,适当的设置可以提高导入的效率。对于innoDB类型的表,有以下几种方式可以提高导入的效率
<1>主键顺序插入
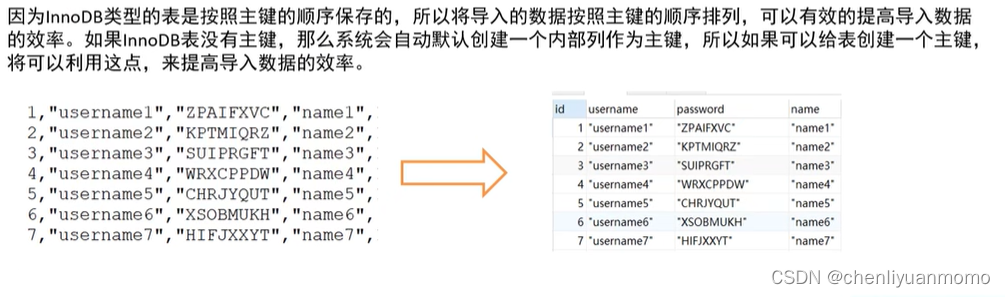
<2>关闭唯一性校验

(2)优化insert语句
当进行数据的insert操作的时候,可以考率采用以下几种优化方案



(3)优化 order by 语句
<1>环境准备

<2>两种排序方式
第一种是通过对返回数据进行排序,也就是通常说的filesort排序,所有不是通过索引直接返回结果的排序都叫filesort排序
第二种通过有序索引顺序扫描直接返回有序数据,这种情况即为using index,不需要额外排序,操作效率高
explain select * from emp order by age; -- Using filesort
explain select * from emp order by age,salary; -- Using filesortexplain select id from emp order by age; -- Using index
explain select id,age from emp order by age; -- Using index
explain select id,age,salary,name from emp order by age; -- Using filesort-- order by 后边的多个排序字段要求尽量排序方式相同
explain select id,age from emp order by age asc,salary desc; -- Using index;Using filesort
explain select id,age from emp order by age desc,salary desc; -- Backward index scan;Using filesort
-- order by 后边的多个排序字段顺序尽量和组合索引字段顺序一致
explain select id age from emp order by salary,age; -- Using index;Using filesort
<3>filesort 优化

(4)优化子查询
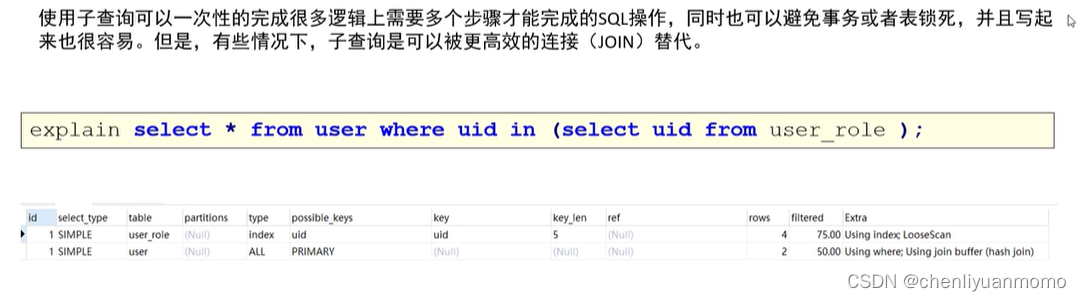
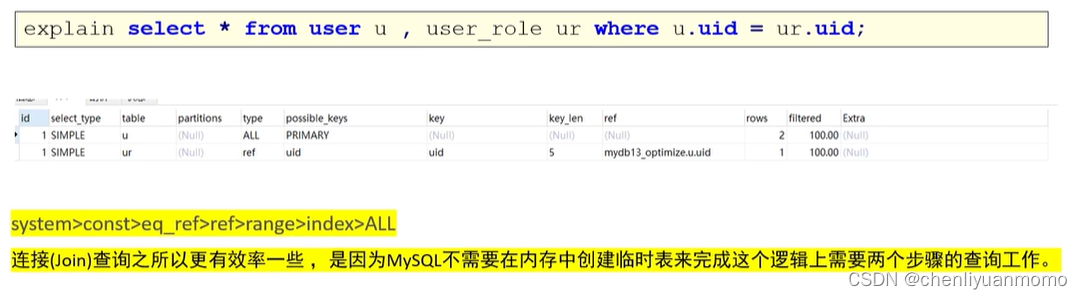
(5)优化limit
一般分页查询时,通过创建覆盖索引能够比较好地提高性能,一个常见又非常头疼的问题就是limit 900000,10 ,此时需要MySQL排序前900010记录,仅仅返回900000-900010的记录,其他记录丢弃,查询的代价非常大
<1>优化思路一
在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容
<2>优化思路二
该方案适用于主键自增的表,可以把limit查询转换成某个位置的查询
![[word] 如何将word文本转换成表格? #知识分享#学习方法#媒体](https://img-blog.csdnimg.cn/img_convert/15e34d6cccf36d654d05b70e2535a6a7.gif)