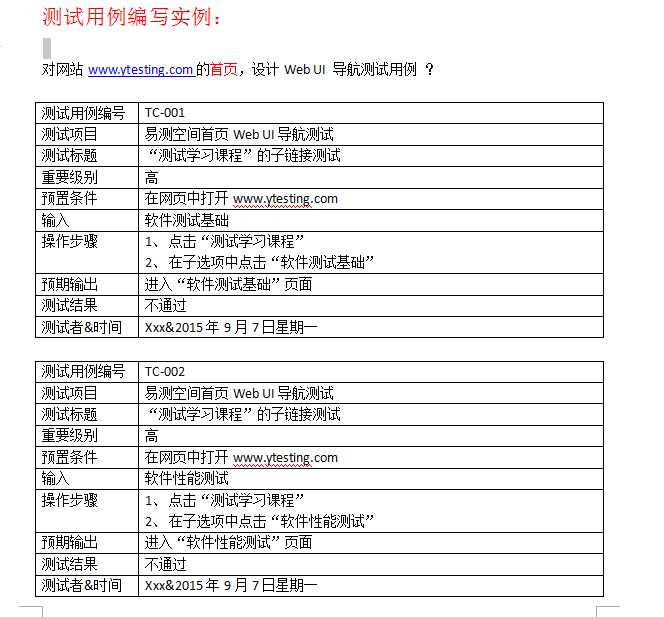
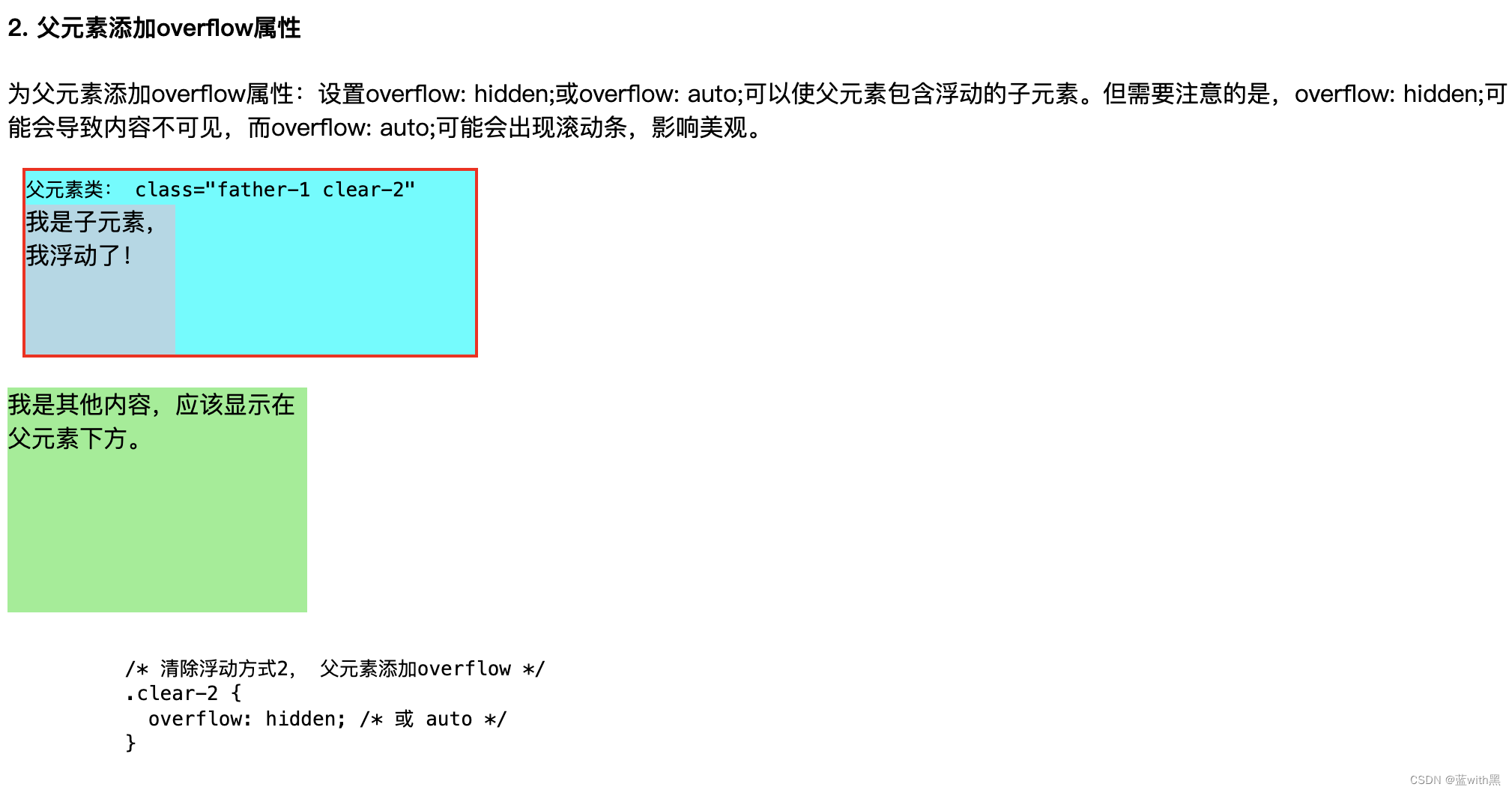
GPS——Guided Policy Search引导策略搜索 基于模型的强化学习算法
GPS目前被作为基础算法广泛应用于各种强化学习任务中,其出发点在于纯粹的策略梯度方法在更新参数时不会用到环境模型因而属于一种无模型强化学习算法。由于没有利用任何环境的内在属性,使得其训练只能完全依靠试错,效率较低。
开环方法:开放循环控制或非反馈控制,是一种控制策略,其中系统的输出或行为仅依赖于预设的指令或计划,而不考虑实际输出或环境状态的变化。在开环控制中,一旦确定了控制策略,就会一直执行下去,不会根据系统的实际表现进行调整。
闭环方法:反馈控制,涉及到系统通过传感器持续监测器输出或环境状态,并将这些信息反馈到控制系统中,以调整其输入或行为。闭环控制能够自动纠正偏差,因此对环境变化和不确定性有更好的适应性。
路径优化算法是一个开环方法,策略梯度是一个闭环方法,将两者相结合,利用路径优化算法的输出结果来指导策略梯度方法的训练过程,从而提高策略梯方法的效率,即GPS算法。
GPS的基本结构
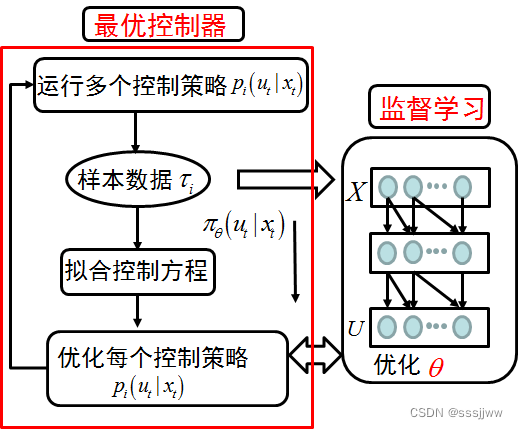
GPS分为两个模块:左侧是最优控制,右侧是策略搜索模块
最优控制器:在该模块中,控制器会运行当前的控制策略,并产生数据,然后基于这些产生的数据利用机器学习的方法,例如回归的方法拟合控制方法。有了控制方程就可以利用经典的最优控制的方法来求解当前的最优控制率。经典的最优控制的方法包括变分法、庞特里亚金最大值原理和动态规划的方法。在GPS中,最常用的是动态规划的方法,如LQR(线性二次型调节器)、LQG(线性二次高斯调节器)、iLQG(迭代线性二次高斯调节器)、DDP(微分动态规划)
监督学习模块:需要的输入数据和标签数据分别由最优控制器模块的实际轨迹数和最优控制率来提供,参数更新的方法为随机梯度下降法。
GPS=最优控制器+监督学习,+是耦合关系,体现为交互性
GPS算法是通过约束条件来实现最优控制器与监督学习网络之间的交互的,约束条件的意思是最优控制器所产生的分布应该与监督神经网络所产生的分布相同,即最优控制器的控制率应该与监督神经网络的控制率在采样点相同。
GPS算法通常包括的步骤:
1、策略初始化:初始策略可以是基于专家知识手动设计,也可以是简单的神经网络
2、数据搜集:使用当前策略在环境中执行一系列的试验,收集状态-动作对,这些状态-动作对就是所谓的“采样点”
3、策略评估:在这些采样点上,使用最优控制方法(如:ILQR)来找到在当前策略下,从每个状态到下一个状态的最优动作,这些最优动作形成一个行的动作分布。
4、监督学习:使用策略评估中得到的最优动作作为标签,训练一个监督学习网络来近似最优策略,这里的监督学习网络输出的动作应该尽可能接近最优控制器输出的动作。
5、策略改进:将监督学习网络作为新的策略,并重复上述步骤,直到网络的输出动作与最优控制器的输出动作在采样点上非常接近,即两个分布相同或足够相似。
监督学习网络通过约束条件参与到最优控制器的优化,而优化好的控制器通过提供监督学习的标签来指导监督神经网络进行策略搜索。
GPS算法的缺点:
1、计算复杂性:GPS算法在策略评估和策略改进步骤中使用了迭代线性二次调节器或其他优化技术,这些计算通常是非常复杂的,尤其是高纬状态和动作空间中。
2、数据需求:GPS算法需要大量的数据来准确估计策略梯度,尤其是在复杂环境中,这意味着在实际应用中可能需要大量的试错过程,增加时间成本。
3、局部最优:采用梯度下降法会陷入局部最优
4、对模型精度的依赖:GPS算法通常假设环境模型是已知的或者可以通过监督学习来准确估计的,但是在许多实际问题中,环境模型可能是未知的,很难准确估计,可能会导致算法性能的下降。

![猫头虎分享已解决Bug || RuntimeError: size mismatch, m1: [32 x 100], m2: [500 x 10]](https://img-blog.csdnimg.cn/direct/aa86eef0d81e4f279688a772e92ea3bc.webp#pic_center)