Azkaban工作流调度系统
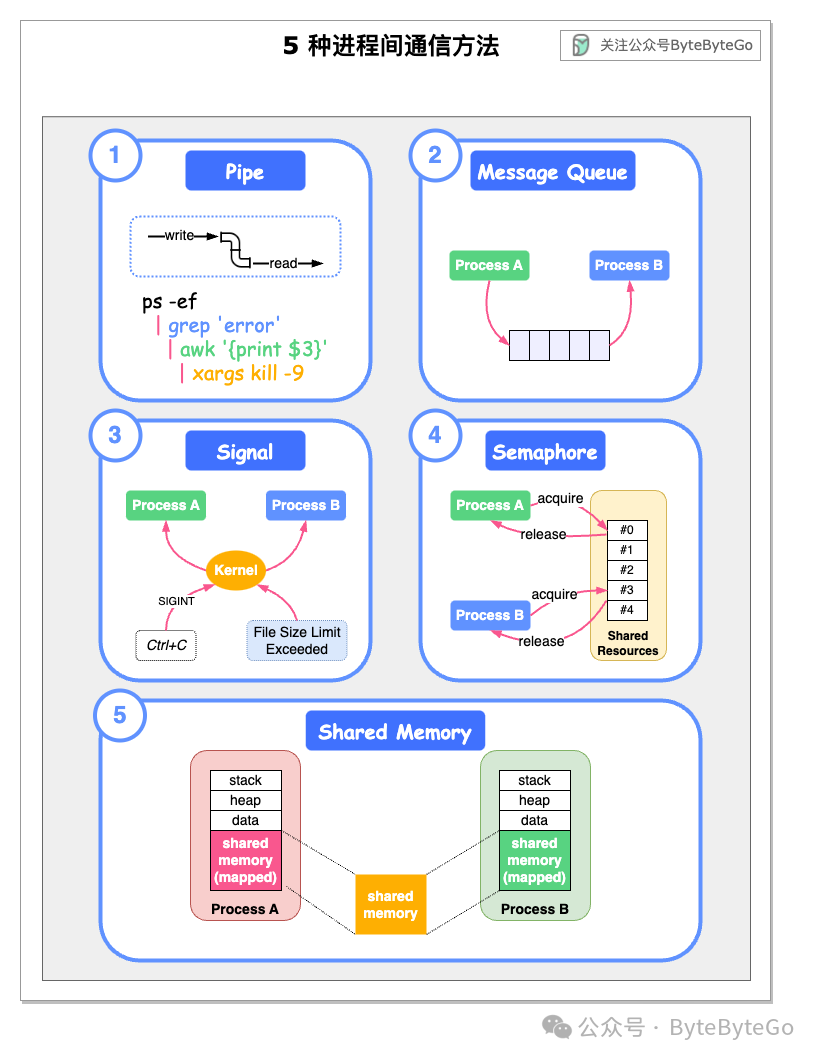
- 1. 工作流调度系统解决了什么问题
- 2. 特点
- 3. 与Ooize简单对比
- 4. 架构
- 5. Job类型
- 6. 总结
1. 工作流调度系统解决了什么问题
我曾经参与过一个数据治理的项目,项目的大概流程是【数据获取-数据清洗入库-展示】:

这时候就出现问题了,数据导入成功后要执行清洗流程,那什么时候数据导入完成呢?又是什么时候开始执行数据清洗流程呢?盯着当然是可以的,但是复杂的流程我们实现了自动化,执行的时候却要人工,比较浪费时间。直接使用crontab可以实现定时,但是无法实现顺序执行。
我们当时自己搭建了一个调度平台,实现的功能是定时调度指定的shell脚本,shell脚本去调用ktr或者kjb脚本并输出日志数据,这个平台解决了数据导入阶段,也解决了数据清洗阶段,但是没能实现自动化,因为不知道数据导入何时结束、导入是否成功,也就没法定时调用清洗脚本,最终,这个平台也被放弃了,我们合并了shell脚本,自己在Linux系统上进行执行及数据校验。😩
后来开始学习大数据,大数据相关的组件更多,流程也更多,调度文件就凸显了,例如,某个业务系统每天产生20G原始数据,我们每天都要对其进行处理,处理步骤如下所示:
通过Hadoop先将原始数据上传到HDFS上(HDFS的操作) >> 使用MapReduce对原始数据进行清洗(MapReduce的操作) >> 将清洗后的数据导入到hive表中(hive的导入操作) >> 对Hive中多个表的数据进行JOIN处理,得到一张hive的明细表(创建中间表) >> 通过对明细表的统计和分析,得到结果报表信息(hive的查询操作)。

这些任务单元 (数据收集、数据清洗、数据存储、数据分析等) ,任务单元及其之间的依赖关系组成了复杂的工作流。复杂的工作流管理涉及到很多问题:
- 如何定时调度某个任务?
- 如何在某个任务执行完成后再去执行另一个任务?
- 如何在任务失败时候发出预警?
工作流调度系统解决了这些实际问题。
2. 特点
Azkaban是由Linkedin公司推出的一个批量工作流任务调度器,主要用于在一个工作流内以一个特定的顺序运行一组工作和流程,它的配置是通过简单的key:value对的方式,通过配置中的dependencies来设置依赖关系【可以设置一个,也可以设置多个】。Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流,它的 官网 介绍如下:
- Compatible with any version of Hadoop 兼容任何版本的 Hadoop
- Easy to use web UI 易于使用的Web用户界面
- Simple web and http workflow uploads 可以使用简单的 Web 页面进行工作流上传
- Project workspaces 支持按项目进行独立管理
- Scheduling of workflows 定时任务调度
- Modular and pluginable 模块化和可插拔的插件机制
- Authentication and Authorization 身份认证/授权(权限的工作)
- Tracking of user actions 跟踪用户操作
- Email alerts on failure and successes 支持失败和成功的电子邮件提醒
- SLA alerting and auto killing SLA 警报和自动查杀失败任务
- Retrying of failed jobs重试失败的任务
这里展示一张简单的前端任务调度流程图:

还可以进行权限配置:

项目日志展示:

3. 与Ooize简单对比
尽管工作流调度器能够解决的需求场景基本一致,但在设计理念、目标用户、应用场景等方面还是存在显著的区别,在做技术选型的时候,可以提供参考:
| 特性 | Oozie | Azkaban |
|---|---|---|
| 工作流描述语言 | XML | text file with key/value pairs |
| 是否要web容器 | Yes | Yes |
| 进度跟踪 | web page | web page |
| Hadoop Job调度支持 | Yes | Yes |
| 运行模式 | daemon | daemon |
| 事件通知 | No | Yes |
| 支持的hadoop版本 | 0.20+ | Compatible with any version of Hadoop |
| 重试支持 | Yes | Yes |
| 运行任意命令 | Yes | Yes |
| Azkaban 和 Oozie 都是目前使用最为广泛的工作流调度程序,其主要区别如下: |
功能对比
- 两者均可以调度 Linux 命令、MapReduce、Spark、Pig、Java、Hive 等工作流任务;
- 两者均可以定时执行工作流任务。
工作流定义
- Azkaban 使用 Properties(Flow 1.0) 和 YAML(Flow 2.0) 文件定义工作流;
- Oozie 使用 Hadoop 流程定义语言(hadoop process defination language,HPDL)来描述工作流,HPDL 是一种 XML 流程定义语言。
资源管理
- Azkaban 有较严格的权限控制,如用户对工作流进行读/写/执行等操作;
- Oozie 暂无严格的权限控制。
运行模式
Azkaban 3.x 提供了两种运行模式:
-
solo server model(单服务模式) :元数据默认存放在内置的 H2 数据库(可以修改为MySQL),该模式中 webServer (管理服务器) 和 executorServer (执行服务器) 运行在同一个进程中,进程名是 AzkabanSingleServer 。该模式适用于小规模工作流的调度。
-
multiple-executor(分布式多服务模式) :存放元数据的数据库为 MySQL,MySQL 应采用主从模式进行备份和容错。这种模式下 webServer 和 executorServer 在不同进程中运行,彼此之间互不影响,适合用于生产环境。
Oozie 使用 Tomcat 等 Web 容器来展示 Web 页面,默认使用 derby 存储工作流的元数据,由于derby 过于轻量,实际使用中通常用 MySQL 代替。
如果你的工作流不是特别复杂,推荐使用轻量级的 Azkaban,主要有以下原因:
- 安装方面:Azkaban 3.0 之前都是提供安装包的,直接解压部署即可。Azkaban 3.0 之后的版本需要编译,这个编译是基于 gradle 的,自动化程度比较高;
- 页面设计:所有任务的依赖关系、执行结果、执行日志都可以从界面上直观查看到;
- 配置方面:Azkaban Flow 1.0 基于 Properties 文件来定义工作流,这个时候的限制可能会多一点。但是在 Flow 2.0 就支持了 YARM。YARM 语法更加灵活简单,著名的微服务框架 Spring Boot就采用的 YAML 代替了繁重的 XML。
4. 架构
Azkaban的multiple-executor(分布式多服务模式) 由三个关键组件构成:

-
AzkabanWebServer:AzkabanWebServer是整个Azkaban工作流系统的主要管理者,它用户登录认证、负责project管理、定时执行工作流、跟踪工作流执行进度等一系列任务。
-
AzkabanExecutorServer:负责具体的工作流的提交、执行,它们通过mysql数据库来协调任务的执行。
-
关系型数据库(MySQL):存储大部分执行流状态,AzkabanWebServer和AzkabanExecutorServer都需要访问数据库。
5. Job类型
原生的 Azkaban 支持的 plugin 类型有以下这些,官网也有举例 但是官网很不友好【网速不行、举例不详细、有些文件无法下载 😟】 :
- command:Linux shell命令行任务(最为强大,懂的都懂 😏)
- gobblin:通用数据采集工具
- hadoopJava:运行hadoopMR任务
- java:原生java任务
- hive:支持执行hiveSQL
- pig:pig脚本任务
- spark:spark任务
- hdfsToTeradata:把数据从hdfs导入Teradata
- teradataToHdfs:把数据从Teradata导入hdfs
----------------------------------------【以下举例都是flow1.0语法】----------------------------------------
- command类型 job配置举例
type=command
# 只要是Linux命令能够实现的操作 这里都能执行 所以说这种类型最为强大
command=echo "This is azkaban cmd ... "
command.1=who am i
# 依赖前一个job 配置文件为 cmd1.job
dependencies=cmd1
- java类型 job配置举例【我更原因使用command类型的job调度Java代码】
type=javaprocess
# 所有相关代码所在的文件夹
classpath=/home/azkaban/*
# 要执行的主类
java.class=AzkabanTest
- hadoopJava类型举例【依然可以使用command类型】
type=hadoopJava
# 所有相关代码所在的文件夹
classpath=./lib/*,${azkaban.home}/lib/*
job.extend=false
# 主类
job.class=azkaban.jobtype.examples.java.WordCount
# 配置
force.output.overwrite=true
input.path=/input
output.path=/output
- hive类型举例【依然可以使用command类型】
type=hive
# 代理用户
user.to.proxy=azkaban
# 所有相关代码所在的文件夹
classpath=./lib/*,${azkaban.home}/lib/*
azk.hive.action=execute.query
# 执行的SQL文件
hive.script=/hive.sql
- spark类型举例【依然可以使用command类型】
type=spark
# master配置
master=yarn-cluster
# 执行的jar包
execution-jar=lib/spark-template-1.0-SNAPSHOT.jar
# 执行的主类
class=com.dataeye.template.spark.WordCount
# 参数信息
params=hdfs://de-hdfs/data/yann/info.txt paramtest
6. 总结
我也使用过 xxl-job 任务调度系统,xxl-job 有它的优势,但是无法实现工作流就是说 job 之间的依赖需要我们自己在后台进行维护【这样就增加了 job 之间的耦合】,实际上我并不清晰 Azkaban 是如何判断当前 job 执行完成的?有知道的小伙伴,欢迎分享!