目录
前言:
1.认识堆
a.如何认识堆?
b.大根堆与小根堆
c.堆应用的简单认识
2.堆的结构与要实现的功能
3.向上调整算法
4.向下调整算法
5.向堆插入数据并建堆
6.堆的大小
7.堆的判空
8.取堆顶数据
9.删除堆顶数据
10.向上调整时间复杂度
11.向下调整时间复杂度
12.堆排序
a.直接将数组放到堆再取堆顶
b.在将数组放到堆的时候就直接调整,用数组建堆
13.topk问题
总结:
前言:
堆其实与二叉树息息相关,本篇将从如何实现堆,以及堆的应用等方面入手。
1.认识堆
a.如何认识堆?
我们只要记住关键的两点:1.堆必须是完全二叉树。2.堆要么是大堆,要么是小堆。
b.大根堆与小根堆
那什么是大堆,什么又是小堆呢?
大堆:树中任意一个父亲都大于或等于孩子。
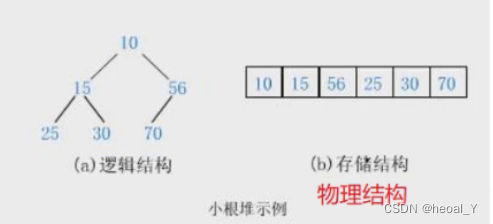
小堆:树中任意一个父亲都小于或等于孩子。

c.堆应用的简单认识
堆排序:时间复杂度为O(N*logN),属于快一点的排序。
topk问题:N个数找最大的前K个。
优先级队列:C++中stl的priority_queue容器的底层实现需要用到建堆的思想。
2.堆的结构与要实现的功能
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <assert.h>typedef int HPDataType;
typedef struct Heap
{HPDataType* a;HPDataType size;HPDataType capacity;
}HP;void InitHeap(HP* php);
void DestroyHeap(HP* php);
void PushHeap(HP* php, HPDataType x);
void HeapPop(HP* php);
HPDataType HeapTop(HP* php);
bool HeapEmpty(HP* php);
int HeapSize(HP* php);
void AdjustUp(HPDataType* a, int child);
void AdjustDown(int* a, int n, int parent);
void Swap(HPDataType* p1, HPDataType* p2);
我们提供以下数据来建堆:

3.向上调整算法
我们现在如果要让提供的数据插入到这个堆里面,如何保证插入的时候就建好堆了呢?这时我们就要用到向上向下调整的算法了。假设我们现在要建一个小堆,就要保证每一个子节点都要小于或者等于它的父节点,用我们提供好的数据,当插入到32这个数据的时候就要进行调整了:
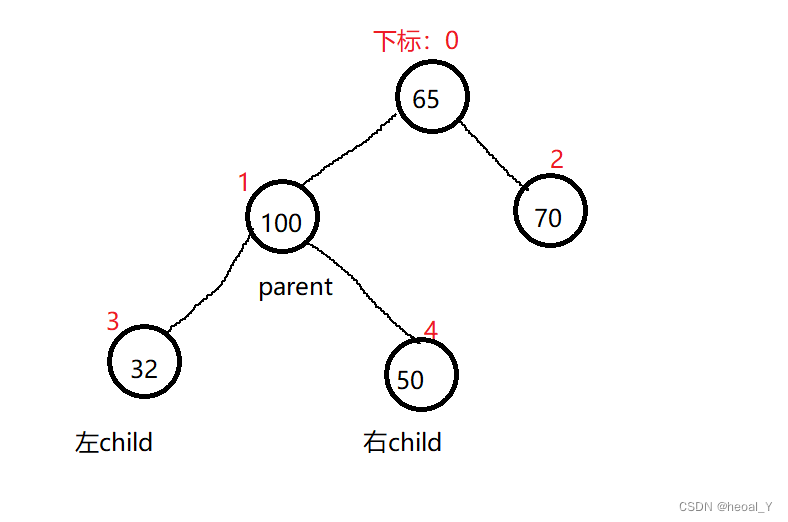
既然是向上调整,那我们就要找孩子的父亲,那如何找到父亲呢?通过下标的关系可以发现,不管是左还是右孩子,只要遵循(child-1)/2就能找到父亲的下标,然后就是交换嘛;交换过后我们要让孩子走到父亲位置,再找到新的父亲,一轮一轮的向上,这就是向上调整算法: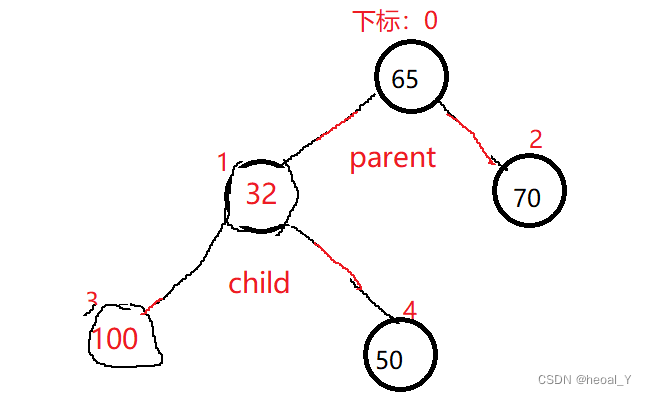
void AdjustUp(HPDataType* a, int child)
{//默认建小堆int parent = (child - 1) / 2;while (child > 0)//等于0就停止了,等于0说明孩子在根的位置,就没有父亲了{if (a[child] < a[parent]){Swap(&a[child], &a[parent]);child = parent;//孩子走到父亲的位置继续再找新的父亲parent = (child - 1) / 2;}else{break;}}
要注意的就是循环条件,如果孩子走到0说明走到根的位置了,就没有父亲了,循环停止。
4.向下调整算法
向下调整算法与向上调整算法相反,其实向下就是找孩子,如果建小堆就让左右孩子中最小的孩子与父亲交换(最小的孩子与父亲交换后,父亲就变成三者中最小的了,符合小堆的性质),再让父亲走到孩子的位置上,再往下继续找到新的孩子,直到孩子不存在的情况。
关键来了,如何找到左右孩子中的最小的那个呢?如何通过父亲找到孩子呢?
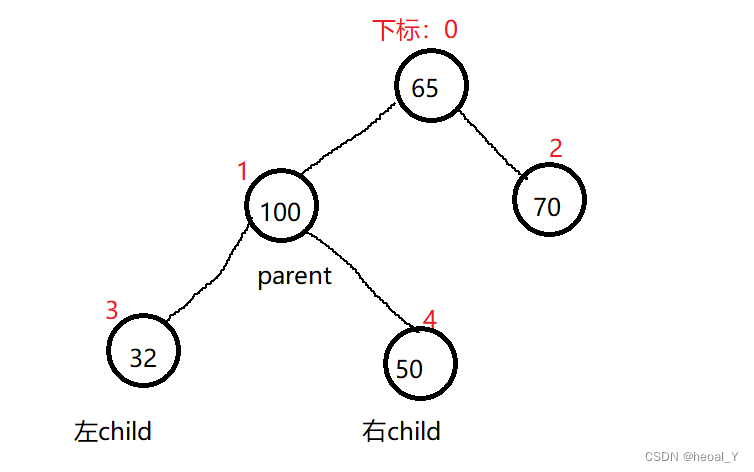
我们可以默认左孩子是最小的那一个,如果左孩子大于右孩子,那做孩子的下标+1不就到右孩子了吗?解决了第一个问题,那如何通过父亲找到孩子呢,既然我们默认左孩子是小的那一个,我们可以先找到左孩子,通过下标的关系,我们就知道左孩子child=parent*2+1,好了,这就是向下调整算法的思路,来看代码:
void AdjustDown(int* a, int n, int parent)
{//默认小堆int child = parent * 2 + 1;//默认是左孩子while (child < n){//这里右孩子的存在条件必须放在&&的前面,因为如果放在后面,前面的条件为假,右孩子也为假,就判断不出来是哪个了(检查右孩子存在必须更严格)if (child + 1 < n && a[child] > a[child + 1])//如果右孩子存在(因为如果左孩子为n-1,那右孩子就为n了,就越界了)并且左孩子大于右孩子,下标就走到右孩子上{child = child + 1;}if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}}
注意点:
1.我们既然默认左孩子为小的那一个,那结束条件就应该是左孩子不存在的情况即当左孩子等于n的时候就越界了,而又由于堆是完全二叉树,所以左孩子不存在,那右孩子一定不存在,所以只写这一个就行。
2.child + 1 < n && a[child] > a[child + 1],首先需要注意左孩子存在,但右孩子不存在的情况,所以判断child+1<n,其次这个条件要写到&&的前面,因为如果写到后面,a[child]>a[child+1]为假,就判断不出右孩子可能越界的情况了,所以右孩子的检查应该放到&&前面。
5.向堆插入数据并建堆
void PushHeap(HP* php, HPDataType x)
{assert(php);if (php->size == php->capacity){int NewCapacity = php->capacity = 0 ? 4 : php->capacity * 2;HPDataType* tmp = (HPDataType*)realloc(php->a, sizeof(HPDataType) * NewCapacity);if (tmp == NULL){perror("realloc fail");return;}php->a = tmp;php->capacity = NewCapacity;}php->a[php->size] = x;php->size++;AdjustUp(php->a, php->size - 1);//向上调整传孩子,即插入的数据,找父亲}
需要注意的是最后向上调整传的孩子是插入的数据的下标,因为插入后size++了,所以-1才对应插入的数据的下标。
6.堆的大小
int HeapSize(HP* php)
{assert(php);return php->size;
}
7.堆的判空
bool HeapEmpty(HP* php)
{assert(php);return php->size == 0;
}
8.取堆顶数据
HPDataType HeapTop(HP* php)
{assert(php);assert(!HeapEmpty(&php));return php->a[0];
}
9.删除堆顶数据
如果我们直接删除堆顶的数据会导致这个堆变乱,所以我们采用交换堆顶和堆尾的数据,将堆的大小减1,这样就访问不到堆尾的数据也就起到了删除的效果了,然后我们再从根节点开始做向下调整算法,恢复堆即可,注意空堆不能删,要判空:
void HeapPop(HP* php)
{assert(php);assert(!HeapEmpty(&php));Swap(&php->a[0], &php->a[php->size - 1]);php->size--;AdjustDown(php->a, php->size, 0);//从根节点开始向下调整}
10.向上调整时间复杂度
按最坏的情况计算时间复杂度,就拿满二叉树来说:
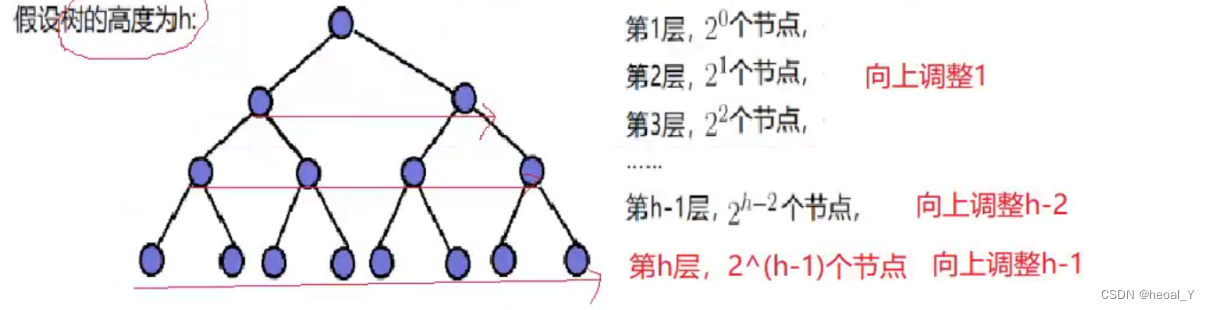
我们先找到每一次的节点数,再乘向上调整的次数,假设树的高度为h,那我们就将1-h层的所有节点的调整次数相加,就是时间复杂度(计算采用等比数列求和的乘公比错位相减的方法):
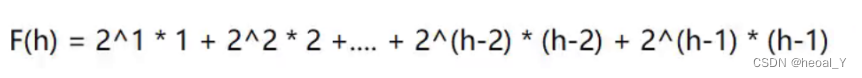
又因为满二叉树的节点个数为2^h-1,所以我们设树有N个节点,就能得到高度,再代入F(h):

实际去除不影响结果的项也就是O(N*logN),N为节点个数。
11.向下调整时间复杂度
一样拿满二叉树来说:
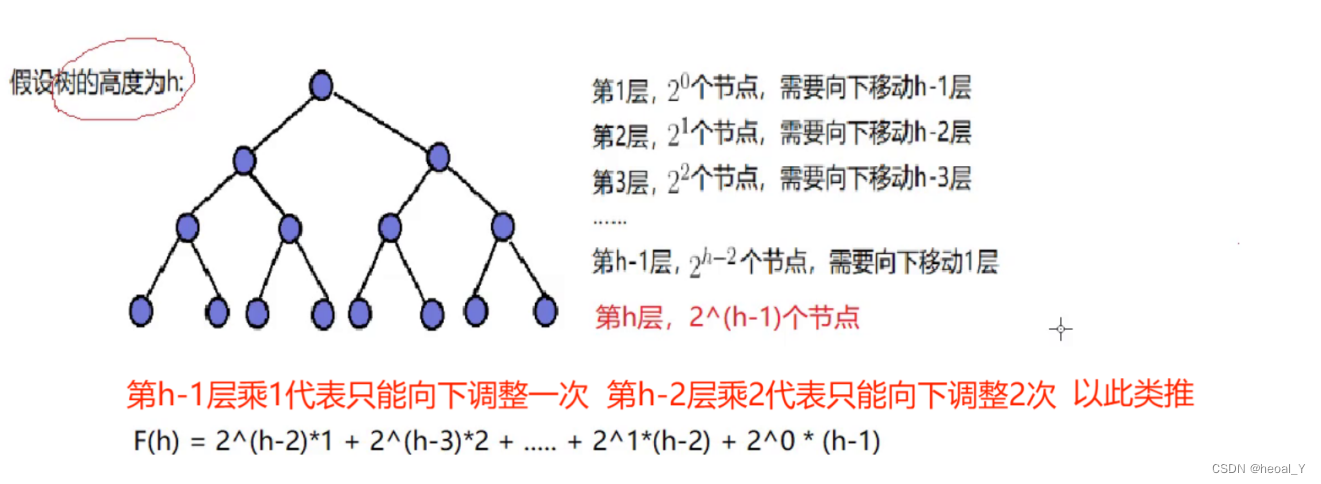
实际计算结果:

实际去除不影响结果的项也就是O(N),N为节点个数。
12.堆排序
a.直接将数组放到堆再取堆顶
void HeapSort1(int* a, int n)
{HP hp;InitHeap(&hp);for (int i = 0; i < n; i++){PushHeap(&hp, a[i]);}int i = 0;while (!HeapEmpty(&hp)){int top = HeapTop(&hp);a[i++] = top;HeapPop(&hp);}
}
这样的坏处就是想要改升序降序要改向上向下调整的逻辑,有些麻烦,而且时间上有些麻烦,需要堆排的时候还要写一个堆出来。
b.在将数组放到堆的时候就直接调整,用数组建堆
如果我们要排成降序,就建小堆,小堆选出最小的,首尾交换,最小的放到最后的位置,最后一个数据不看做堆里面的,再次向下调整就可以选出次小的,以此类推,相当于一个一个头插;
调用一次是O(logN),N次就是O(N*logN),计算方法跟向下调整差不多;
向下调整建堆需要倒着调整,叶子节点不需要处理,倒数第一个非叶子节点即最后一个节点的父亲开始调整:
void HeapSort(int* a, int n)
{for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, n, i);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}
}
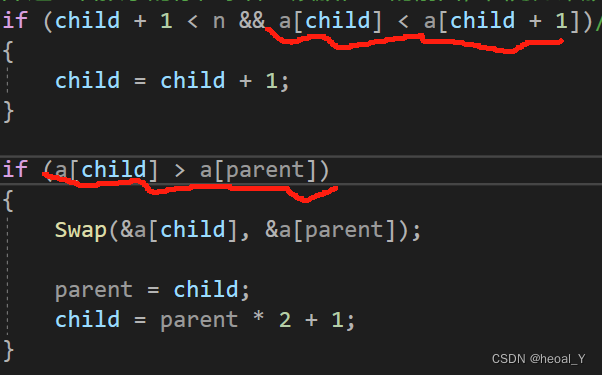
如果我们要排升序,只需要改动向下调整或者写两个建堆方法:
改动两处:选孩子时选大的那个;如果孩子大于父亲,交换:
建堆时也可向上调整建堆,具体实现博主暂时不清楚~~~:
for (int i = 1; i < n; i++)//下标为0即第一个数默认是堆{AdjustUp(a, i);//建堆,相当于一个一个插入成堆}注意:
1.为什么升序不建小堆呢?因为小堆最小的已经在前面了,不管是移动还是怎么剩下的都要重新建堆
2.堆排序整体时间复杂度为N+N*logN,也就是O(N*logN)
13.topk问题
什么是topk问题?
就是N个数找最大的前N个:

面对庞大的数据,数据放在磁盘的文件里面,而内存是有限的,所以我们将这些数据的前k个建堆,将剩下的数据与堆顶元素进行比较,符合条件就交换,然后再调整,重复操作即可,那该怎么建堆呢?首先对前3 数据进行建一个小堆,注意这里不能建大堆,如果建大堆的话,可能最大的数据在前三个数,其余2个数据在余下的 N-K个数里面,这样其余2个就不能进堆了:
void CreateNData()
{//造数据int n = 10000;srand((unsigned int)time(0));const char* file = "data.txt";FILE* fin = fopen(file, "w");if (fin == NULL){perror("fopen error");return;}for (size_t i = 0; i < n; i++){int x = rand() % 1000000;fprintf(fin, "%d\n", x);}fclose(fin);
}void PrintTopK(int k)
{const char* file = "data.txt";FILE* fout = fopen(file, "r");if (fout == NULL){perror("fopen error");return;}int* kminheap = (int*)malloc(sizeof(int) * k);if (kminheap == NULL){perror("malloc error");return;}for (int i = 0; i < k; i++){fscanf(fout, "%d", &kminheap[i]);}for (int i = (k - 1 - 1) / 2; i >= 0; i--){AdjustDown(kminheap, k, i);}int val = 0;while (!feof(fout))//fscanf读到文件结尾,调用feof,feof读到文件末尾返回非0,否则返回0{fscanf(fout, "%d", &val);if (val > kminheap[0]){kminheap[0] = val;AdjustDown(kminheap, k, 0);}}for (int i = 0; i < k; i++){printf("%d ", kminheap[i]);}printf("\n");
}

![[职场] Android是什么?Android行业有哪些- #媒体#经验分享](https://img-blog.csdnimg.cn/img_convert/8fcbcfd5756de07d9386140c06df63df.jpeg)