Paper name
FINITE SCALAR QUANTIZATION: VQ-VAE MADE SIMPLE
Paper Reading Note
Paper URL: https://arxiv.org/abs/2309.15505
Code URL:
- (官方 jax 实现) https://github.com/google-research/google-research/tree/master/fsq
- (pytorch 实现) https://github.com/lucidrains/vector-quantize-pytorch?tab=readme-ov-file#finite-scalar-quantization
TL;DR
- 2023 年 google 发表的文章,可以用于文本、视频生成领域中。提出一种称为有限标量量化(FSQ)的简单方案来替换 VQ-VAEs 中的向量量化(VQ)。解决传统 VQ 中的两个主要问题:
- 需要避免 codebook collapse 的辅助损失
- 大 codebook size 情况下码本利用率低
Introduction
背景
- vqgan、phenaki 等工作表明,对使用 GAN 损失训练的 VQ-VAE 表示进行自回归 transformer 模型训练可以实现强大的图像和视频生成模型
- 然而 VQVAE 中的向量量化 (VQ)有一定缺点:
- 训练优化困难:在训练VQ-VAE时,目标是学习一个码本 C,希望其包含输入数据(通常是图像)的压缩语义表示。在前向传播中,图像 x 被编码成一个表示 z(通常是特征向量序列),并且 z 中的每个向量都被量化为 C 中最接近的向量。量化操作是不可微的。在使用 VQ 在潜在表示中训练 VAE 时,需要使用直通估计器(STE),将梯度从解码器输入复制到编码器输出,从而使得编码器的梯度能正常传导。由于这仍然不能产生用于码书向量的梯度,vqvae 工作进一步引入了两个辅助损失,将码字向量拉向(未量化的)表示向量,反之亦然。这导致随着 C 的大小增加,可能会有码本坍塌(codebook collapse)问题,也即许多码字将不会被使用。后续一些工作需要单独处理这个问题,比如重新初始化整个码书等
本文方案
- 提出一种称为有限标量量化(FSQ)的简单方案来替换 VQ-VAEs 中的向量量化(VQ)。新方案希望解决传统 VQ 中的两个主要问题:
- 消除辅助损失
- 提高码本利用率
- 作为 VQ 的可替换组件
- 具体实现方式
- 将 VAE 表示投影到少量维度(通常少于10)。每个维度被量化为一组固定的值,由这些数值集合的乘积给出(隐式的)码本 (codebook)
- 比如对于一个具有 d 个 channel 的向量 z,如果将每个条目 zi 映射到 L 个值(比如通过 z i = R o u n d ( ⌊ L / 2 ⌋ t a n h ( z i ) ) z_i = Round(\lfloor L / 2 \rfloor tanh(z_{i})) zi=Round(⌊L/2⌋tanh(zi)) ,其中 Round 是四舍五入算子),则可以获得一个量化后的向量 z ^ \hat{z} z^,其中 z ^ \hat{z} z^ 是 L d L^d Ld 个唯一可能的向量之一。下图展示了 d=3, L=3 的 FSQ,码本 C = ( − 1 , − 1 , − 1 ) , ( − 1 , − 1 , 0 ) , ( − 1 , − 1 , 1 ) , . . . , ( 1 , 1 , 1 ) C = {(−1, −1, −1), (−1, −1, 0), (−1, −1, 1), . . . , (1, 1, 1)} C=(−1,−1,−1),(−1,−1,0),(−1,−1,1),...,(1,1,1),其中码本大小 ∣ C ∣ = L d = 27 |C|=L^{d}=27 ∣C∣=Ld=27。
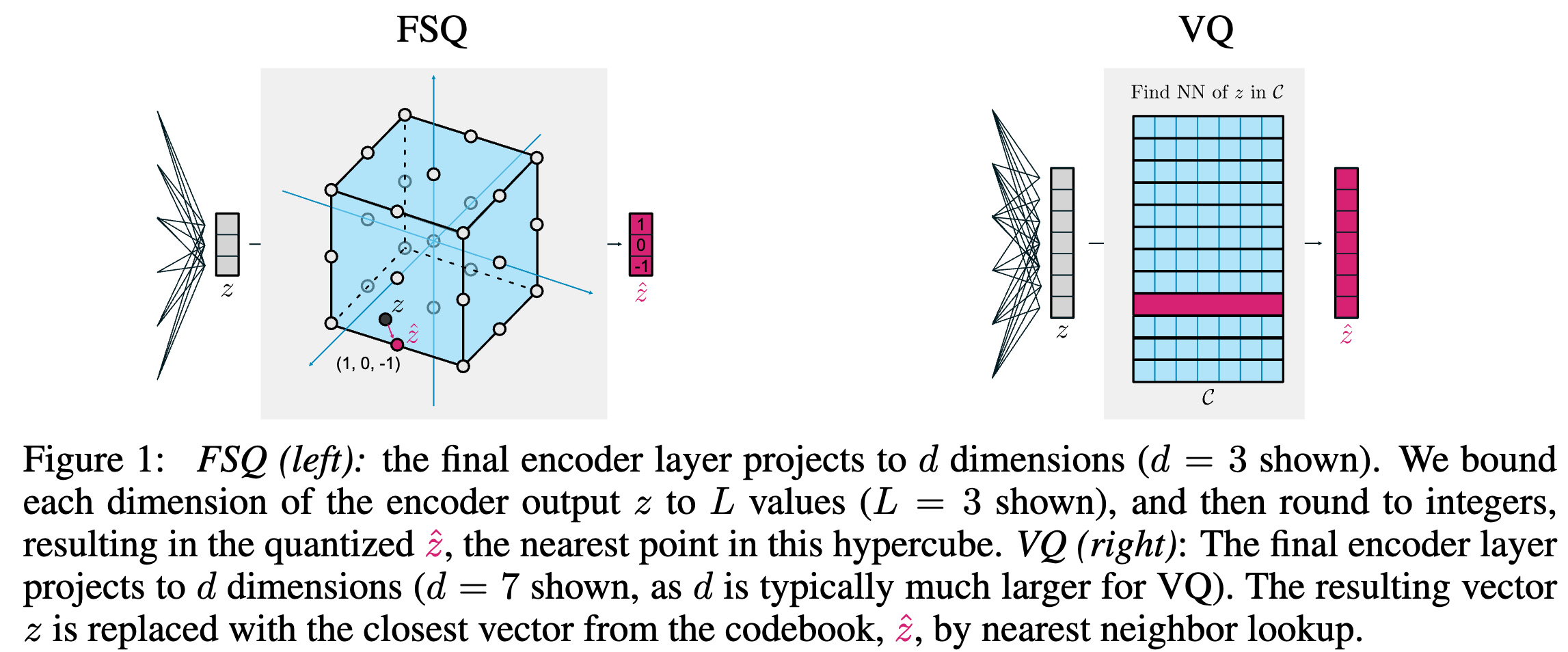
- 比如对于一个具有 d 个 channel 的向量 z,如果将每个条目 zi 映射到 L 个值(比如通过 z i = R o u n d ( ⌊ L / 2 ⌋ t a n h ( z i ) ) z_i = Round(\lfloor L / 2 \rfloor tanh(z_{i})) zi=Round(⌊L/2⌋tanh(zi)) ,其中 Round 是四舍五入算子),则可以获得一个量化后的向量 z ^ \hat{z} z^,其中 z ^ \hat{z} z^ 是 L d L^d Ld 个唯一可能的向量之一。下图展示了 d=3, L=3 的 FSQ,码本 C = ( − 1 , − 1 , − 1 ) , ( − 1 , − 1 , 0 ) , ( − 1 , − 1 , 1 ) , . . . , ( 1 , 1 , 1 ) C = {(−1, −1, −1), (−1, −1, 0), (−1, −1, 1), . . . , (1, 1, 1)} C=(−1,−1,−1),(−1,−1,0),(−1,−1,1),...,(1,1,1),其中码本大小 ∣ C ∣ = L d = 27 |C|=L^{d}=27 ∣C∣=Ld=27。
- 为了让 round 也获得梯度,这里也使用了 STE。因此,使用 FSQ 在使用重构损失训练的自动编码器中,我们获得了对编码器的梯度,这迫使模型将信息分散到多个 quantization bins 中,因为这减少了重构损失。结果是,我们获得了一个使用所有码字的量化器,而不需要任何辅助损失。
- 尽管 FSQ 的设计要简单得多,但本文在图像生成、多模态生成、深度估计等任务中获得了有竞争力的结果。FSQ 的优点是不会遭受码本坍塌(codebook collapse),并且不需要 VQ 中为了避免码本坍塌而使用的复杂机制(承诺损失、码本重新播种、码分割、熵惩罚等)
- 将 VAE 表示投影到少量维度(通常少于10)。每个维度被量化为一组固定的值,由这些数值集合的乘积给出(隐式的)码本 (codebook)
FSQ 超参数
- FSQ具有以下超参数:通道数 d 和每个通道的级别数 L = [L1, . . . , Ld]。在我们的大部分实验中,为了进行公平比较,我们将根据我们打算用 FSQ 替换的 VQ 码书选择目标码书大小 |C|。然而,各种不同的 d 和 Li 的配置都可以近似给定的 |C|。我们在研究中探索了各种配置,并发现并非所有选择都会产生最佳结果。然而,我们发现了一个简单的启发式方法,在所有考虑的任务中表现良好:对于所有i,使用 Li ≥ 5。在表1中,我们列出了常见目标 |C| 的 L 值。
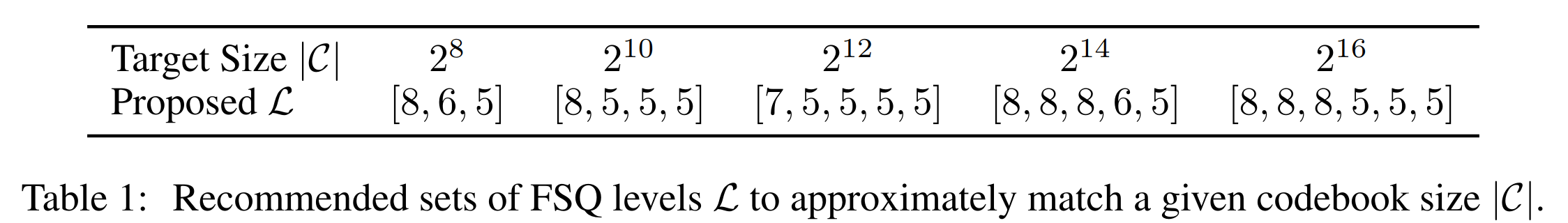
FSQ 参数量
- 我们注意到,与 VQ 相比,FSQ 的参数更少,因为在 VQ 中,会学习一个大小为 |C| · d 的码书。例如,对于典型的 |C|=2^12=4096 和 d=512,这将导致 2M 个参数,而 FSQ 则不具备这些参数。此外,由于对于 FSQ 来说,d 往往比 VQ 小得多(例如,对于这个 |C|,FSQ 的 d 为5,见表1),所以当训练 FSQ 时,最终的编码器层也具有更少的参数。为了弥补这一点,我们探索了在 VAE 编码器末尾或解码器开始处添加更多的全连接层,但发现这样做并没有进一步的收益。因此,在本文中的所有模型中,具有相同码书大小的 FSQ 具有更少的参数。
代码实现
- 主要看 quantization 实现,可以看出来实现方面很简单,不考虑 L 要兼容奇数偶数的情况下,其实量化操作主要就是对输入的 z 非线性缩放后进行四舍五入操作
import jax.numpy as jnp
import numpy as npdef round_ste(z):"""使用直通梯度进行四舍五入。"""zhat = jnp.round(z) # 对输入数组z进行四舍五入return z + jax.lax.stop_gradient(zhat - z) # 返回z加上z和四舍五入后的z的差值,这个差值的梯度会被停止传播class FSQ:"""量化器类。"""def __init__(self, levels: list[int], eps: float = 1e-3):"""初始化量化器。Args:levels (list[int]): 分量化等级列表。eps (float): 用于边界处理的微小值。"""self._levels = levelsself._eps = epsself._levels_np = np.asarray(levels) # 将等级列表转换为NumPy数组self._basis = np.concatenate(([1], np.cumprod(self._levels_np[:-1]))).astype(np.uint32) # 创建基数组self._implicit_codebook = self.indexes_to_codes(np.arange(self.codebook_size)) # 初始化隐式码本@propertydef num_dimensions(self) -> int:"""输入期望的维度数量。"""return len(self._levels)@propertydef codebook_size(self) -> int:"""码本的大小。"""return np.prod(self._levels)@propertydef codebook(self):"""返回隐式码本。形状为 (prod(levels), num_dimensions)。"""return self._implicit_codebookdef bound(self, z: jax.Array) -> jax.Array:"""对形状为 (..., d) 的数组z进行边界处理。"""half_l = (self._levels_np - 1) * (1 - self._eps) / 2 # 计算每个维度的边界offset = jnp.where(self._levels_np % 2 == 1, 0.0, 0.5) # 计算偏移量shift = jnp.tan(offset / half_l) # 计算偏移return jnp.tanh(z + shift) * half_l - offset # 应用边界和偏移def quantize(self, z: jax.Array) -> Codeword:"""量化z,返回量化后的zhat,形状与z相同。"""quantized = round_ste(self.bound(z)) # 对边界处理后的z进行四舍五入# 重新归一化到[-1, 1]区间half_width = self._levels_np // 2return quantized / half_widthdef _scale_and_shift(self, zhat_normalized):# 将归一化后的zhat缩放和偏移,使其范围在[0, ..., L-1]half_width = self._levels_np // 2return (zhat_normalized * half_width) + half_widthdef _scale_and_shift_inverse(self, zhat):# 逆操作,将范围在[0, ..., L-1]的zhat转换回归一化形式half_width = self._levels_np // 2return (zhat - half_width) / half_widthdef codes_to_indexes(self, zhat: Codeword) -> Indices:"""将码转换为码本中的索引。Args:zhat (Codeword): 归一化后的码。Returns:Indices: 码本中的索引。"""assert zhat.shape[-1] == self.num_dimensions # 确保码的维度与期望的维度相同zhat = self._scale_and_shift(zhat) # 缩放和偏移return (zhat * self._basis).sum(axis=-1).astype(jnp.uint32) # 计算索引def indexes_to_codes(self, indices: Indices) -> Codeword:"""`codes_to_indexes`的逆操作。Args:indices (Indices): 码本中的索引。Returns:Codeword: 转换后的码。"""indices = indices[..., jnp.newaxis] # 扩展索引维度codes_non_centered = np.mod(np.floor_divide(indices, self._basis), self._levels_np) # 计算非中心化的码return self._scale_and_shift_inverse(codes_non_centered) # 逆缩放和偏移
Experiments
MaskGIT 与 UViM 回顾
- 首先简要回顾一下 MaskGIT 和 UViM。
- 在MaskGIT中,作者首先训练了一个(卷积)VQ-GAN自编码器用于重建(第一阶段)。然后,他们冻结了自编码器,并训练了一个掩码变换器 BERT style来预测量化表示(第二阶段):给定一个表示 z,随机地“掩盖”一部分 token,即用一个特殊的 MASK token 替换。生成的序列 zM 被馈送到一个 transformer 中,除了一个 class token 外,transformer 为每个被掩盖的 token 预测一个分布。在推断过程中,最初只有 MASK token 和 class token 与 transformer 一起被馈送。然后,根据预测的置信度选择一些 token 位置,并抽样相应的 token。这些 token 用于替换输入中的掩码 token,并且再次运行模型,直到所有输入 token 都被揭示。
- UViM 是一种通用架构,用于解决计算机视觉中的各种(密集)预测任务。在第一阶段,基于 transformer 的 VQ-VAE 被训练来模拟目标任务的标签空间。可选地,VQ-VAE编码器和解码器都可以依赖于任务输入(RGB图像用于深度估计和分割,灰度图像用于着色)作为附加信息或“上下文”,这对于某些任务是有益的。在第二阶段,一个编码器-解码器 transformer 被训练来预测由 VQ-VAE 编码器产生的量化 token 的密集标签,给定任务输入。对于推断,使用条件于输入的 transformer 自回归地对代码进行采样,然后将其馈送给 VQ-VAE 解码器。这个架构对于三个任务是共享的,但是为每个任务学习了不同的权重。
VQ、FSQ 对比的指标
- 基于 MaskGIT 进行对比,对较低分辨率的 128 × 128 ImageNet 图像进行了训练,训练时间较原始论文更短(第一阶段 100 个 epoch,第二阶段 200 个 epoch。这使我们能够调整码本大小和其他超参数。对于 VQ,我们使用了 MaskGIT 的辅助熵损失,旨在增加码本的熵(以增加利用率)。我们只调整码本大小。对于 FSQ,我们探索各种 d 和 Li 来匹配这些码本大小。
- 跟踪以下指标:
- 重建 FID:即当将 50k 验证图像馈送到量化自动编码器时,由 GAN 训练的自动编码器获得的 FID。如果第二阶段 transformer 能够完美地对数据建模,这就是它将实现的理想 FID。
- 码本使用情况:在对验证集进行编码时至少使用了一次的码字的比例。
- sample FID:即第二阶段使用 transformer 对表示 z ^ \hat{z} z^ 进行抽样(按类条件)时获得的 FID
- 压缩成本: 作为模拟表示底层离散分布的困难程度的代理(即,建模复杂性)。请注意,任何预测离散码的分布的 transformer 都可以用于对相应表示进行无损压缩。对于掩码 transformer,唯一的要求是一个确定性的掩码 schedule,逐渐揭示输入。使用这样的 schedule,我们可以通过将 transofmre 输出与熵编码配对,将任何 z ^ \hat{z} z^ 压缩到比特。我们使用了 M2T 中采用的确定性掩码 schedule
训练细节
MaskGIT
- 早期实验表明,与 VQ 相比,FSQ 在 Precision & Recall 点上处于不同的位置(FSQ 具有更高的召回率和更低的精确度)。受扩散文献的启发,因此我们将分类器无关的引导(CFG)添加到 MaskGIT 中:在训练过程中,我们用 MASK 标记替换 10% 的类别标签,以让模型学习无条件分布。在推断过程中,我们对 logits 进行插值:设 l c l_{c} lc 是在给定类别标签 c 的情况下获得的 logits, l ∅ l_{∅} l∅ 是无条件 logits。在推断过程中,我们计算新的 logits l ′ = l c + α ( l c − l ∅ ) l^{′} = l_{c} + α(l_{c} − l_{∅}) l′=lc+α(lc−l∅) ,其中 α 是 CFG 推断权重。直观地说,这将预测的分布拉向无条件分布。这一点之前在 MUSE 里面已经被探讨过。
UVIM
- 三个任务都做实验:panoptic segmentation, depth estimation, colorization
- stage2 会训练 3 次取平均精度
- 评测指标:
- 全景分割使用全景质量(PQ)
- 深度估计使用 RMSE
- 着色使用 FID-5k
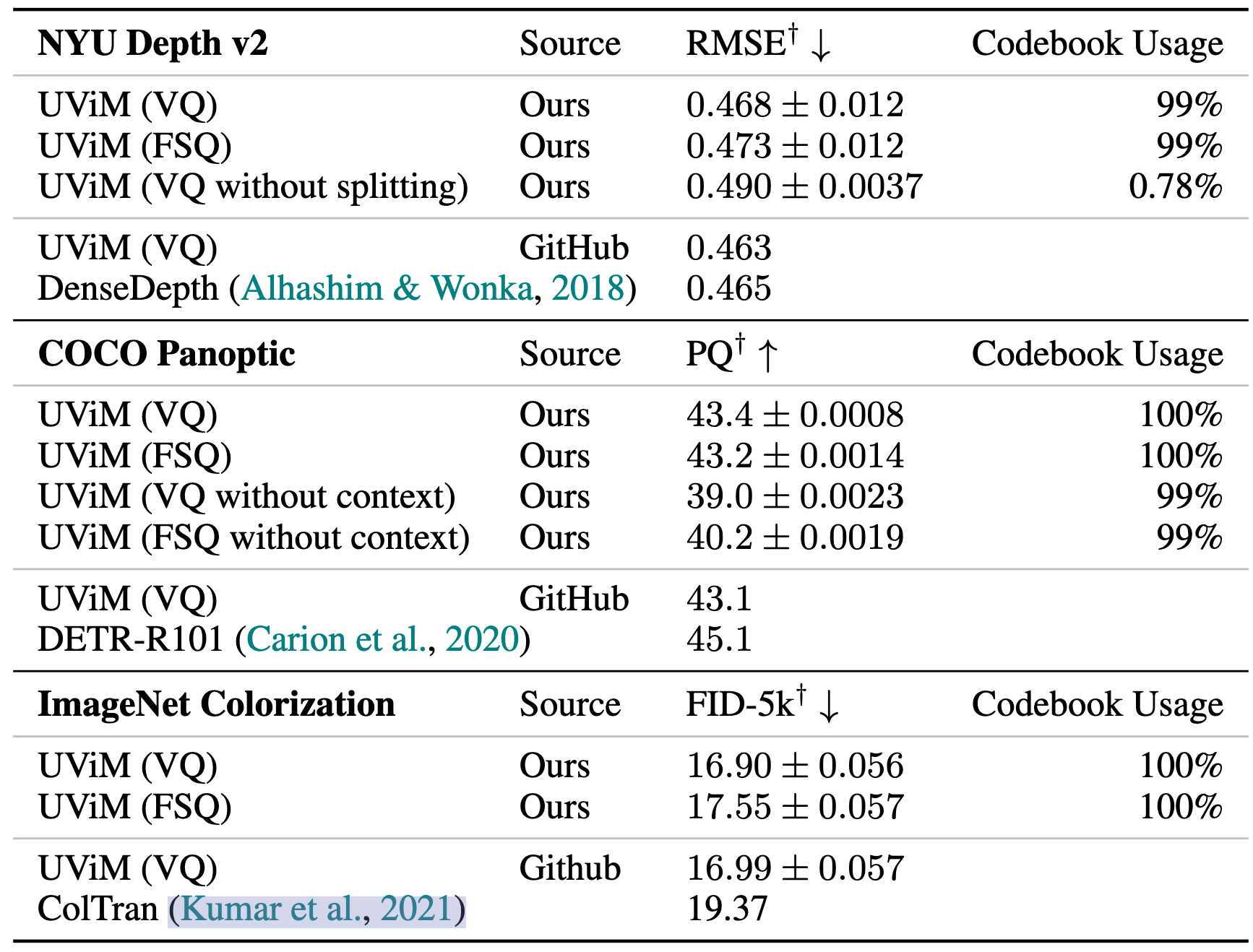
- 实验了 UViM 使用的码本分割策略,以避免在 VQ-VAE 中出现未使用的码字。具体来说,他们采用了 Linde 等人(1980)的算法,在整个训练过程中,检测未使用的向量,然后将这些向量替换为将最常用的嵌入拆分为两个新的嵌入,并为每个嵌入添加噪声。由于我们观察到在全景分割任务中关闭码本分割时出现了训练不稳定性,我们使用深度估计任务进行此项消融研究。
VQ 对比 FSQ
- 128px Imagenet 实验:
- FSQ 当 codebook size 越大重建 FID 越低,比 VQ 更适合大 codebook(VQ 在 2^11 下精度最高,再增加 codebook 利用率就逐渐降低了)
- 低 codebook size 下 VQ 略优于 FSQ,原因主要是 VQ 表达能力天生更强
- 生成精度随着 codebook size 增加 FSQ 也是变好的
- codebook 利用率 FSQ 更高(2^14 下基本全部使用,之后略有下降)
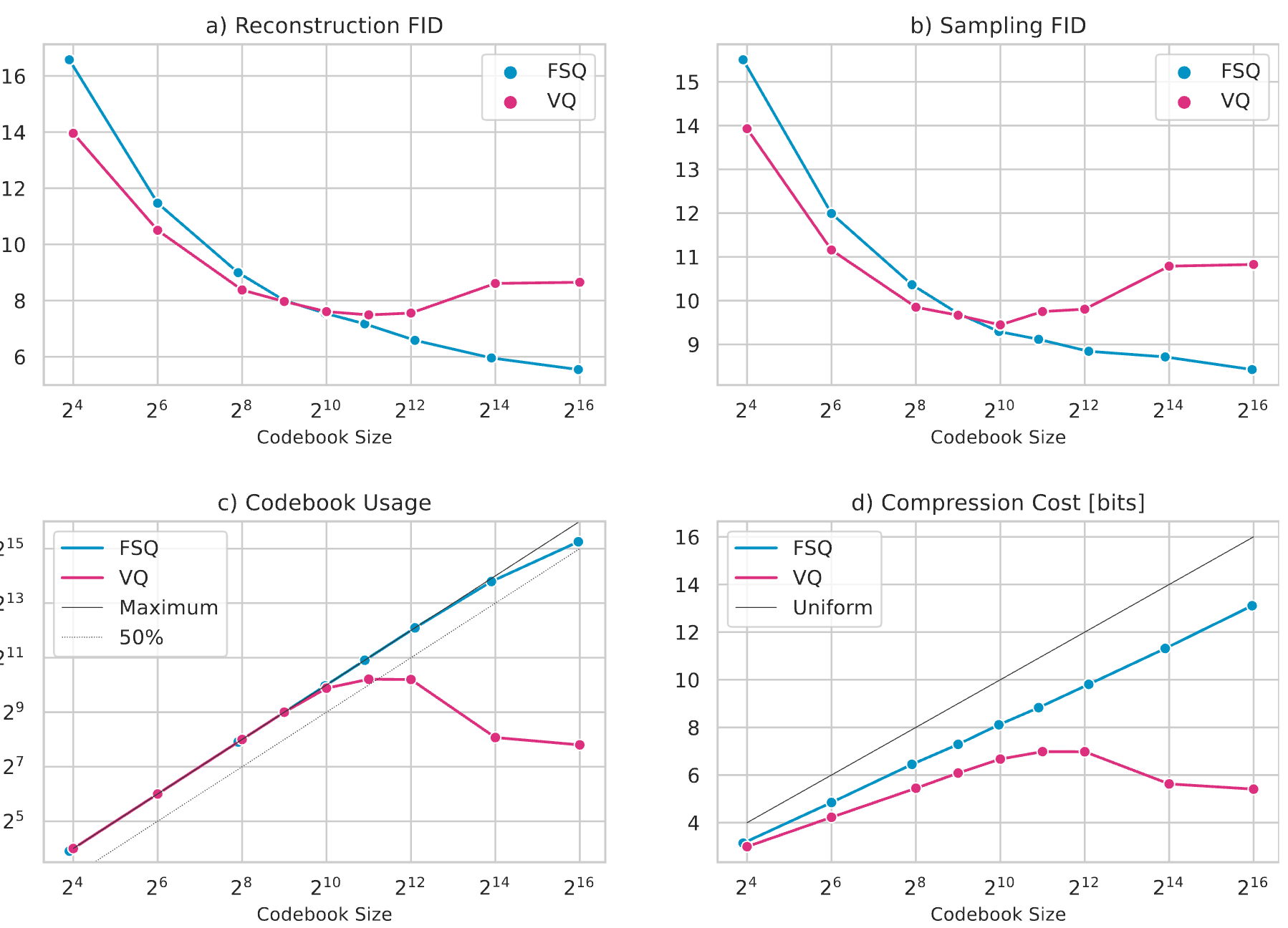
- 如果再继续增加 codebook size,sample FID 能否继续增加?
- 作者认为不能。因为如上图 d 所示,表示的压缩成本不断增加。这表明对于 transformer 来说,量化表示变得越来越复杂了。2^12 codebook 之后再增加精度趋向饱和。
MaskGIT 实验
- 定量对比:VQ 和 FSQ 精度接近

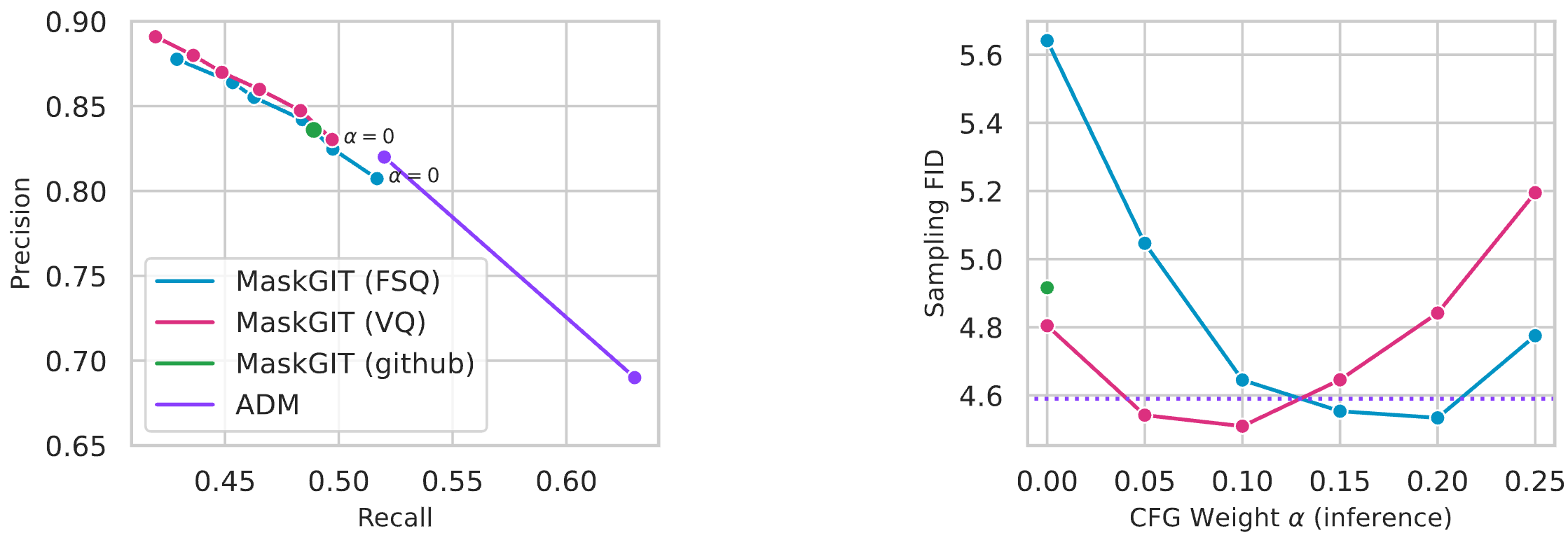
- 可视化对比:效果接近

UViM 实验
- 定量对比:FSQ 比 VQ 精度差不多,FSQ 稍差一点
- 可视化对比

Thoughts
- 消除 vq 的各种辅助损失看起来很有吸引力
- FSQ 精度上比 vq 并没有明显优势,这里可能还有优化空间