跨越千年医学对话:用AI技术解锁中医古籍知识,构建能够精准问答的智能语言模型,成就专业级古籍解读助手(LLAMA)
介绍:首先在 Ziya-LLaMA-13B-V1基线模型的基础上加入中医教材、中医各类网站数据等语料库,训练出一个具有中医知识理解力的预训练语言模型(pre-trained model),之后在此基础上通过海量的中医古籍指令对话数据及通用指令数据进行有监督微调(SFT),使得模型具备中医古籍知识问答能力。
0.模型信息 Model Information
| 需求 Demand | 任务 Task | 系列 Series | 模型 Model | 参数 Parameter | 额外 Extra |
|---|---|---|---|---|---|
| 通用 General | AGI 模型 | 姜子牙 Ziya | LLaMA | 13B | English&Chinese |
- Brief Introduction
姜子牙通用大模型V1是基于LLaMa的130亿参数的大规模预训练模型,具备翻译,编程,文本分类,信息抽取,摘要,文案生成,常识问答和数学计算等能力。目前姜子牙通用大模型已完成大规模预训练、多任务有监督微调和人类反馈学习三阶段的训练过程。
pip install torch==1.12.1 tokenizers==0.13.3 git+https://github.com/huggingface/transformers0.1继续预训练 Continual pretraining
原始数据包含英文和中文,其中英文数据来自 openwebtext、Books、Wikipedia 和 Code,中文数据来自清洗后的悟道数据集、自建的中文数据集。在对原始数据进行去重、模型打分、数据分桶、规则过滤、敏感主题过滤和数据评估后,最终得到 125B tokens 的有效数据。
为了解决 LLaMA 原生分词对中文编解码效率低下的问题,我们在 LLaMA 词表的基础上增加了 7k + 个常见中文字,通过和 LLaMA 原生的词表去重,最终得到一个 39410 大小的词表,并通过复用 Transformers 里 LlamaTokenizer 来实现了这一效果。
在增量训练过程中,我们使用了 160 张 40GB 的 A100,采用 2.6M tokens 的训练集样本数量和 FP 16 的混合精度,吞吐量达到 118 TFLOP per GPU per second。因此我们能够在 8 天的时间里在原生的 LLaMA-13B 模型基础上,增量训练 110B tokens 的数据。
训练期间,虽然遇到了机器宕机、底层框架 bug、loss spike 等各种问题,但我们通过快速调整,保证了增量训练的稳定性。我们也放出训练过程的 loss 曲线,让大家了解可能出现的问题。
0.2 多任务有监督微调 Supervised finetuning
在多任务有监督微调阶段,采用了课程学习(curiculum learning)和增量训练(continual learning)的策略,用大模型辅助划分已有的数据难度,然后通过 “Easy To Hard” 的方式,分多个阶段进行 SFT 训练。
SFT 训练数据包含多个高质量的数据集,均经过人工筛选和校验:
- Self-Instruct 构造的数据(约 2M):BELLE、Alpaca、Alpaca-GPT4 等多个数据集
- 内部收集 Code 数据(300K):包含 leetcode、多种 Code 任务形式
- 内部收集推理 / 逻辑相关数据(500K):推理、申论、数学应用题、数值计算等
- 中英平行语料(2M):中英互译语料、COT 类型翻译语料、古文翻译语料等
- 多轮对话语料(500K):Self-Instruct 生成、任务型多轮对话、Role-Playing 型多轮对话等
0.3 人类反馈学习 Human-Feedback training
为了进一步提升模型的综合表现,使其能够充分理解人类意图、减少 “幻觉” 和不安全的输出,基于指令微调后的模型,进行了人类反馈训练(Human-Feedback Training,HFT)。在训练中,我们采用了以人类反馈强化学习(RM、PPO)为主,结合多种其他手段联合训练的方法,手段包括人类反馈微调(Human-Feedback Fine-tuning,HFFT)、后见链微调(Chain-of-Hindsight Fine-tuning,COHFT)、AI 反馈(AI Feedback)和基于规则的奖励系统(Rule-based Reward System,RBRS)等,用来弥补 PPO 方法的短板,加速训练。
我们在内部自研的框架上实现了 HFT 的训练流程,该框架可以利用最少 8 张 40G 的 A100 显卡完成 Ziya-LLaMA-13B-v1 的全参数训练。在 PPO 训练中,我们没有限制生成样本的长度,以确保长文本任务的奖励准确性。每次训练的总经验池尺寸超过 100k 样本,确保了训练的充分性。
1.训练数据
1.1 继续预训练数据(纯文本语料)约0.5G
包含两部分:①中医教材数据:收集“十三五”规划所有中医教材共22本。②在线中医网站数据:爬取中医世家、民间医学网等在线中医网站及知识库。
- 通用指令微调数据
Alpaca-GPT4 52k 中文
-
alpaca_gpt4_data.json包含由 GPT-4 生成的 52K 指令跟随数据,并带有 Alpaca 提示。该 JSON 文件与 Alpaca 数据具有相同的格式,只是输出由 GPT-4 生成的:instruction:str,描述模型应执行的任务。每条 52K 指令都是唯一的。input:str,任务的任选上下文或输入。output:str,指令的答案由生成GPT-4。
-
alpaca_gpt4_data_zh.json包含由 GPT-4 生成的 52K 指令跟踪数据,并由 ChatGPT 翻译成中文的 Alpaca 提示。此 JSON 文件具有相同的格式。 -
comparison_data.json通过要求GPT-4评估质量,对GPT-4、GPT-3.5和OPT-IML等透明模型的响应进行排名。user_input:str,用于查询LLM的提示。completion_a:str,一个模型完成,其排名完成_b。completion_b:str,不同的模型完成,其质量得分较低。
-
unnatural_instruction_gpt4_data.json包含由 GPT-4 生成的 9K 指令跟随数据,并带有非自然指令中的提示。此 JSON 文件与 Alpaca 数据具有相同的格式。
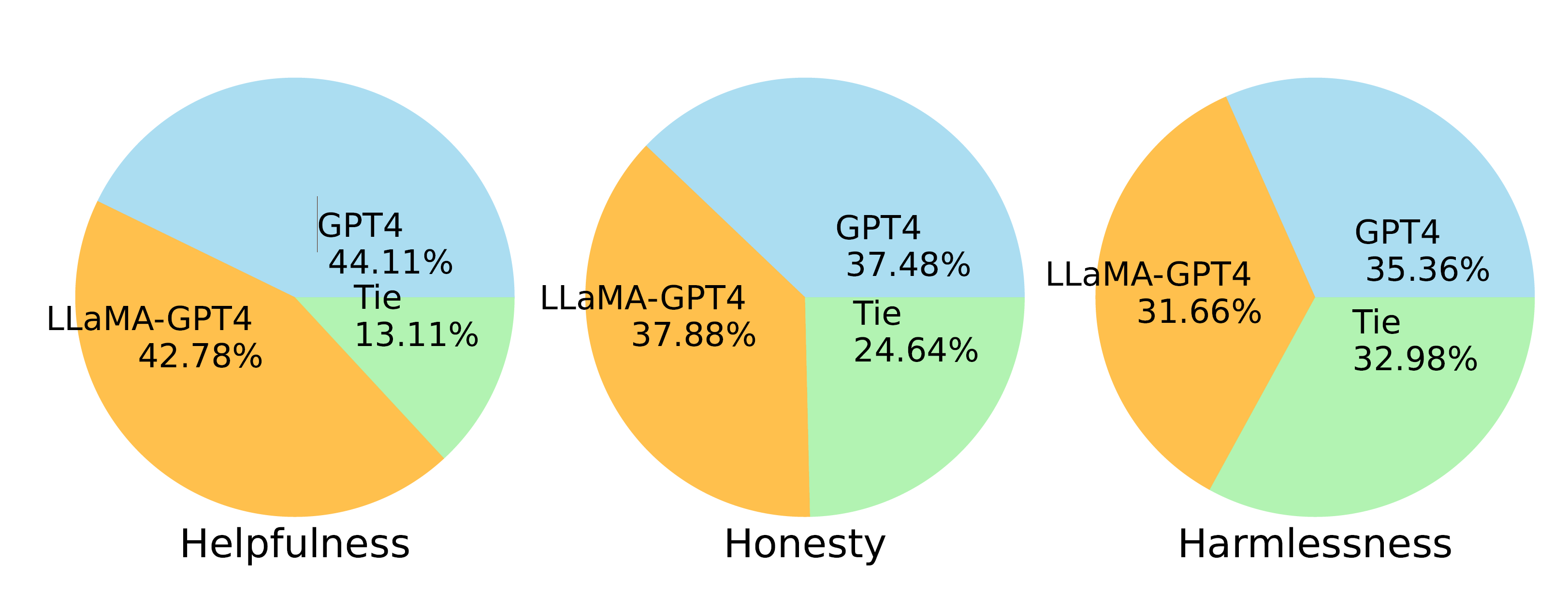
- 比较了两种指令调整的 LLaMA 模型,分别根据 GPT-4 和 GPT-3 生成的数据进行微调。
- 在“有用性”标准中,LLaMA-GPT-4 的表现明显优于 LLaMA-GPT-3。
- LLaMA-GPT-4 在所有三个标准中的表现与原始 GPT-4 相似,这为开发最先进的遵循指令的 LLM 提供了一个有希望的方向。
1.2 中医古籍指令对话数据
- 语料库来源
以《中华医典》数据库为语料来源,约338MB,由两部分组成:①非结构化的“古籍文本”:涵盖了886本标点符号及内容完整的中医古籍。②结构化的“古籍辞典”:包含“名医”、“名言”、“名词”、“名著”等六大类,由中医学界诸多知名学者对中医古籍内容知识进一步系统提炼整理,是中医古籍内容精华最为直接的集中体现。
构建指令微调对话数据集
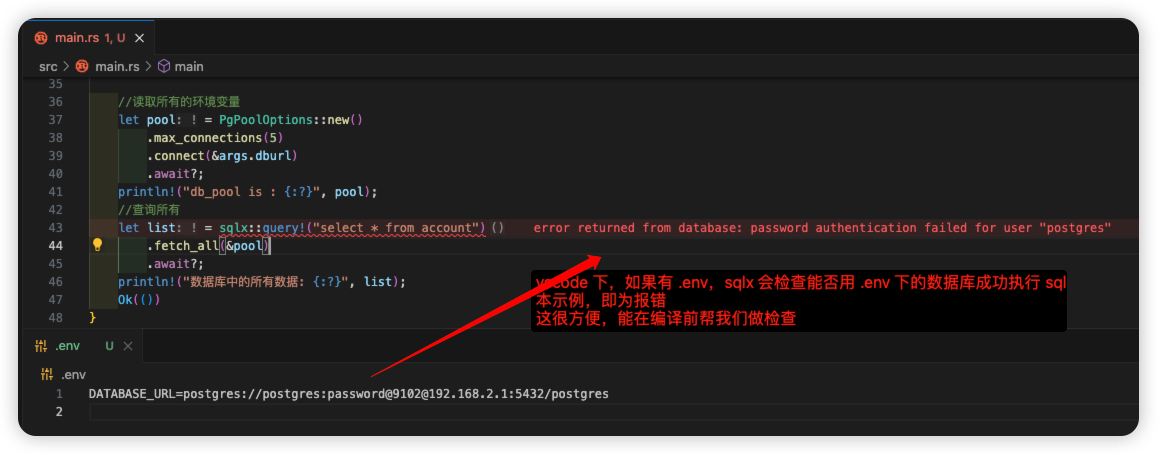
通过知识引导的指令数据生成和指令数据质量优化两个阶段,最终获得504372个对话数据。
- 知识引导的指令数据生成
让ChatGPT基于对该段中医古籍的知识内容理解,模拟用户与AI,通过自问自答的方式,生成逻辑关系相关的若干问题和答案,从而保证对话数据的准确性和可靠性。 - 指令数据质量优化
尽管基于知识引导使得生成的指令数据基于特定领域,并且与所提供的无监督文本内容相关,避免了模型内部“已有知识”的干扰。然而这种方法难以对数据质量进行监督和控制,也难以保证指令数据的多样性和难度,这可能导致大模型对指令数据集的过度拟合。为了解决这个问题,我们在现有指令数据集的基础上,通过指令数据过滤-指令数据整合两个阶段对数据进行二次优化。
中医古籍指令数据种类概览(共504372条对话数据)
| 对话类型 | 数量 | 对话类型 | 数量 |
|---|---|---|---|
| 医经理论 | 40410 | 温病类 | 10288 |
| 诊法治法 | 14184 | 综合医书 | 86413 |
| 本草方书 | 144993 | 临证各科 | 56872 |
| 针灸推拿灸 | 31009 | 中医问诊 | 76765 |
| 伤寒金匮 | 29602 | 预防养生 | 13836 |
2.模型训练
2.1实验参数
| 超参数 | 继续预训练 | 有监督微调 | DPO优化 |
|---|---|---|---|
| learning_rate | 6e-5 | 3e-4 | 3e-4 |
| lora_rank | 16 | 16 | 16 |
| num_train_epochs | 5 | 6 | 6 |
| per_device_train_batch_size | 8 | 16 | 8 |
| per_device_eval_batch_size | - | 16 | - |
| gradient_accumulation_steps | 4 | 4 | 4 |
| lr_scheduler_type | cosine | cosine | cosine |
| logging_steps | 1000 | 100 | 100 |
| save_steps | 2000 | 5000 | 2000 |
| train_loss | 1.456 | 1.245 | 0.00276 |
| eval_loss | - | 1.258 | - |
2.2模型下载-LoRA权重
| 模型名称 | 大小 | 下载地址 |
|---|---|---|
| pretrain | 25.05MB | 下载地址 |
| sft | 25.05MB | 下载地址 |
| dpo | 50.16MB | 下载地址 |
3.模型效果
| 应用示例 | Input | 通义千问 | Huang-Di |
|---|---|---|---|
| 医经理论 | 中医古籍中的“阴虚之热”和“阴盛格阳之火”分别应该如何进行治疗? | 很抱歉呀,目前我还没有掌握回答这个问题的技巧,我会不断学习,您也可以问我一些其他问题,我会努力给您解答。 | 在中医中,“阴虚之热”是由于人体内阴气不足、水液不行、真阴耗伤等原因所致的虚火症状。对于阴虚之热的治疗,建议采用滋补阴液的方法,如六味地黄丸等中药进行治疗,能够缓解症状,达到滋阴降火的效果。而“阴盛格阳之火”则是指人体内阳气不足、阴气过盛、火热亢盛等导致的虚火症状。对于阴盛格阳之火的治疗,建议采用温补阳气的方法进行治疗,如附子干姜肉桂等中药能够温补阳气,从而产生脾胃运化之功,消除虚火症状。总的来说,中医认为实火宜泻、虚火宜补,从病因和症状分析,采用不同的治疗方法,有利于恢复人体内阴阳平衡,达到疾病的治疗和康复效果。 |
| 诊法治法 | 如何判断一个人阴阳失调? | 中医认为,阴阳失调是指人体内阴阳两种力量的失衡,通常表现为身体的不适和疾病。可以通过观察一个人的症状来判断其是否阴阳失调,例如:体温过高或过低、头痛、口干、口臭、腹泻、便秘、失眠、多梦、焦虑、抑郁等。另外,可以通过检查一个人的脉搏和舌苔来进一步判断其阴阳失调的情况。 | 阴阳失调是中医理论中的重要概念,它指的是身体内部阴阳两种力量之间的不平衡。通常来说,判断一个人是否存在阴阳失调需要从以下几方面入手:1.观察外貌特征:阴虚、阳盛型的患者通常容易出现脸色苍白、瘦弱等症状;而阳虚、阴盛型的患者则可能表现为面色红润、肥胖等情况。2.检查舌苔:中医认为舌质和舌苔可以反映脏腑功能的变化。例如,阴虚型患者的舌质可能较薄,舌苔可能较厚;而阳虚型患者的舌质可能较厚,舌苔可能较薄。3.询问病史:了解患者过去是否有过类似疾病或者长期服用某些药物也可以帮助诊断阴阳失调。4.检测体温:阴虚型患者往往会出现低热、寒战等症状,而阳虚型患者则可能出现高热、汗多等情况。 |
| 针灸推拿灸 | 古籍中九刺是什么? | 九刺是中医针灸学中的一种治疗方法,也称为“九针”。九刺是指使用九根针具,通过不同的刺激方式和手法,对特定的穴位进行刺激,以达到治疗疾病的目的。九刺的应用范围非常广泛,可以用于治疗各种疾病,如肩周炎、腰痛、坐骨神经痛、痛风等。 | 九刺指的是中医中古代的九种刺法,分别是输刺、远道刺、经刺、络刺、分刺、大泻刺、毛刺、巨刺、淬刺。在《灵枢经》的《官针》条中就提到:“凡刺有九,以应九变”,也就是说,九种不同的刺法适用于不同的病变。其中,输刺是通过针刺使病邪随汗液排出;远道刺是在病变部位远处刺激;经刺是通过刺激经脉穴位将病邪排出;络刺是刺激络脉,达到类似经刺的效果;分刺是将病变部位分成若干小部分进行刺激;大泻刺是快速放血,将有毒血液排出体外;毛刺是将针头刺入皮肤表层,产生微刺激;巨刺则是在病变部位直接刺出大量污血;淬刺是将针先烤热后再刺激穴位。九刺的运用需要根据不同的疾病情况灵活选择,是中医治疗的重要手段之一。 |
| 中医问诊 | 最近我怀孕了,但是感到神疲无力、面色黯淡、腰酸腹痛并且出现阴道流血的症状,这是否属于血虚滑胎的情况?请问怎样治疗? | 首先,我要强调的是,我不是医生,我只能提供一些建议。如果你怀孕期间出现这些症状,请务必咨询专业的医生。血虚滑胎是中医中的一个概念,通常是指孕妇血液不足,导致胎儿不稳定,容易流产。但是,出现这些症状并不一定就是血虚滑胎,可能是其他原因引起的。因此,建议你及时就诊,让医生进行详细检查,确诊原因。在确诊后,医生会根据具体情况给出相应的治疗方案。对于血虚滑胎的治疗,中医可能会采用补血、安胎的方法,比如服用一些补血的药物,如当归、红枣、枸杞等。此外,还需要注意休息,保持良好的生活习惯,避免过度劳累,保持情绪稳定等。总之,如果你怀孕期间出现这些症状,请务必及时就诊,让专业的医生进行诊断和治疗。希望你和宝宝都健康平安! | 是的,你的症状很可能是血虚滑胎引起的。血虚滑胎是指由于孕妇平时血虚及有滑胎病史,怀孕后阴血益虚导致胎儿失去滋养而引起的情况。其中症状包括神疲无力、面色淡黄、浮肿、腰酸腹痛,而且严重的话还会出现阴道流血和胎动欲坠等症状。对于血虚滑胎的治疗,应该以补血益气为主,以此来预防滑胎的发生。常用的中药方剂包括胎元饮,该方剂的组成包括人参、当归、杜仲、芍药、熟地、白术、陈皮、炙甘草等,可起到补气补血的作用。如果出现下血症状,还可以加入阿胶和艾炭等药物。需要强调的是,血虚滑胎的治疗应该遵循个性化的原则,应根据孕妇的具体情况而定。另外,饮食调理、心理调节等方面的治疗也非常重要,这些措施可以有效地提高孕妇血液的养分含量,提高孕妇免疫力,从而预防或缓解血虚滑胎产生的症状。如果出现滑胎症状,建议及时就医,并且采取综合治疗。"希望我的回答能够对你有所帮助。如果你还有其他问题,请随时向我提问。祝你健康快乐! |
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
模型下载链接
https://download.csdn.net/download/sinat_39620217/88860093?spm=1001.2101.3001.9500
- 参考链接
1.https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1
2.https://github.com/ymcui/Chinese-LLaMA-Alpaca
3.https://github.com/huggingface/peft