| 模型 | 模型参数 | 创新点 | 评价 |
|---|---|---|---|
| GPT1 | 预训练+微调, 创新点在于Task-specific input transformations。 | ||
| GPT2 | 15亿参数 | 预训练+Prompt+Predict, 创新点在于Zero-shot | Zero-shot新颖度拉满,但模型性能拉胯 |
| GPT3 | 1750亿参数 | 预训练+Prompt+Predict, 创新点在于in-context learning | 开创性提出in-context learning概念,是Prompting祖师爷(ICL)是Prompting范式发展的第一阶段。 |
1.GPT
Improving Language Understanding by Generative Pre-Training
paper: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
1.1.Abstract
目前NLU(Natural Language Understanding)方向的局限性:有标签的数据相对较少,限制了模型性能的提升。此外,目前预训练语言模型存在一定的局限性:
1.不能通用:不同损失函数在各个任务上表现差异大,训练数据集并没有包含各个NLP任务。
2.不统一:将预训练语言模型迁移到下游任务的方法不统一,不同的子任务,有时还需要调整模型结构。
GPT的基本思想是:先在大规模没有标签的数据集上训练一个预训练模型,即generative pre-training的过程,再在子任务小规模有标签的数据集上训练一个微调模型,即discriminative fine-tuning的过程。
GPT模型是在Google BERT模型之前提出的, 与BERT最大的区别在于GPT采用了传统的语言模型方法进行预训练, 即使用单词的上文来预测单词, 而BERT是采用了双向上下文的信息共同来预测单词.正是因为训练方法上的区别, 使得GPT更擅长处理自然语言生成任务(NLG), 而BERT更擅长处理自然语言理解任务(NLU)。 很多时候我们说BERT和GPT的区别在于编码器和解码器,其中编码器可以看到全部而解码器只能看到部分,这个说法其实非常不准确。真正不一样的地方在于预训练任务(以及其对应的目标函数)。GPT的预训练任务是下一个词预测,这比BERT的完形填空难得多,因为它要预测一个开放式的结局。
“这是导致GPT在训练上和效果上比BERT差很多的重要原因。但如果你的模型真的能够预测未来的话,它的能力要比BERT这样的模型强大很多。这就是为什么作者要一直不断把模型做大,一直不断努力,最终造出了GPT-3那样子惊艳的东西。OpenAI选择了一个更难的技术路线,但可能它的天花板也就更高了。”——李沐
1.2.Model Construction
GPT-1选择使用Transformer结构,是因为在NLP的相关任务中,Transformer学到的features更稳健。与循环神经网络等其他模型相比,Transformer提供了更结构化的长期记忆,这有利于文本中的长期依赖关系的处理,从而更好的抽取句子层面和段落层面的语义信息。
GPT-1利用了任务相关的输入一个表示,将结构化文本输入作为一个连续的token序列进行处理。
经典的Transformer Decoder Block包含3个子层, 分别是Masked Multi-Head Attention层, Encoder-Decoder Attention层, 以及最后的一个全连接层。
GPT是一个Decoder-Only的结构,他根本就没有编码器,自然无从从编码器中获得Key和Value! 因此,在Decoder-Only的魔改Transformer中,我们往往会取消第二个Encoder-decoder Attention子层, 只保留Masked Multi-Head Attention层, 和Feed Forward层
- Embedding:词嵌入+位置编码
- 带掩码的多头自注意力机制,让当前时间步和后续时间步的信息的点积在被softmax后都为零
- 输出的向量输入给一个全连接层,而后再输出给下一个Decoder。
- GPT有12个Decoder,经过他们后最终的向量经过一个logit的linear层、一个softmax层,就输出了一个下一个词的概率分布函数。
- 输出的词会作为下一个词的输入。

GPT的训练范式:预训练+Fine-Tuning
1.3.无监督预训练
GPT-1的无监督预训练是基于语言模型进行训练的,给定一个无标签的序列 U = { u 1 , u 2 , . . . , u n } U=\{u_1,u_2,...,u_n\} U={u1,u2,...,un}, GPT1的基础框架:
h 0 = U W e + W p h l = t r a n s f o r m e r ( h l − 1 ) P ( u ) = s o f t m a x ( h n W e T ) \begin{aligned} h_0&=UW_e+W_p \\ h_l&=transformer(h_{l-1})\\ P(u)&=softmax(h_nW_e^T) \\ \end{aligned} h0hlP(u)=UWe+Wp=transformer(hl−1)=softmax(hnWeT)
其中, W e W_e We:表示词嵌入矩阵; W p W_p Wp:表示位置嵌入矩阵; W e T W_e^T WeT:表示线性映射层对应的参数矩阵,维度是词表的大小。
语言模型的优化目标是最大化下面的似然值: L 1 ( U ) = Σ i l o g P ( u i ∣ u i − k , . . . , u i − 1 ; θ ) L_1(U)=\Sigma_ilogP(u_i|u_{i-k},...,u_{i-1};\theta) L1(U)=ΣilogP(ui∣ui−k,...,ui−1;θ)
其中,k:表示是滑动窗口的大小,即每次预测单词时的句子长度; θ \theta θ:表示模型参数;P:表示条件概率。
1.4.有监督微调
当得到无监督的预训练模型后,可以将该模型直接应用到有监督任务中。每个实例有 m m m个输入 x 1 , x 2 , . . . , x m x^1,x^2,...,x^m x1,x2,...,xm ,以及标签y组成。首先将这些token输入到预训练的GPT1中,得到最终的特征向量 h l m h_l^m hlm,然后再通过一个全连接层得到预测结果y:
P ( y ∣ x 1 , x 2 , . . . , x m ) = s o f t m a x ( h l m W y ) \begin{aligned} P(y|x^1,x^2,...,x^m)&=softmax(h_l^mW_y) \end{aligned} P(y∣x1,x2,...,xm)=softmax(hlmWy)
有监督的目标是最大化以下损失:
L 2 ( C ) = Σ l o g P ( y ∣ x 1 , x 2 , . . . , x m ) \begin{aligned} L_2(C)&=\Sigma logP(y|x^1,x^2,...,x^m) \\ \end{aligned} L2(C)=ΣlogP(y∣x1,x2,...,xm)
GPT1中,作者并没有直接使用L2,而是使用联合的损失,并使用 λ \lambda λ进行两个任务权值的调整 λ \lambda λ的值一般为0.5:
L 3 ( C ) = L 1 ( C ) + L 2 ( C ) \begin{aligned} L_3(C)&=L_1(C)+L_2(C) \\ \end{aligned} L3(C)=L1(C)+L2(C)
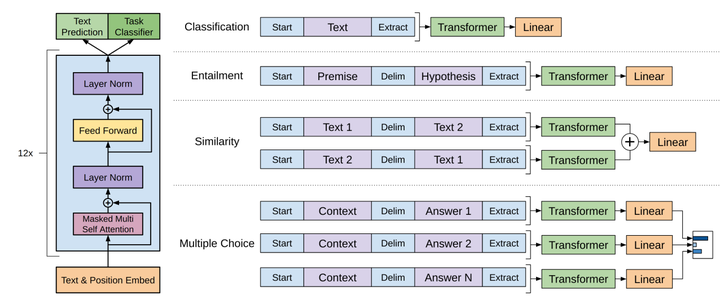
-
文本分类:可以看到,有两个特殊符号(Start和Extract)加了一个线性层。
-
蕴含理解:给一段话,提出一个假设,看看假设是否成立。将前提(premise)和假设(hypothesis)通过分隔符(Delimiter)隔开,两端加上起始和终止token。再依次通过transformer和全连接得到预测结果;
-
文本相似:断两段文字是不是相似。相似是一个对称关系,A和B相似,那么B和A也是相似的;所以参考那张图,先有Text1+分隔符+Text2,再有Text2+分隔符+Text1,两个序列分别经过Transformers后,各自得到输出的向量;我们把它按元素加到一起,然后送给一个线性层。这也是一个二分类问题。
-
问答:多个序列,每个序列都由相同的问题Context和不同的Answer构成。如果有N个答案,就构造N个序列。每个QA序列都各自经过Transformers和线性层,对每个答案都计算出一个标量;最后经过softmax生成一个各个答案的概率密度分布。这是一个N分类问题。
GPT1买点:
通过这样的方法,这四个自任务就都变成了序列+标注的形式。尽管各自的形式还是稍微有一些不一样,但不管输入形式如何、输出构造如何,中间的Transformer他是不会变的。不管怎样,我们都不去改图中的Transformer的模型结构,这是GPT和之前工作的区别,也是这篇文章的一个核心卖点。
1.5.GPT与BERT
GPT和BERT的区别:
GPT使用的Transformer的Decoder层(目标函数为标准的语言模型,每次只能看到当前词之前的词,需要用到Decoder中的Masked attention),
BERT使用的Transformer的Encoder层(目标函数为带[Mask]的语言模型,通过上下文的词预测当前词,对应Encoder)
为什么GPT的性能比BERT差:
GPT预训练时的任务更难(BERT的base就是为了和GPT对比,参数设定几乎一样);
BERT预训练用的数据集大小几乎是GPT的四倍;
2.GPT2
Language Models are Unsupervised Multitask Learners
paper: https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
2.1.Abstract
基于GPT1和BERT的工作,发现GPT1这种上下文生成应用面更广以及BERT使用编码器和大规模数据集获得了更好的实验效果。一个使用了解码器,一个使用了编码器,换做作者是你,你是否还会继续打回去?GPT2的目的就是做这个事情,模型更大,数据更多,效果是否能干掉BERT。
作者收集了一个更大的数据集WebText,百万网页数据,同时将模型从1亿参数(110M)变成了15亿参数(1.5B)但存在一个问题,数据集上去了,效果真的有明显的优势吗?于是作者想到了zero-shot这个路子。
2.2.Model Construction
- 数据: 多任务+大规模数据
- zero shot, 序列的改造使不同任务的输入序列与训练时见到的文本长得一样。
- 模型:在GPT-1上的调整
- 后置层归一化( post-norm )改为前置层归一化( pre-norm )
- 在模型最后一个自注意力层之后,额外增加一个层归一化;
- 调整参数的初始化方式,按残差层个数进行缩放,缩放比例为 1 : sqrt(n)
- 输入序列的最大长度从 512 扩充到 1024;
- 模型层数扩大
GPT2的训练范式:预训练+Prompt predict (zero-shot learning)
2.3.无监督预训练
同上述GPT1一样。
2.4.zero-shot predict
下游任务转向做zero-shot而放弃微调,相较于GPT,出现一个新的问题:样本输入的构建不能保持GPT的形态,因为模型没有机会学习Start,Delim,Extract这些特殊token。因此,GPT-2使用一种新的输入形态:增加文本提示,后来被称为prompt(不是GPT-2第一个提出,他使用的是18年被人提出的方案)。
下面将介绍zero-shot的由来,即背后的思想
2.4.1.多任务学习
现在的语言模型泛化能力比较差,在一个训练集、一个训练任务上训练出来的参数很难直接用到下一个模型里。因此,目前大多数模型都是Narrow Expert,而不是Competent Generalists。OpenAI希望朝着能够执行许多任务的更通用的系统发展–最终不需要为每个任务手动创建和标记训练数据集。
多任务学习的定义:
多任务学习(Multi-Task Learning, MTL)是一种机器学习方法,它可以通过同时学习多个相关的任务来提高模型的性能和泛化能力。与单任务学习只针对单个任务进行模型训练不同,多任务学习通过共享模型的部分参数来同时学习多个任务,从而可以更有效地利用数据,提高模型的预测能力和效率。
如何做到多任务学习呢:
把所有的任务都归结为上下文的问题回答。具体的,应该满足如下的条件:
-
必须对所有任务一视同仁,也就是喂给模型的数据不能包含这条数据具体是哪个任务,不能告诉模型这条数据是要做NMT,另一条数据要做情感分类。
-
模型也不能包含针对不同任务的特殊模块。给模型输入一段词序列,模型必须学会自己辨别这段词序列要求的不同的任务类型,并且进行内部切换,执行不同的操作。
-
此外,模型还应具备执行这10个任务之外的任务的能力,即zero shot learning。
Multitask Question Answering Network, MQAN这篇文章中提出了一个新的在没有任何特定任务模块或参数的情况下联合学习decaNLP的所有任务。把各种下游子任务都转换为QA任务,并且让模型通过我们告诉他的自然语言**(Prompt)**去自动执行不同的操作,从而完成任务的想法也是GPT-2的关键。这就是为什么提出GPT-2的论文的标题叫:Language Models are Unsupervised Multitask Learners
2.4.2.Zero-shot相关细节
GPT-2 最大的改变是抛弃了前面“无监督预训练+有监督微调”的模式,而是开创性地引入了 Zero-shot 的技术,即预训练结束后,不需要改变大模型参数即可让它完成各种各样的任务。
Zero-shot的含义:
我们用预训练模型做下游任务时,不需要任何额外的标注信息,也不去改模型参数。
GPT1过度到GPT2的zero-shot:
GPT1中,我们的模型在自然语言上进行预训练,到了给下游任务做微调的时候,我们是引入了很多模型之前从来没有见过的特殊符号,这个符号是针对具体的任务专门设计的,即给GPT的输入进行了特殊的构造,加入了开始符、结束符、分割符。这些符号,模型要在微调的过程中慢慢认识。
如果想要做Zero-short Learning,即不做任何额外的下游任务训练的话,就没办法让模型去临时学习这些针对特定任务的构造了。因此,我们在构造下游任务的输入的时候,就不能引入特殊的符号,而是要让整个下游任务的输入和之前在预训练的时候看到的文本形式一样。即要使得输入的形式应该更像自然语言。
Zero-shot到Prompting:
既然输入的形式也要更像自然语言,那么就应该让模型通过我们的自然语言,去知道现在要去执行什么任务。
要如何做:实现Zero-shot learning的前提就是,我们得能够做到不需要针对下游的任务,给模型的输入结构做专门的设计;而是只需要给模型指示,也就是提示词(Prompt)就好了。
为什么prompt能够实现下游任务的预测:
Our speculation is that a language model with sufficient capacity will begin to learn to infer and perform the tasks demonstrated in natural language sequences in order to better predict them, regardless of their method of procurement. ——OpenAI
当数据量足够大、模型能力足够强的时候,语言模型会学会推测并执行用自然语言提出的任务,因为这样可以更好的实现下一词预测。(ICL的雏形)
2.5.GPT2 conclusion
GPT-2的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型有迁移到其它类别任务中而不需要额外的训练,即zero-shot learning的能力。但是效果其实很一般。
GPT-2表明随着模型容量和数据量的增大,其潜能还有进一步开发的空间,基于这个思想,促使了GPT3的出现。
2.6. GPT2 code study
下面是两个中文GPT2实战项目:
https://github.com/Morizeyao/GPT2-Chinese
https://github.com/yangjianxin1/GPT2-chitchat?tab=readme-ov-file
模型训练:
1.dataset process: 将语料通过sentencetokens转换为input_ids送入model中 ,例[101,122,123,435,634,102] 是一个length=6,其中101: ,102:
2.model inference:input_ids进入transformer的decoder中以及经过全连接层后,产生的结果与输入的length对齐,即6*768维度的(note:假设他是从第一个词之后开始预测)
3.Loss function compute:计算损失函数,true_labels是输入的input_ids,但是只取前[1:];logits是model输出的结果,但是只取[:-1],因为生成式模型是用前面的内容预测下一个词,假设输入的原文本是:
[ C L S ] [CLS] [CLS] 测试 [ S E P ] [SEP] [SEP]
那么会从 [ C L S ] [CLS] [CLS]开始预测下一个token,labels[…, 1:, :]就是"测试 [ S E P ] [SEP] [SEP]“这几个待预测token对应的id,logits[…, :-1, :]是因为-1是根据” [ S E P ] [SEP] [SEP]"预测的,原始输入到 [ S E P ] [SEP] [SEP]处就截止了,所以预测的最后一个token不需要,也正好和labels的长度对齐。
模型预测:
1.model input:输入prompt内容
2.model inference:model根据prompt内容输出与prompt对齐的结果,只取最后一个作为predict结果,并且将该结果拼接到prompt中,继续执行model做predict,直到model的输出为,则说明推理执行完毕。
3.对于对话类型:需要有一个历史存储,将上k次的问答内容保存在history中,并且将这些history一起送入model中去产生predict结果,从而达到多轮对话的目的。
3.GPT3
Language Models are Few-Shot Learners
2005.14165.pdf (arxiv.org)
3.1.Abstract
为什么提出GPT3:
GPT模型指出,如果用Transformer的解码器和大量的无标签样本去预训练一个语言模型,然后在子任务上提供少量的标注样本做微调,就可以很大的提高模型的性能。GPT2则是更往前走了一步,说在子任务上不去提供任何相关的训练样本,而是直接用足够大的预训练模型去理解自然语言表达的要求,并基于此做预测。但是,GPT2的性能太差,有效性低。
GPT3其实就是来解决有效性低的问题。Zero-shot的概念很诱人,但是别说人工智能了,哪怕是我们人,去学习一个任务也是需要样本的,只不过人看两三个例子就可以学会一件事了,而机器却往往需要大量的标注样本去fine-tune。那有没有可能:给预训练好的语言模型一点样本。用这有限的样本,语言模型就可以迅速学会下游的任务?
Note: GPT3中的few-shot learning,只是在预测是时候给几个例子,并不微调网络。GPT-2用zero-shot去讲了multitask Learning的故事,GPT-3使用meta-learning和in-context learning去讲故事。
3.2.Model Construction
GPT-3沿用了GPT-2的结构,但是在网络容量上做了很大的提升,并且使用了一个Sparse Transformer的架构,具体如下:
-
GPT-3采用了96层的多头transformer,头的个数为 96;
-
词向量的长度是12,888;
-
上下文划窗的窗口大小提升至2,048个token;
-
使用了alternating dense和locally banded sparse attention
Sparse Transformer:
Sparse Transformer是一种旨在处理高维、稀疏和长序列数据的Transformer拓展版,相比于传统的Transformer架构,Sparse Transformer通过在自注意力机制中引入稀疏性,减少了网络中计算的数量,从而可以处理更长的序列数据。具体的:在处理高维、稀疏数据时,Sparse Transformer可以避免对所有输入的位置进行计算,只计算与当前位置相关的位置,从而提高了计算效率。
GPT3的batch size达到320万,为什么用这么大的:
首先,大模型相比于小模型更不容易过拟合,所以更用大的、噪音更少的Batch也不会带来太多负面影响;其次,现在训练一个大模型会用到多台机器做分布式计算,机器与机器之间数据并行。最后,虽然批大小增加会导致梯度计算的时间复杂度增加,但是较大的batch size通常可以提高模型的训练效率和性能。
GPT3的训练范式:预训练+Prompt predict (few-shot learning)
3.3.无监督预训练
同上述GPT1、GPT2一样。
3.4.In-Context Learning (ICL,上下文学习)
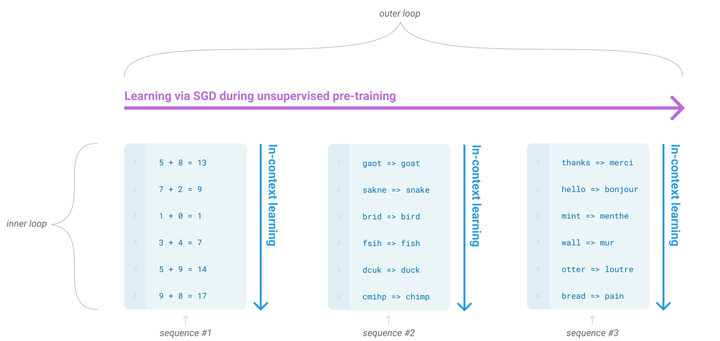
GPT-3的few-shot learning是不会做梯度下降,它是怎么做的:
只做预测,不做训练,我们希望Transformer在做前向推理的时候,能够通过注意力机制,从我们给他的输入之中抽取出有用的信息,从而进行预测任务,而预测出来的结果其实也就是我们的任务指示了。这就是上下文学习(In context learning)。
要理解in-context learning,我们需要先理解meta-learning(元学习)。对于一个少样本的任务来说,模型的初始化值非常重要,从一个好的初始化值作为起点,模型能够尽快收敛,使得到的结果非常快的逼近全局最优解。元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
GPT-3的上下文学习能力究竟从何而来:
有需要论文对ICL的出现进行了一定的科学解释,具体参考ICL相关论文(LLMs的细节),总之,当训练出一个GPT-3这么大的模型后,上下文学习能力就能被体现出来了。
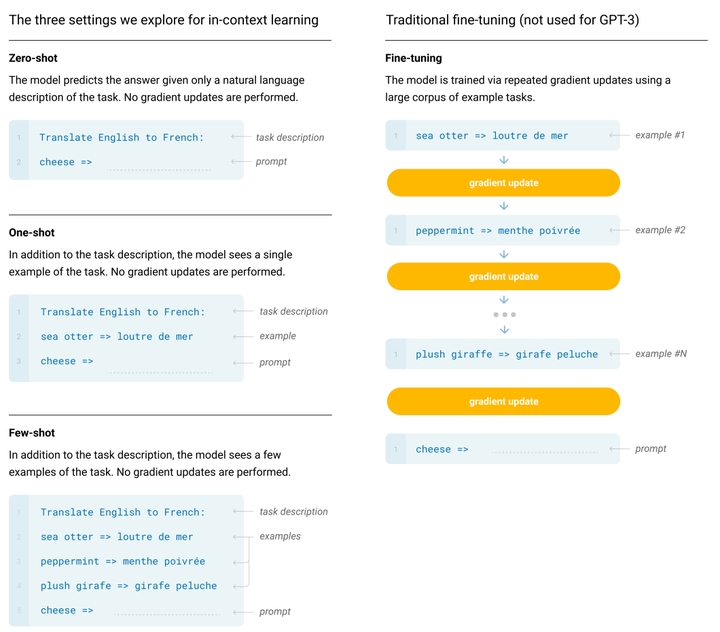
为了体现ICL,OpenAI用三个方法来评估他:
-
Few Shot Learning(FS):用自然语言告诉模型任务;对每个子任务,提供10~100个训练样本。
-
One-shot Learning(1S):用自然语言告诉模型任务,而后只给该任务提供1个样本。
-
Zero-shot learning(0S):用自然语言告诉模型任务,但一个样本都不给**。**
这个模式的缺陷:
-
GPT-3的输入窗口长度是有限的,不可能无限的堆叠example的数量,即有限的输入窗口限制了我们利用海量数据的能力。
-
每次做一次新的预测,模型都要从输入的中间抓取有用的信息;可是我们做不到把从上一个输入中抓取到的信息存起来,存在模型中,用到下一次输入里。
3.5. GPT3 Conclusion
GPT系列从1到3,通通采用的是transformer架构,模型结构并没有创新性的设计。GPT-3的本质还是通过海量的参数学习海量的数据,然后依赖transformer强大的拟合能力使得模型能够收敛。GPT-3学到的模型分布也很难摆脱这个数据集的分布情况。得益于庞大的数据集,GPT-3可以完成一些令人感到惊喜的任务,但是GPT-3也不是万能的,对于一些明显不在这个分布或者和这个分布有冲突的任务来说,GPT-3还是无能为力的。此外,GPT3长文本生成能力还是很弱。
GPT-3是怎么进化成ChatGPT的:
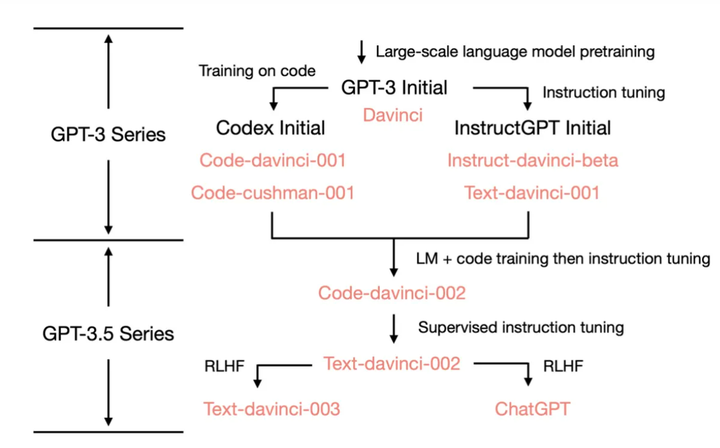
参考
GPT-1:language_understanding_paper.pdf (openai.com)
GPT-2:language_models_are_unsupervised_multitask_learners.pdf (openai.com)
GPT-3:Language Models are Few-Shot Learners (arxiv.org)
其他解读:
GPT系列解读(一) - 知乎 (zhihu.com)
GPT-2:语言模型是无监督的Multitask Learner - 知乎 (zhihu.com)
GPT-3:语言模型是Few-Shot Learner - 知乎 (zhihu.com)
GPT2实战:
https://github.com/Morizeyao/GPT2-Chinese
https://github.com/yangjianxin1/GPT2-chitchat?tab=readme-ov-file