前言
春节刚归来,我们不搞那么烧脑,先来一篇浅显易懂的文章,期望给大家带来一些新的解题思路。
背景
过去多年无论是一款插件推广,还是组件库统一,无论是一次机制流程制定,还是前端工程化体系建设,相信很多同学与我一样,在跨团队方案推广统一过程中,前期无论做好多详实的准备,最终都会有一种未竟全功的感觉。
推广过程中,总会有人摆出历史包袱过重这一拦路虎“说服”我们,比如”我这项目不维护了,无需升级“,”我这项目框架太老旧了,无法升级“,或两者兼有之,到底改哪些项目,多取决于双方自行判断,说穿了其实是双方“非不能也,乃不欲也”。
危害
一方面前端项目下线充满不确定性,业务不维护不代表页面无访问,旧有项目中总有一些页面残留,需要长期持续跟进。
另一方面过去多年前端技术生态快速向前发展,造成了不同部门、时期,从jquery、vue2、vue3、react、angular到webpack3、4、5、gulp、vite等前端基建五花八门的场景,仅23年我们团队就先后接入过webpack5、vite、pinia、rspack等前端架构局部优化,跨团队统一需要做大量兼容工作,全量统一困难。
前端项目的业务和技术特点,造成了前端项目数量基本越垒越多,每个项目总有几个有流量的页面时不时跳出来恶心人。造成了前端基建越来越庞杂,兼容成本偏高,总是不能全量升级。形成了前端项目独特的长尾化问题,项目长尾化,基建长尾化,团队意识长尾化。随着时间延续会带来升级维护困难和难以言表的线上偶发惊吓。
根源和解决思路
基于我司经验,问题产生根源一是前端团队资源有限,并不能覆盖全部项目;二是没有统一标准,项目缺乏统一标准管理,各团队自我决策改动范围;三是缺乏强制机制,并不能保证完成效果和时间。
资源有限是个基本无法解决的问题,我们只能从标准和强制机制两个角度去解决,基于此我们针对性的制定了转转自己的项目动态分级标准和强制倒逼机制。
项目动态分级
分级指的是用客观统一的数据标准反映项目重要性,规避主观评判。动态指的是随着时间延续,项目走过新建、迭代、维护、下线的生命周期,客观数据也随生命周期波谷、波峰、波谷往复更替。项目动态分级的最大好处是将有限资源聚焦在重点项目上。
以过去我司推进项目代码规范为例,我们设计时采用项目月活跃分支数、月代码提交行数、项目用户日访问量几个指标确定项目级别;
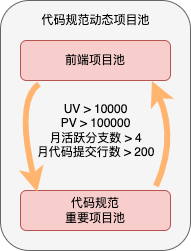
比如只有同时满足日访问量UV高于10000、日PV高于100000、月活跃分支数多于4个、月代码提交行数多于200的项目才确定为移动端重点项目,其它项目为非重点项目,每日或每周可以跑定时任务更新项目分级数据,具体数据可以通过拉取git api和公司前端埋点数据获得。
针对重点项目,可以制定2-4个月的改造时间节点和达标标准,非重点项目可以不做改造或制定其它策略。
我司前端项目数不到千,仅将项目分成重要和不重要两个级别已经够用,如场景有必要,也可将项目进一步拆分为更多级别。
指标边界值
大家可能对上面UV > 10000或月活跃分支数 > 4 等指标边界值是怎么确定的感兴趣?
说一下我们的思路,相信每个前端团队过去都手动收集过团队中的重点项目有哪些,这些手动数据可以作为我们的衡量基础,可以不断尝试调整我们的指标边界值,计算出的重点项目一般达到基本覆盖我们手动收集的95%以上重点项目即可,以此来确定边界值指标,一般结果肯定会大于我们的手动集,大家拿到结果可以人工再去分析下具体项目,基本能够发现多出来的项目大部分都是真实的重点项目,大部分都是因为我们谈到的历史包袱问题,不提罢了。
注意如果动态项目池,每日或每周都有较大变化,可能是你的指标不太合理,可以考虑扩大或缩小边界值来解决。另外注意突然进入重点动态项目池的项目,一般下个周期有可能就波动出去了,此类项目可以不做处理,也可推动解决,留好一定改动时间即可。
多指标好处
相比单指标确定边界值,多指标有哪些好处呢?
多指标好处一个是覆盖全部场景,比如我司移动端项目框架为Vue,有大量用户访问,中后台项目技术栈为React,没有大量用户访问。如果仅使用用户访问量指标,中后台项目全部会被排除在重点项目外,如果仅使用项目活跃度,移动端最看重的用户访问量不被纳入,项目区分度不够,但是两者相结合,恰好能覆盖移动端和PC端的全量场景。
另一个是多指标得出的结果稳定性更好,不会因单指标剧烈变化造成结果波动太大的情况,比如去年618和双11期间,尽管我司用户访问量大增,但重点项目集并没有什么变化。
强制倒逼机制
另外怎么确保deadline无延期呢?
我司采用的解决办法是与上线环节绑定,通过强拦截和审批拦截的方式,确保各团队能在最终时间节点之前,完成全部项目的改造。除此之外,强制机制能够倒逼各团队提升生产率,将很多重复性工作自动化,比如上文说到的代码规范,总会有同学梳理出一套本地自动化方案,帮我们完成配套建设。当我们标准达成、配套健全后,就可以考虑下扩大范围或者提高标准的事情了。
另外大家需要注意,跨组推进工作中很重要的一点是前置沟通,给同学们留下足够的时间,比如2-6个月,达成时间共识很重要,不要自觉良好一刀切,想想过去经历的很多跨组项目,半年能彻底搞完就很不错了。
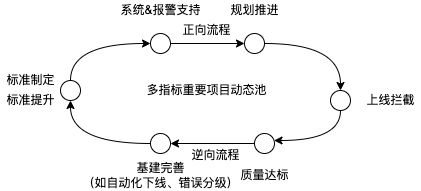
思路&基建复用
本文谈到的整套分级和强制思路,后续逐步复用在我司代码重复度、复杂度、线上异常治理、性能指标等多项跨团队公共事项落地中,有些指标直接复用同一套项目分级标准即可,有些指标需要一定的改动,比如性能指标,就从重点项目,变为重点页面即可,大部分基础能力和解决问题的思路仍可复用。
总结
保持公司各团队基建、标准、机制统一,长期看是非常有必要的事,但过去受制于历史包袱问题这一隐性拦路虎,前端很难做到跨团队统一方案的效用最大化,总会留下一些尾巴,本文通过转转过去的实践,给出了项目分级和强制机制的解体思路,非常适合前端资源并不那么充足的公司,至少能够保证公司重要的项目长期标准统一。
另外整个思路的落地,除标准制定外,还涉及到数据抽取、各指标检测、CICD集成、报警机制、系统开发等多方面的具体工作,每一部分都能作为一个单独的模块去做分享,比如代码规范涉及到的项目代码增量存量检测、代码复杂度、重复度检测,线上异常治理涉及到的实时报警策略、错误分级策略等,因篇幅关系,本文不再赘述,期待后面其他转转er的文章吧!!!