一、前言
首先这个博客会介绍一些关于MySQL中索引的基本内容以及一些基本的语法,当然里面也会有些常见的面试题的解答。
二、关于索引
1、概念
索引是一种能够帮助MySQL高效的去磁盘检索数据的一种数据结构。在MySQL的Innodb存储引擎中呢,采用的是B+树的结构去实现索引和数据的存储。
2、原理
未添加索引:
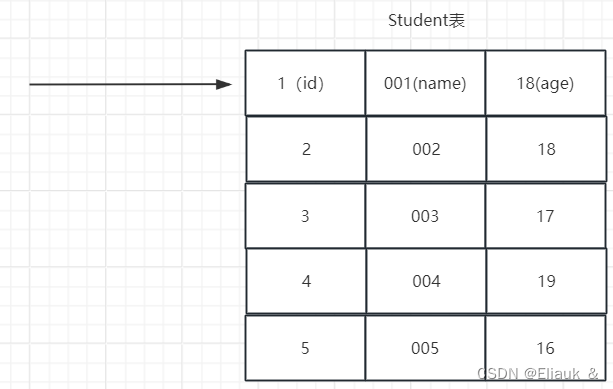
如图所示:当我们未添加索引时,假如以id查询某个学生信息时,我们的MySQL会做一个全表的扫描查询,不管你查询的是id=1还是id=5。所以当数据量增多时,我们的查询时间就会增多。
假设现在我们以id建立索引:

如图所示,当我们建立以id为索引时,MySQL在查询的时候,我们的id索引会形成二叉树的结构(该二叉树的前提是平衡二叉树,当然还有B树、B+树的数据结构),如这时我们要查找id=3的学生,MySQL就从id=2开始,3>2,走右子树,找到4,4>3,走左子树找到3。这时查找速度远快于没有索引时的结构。
三、常见索引的种类
1、主键索引(Primary key)
只要我们创建了主键(primary key),那么它就主动成了一个索引,称为主键索引。
2、唯一索引(Unique)
在我们的表的字段中,我们创建了唯一约束(unique),那么该字段是唯一的,同时也是索引,称为唯一索引。
3、普通索引(Index)
普通索引是最基本的索引,它没有任何限制。这也是我们用的最多的索引机制。
4、全文索引(Fulltext)
全文索引适用于MyISAM存储引擎。
四、常见的索引的指令
①查询索引
show indexs from 表名;
②添加索引:
普通索引:
(1)alter table 表名 add index 索引名称(列名);
(2)create index 索引名称 on 表名(列名);
唯一索引:
create unique index 索引名称 on 表名(列名);
主键索引:
alter table 表名 add primary key 列名;
③删除索引:
drop index 索引名称 on 表名
删除主键索引
alter table 表名 drop primary key
④查询索引
(1)show index from 表名;
(2)show inedexs from 表名;
(3)show keys from 表名;
(4)desc 表名。
五、适合索引的情况
①:比较频繁的作为查询条件的字段应该创建索引;
②:唯一性太差的字段不合适 单独作为索引,即使频繁的作为查询条件(如人的性别,有男、女两种状态唯一性差);
③:更新非常频繁的字段不适合创建索引;
④:不会出现在where(或者having)子句中的字段不应创建索引。
六、市面上高频常见的索引的面试回答
这里呢是博主找了一些市面上常见的有关索引的面试题,做个总结,以便于后期的复习。
1、谈谈MySQL索引的优缺点
优点:
①通过B+树的结构来存储数据,可以大大减少数据检索时的磁盘IO的次数,从而提升数据查询的性能;
②B+树索引在进行范围查找的时候,只需要找到起始节点,然后基于叶子节点的链表结构往下读取即可,查询效率较高;
③通过唯一索引的约束,可以保证数据表中每一行数据的唯一性;
缺点:
①数据的增加、修改、删除,需要涉及到索引的维护,当数量较大的情况下,索引的维护会带来较大的性能开销;
②一个表中允许存在一个聚簇索引和多个非聚簇索引,但是索引数不能创建多个,否则会造成索引维护成本过高;
③创建索引的时候,需要考虑到索引字段值的分散性,如果字段的重复数据过多,创建索引反而会带来性能的降低。
2、聚簇索引与非聚簇索引区别
(MySQL的索引从物理存储的角度对索引进行分类可以分为聚簇索引(Innodb)与非聚簇索引(MyISAM))
聚簇索引:所谓聚簇索引,就是指主索引文件和数据文件为同一份文件,聚簇索引主要用在Innodb存储引擎中。在该索引实现方式中B+Tree的叶子节点上的data就是数据本身。因此从聚簇索引中获得数据要比在非聚簇索引中查找更快。
首先我们可以看到我们的Innodb存储引擎中有以下两个文件:

其中.frm文件表示表的结构,.ibd文件表示Innodb 数据表索引+数据,它是索引与数据在同一个文件中,是聚合在一起的。
其次聚集索引的结构如下,我们可以清晰看到数据和索引存储在同一个文件之中的。

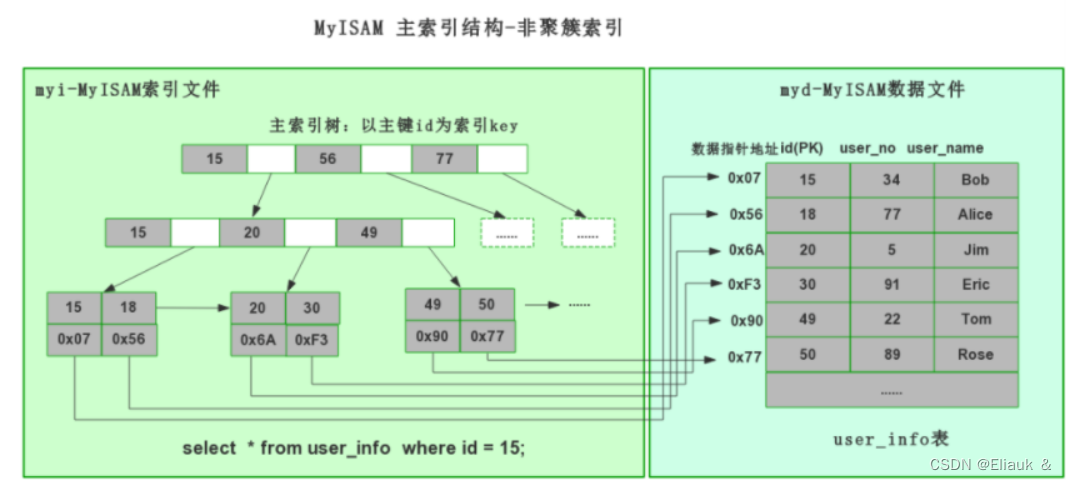
非聚簇索引: 非聚簇索引就是指B+Tree的叶子节点上的data,并不是数据本身,而是保存的实际指向存放数据块的指针。通过辅助索引首先找到的是主键值,再通过主键值找到数据行的数据页,主要用在MyISAM存储引擎中。 非聚簇索引需要先查询一遍索引文件,得到索引,根据索引获取数据,比聚簇索引多了一次读取数据的IO操作,所以查找性能上会差。
首先我们可以看到我们的MyISAM存储引擎中有以下三个文件:
其中.frm文件表示我们表的结构,.MYD文件表示我们MyISAM的表数据,.MYI文件表示我们MyISAM的索引,所以它的表的数据和索引是通过非聚合的方式储存的。
其次聚集索引的结构如下,我们可以清晰看到数据和索引存储是不在同一个文件之中的
 3、什么情况下mysql会索引失效
3、什么情况下mysql会索引失效
①where 后面使用函数 ②使用or条件③ 模糊查询 %放在前边 ④类型转换 ⑤组合索引 (最佳左前缀匹配原则)
4、什么是联合索引?以及其优点?
联合索引:是指两个或更多个列上的索引被称作联合索引,联合索引又叫复合索引。对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持(a) | (a,b)| (a,b,c )3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。
优点:
①减少开销
建一个联合索引(a,b,c),实际相当于建了(a),(a,b),(a,b,c)三个索引.每多一个索引,都会增加写操作的开销和磁盘空间的开销.对于大量数据的表,使用联合索引会大大的减少开销!
②效率高
索引列多,通过联合索引筛选出的数据越少。
③覆盖索引
对联合索引(a,b,c),如果有如下sql的 select a,b,c from table where a='xxx' and b='xx'; 那么mysql可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机io操作。在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
5、什么是索引下推、回表查询、索引覆盖
①:回表查询
当我们的SQL查询要的是全部数据,无法从普通索引里面去获得时,需要做二次查询,通过聚集索引中把所有的数据取出来。这个过程就是回表查询。如下图所示:
 如图所以,假设有个user表,里面包含id、name、phone、age这些字段,我们以name建立普通索引,那么此时就会以name的数据经过B+树算法形成了B+Tree,存储到硬盘,如图中右图所示,其叶子节点存的是最终数据包含name(当前索引列的数据)、id(主键列的数据),非叶子节点存储的是一个键值,通过键值定位到最终的数据。此时我们的查询语句是select * from user where name = '***',这时执行流程:先name形成的二叉树查数据,找到name和id;其次,我们需要的是完整数据(select *),就会通过id去我们的聚簇索引上去查的最终完整的数据。这个过程就是回表。
如图所以,假设有个user表,里面包含id、name、phone、age这些字段,我们以name建立普通索引,那么此时就会以name的数据经过B+树算法形成了B+Tree,存储到硬盘,如图中右图所示,其叶子节点存的是最终数据包含name(当前索引列的数据)、id(主键列的数据),非叶子节点存储的是一个键值,通过键值定位到最终的数据。此时我们的查询语句是select * from user where name = '***',这时执行流程:先name形成的二叉树查数据,找到name和id;其次,我们需要的是完整数据(select *),就会通过id去我们的聚簇索引上去查的最终完整的数据。这个过程就是回表。
(PS:对于主键索引的树,如果用户设置了主键则会生成主键索引;若没有主键,Innodb会优先选择一个unique键作为主键;若主键和unique都没有的话,则Innodb会自动为用户添加一个叫做DB_ROW_ID的键作为默认主键,只不过这个键我们看不见。所以对于Innodb来讲主键索引一定是存在的。)
②:索引下推
索引下推:简称ICP,是在MySQL5.6的版本上推出,用于优化查询。
用以下案例做个讲解:
select * from student where name like '李%' and age=18;
未设置索引下推的情况:
首先设置了index(name,age)那么在执行语句时,根据最左前缀法则,该语句搜索索引树时,只能匹配到名字里第一个字为李的记录,接下来从该记录开始,逐个回表,到主键索引上找到相应的记录,再和age这个字段做比较看值是否合适。
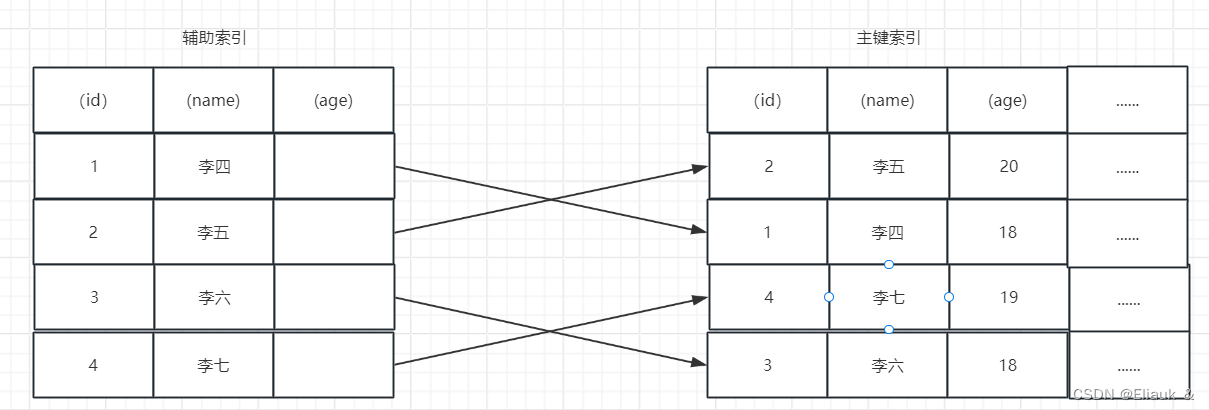 如上图所示,未配置索引下推,那么在语句执行时,先找到姓李的用户,而不会看age的值,然后分别去主键索引中根据id查询数据,再结合age做过滤,一共要回表4次。
如上图所示,未配置索引下推,那么在语句执行时,先找到姓李的用户,而不会看age的值,然后分别去主键索引中根据id查询数据,再结合age做过滤,一共要回表4次。
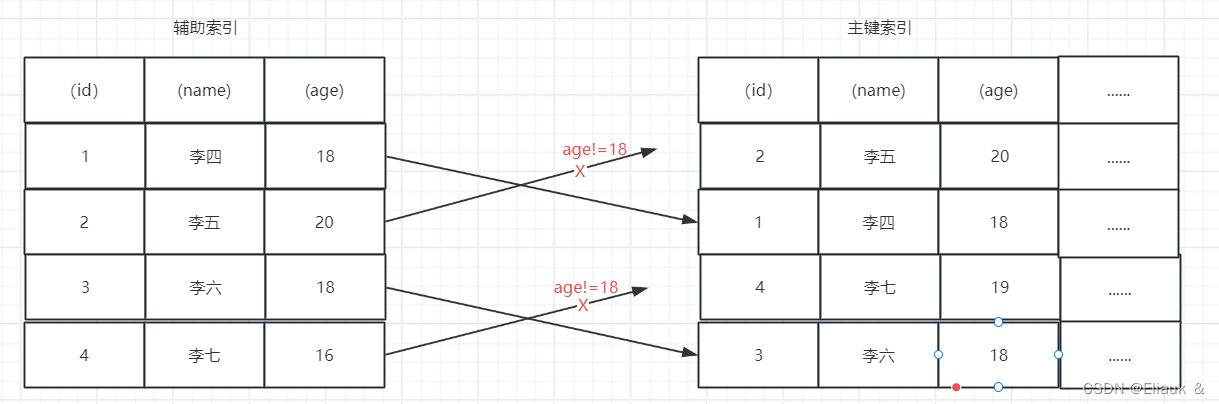
若做了索引下推:
Innodb在(name、age)索引内部就做了age是否为18的判断,对于不符合的数据直接跳过,减少了回表的次数,从而提高整体的性能。如下图所示:
③:索引覆盖
索引覆盖:是一种避免回表查询的优化策略,只需在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
实现方式:将查询的字段建立 普通索引或者联合索引,这样就可以直接返回索引中的数据,不需要通过聚集索引去定位行记录,避免了回表的情况发生。案例上面那个联合索引的优点提到。
注意事项:
如果一个索引包含了所需的查询的所有字段的值(不需要回表),这个索引就是覆盖索引。
MySQL只能使用B+Tree索引做覆盖索引(因为只有B+Tree能储存索引列值)。
七、总结
这篇博客记录索引的一些基本原理,基本使用以及常见的面试题。通过博客的记录方便博主后期的复习,也希望对大家有所帮助,记得点赞、关注,支持博主一波哦~,后期还有更多内容!