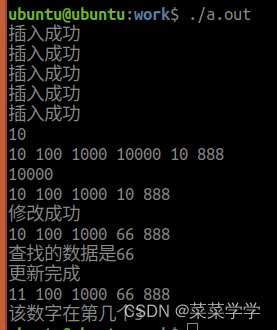
一.安装和连接
1.1 安装
mysql安装教程:
2021MySql-8.0.26安装详细教程(保姆级)_2021mysql-8.0.26安装详细教程(保姆级)_mysql8.0.26_ylb呀的博客-cs-CSDN博客
workbench安装:
MySQL Workbench 安装及使用-CSDN博客
1.2 配置头文件库
将安装目录下的inlcude和bin下的libmysql放入我们的工程文件主目录

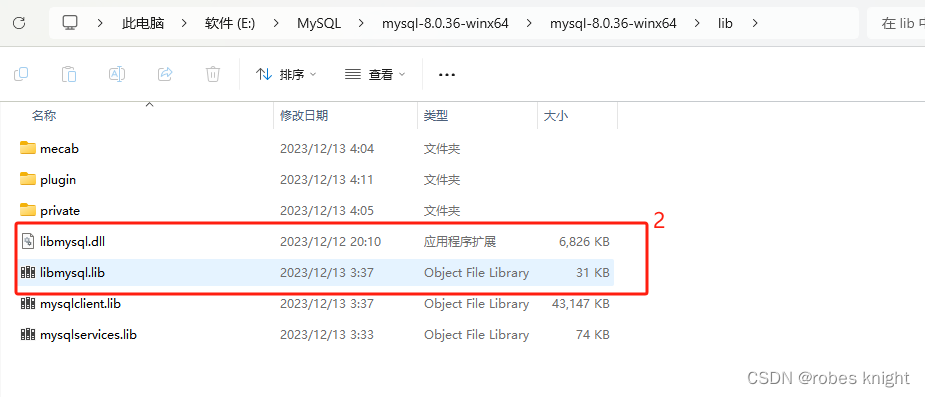
vs下创建控制台项目,然后打开文件所在路径,复制过去
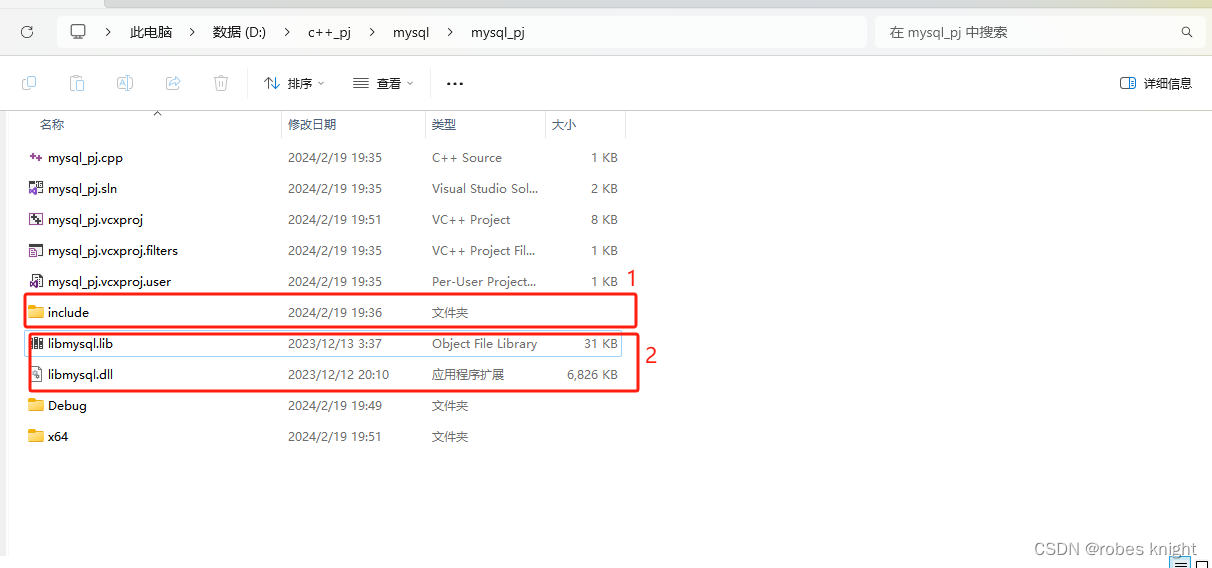
设置头文件库
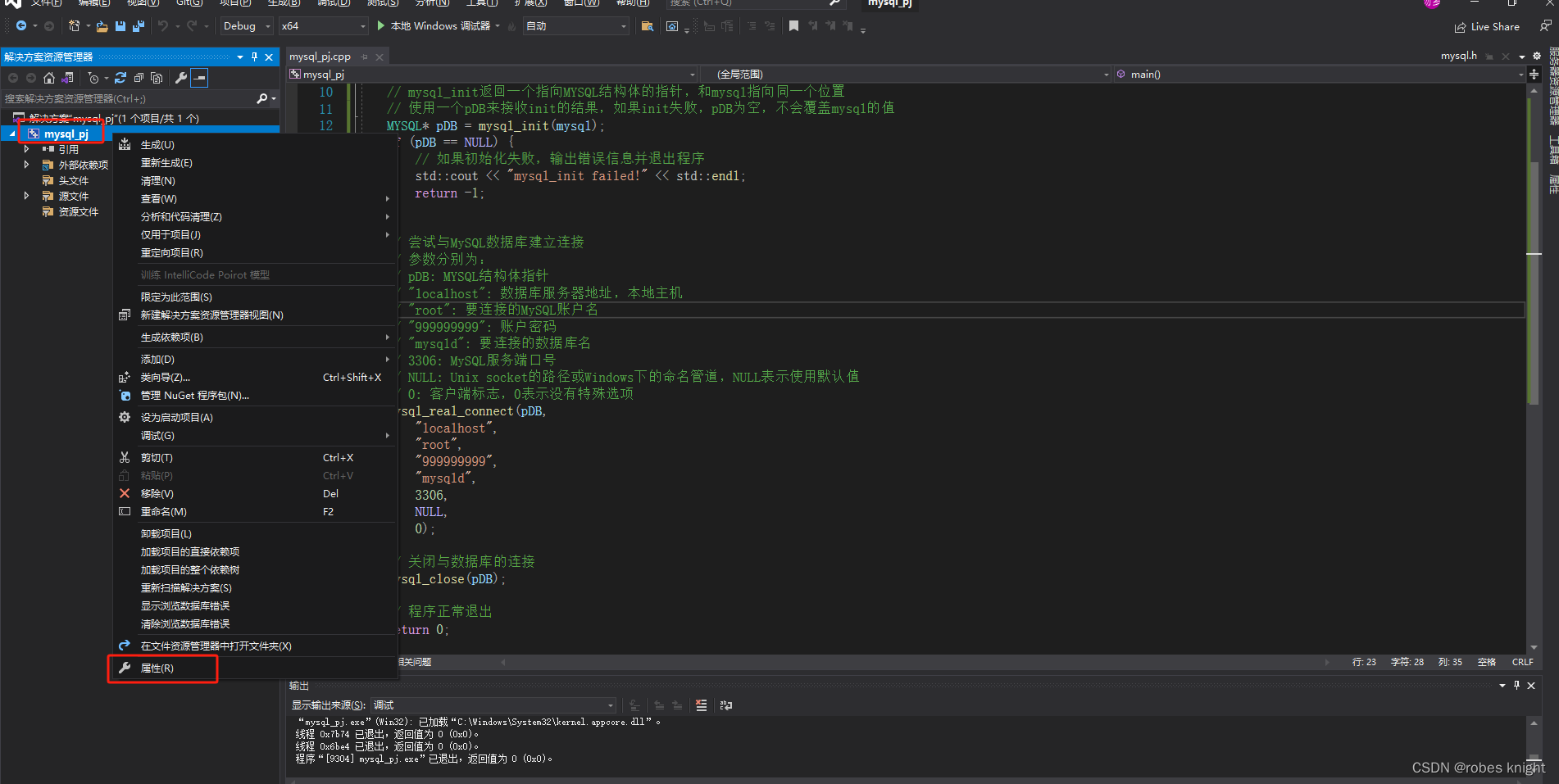
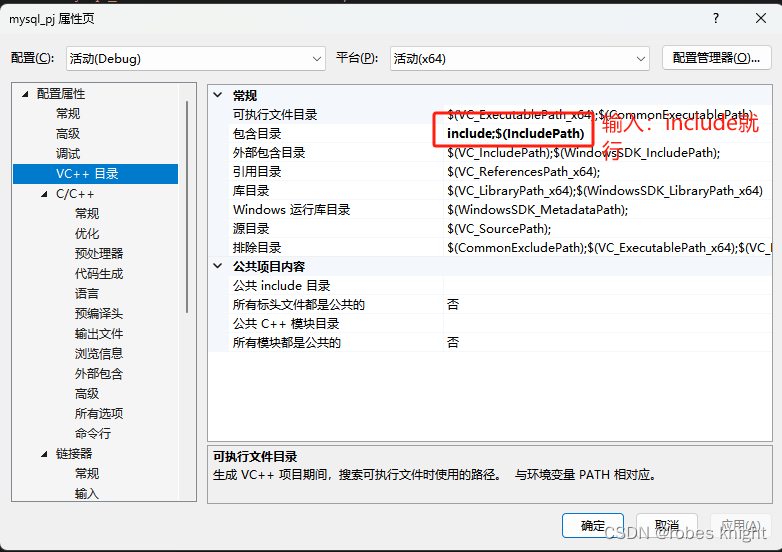
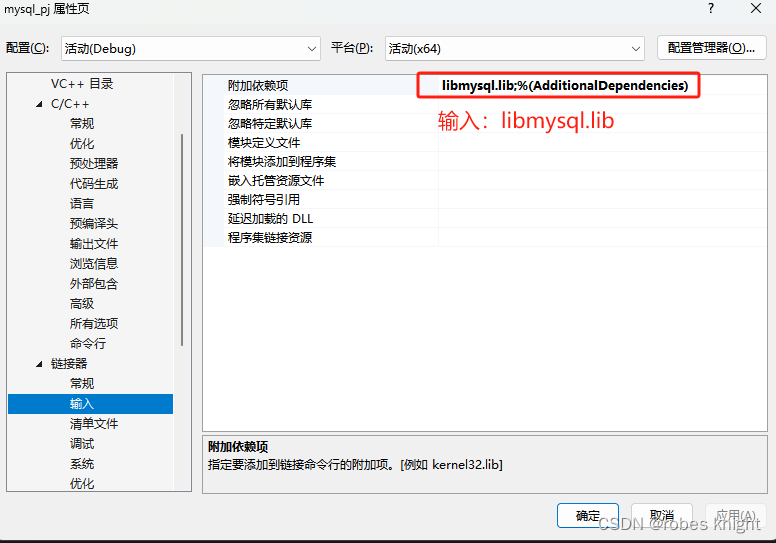 注意:一定要在64位环境下编译,libmysql只适配64位环境
注意:一定要在64位环境下编译,libmysql只适配64位环境
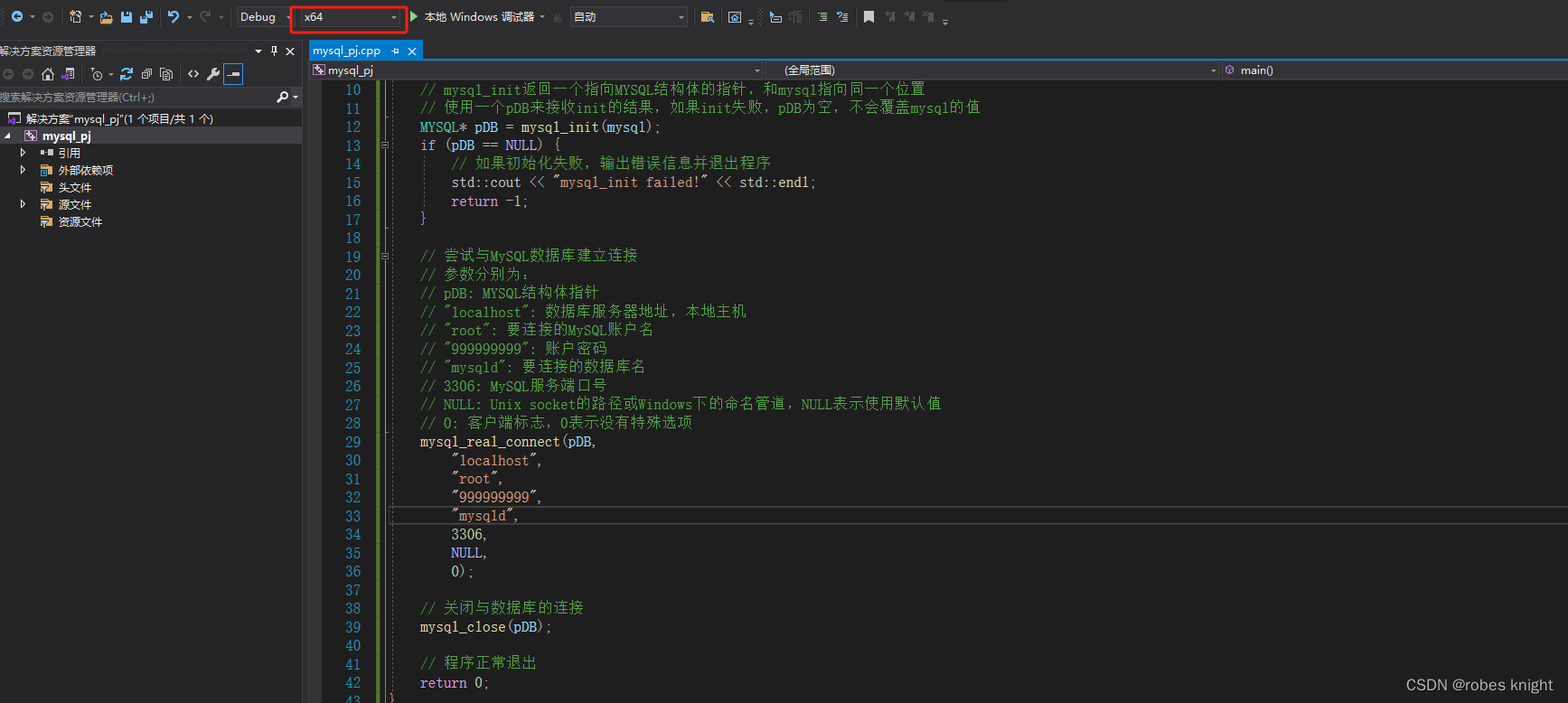
1.3 数据库连接
#include <iostream>
#include <mysql.h> // 引入MySQL的头文件int main()
{// 创建一个MYSQL结构体的实例MYSQL* mysql = new MYSQL();// 初始化MYSQL结构体,并进行必要的设置以准备连接数据库// mysql_init返回一个指向MYSQL结构体的指针,和mysql指向同一个位置// 使用一个pDB来接收init的结果,如果init失败,pDB为空,不会覆盖mysql的值MYSQL* pDB = mysql_init(mysql);if (pDB == NULL) {// 如果初始化失败,输出错误信息并退出程序std::cout << "mysql_init failed!" << std::endl;return -1;}// 尝试与MySQL数据库建立连接// 参数分别为:// pDB: MYSQL结构体指针// "localhost": 数据库服务器地址,本地主机// "root": 要连接的MySQL账户名// "999999999": 账户密码// "mysqld": 要连接的数据库名// 3306: MySQL服务端口号// NULL: Unix socket的路径或Windows下的命名管道,NULL表示使用默认值// 0: 客户端标志,0表示没有特殊选项mysql_real_connect(pDB,"localhost","root","999999999","mysqld",3306,NULL,0);// 关闭与数据库的连接mysql_close(pDB);// 程序正常退出return 0;
}二、常用命令
2.1 基本数据结构
MySQL 中的五大数据类型(INTEGER、DECIMAL、DATETIME、TEXT、BLOB)
INTEGER:TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT
对应的C/C++类型:char、short、int、int、int64_t
DECIMAL:FLOAT、DOUBLE、DECIMAL
对应的C/C++类型:float、double、double==longdouble
DATETIME:DATE、TIME、YEAR、DATETIME、TIMESTAMP
对应的C/C++类型:struct tm、tm、int、tm、time_t
TEXT:NCHAR、CHAR、NVARCHAR、VARCHAR、TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT
对应的C/C++类型:unsignedchar*、char*、unsigned char*、char*、char[256]、string、string、 string
BLOB:BLOB、TINYBLOB、MEDIUMBLOB、LONGBLOB
对应的C/C++类型:char*
尽管他们是对应的,但是并没有一个标准的方法来转换MySQL数据到C/C++的数据类型
tm补充:
truct tm
{int tm_sec; // seconds after the minute- [0, 60] including leap secondint tm_min; // minutes after the hour- [0, 59]int tm_hour; // hours since midnight- [0, 23]int tm_mday; // day of the month- [1, 31]int tm_mon; // months since January- [0, 11]int tm_year; // years since 1900int tm_wday; // days since Sunday- [0, 6]int tm_yday; // days since January 1- [0, 365]int tm_isdst; // daylight savings time flag
};2.2 mysql命令执行流程
执行命令的过程:
- 1、发送SQL命令
- 2、获取SQL执行结果
- 3、解析获取到的结果
1、发送SQL命令接口:
int STDCALL mysql_real_query(MYSQL *mysql, const char *q, unsigned long length);query命令不止可以进行查询
q 是SQL指令,具体执行什么操作
length 是指令的长度,因为内部使用了网络编程,指定长度更准确
2、获取执行结果:
MYSQL_RES *STDCALL mysql_use_result(MYSQL *mysql);注意:一个query后面就要立即跟上result,不能两次查询后面跟一次获取
解析完毕后,释放结果,不然会占用大量内存:
void STDCALL mysql_free_result(MYSQL_RES *result); 3、解析结果:
获取的数据库数据结果为一个表,有n行m列
获取结果集列的数量:
unsigned int STDCALL mysql_num_fields(MYSQL_RES *res);获取结果集行的数量:
my_ulonglong STDCALL mysql_num_rows(MYSQL_RES *res);取结果中的行接口:
MYSQL_ROW STDCALL mysql_fetch_row(MYSQL_RES *result);返回一个字符串数组,每个字段可以通过索引访问,如过使用row 接收,那么row[0] 是第一列,row[1] 是第二列,等等。
获取每一行的长度接口:
unsigned long *STDCALL mysql_fetch_lengths(MYSQL_RES *result);返回一个数组,包含每一行的数据长度
获取结果集中每一列的定义(数据类型)接口:
MYSQL_FIELD *STDCALL mysql_fetch_fields(MYSQL_RES *res);2.3 创建用户
创建:
CREATE USER '用户名'@'范围'IDENTIFIED BY'密码';范围包括:ip、localhost、%:
ip 即只能从指定地址登录
localhost 即只能从本机登录
% 即可以从任何地址登录
授权操作表 :
GRANT privileges ON databasename.tablename TO '用户名'@'范围'privileges 可以是: SELECT,INSERT,UPDATE,DELETE,CREATE,DROP,ALTER,EXECUTE,INDEX,
REFERENCES ALTER ROUTINE,CREATE ROUTINE,CREATE TEMPORARY,SHOW VIEW,LOCK TABLES ALL
databasename 是库的名称
可以填入*表示所有 tablename 是表的名称,可以填入*表示所有
撤销权限
REVOKE 权限 ONdatabasename.tablename FROM'用户名'@'范围'创建实操:
#include <iostream>
#include <mysql.h> // 引入MySQL的头文件
void connect() {// 创建一个MYSQL结构体的实例MYSQL* mysql = new MYSQL();// 初始化MYSQL结构体,并进行必要的设置以准备连接数据库// mysql_init返回一个指向MYSQL结构体的指针,和mysql指向同一个位置// 使用一个pDB来接收init的结果,如果init失败,pDB为空,不会覆盖mysql的值MYSQL* pDB = mysql_init(mysql);if (pDB == NULL) {// 如果初始化失败,输出错误信息并退出程序std::cout << "mysql_init failed!" << std::endl;return;}// 尝试与MySQL数据库建立连接// 参数分别为:// pDB: MYSQL结构体指针// "localhost": 数据库服务器地址,本地主机// "root": 要连接的MySQL账户名// "999999999": 账户密码// "mysql": 要连接的数据库名// 3306: MySQL服务端口号// NULL: Unix socket的路径或Windows下的命名管道,NULL表示使用默认值// 0: 客户端标志,0表示没有特殊选项pDB = mysql_real_connect(pDB,"localhost","root","999999999","mysql",3306,NULL,0);std::cout << pDB << std::endl;if (pDB) {//创建用户std::string sql = "CREATE USER 'hello'@'localhost' IDENTIFIED BY '123456'";int ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "error:" << mysql_error(pDB) << std::endl;}//MYSQL_RES* result = mysql_use_result(mysql);if (result != NULL) {unsigned nFields = mysql_num_fields(result);my_ulonglong nRows = mysql_num_rows(result);MYSQL_FIELD* fields = mysql_fetch_fields(result);for (unsigned int i = 0; i < nRows; i++) {MYSQL_ROW row = mysql_fetch_row(result);if (row != NULL) {for (unsigned j = 0; j < nFields; j++) {std::cout << "type:" << fields[j].type << " " << fields[j].name<< ":" << row[j] << std::endl;}}std::cout << "==========" << std::endl;}mysql_free_result(result);}else {std::cerr << "Failed to retrieve result set: " << mysql_error(mysql) << std::endl;}//授权操作表sql = "GRANT ALL ON *.* TO 'hello'@'localhost'";mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());result = mysql_use_result(mysql);if (result != NULL) {unsigned nFields = mysql_num_fields(result);my_ulonglong nRows = mysql_num_rows(result);MYSQL_FIELD* fields = mysql_fetch_fields(result);for (unsigned i = 0; i < nRows; i++) {MYSQL_ROW row = mysql_fetch_row(result);if (row != NULL) {for (unsigned j = 0; j < nFields; j++) {std::cout << "type:" << fields[j].type << " " << fields[j].name<< ":" << row[j] << std::endl;}}std::cout << "===================================================" <<std::endl;}mysql_free_result(result);}// 关闭与数据库的连接mysql_close(pDB);}delete mysql;return;
}
int main()
{connect();// 程序正常退出return 0;
}workbench中查看创建的用户:
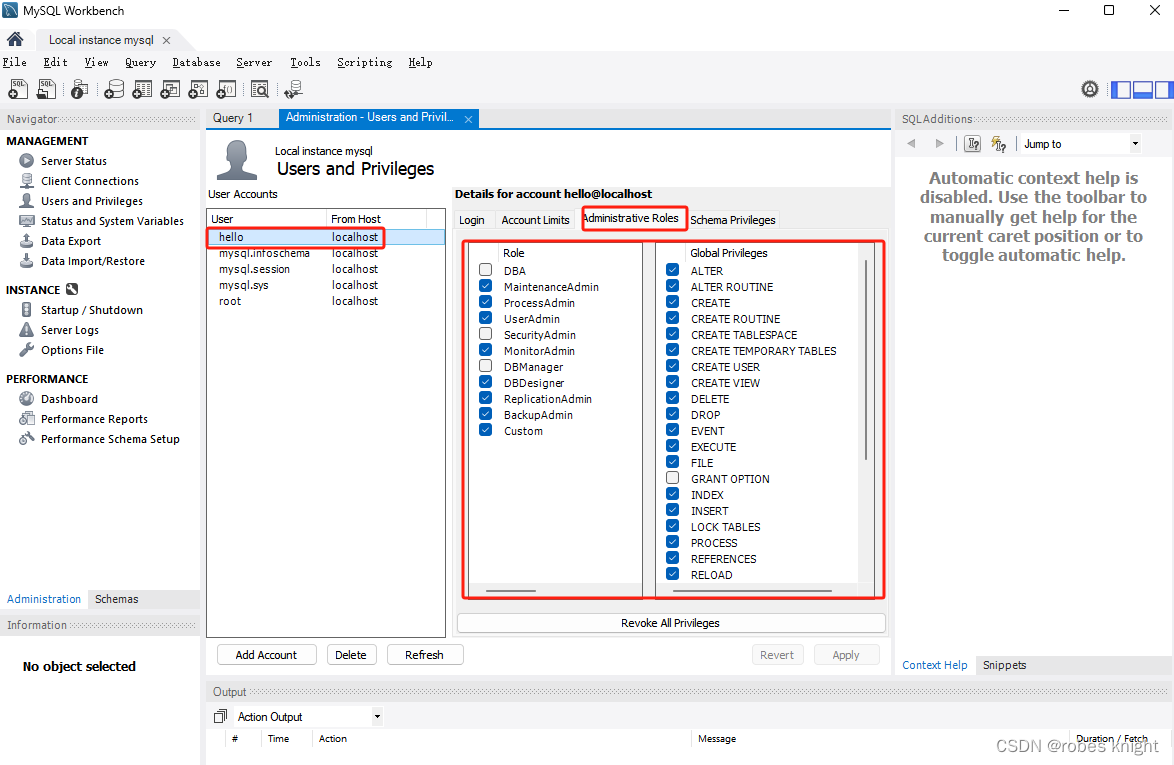
2.4 创建仓库与删除仓库
创建数据仓库:
CREATE DATABASE 数据仓库名;数据库名称不要使用奇怪的或者特殊的符号,例如空格、路径符、引号
MySQL 如何指派仓库权限给用户:
GRANT 权限 ONdatabasename.tablenameTO'用户名'@'范围'切换数据库:
USE 数据仓库名;用户、数据库、表等等,这些元素的创建,一般是不会有返回结果 仅仅有一个返回值,标明执行的结果是成功还是失败!
删除库:
DROPDATABASE 数据仓库名;实例:
void show_result(MYSQL_RES* result){unsigned nFields = mysql_num_fields(result);my_ulonglong nRows = mysql_num_rows(result);MYSQL_FIELD* fields = mysql_fetch_fields(result);for (unsigned i = 0; i < nRows; i++) {MYSQL_ROW row = mysql_fetch_row(result);if (row != NULL) {for (unsigned j = 0; j < nFields; j++) {std::cout << "type:" << fields[j].type << " " << fields[j].name<< ":" << row[j] << std::endl;}}std::cout << "===================================================" <<std::endl;}
}
int database_create() {// 创建一个MYSQL结构体的实例MYSQL* mysql = new MYSQL();// 初始化MYSQL结构体,并进行必要的设置以准备连接数据库// mysql_init返回一个指向MYSQL结构体的指针,和mysql指向同一个位置// 使用一个pDB来接收init的结果,如果init失败,pDB为空,不会覆盖mysql的值MYSQL* pDB = mysql_init(mysql);if (pDB == NULL) {// 如果初始化失败,输出错误信息并退出程序std::cout << "mysql_init failed!" << std::endl;return;}pDB = mysql_real_connect(pDB,"localhost","root","999999999","mysql",3306,NULL,0);std::cout << pDB << std::endl;if (pDB) {std::string sql = "CREATE DATABASE hello";int ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "mysql error:" << mysql_error(pDB) << std::endl;}MYSQL_RES* result = mysql_use_result(mysql);if (result != NULL) {show_result(result);std::cout << "===================================================" <<std::endl;mysql_free_result(result);}//授予权限sql = "GRANT ALL ON hello.* TO 'hello'@'localhost';";ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "mysql error:" << mysql_error(pDB) << std::endl;return-1;}result = mysql_use_result(mysql);if (result != NULL) {show_result(result);std::cout << "===================================================" <<std::endl;mysql_free_result(result);}sql = "USE hello;";ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "mysql error:" << mysql_error(pDB) << std::endl;return-1;}result = mysql_use_result(mysql);if (result != NULL) {show_result(result);std::cout << "===================================================" <<std::endl;mysql_free_result(result);}sql = "DROP DATABASE hello;";ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "mysql error:" << mysql_error(pDB) << std::endl;return-1;}result = mysql_use_result(mysql);if (result != NULL) {show_result(result);std::cout << "===================================================" <<std::endl;mysql_free_result(result);}mysql_close(pDB);delete mysql;return 0;
}效果:创建成功(设置断点调试到DROP DATABASE之前即可)
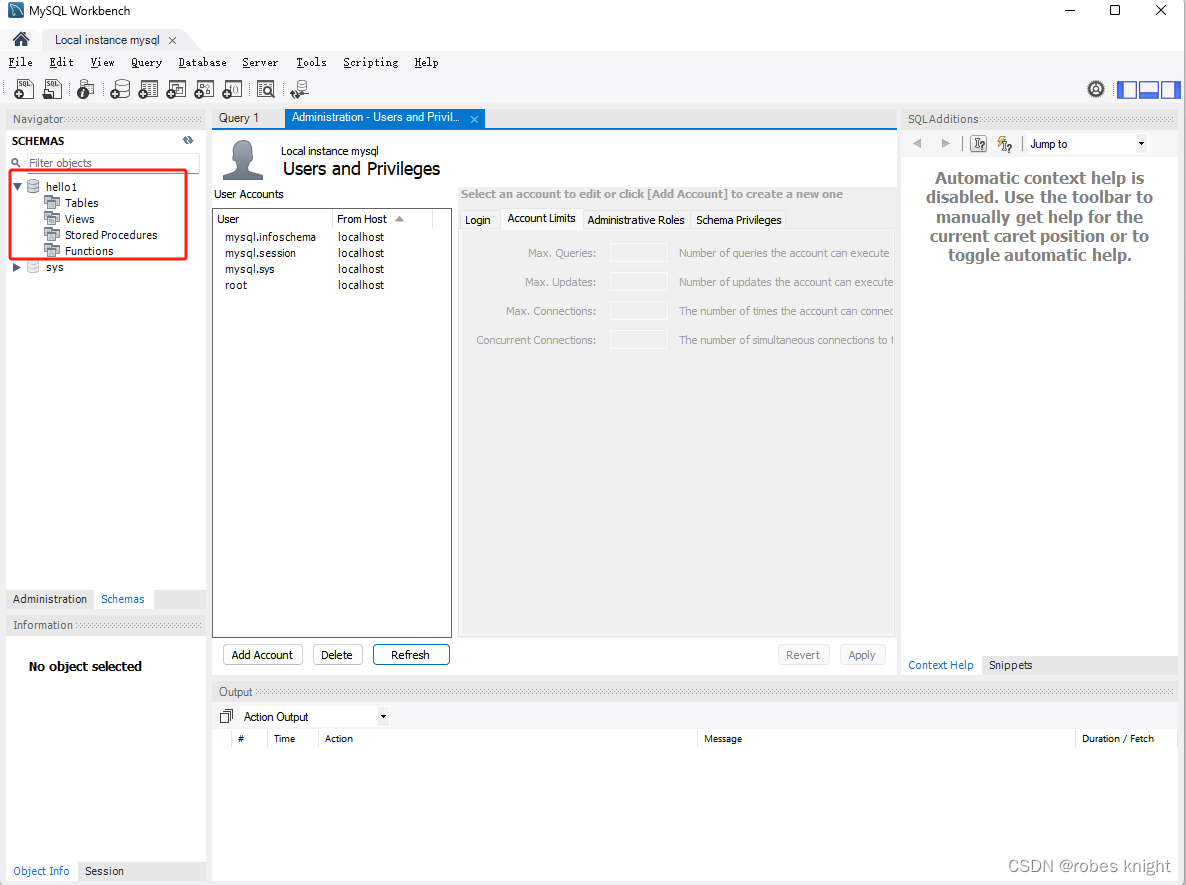
2.5 创建表和删除表
创建表:
CREATE TABLE IF NOT EXISTS(可略) `表名称`(`列名称1` 数据类型 关键字列表(可略) 默认值(可略)......
)ENGINE=InnoDB DEFAULT CHARSET=utf8;关键字和含义如下:
AUTO_INCREMENT 自动增加,只能用于整数类型列
NOTNULL 列不能为空
NULL 列可以为空
PRIMARY KEY 主键 表中主键的值是唯一的,可以用于标记和查找数据
UNSIGNED 无符号的数,只能修饰整数类型列
DEFAULT 默认值 用于指定列的默认值
UNIQUE 唯一 该列的要么为NULL要么就必须是唯一的,不可重复
ZEROFILL 0 值填充,如果没有指定该列的值,则会填入0
删除MySQL数据表:
DROPTABLE `表名称`;实例:
int create_table() {// 创建一个MYSQL结构体的实例MYSQL* mysql = new MYSQL();// 初始化MYSQL结构体,并进行必要的设置以准备连接数据库// mysql_init返回一个指向MYSQL结构体的指针,和mysql指向同一个位置// 使用一个pDB来接收init的结果,如果init失败,pDB为空,不会覆盖mysql的值MYSQL* pDB = mysql_init(mysql);if (pDB == NULL) {// 如果初始化失败,输出错误信息并退出程序std::cout << "mysql_init failed!" << std::endl;return -1;}pDB = mysql_real_connect(pDB, "localhost", "root", "999999999", "mysql", 3306, NULL, 0);std::cout << pDB << std::endl;if (pDB) {//创建数据库std::string sql = "CREATE DATABASE hello";int ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "mysql error:" << mysql_error(pDB) << std::endl;return -1;}//授予权限sql = "GRANT ALL ON hello.* TO 'hello'@'localhost';";ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "mysql error:" << mysql_error(pDB) << std::endl;return -1;}//通过use 将操作的数据库从mysql切换到hellosql = "USE hello;";ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "mysql error:" << mysql_error(pDB) << std::endl;return-1;}//
/*创建的表名为 hello,具有一个名为 编号 的列,
该列的数据类型为 NVARCHAR(16),
并且这个列被指定为表的主键。
表使用的存储引擎是 InnoDB,
默认的字符集为 utf8
*/sql = "CREATE TABLE IF NOT EXISTS `hello`(`编号` TEXT PRIMARY KEY)ENGINE=InnoDB DEFAULT CHARSET=utf-8; ";ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "mysql error:" << mysql_error(pDB) << std::endl;return-1;}sql = "DROP TABLE `hello`;";ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "mysql error:" << mysql_error(pDB) << std::endl;return-1;}sql = "DROP DATABASE hello;";ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "mysql error:" << mysql_error(pDB) << std::endl;return-1;}mysql_close(pDB);}delete mysql;return 0;
}int main(){//user_create();//database_create();create_table();// 程序正常退出return 0;
}效果:创建了一个空表(调试到DROP之前)
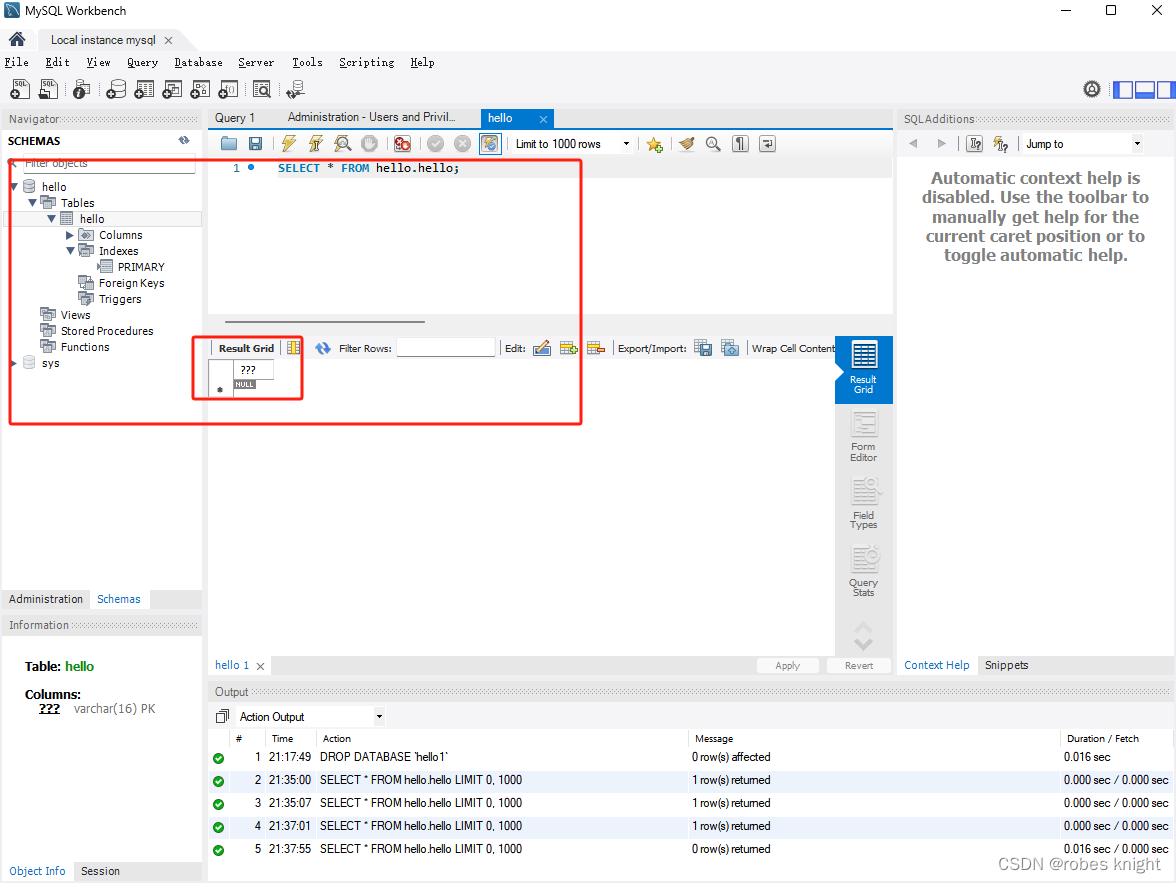
注意:
- 主键的数据类型,它不能是可变长度的类型 例如:TEXT、BLOB
- 表名需要使用``符号来包围,千万不能使用单引号
三、增删改查
3.1 插入
向MySQL数据表插入数据通用的 INSERTINTOSQL语法:
语法:
INSERT INTO 表名([字段1,字段2..])VALUES('值1','值2'..),[('值1','值2'..)..];
-- 普通用法
INSERT INTO `student`(`name`) VALUES ('zsr');-- 插入多条数据
INSERT INTO `student`(`name`,`pwd`,`sex`) VALUES ('zsr','200024','男'),('gcc','000421','女');-- 省略字段
INSERT INTO `student` VALUES (5,'Bareth','123456','男','2000-02-04','武汉','1412@qq.com',1);
- 字段和字段之间使用英文逗号隔开
- 字段是可以省略的,但是值必须完整且一一对应
- 可以同时插入多条数据,VALUES后面的值需要使用逗号隔开
实例:
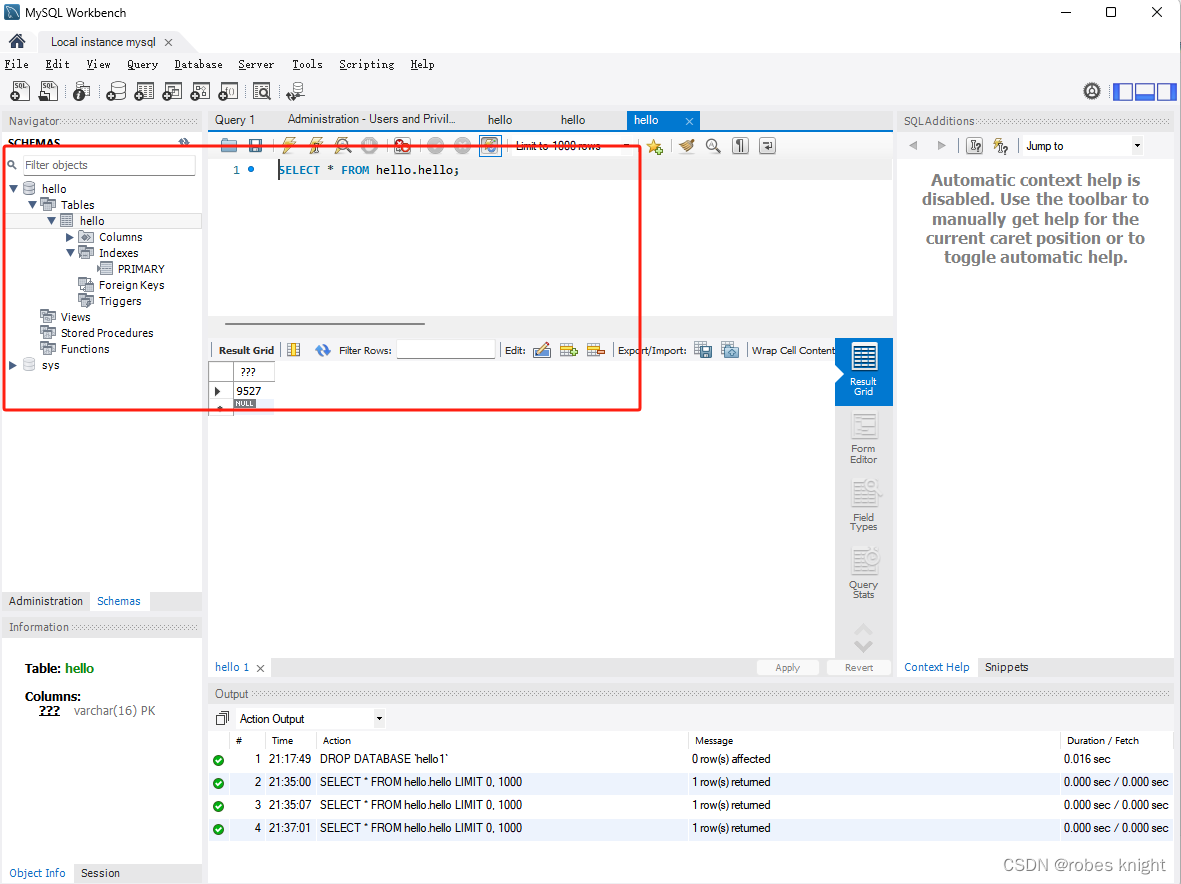
sql = "CREATE TABLE IF NOT EXISTS `hello` (`编号` NVARCHAR(16) PRIMARY KEY)ENGINE = InnoDB DEFAULT CHARSET = utf8; ";ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "mysql error:" << mysql_error(pDB) << std::endl;//return-1;}sql = "INSERT INTO `hello` (`编号`) VALUES (\"9527\");";ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "mysql error:" << mysql_error(pDB) << std::endl;//return-1;}
效果:
3.2 删除
MySQL 数据表中删除数据的通用语法:
DELETE FROM 表名 [WHERE 条件]
-- 删除数据(避免这样写,会全部删除)
DELETE FROM `student`;-- 删除指定数据
DELETE FROM `student` WHERE id=1;
- 如果没有指定 WHERE 子句,MySQL 表中的所有记录将被删除。
- 你可以在 WHERE 子句中指定任何条件
- 您可以在单个表中一次性删除记录。
- 当你想删除数据表中指定的记录时 WHERE 子句是非常有用的
实例:
sql = "INSERT INTO `hello` (`编号`) VALUES (\"9527\");";ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "mysql error:" << mysql_error(pDB) << std::endl;//return-1;}sql = "INSERT INTO `hello` (`编号`) VALUES (\"9528\");";ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "mysql error:" << mysql_error(pDB) << std::endl;//return-1;}sql = "DELETE FROM `hello` WHERE `编号`=\"9527\";";ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "mysql error:" << mysql_error(pDB) << std::endl;//return-1;}效果:
只剩下9528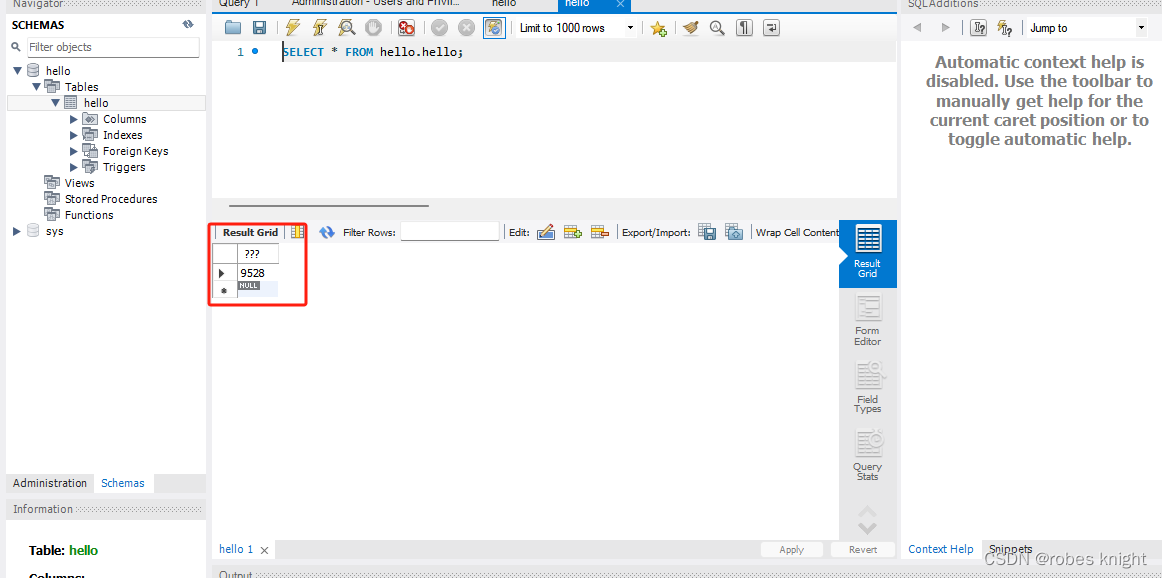
3.3 数据更新
MySQL 数据表数据的通用 SQL 语法:
UPDATE 表名 SET 字段1=值1,[字段2=值2...] WHERE 条件[];
-- 修改学员名字,指定条件
UPDATE `student` SET `name`='zsr204' WHERE id=1;-- 不指定条件的情况,会改动所有表
UPDATE `student` SET `name`='zsr204';-- 修改多个属性
UPDATE `student` SET `name`='zsr',`address`='湖北' WHERE id=1;-- 通过多个条件定位数据
UPDATE `student` SET `name`='zsr204' WHERE `name`='zsr' AND `pwd`='200024';
- 你可以同时更新一个或多个字段。
- 你可以在 WHERE 子句中指定任何条件。
- 你可以在一个单独表中同时更新数据。
- 当你需要更新数据表中指定行的数据时 WHERE 子句是非常有用的。
实例:
sql = "UPDATE `hello` SET age=18 WHERE `编号`=\"9528\";";ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "mysql error:" << mysql_error(pDB) << std::endl;return-1;}sql = "UPDATE `hello` SET age=19 WHERE `age`>=35 AND `age`!=18;";ret = mysql_real_query(pDB, sql.c_str(), (unsigned long)sql.size());if (ret != 0) {std::cout << "mysql error:" << mysql_error(pDB) << std::endl;return-1;}
- "UPDATE `hello`: 指定了要更新的表名为
hello。SET age=19: 指明将
age列的值更新为19。WHERE
age>=35 ANDage!=18: 定义了更新操作的条件。只有当age列的值大于或等于35并且age的值不等于18时,该行的age列的值才会被更新为19。
3.4 查询
SELECT table_name.column_name,column_name,...FROM table_name,table_name2,...WHERE ClauseLIMIT N OFFSET M
SELECT: 这部分指定要从数据库中检索的列。可以使用
table_name.column_name的形式指定某个表的特定列,或者直接使用column_name如果在查询上下文中列名是唯一的。FROM: 指定要从中检索数据的表。如果要从多个表中检索数据,表名之间应该使用逗号
,分隔。WHERE: 这个子句用于过滤
SELECT语句返回的记录,只包括满足指定条件的记录。这部分是可选的,如果省略,SELECT语句将返回所有记录。LIMIT N: 这个子句用于限制查询结果的数量。
N是一个整数,定义了返回记录的最大数目。OFFSET M: 这个子句用于指定从哪里开始返回记录。
M是一个整数,表示要跳过的记录数量。这通常用于实现分页功能。
查询语句中你可以使用一个或者多个表,表之间使用逗号(,)分割,并使用WHERE语句来设 定查询条件。SELECT 命令可以读取一条或者多条记录。
- 你可以使用星号(*)来代替其他字段,SELECT语句会返回表的所有字段数据
- 你可以使用 WHERE 语句来包含任何条件。
- 你可以使用 LIMIT 属性来设定返回的记录数。
- 你可以通过OFFSET指定SELECT语句开始查询的数据偏移量。默认情况下偏移量为0。
1.基础查询
SELECT 查询列表 FROM 表名;
- 查询列表可以是:表中的(一个或多个)字段,常量,变量,表达式,函数
- 查询结果是一个虚拟的表格
-- 查询全部学生
SELECT * FROM student;-- 查询指定的字段
SELECT `LoginPwd`,`StudentName` FROM student;-- 别名 AS(可以给字段起别名,也可以给表起别名)
SELECT `StudentNo` AS 学号,`StudentName` AS 学生姓名 FROM student AS 学生表;-- 函数 CONCAT(str1,str2,...)
SELECT CONCAT('姓名',`StudentName`) AS 新名字 FROM student;-- 查询系统版本(函数)
SELECT VERSION();-- 用来计算(计算表达式)
SELECT 100*53-90 AS 计算结果;-- 查询自增步长(变量)
SELECT @@auto_increment_increment;-- 查询有哪写同学参加了考试,重复数据要去重
SELECT DISTINCT `StudentNo` FROM result;
2.条件查询
where 条件字句:检索数据中符合条件的值语法:
select 查询列表 from 表名 where 筛选条件;
使用:
-- 查询考试成绩在95~100之间的
SELECT `StudentNo`,`StudentResult` FROM result
WHERE `StudentResult`>=95 AND `StudentResult`<=100;
-- &&
SELECT `StudentNo`,`StudentResult` FROM result
WHERE `StudentResult`>=95 && `StudentResult`<=100;
-- BETWEEN AND
SELECT `StudentNo`,`StudentResult` FROM result
WHERE `StudentResult`BETWEEN 95 AND 100;-- 查询除了1000号以外的学生
SELECT `StudentNo`,`StudentResult` FROM result
WHERE `StudentNo`!=1000;
-- NOT
SELECT `StudentNo`,`StudentResult` FROM result
WHERE NOT `StudentNo`=1000;-- 查询名字含d的同学
SELECT `StudentNo`,`StudentName` FROM student
WHERE `StudentName` LIKE '%d%';-- 查询名字倒数第二个为d的同学
SELECT `StudentNo`,`StudentName` FROM student
WHERE `StudentName` LIKE '%d_';-- 查询1000,1001学员
SELECT `StudentNo`,`StudentName` FROM student
WHERE `StudentNo` IN (1000,1001);
3.分组查询
select 分组函数,分组后的字段
from 表
【where 筛选条件】
group by 分组的字段
【having 分组后的筛选】
【order by 排序列表】

-- 查询不同科目的平均分、最高分、最低分且平均分大于90
-- 核心:根据不同的课程进行分组
SELECT SubjectName,AVG(StudentResult),MAX(`StudentResult`),MIN(`StudentResult`)
FROM result r
INNER JOIN `subject` s
on r.SubjectNo=s.SubjectNo
GROUP BY r.SubjectNo
HAVING AVG(StudentResult)>90;
4.联合查询
联合多次查询结果:
UNION关键字用于合并第一个和随后的SELECT语句的结果
SELECT expression1, expression2, ... expression_n
FROM tables
[WHERE conditions]
UNION [ALL | DISTINCT]
SELECT expression1, expression2, ... expression_n
FROM tables
[WHERE conditions];
4.连接查询

实例:
-- 查询学员所属的年级(学号,学生姓名,年级名称)
SELECT `StudentNo`,`StudentName`,`GradeName`
FROM student s
/*INNER JOIN 子句用于连接两个表。这里连接了 grade 表,
并且给 grade 表指定了别名 g。INNER JOIN 会合并两个表中有匹配的行,
如果行在连接的两边都没有匹配,则不会出现在结果集中。*/
INNER JOIN grade g
/* ON 子句指定了连接条件。这里,连接的条件是 student 表中
的 GradeID 列与 grade 表中的 GradeID 列相等。基于这个条件,
只有当两个表的 GradeID 值匹配时,相应的行才会被包含在内。*/
ON s.GradeID=g.GradeID;
-- 查询科目所属的年级
SELECT `SubjectName`,`GradeName`
FROM `subject` s
INNER JOIN `grade` g
ON s.GradeID=g.GradeID;-- 查询列参加程序设计考试的同学信息(学号,姓名,科目名,分数)
SELECT s.`StudentNo`,`StudentName`,`SubjectName`,`StudentResult`
FROM student s
INNER JOIN result r
on s.StudentNo=r.StudentNo
INNER JOIN `subject` sub
on r.SubjectNo=sub.SubjectNo
where SubjectName='课程设计';
四.索引
索引(
Index)是帮助MySQL高效获取数据的数据结构。
- 提高查询速度
- 确保数据的唯一性
- 可以加速表和表之间的连接 , 实现表与表之间的参照完整性
- 使用分组和排序子句进行数据检索时 , 可以显著减少分组和排序的时间
- 全文检索字段进行搜索优化
缺点:
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。 上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点: 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE 和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。 易道云信息技术研究院 建立索引会占用磁盘空间的索引文件
以下面这段代码来解释不同索引:
-- 创建学生表student
CREATE TABLE `student`( `StudentNo` INT(4) NOT NULL COMMENT '学号',`LoginPwd` VARCHAR(20) DEFAULT NULL,`StudentName` VARCHAR(20) DEFAULT NULL COMMENT '学生姓名',`Sex` TINYINT(1) DEFAULT NULL COMMENT '性别,取值0或1',`GradeID` INT(11) DEFAULT NULL COMMENT '年级编号',`Phone` VARCHAR(50) NOT NULL COMMENT '联系电话,允许为空,即可选输入',`Adress` VARCHAR(255) NOT NULL COMMENT '地址,允许为空,即可选输入',`BornDate` DATETIME DEFAULT NULL COMMENT '出生时间',`Email` VARCHAR(50) NOT NULL COMMENT '邮箱账号,允许为空,即可选输入',`IdentityCard` VARCHAR(18) DEFAULT NULL COMMENT '身份证号',PRIMARY KEY (`StudentNo`),UNIQUE KEY `IdentityCard` (`IdentityCard`),KEY `Email` (`Email`)
)ENGINE=MYISAM DEFAULT CHARSET=utf8;
1.主键索引(PRIMARY KEY)
唯一的标识,主键不可重复,只有一个列作为主键
- 最常见的索引类型,不允许为空值
- 确保数据记录的唯一性
- 确定特定数据记录在数据库中的位置
PRIMARY KEY (`StudentNo`),-- 创建表的时候指定主键索引
CREATE TABLE tableName(......PRIMARY INDEX (columeName)
)-- 修改表结构添加主键索引
ALTER TABLE tableName ADD PRIMARY INDEX (columnName)
2.普通索引(KEY / INDEX)
默认的,快速定位特定数据
- index 和 key 关键字都可以设置常规索引
- 应加在查询找条件的字段
- 不宜添加太多常规索引,影响数据的插入,删除和修改操作
KEY `Email` (`Email`)-- 直接创建普通索引
CREATE INDEX indexName ON tableName (columnName)-- 创建表的时候指定普通索引
CREATE TABLE tableName(......INDEX [indexName] (columeName)
)-- 修改表结构添加普通索引
ALTER TABLE tableName ADD INDEX indexName(columnName)
3.唯一索引(UNIQUE KEY)
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值
与主键索引的区别:主键索引只能有一个、唯一索引可以有多个
UNIQUE KEY `IdentityCard` (`IdentityCard`),-- 直接创建唯一索引
CREATE UNIQUE INDEX indexName ON tableName(columnName)-- 创建表的时候指定唯一索引
CREATE TABLE tableName( ......UNIQUE INDEX [indexName] (columeName)
); -- 修改表结构添加唯一索引
ALTER TABLE tableName ADD UNIQUE INDEX [indexName] (columnName)
五.事物
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删 除一个人员,你既需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章 等等,这样,这些数据库操作语句就构成一个事务!
在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
谈到事务一般都是以下四点
原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性(Consistency)
事务前后数据的完整性必须保持一致。
隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
5.1 事物四大特性
1.原子性
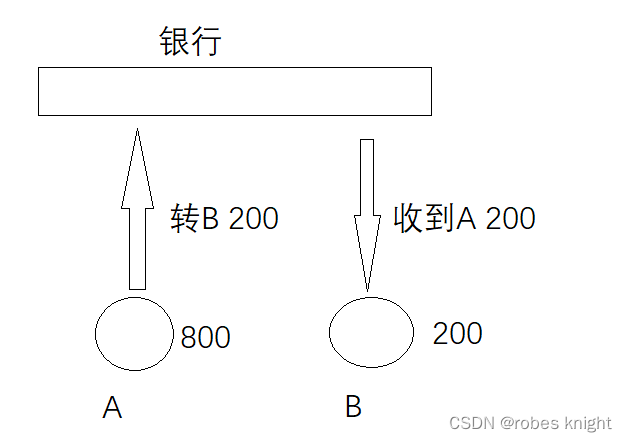
这个过程包含两个步骤
A: 800 - 200 = 600
B: 200 + 200 = 400
原子性表示,这两个步骤一起成功,或者一起失败,不能只发生其中一个动作
2.一致性(Consistency)
操作前A:800,B:200
操作后A:600,B:400
一致性表示事务完成后,符合逻辑运算
3.持久性
表示事务结束后的数据不随着外界原因导致数据丢失
操作前A:800,B:200
操作后A:600,B:400
如果在操作前(事务还没有提交)服务器宕机或者断电,那么重启数据库以后,数据状态应该为
A:800,B:200
如果在操作后(事务已经提交)服务器宕机或者断电,那么重启数据库以后,数据状态应该为
A:600,B:400
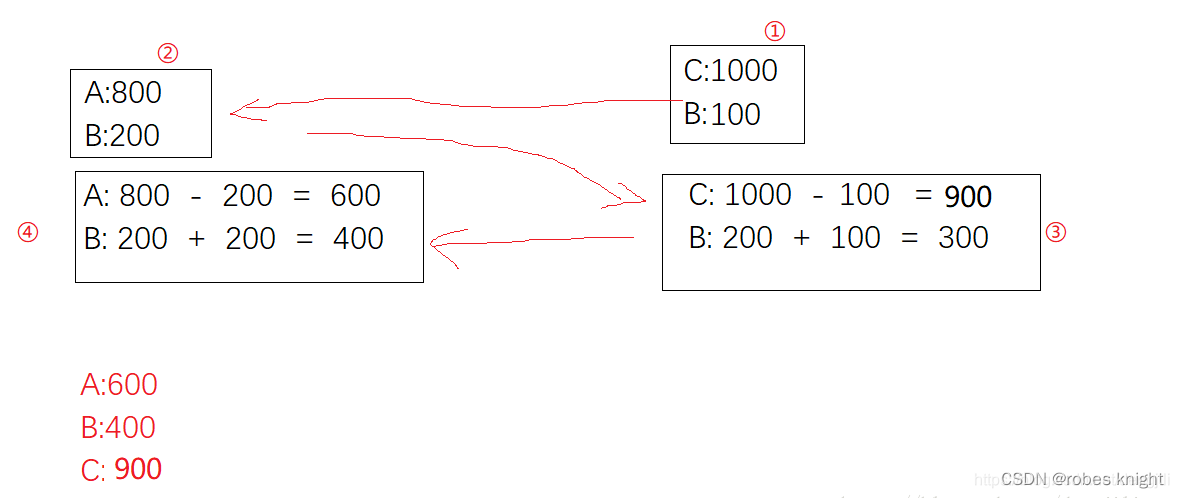
4.隔离性
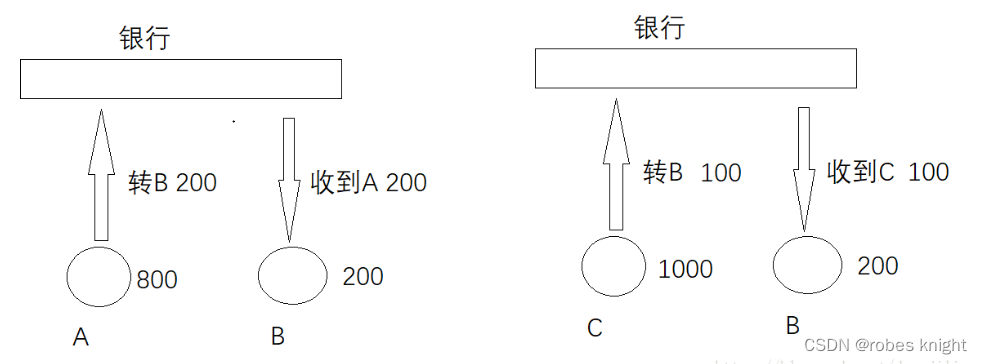
事务一)A向B转账200
事务二)C向B转账100
两个事务同时进行,其中一个事务读取到另外一个事务还没有提交的数据,执行步骤如图所示,按照数字顺序执行
5.2 事物执行
MYSQL 事务处理主要有两种方法:
1、用 BEGIN,ROLLBACK,COMMIT 命令行语句来实现
- BEGIN 开始一个事务
- ROLLBACK 事务回滚
- COMMIT 事务确认
BEGIN; -- 开始一个事务
INSERT INTO table_name (column1) VALUES (value1); -- 执行操作
-- 如果发生错误
ROLLBACK; -- 回滚事务
2、直接用 SET 来改变 MySQL 的自动提交模式,并通过相应的函数来实现:
- SETAUTOCOMMIT=0 禁止自动提交
- SETAUTOCOMMIT=1 开启自动提交
bool STDCALL mysql_commit(MYSQL *mysql);bool STDCALL mysql_rollback(MYSQL *mysql);bool STDCALL mysql_autocommit(MYSQL *mysql, bool auto_mode);1.命令行方式
1️⃣ 关闭自动提交
SET autocommit=0; 2️⃣ 事务开启
START TRANSACTION -- 标记一个事务的开始,从这个之后的sql都在同一个事务内3️⃣ 成功则提交,失败则回滚
-- 提交:持久化(成功)
COMMIT
-- 回滚:回到原来的样子(失败)
ROLLBACK4️⃣ 事务结束
SET autocommit=1; -- 开启自动提交5️⃣ 其他操作
SAVEPOINT 保存点名; -- 设置一个事务的保存点
ROLLBACK TO SAVEPOINT 保存点名; -- 回滚到保存点
RELEASE SAVEPOINT 保存点名; -- 撤销保存点2. 函数操作(c++)
#include <mysql.h>
#include <stdbool.h>
#include <stdio.h>int main() {MYSQL *mysql;bool ret;// 初始化连接mysql = mysql_init(NULL);// 连接到数据库if (mysql_real_connect(mysql, "host", "user", "password", "database", 0, NULL, 0) == NULL) {fprintf(stderr, "Failed to connect to database: Error: %s\n", mysql_error(mysql));mysql_close(mysql);return 1;}// 关闭自动提交ret = mysql_autocommit(mysql, false);if (!ret) {fprintf(stderr, "Failed to disable autocommit mode: Error: %s\n", mysql_error(mysql));mysql_close(mysql);return 1;}// 开始事务,执行一系列SQL操作if (mysql_query(mysql, "INSERT INTO `table_name` (`column`) VALUES ('value')") ||mysql_query(mysql, "UPDATE `table_name` SET `column` = 'value' WHERE `id` = 1")) {fprintf(stderr, "SQL Error: %s\n", mysql_error(mysql));// 如果出错则回滚事务mysql_rollback(mysql);mysql_close(mysql);return 1;}// 提交事务ret = mysql_commit(mysql);if (!ret) {fprintf(stderr, "Failed to commit transaction: Error: %s\n", mysql_error(mysql));mysql_rollback(mysql);mysql_close(mysql);return 1;}// 重新启用自动提交mysql_autocommit(mysql, true);// 关闭数据库连接mysql_close(mysql);return 0;
}
六.触发器
触发器解释:
触发器是与表有关的数据库对象,在满足定义条件时触发,并执行触发器中定义的语句集合。 触发器的这种特性可以协助应用在数据库端确保数据的完整性。 举个例子,比如你现在有两个表【用户表】和【日志表】,当一个用户被创建的时候,就需 要在日志表中插入创建的log日志,如果在不使用触发器的情况下,你需要编写程序语言逻 辑才能实现,但是如果你定义了一个触发器,触发器的作用就是当你在用户表中插入一条数 据的之后帮你在日志表中插入一条日志信息。当然触发器并不是只能进行插入操作,还能执 行修改,删除。
触发器语法:
CREATE TRIGGER trigger_name trigger_time trigger_event ON tb_name FOR EACH ROWtrigger_stmttrigger_name:触发器的名称 tirgger_time:触发时机,为 BEFORE或者AFTER trigger_event:触发事件,为 INSERT、DELETE 或者 UPDATE
tb_name:表示建立触发器的表明,就是在哪张表上建立触发器
trigger_stmt:触发器的程序体,可以是一条SQL语句或者是用BEGIN和END包含的多条语 句
MySQL创建以下六种触发器:
BEFORE INSERT
BEFORE DELETE
BEFORE UPDATE
AFTER INSERT
AFTER DELETE
AFTER UPDATE
CREATE TRIGGER 触发器名 BEFORE|AFTER 触发事件
ON 表名 FOREACHROW
BEGIN
执行语句列表
END实例:
// Connect to databaseif (!mysql_real_connect(conn, server, user, password, database, 0, NULL, 0)) {std::cerr << "mysql_real_connect failed: " << mysql_error(conn) << std::endl;return 1;}// Define the CREATE TRIGGER statementconst char *create_trigger = R"SQL(CREATE TRIGGER `before_student_insert`BEFORE INSERT ON `students` FOR EACH ROWBEGINIF NEW.age < 18 THENSIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Students must be at least 18 years old.';END IF;END;)SQL";// Execute the SQL statementif (mysql_query(conn, create_trigger)) {std::cerr << "mysql_query failed: " << mysql_error(conn) << std::endl;mysql_close(conn);return 1;}std::cout << "Trigger created successfully" << std::endl;七:补充知识
1.数据备份
MySQL 中你可以使用SELECT...INTO OUTFILE 语句来简单的导出数据到文本文件上。
实例1:
将数据表 hello 数据导出到 ./data.txt 文件中
SELECT * FROM`hello` INTO OUTFILE './data.txt';实例2:
通过命令选项来设置数据输出的指定格式,以下实例为导出 CSV 格式:
SELECT * FROM`passwd` INTO OUTFILE './data.txt'
//FIELDS TERMINATED BY ',':字段(列)之间将以逗号,分隔。FIELDS TERMINATED BY ','
//ENCLOSED BY '"':每个字段的值将被双引号"包围。
//这通常用于确保字段中的任何逗号不会被误解为字段分隔符。ENCLOSED BY '"'
//LINES TERMINATED BY '\r\n':每一行将以回车换行符结束,
//这是Windows系统中常用的行终止符。在Unix或Linux系统中,通常只使用换行符\n。LINES TERMINATED BY'\r\n';示例3:
SELECT a,b,a+b INTO OUTFILE './data.text'FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'LINES TERMINATED BY'\n'FROM test_table;注意:
SELECT...INTO OUTFILE 'file_name'形式的 SELECT 可以把被选择的行写入一个文件中。该文件 被创建到服务器主机上,因此您必须拥有FILE创建权限,才能使用此语法。
linux:
需要有一个登陆服务器的账号来检索文件。否则 SELECT... INTOOUTFILE 不会起任何作 用。 在UNIX中,该文件被创建后是可读的,权限由MySQL服务器所拥有。这意味着,虽然你就 可以读取该文件,但可能无法将其删除。
windows:
Windows下是有限制的 先要打开my.ini,然后找到secure-file-priv 参数 依据这个参数填路径,否则有权限错误,示例如下:
"SELECT * FROM `hello` INTO OUTFILE 'C:/ProgramData/MySQL/MySQL Server8.0/Uploads/hello.txt'\n \FIELDS TERMINATED BY ',' \n \LINES TERMINATED BY '\r\n'";
2.数据恢复
MySQL 中提供了LOADDATAINFILE 语句来插入数据
示例1:
以下实例中将从当前目录中读取文件 dump.txt ,将该文件中的数据插入到当前数据库的 mytbl 表中。
LOAD DATALOCAL INFILE 'dump.txt' INTO TABLE mytbl;如果指定LOCAL关键词,则表明从客户主机上按路径读取文件。如果没有指定,则文件 在服务器上按路径读取文件。
示例2:
你能明确地在LOADDATA语句中指出列值的分隔符和行尾标记,但是默认标记是定位符和 换行符。 易道云信息技术研究院 两个命令的 FIELDS 和 LINES 子句的语法是一样的。两个子句都是可选的,但是如果两个同 时被指定,FIELDS 子句必须出现在 LINES 子句之前。 如果用户指定一个 FIELDS 子句,它的子句(TERMINATEDBY、[OPTIONALLY]ENCLOSEDBY 和 ESCAPED BY) 也是可选的,不过,用户必须至少指定它们中的一个。
LOADDATALOCAL INFILE 'dump.txt' INTO TABLE mytblFIELDS TERMINATED BY ':'LINES TERMINATED BY'\r\n';实例3:
LOAD DATA 默认情况下是按照数据文件中列的顺序插入数据的,如果数据文件中的列与插 入表中的列不一致,则需要指定列的顺序。 如,在数据文件中的列顺序是 a,b,c,但在插入表的列顺序为b,c,a,则数据导入语法如下:
LOADDATALOCAL INFILE 'dump.txt'INTO TABLE mytbl (b, c, a);代码示例:
//方法1
"LOAD DATA LOCAL INFILE 'C:/ProgramData/MySQL/MySQL Server 8.0/Uploads/hello.txt' INTO
TABLE `hello`\n \FIELDS TERMINATED BY ',' \n \LINES TERMINATED BY '\r\n'"//方法2mysqlimport.exe-u root-pFengPan12#$56--local hello "C:/ProgramData/MySQL/MySQL Server8.0/Uploads/hello.txt"--fields-terminated-by=","--lines-terminated-by="\r\n"3.mysql5.0以上恢复数据的注意点
使用:
"LOAD DATA LOCAL INFILE 'C:/ProgramData/MySQL/MySQL Server 8.0/Uploads/hello.txt' INTO
TABLE `hello`\n \FIELDS TERMINATED BY ',' \n \LINES TERMINATED BY '\r\n'"恢复数据,会报错:

原因:
新版本中,很多病毒会通过mysql客户端恢复数据传播,因此官方禁止直接在mysql(客户端)中恢复数据
解决方法,在服务器上执行下面语句恢复:
mysqlimport.exe-u root-pFengPan12#$56--local hello "C:/ProgramData/MySQL/MySQL Server8.0/Uploads/hello.txt"--fields-terminated-by=","--lines-terminated-by="\r\n"如果存放在windows本机下,就使用系统命令来恢复:
std::string cmd = "mysqlimport -u root -pFengPan12#$56 --local hello ";
cmd += "\"C:/ProgramData/MySQL/MySQL Server 8.0/Uploads/hello.txt\" ";
cmd += "--fields-terminated-by=\",\" --lines-terminated-by=\"\\r\\n\"";
system(cmd.c_str());
//import语句会中断连接,如果本地执行,需要自己重新connect mysql如果存放在其他服务器,就要登录服务器,或者ssh过去才行
4.内置函数
MySql函数是MySql数据库提供的内置函数,这些内置函数可以帮助用户更方便的处理表中的数据。

1.数学函数
abs(x)
统计绝对值
count()
数据库系统中 COUNT(expr)用于统计数据行数,其主要作用为返回SELECT语句检索的行中 expr 表达式的值不为 NULL 的行的数量,返回值是一个 BIGINT 值,如果查询结果没有命中任何记录则返回 0。通常的使用方式主要有以下两种:
- COUNT(column) 表示统计对应列有值(不为空)的数据的行数
- COUNT(*) 表示统计结果集的总行数
mysql中的使用:
SELECTcount( * )
FROMt_user
WHEREid > 20;
2.日期函数
返回当前日期:CURDATE(), CURRENT_DATE(), CURRENT_DATE
返回当前时间:CURTIME(), CURRENT_TIME(), CURRENT_TIME
返回当前日期和时间:CURRENT_TIMESTAMP(), CURRENT_TIMESTAMP, LOCALTIME(), LOCALTIME, LOCALTIMESTAMP(), LOCALTIMESTAMP, NOW(), SYSDATE()
参考博客
MySQL详细学习教程(建议收藏)-CSDN博客
事务ACID理解-CSDN博客
mysql_rollback_MySQL的rollback--事务回滚-CSDN博客
C++MySQL数据库操作语句、事务的四大特性_c语言如何使用数据库事务-CSDN博客
MySql中的内置函数大全_mysql内置函数-CSDN博客
MySQL 数据库统计函数 COUNT_mysql count-CSDN博客
MySQL常用的日期时间函数_mysql 时间函数-CSDN博客