Flink SQL支持对动态表进行复杂而灵活的连接操作。 为了处理不同的场景,需要多种查询语义,因此有几种不同类型的 Join。
默认情况下,joins 的顺序是没有优化的。表的 join 顺序是在 FROM 从句指定的。可以通过把更新频率最低的表放在第一个、频率最高的放在最后这种方式来微调 join 查询的性能。需要确保表的顺序不会产生笛卡尔积,因为不支持这样的操作并且会导致查询失败。
1. Regular Joins
Regular join 是最通用的 join 类型。在这种 join 下,join 两侧表的任何新记录或变更都是可见的,并会影响整个 join 的结果。 例如:如果左边有一条新纪录,在 Product.id 相等的情况下,它将和右边表的之前和之后的所有记录进行 join。
- window join 和 interval Join 都是基于划分窗口,将无界数据变为有界数据进行关联
- regular join 则还是基于无界数据进行关联
SELECT * FROM Orders
INNER JOIN Product
ON Orders.productId = Product.id
对于流式查询,regular join 的语法是最灵活的,允许任何类型的更新(插入、更新、删除)输入表。 然而,这种操作具有重要的操作意义:Flink 需要将 Join 输入的两边数据永远保持在状态中。 因此,计算查询结果所需的状态可能会无限增长,这取决于所有输入表的输入数据量。你可以提供一个合适的状态 time-to-live (TTL) 配置来防止状态过大。注意:这样做可能会影响查询的正确性。查看 查询配置 了解详情。
以 A 流 left join B 流举例
A 流数据到来之后,直接去尝试关联 B 流数据:
- 如果关联到了则直接下发关联到的数据
- 如果没有关联到则也直接下发没有关联到的数据,后续 B 流中的数据到来之后,会把之前下发下去的没有关联到数据撤回,然后把关联到的数据数据进行下发。由此可以看出这是基于 Flink SQL 的 retract 机制,则也就说明了其目前只支持 Flink SQL
INNER Equi-JOIN
根据 join 限制条件返回一个简单的笛卡尔积。目前只支持 equi-joins,即:至少有一个等值条件。不支持任意的 cross join 和 theta join。(cross join 指的是类似 SELECT * FROM table_a CROSS JOIN table_b,theta join 指的是类似 SELECT * FROM table_a, table_b)
SELECT *
FROM Orders
INNER JOIN Product
ON Orders.product_id = Product.id
OUTER Equi-JOIN
返回所有符合条件的笛卡尔积(即:所有通过 join 条件连接的行),加上所有外表没有匹配到的行。Flink 支持 LEFT、RIGHT 和 FULL outer joins。目前只支持 equi-joins,即:至少有一个等值条件。不支持任意的 cross join 和 theta join。
SELECT *
FROM Orders
LEFT JOIN Product
ON Orders.product_id = Product.idSELECT *
FROM Orders
RIGHT JOIN Product
ON Orders.product_id = Product.idSELECT *
FROM Orders
FULL OUTER JOIN Product
ON Orders.product_id = Product.idSQL API
CREATE TABLE show_log_table (log_id BIGINT,show_params STRING
) WITH ('connector' = 'datagen','rows-per-second' = '1','fields.show_params.length' = '3','fields.log_id.min' = '1','fields.log_id.max' = '10'
);CREATE TABLE click_log_table (log_id BIGINT,click_params STRING
)
WITH ('connector' = 'datagen','rows-per-second' = '1','fields.click_params.length' = '3','fields.log_id.min' = '1','fields.log_id.max' = '10'
);CREATE TABLE sink_table (s_id BIGINT,s_params STRING,c_id BIGINT,c_params STRING
) WITH ('connector' = 'print'
);INSERT INTO sink_table
SELECTshow_log_table.log_id as s_id,show_log_table.show_params as s_params,click_log_table.log_id as c_id,click_log_table.click_params as c_params
FROM show_log_table
LEFT JOIN click_log_table ON show_log_table.log_id = click_log_table.log_id;
DataStream API
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class RegularJoinExample {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 创建两个数据流DataStream<LeftRecord> leftStream = ...; // 左侧数据流DataStream<RightRecord> rightStream = ...; // 右侧数据流// Regular Join 操作DataStream<ResultRecord> joinedStream = leftStream.join(rightStream).where(leftRecord -> leftRecord.getKey()) // 指定左侧数据流的连接键.equalTo(rightRecord -> rightRecord.getKey()) // 指定右侧数据流的连接键.window(TumblingProcessingTimeWindows.of(Time.seconds(10))) // 指定窗口,如果不指定,默认为全局窗口.apply((leftRecord, rightRecord) -> new ResultRecord(leftRecord, rightRecord)); // 指定连接后的处理逻辑// 打印结果joinedStream.print();// 执行任务env.execute("Regular Join Example");}
}
上面的inner join一般可以不重写joinfunction,因为逻辑较简单,可以直接用lambda表达式,
匹配到的数据输出就行。下面的left join通常要重写 实现JoinFunction 接口或者使用 RichCoFlatMapFunction;
left join的例子:
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;public class LeftJoinExample {public static void main(String[] args) throws Exception {// 设置执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 假设有两个数据流,stream1 和 stream2DataStream<Tuple2<String, Integer>> stream1 = ...;DataStream<Tuple2<String, String>> stream2 = ...;// 执行 left join 操作DataStream<Tuple2<String, Integer>> resultStream = stream1.leftJoin(stream2).where(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0; // 指定 stream1 的键}}).equalTo(new KeySelector<Tuple2<String, String>, String>() {@Overridepublic String getKey(Tuple2<String, String> value) throws Exception {return value.f0; // 指定 stream2 的键}}).window(TumblingEventTimeWindows.of(Time.seconds(10))) // 如果需要窗口操作,可以在这里设置窗口//通常情况下需要自己实现 JoinFunction 接口或者使用 RichCoFlatMapFunction 接口, 否则用原生的 left join 结果可能并不会被包装在一个对象中,而是以一种 Flink 内部的数据结构返回或者是Flink 将无法知道如何处理两个流中的元素 .apply(new JoinFunction<Tuple2<String, Integer>, Tuple2<String, String>, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> join(Tuple2<String, Integer> first, Tuple2<String, String> second) throws Exception {if (second == null) {// 如果 stream2 中没有匹配的元素,则输出 stream1 中的元素,并将 stream2 中的值设置为 nullreturn new Tuple2<>(first.f0, first.f1);} else {// 如果 stream2 中有匹配的元素,则输出 stream1 和 stream2 中匹配的元素return new Tuple2<>(first.f0, first.f1);}}});// 输出 left join 的结果resultStream.print();// 执行程序env.execute("Left Join Example");}
}
注:JoinFunction<IN1, IN2, OUT>
KeySelector<IN, KEY>
RegularJoin特点
- join的流的数据都会存在flink的状态中Forever
- 流中所有的数据对对方来说都是可见的
- 只能用于有界流
- 只能用于等值连接
- 支持 Flink SQL
解决方案的适用场景
该种解决方案虽然是目前在产出质量、时效性上最好的一种解决方案,但是在实际场景中使用时,也存在一些问题:
⭐ 基于 retract 机制,所有的数据都会存储在 state 中以判断能否关联到,所以我们要设置合理的 state ttl 来避免大 state 问题导致的任务不稳定
⭐ 基于 retract 机制,所以在数据发生更新时,会下发回撤数据、最新数据 2 条消息,当我们的关联层级越多,则下发消息量的也会放大
⭐ sink 组件要支持 retract,我们不要忘了最终数据是要提供数据服务给需求方进行使用的,所以我们最终写入的数据组件也需要支持 retract,比如 MySQL。如果写入的是 Kafka,则下游消费这个 Kafka 的引擎也需要支持回撤\更新机制。
Join优化思路
针对上面 3 节说到的 Flink Join 的方案,各自都有一些优势和劣势存在。
但是我们可以发现,无论是哪一种 Join 方案,Join 的前提都是将 A 流和 B 流的数据先存储在状态中,然后再进行关联。
即在实际生产中使用时常常会碰到的问题就是:大状态的问题。
两种大Key状态优化方案
关于大状态问题业界常见两种解决思路:
⭐ 减少状态大小:在 Flink Join 中的可以想到的优化措施就是减少 state key 的数量。在未优化之前 A 流和 B 流的数据往往是存储在单独的两个 State 实例中的,那么我们的优化思路就是将同 Key 的数据放在一起进行存储,一个 key 的数据只需要存储一份,减少了 key 的数量
⭐ 转移状态至外存:大 State 会导致 Flink 任务不稳定,那么我们就将 State 存储在外存中,让 Flink 任务轻量化,比如将数据存储在 Redis 中,A 流和 B 流中相同 key 的数据共同维护在一个 Redis 的 hashmap 中,以供相互进行关联
接下来看看这两种方案实际需要怎样落地。讲述思路也是按照以下几点进行阐述:
⭐ 优化方案说明
⭐ 优化方案 Flink API
⭐ 优化方案的特点
⭐ 优化方案的适用场景
Flink Join 优化方案:同 key 共享 State
优化方案说明
将两条流的数据使用 union、connect 算子合并在一起,然后使用一个共享的 state 进行处理
优化方案 Flink API
FlinkEnv flinkEnv = FlinkEnvUtils.getStreamTableEnv(args);flinkEnv.env().setParallelism(1);flinkEnv.env().addSource(new SourceFunction<Object>() {@Overridepublic void run(SourceContext<Object> ctx) throws Exception {}@Overridepublic void cancel() {}}).keyBy(new KeySelector<Object, Object>() {@Overridepublic Object getKey(Object value) throws Exception {return null;}}).connect(flinkEnv.env().addSource(new SourceFunction<Object>() {@Overridepublic void run(SourceContext<Object> ctx) throws Exception {}@Overridepublic void cancel() {}}).keyBy(new KeySelector<Object, Object>() {@Overridepublic Object getKey(Object value) throws Exception {return null;}}))// 左右两条流的数据.process(new KeyedCoProcessFunction<Object, Object, Object, Object>() {// 两条流的数据共享一个 mapstate 进行处理private transient MapState<String, String> mapState;@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);this.mapState = getRuntimeContext().getMapState(new MapStateDescriptor<String, String>("a", String.class, String.class));}@Overridepublic void processElement1(Object value, Context ctx, Collector<Object> out) throws Exception {}@Overridepublic void processElement2(Object value, Context ctx, Collector<Object> out) throws Exception {}}).print();
优化方案的特点
在此种优化方案下,我们可以自定义:
⭐ state 的过期方式
⭐ 左右两条流的数据的 state 中的存储方式
⭐ 左右两条流数据在关联不到对方的情况下是否要输出到下游、输出什么样的数据到下游的方式
优化方案的适用场景
该种解决方案适用于可以做 state 清理的场景,比如在曝光关联点击的情况下,如果我们能明确一次曝光只有一次点击的话,只要这条曝光或者点击被关联到过,那么我们就可以在 KeyedCoProcessFunction 中自定义逻辑将已经被关联过得曝光、点击的 state 数据进行删除,以减小 state,减轻任务压力。
regular join的基础上window join
一般都要用窗口,不然无界流压力太大
接下来介绍最常用的三种窗口及API


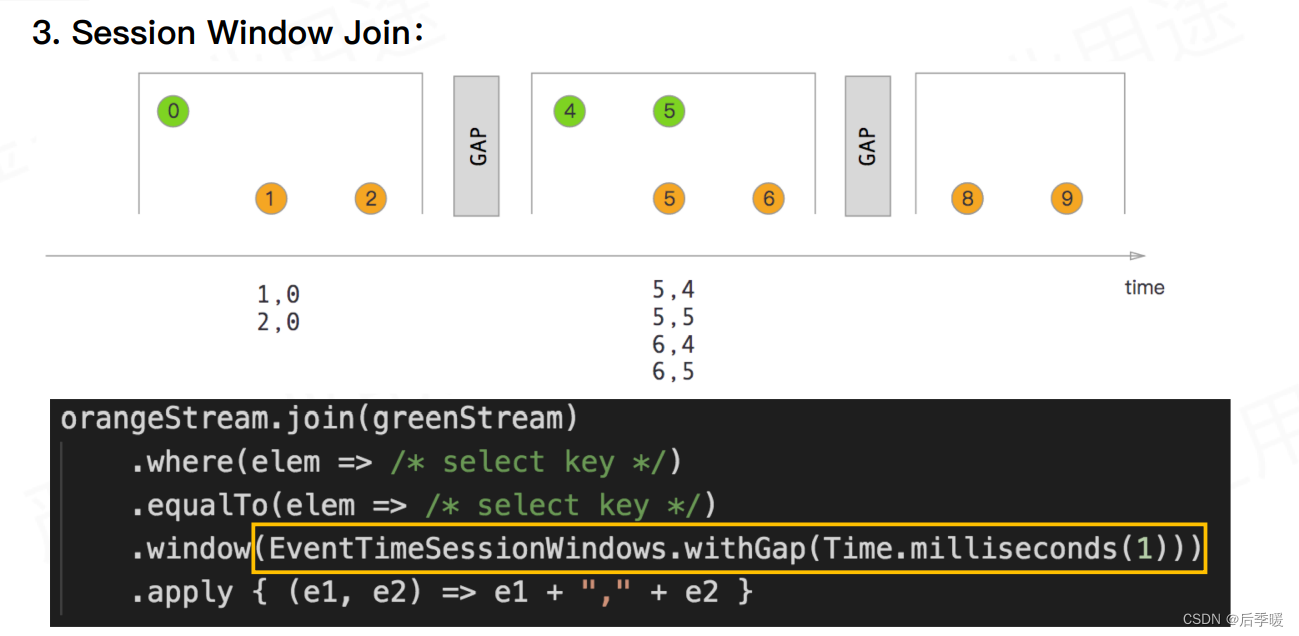
DataStram API
DataStream<Tuple2<String, Integer>> stream1 = ...; // 第一个数据流
DataStream<Tuple2<String, Integer>> stream2 = ...; // 第二个数据流// 执行窗口 left outer join 操作
DataStream<Tuple3<String, Integer, Integer>> resultStream = stream1.leftOuterJoin(stream2).where(<keySelector1>).equalTo(<keySelector2>).window(TumblingEventTimeWindows.of(Time.seconds(10))).apply(new JoinFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, Tuple3<String, Integer, Integer>>() {@Overridepublic Tuple3<String, Integer, Integer> join(Tuple2<String, Integer> first, Tuple2<String, Integer> second) {// 执行 left outer join 操作,并返回结果}});SQL API
SELECT L.num as L_Num, L.id as L_Id, R.num as R_Num, R.id as R_Id, L.window_start, L.window_end
FROM (SELECT * FROM TABLE(TUMBLE(TABLE LeftTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) L
FULL JOIN (SELECT * FROM TABLE(TUMBLE(TABLE RightTable, DESCRIPTOR(row_time), INTERVAL '5' MINUTES))
) R
ON L.num = R.num
AND L.window_start = R.window_start
AND L.window_end = R.window_end;
当我们的窗口大小划分的越细时,在窗口边缘关联不上的数据就会越多,数据质量就越差。窗口大小划分的越宽时,窗口内关联上的数据就会越多,数据质量越好,但是产出时效性就会越差。所以在使用时要注意取舍。
举个例子:以曝光关联点击来说,如果我们划分的时间窗口为 1 分钟,那么一旦出现曝光在 0:59,点击在 1:01 的情况,就会关联不上,当我们的划分的时间窗口 1 小时时,只有在每个小时的边界处的数据才会出现关联不上的情况。
window join源码
window join中,两条流数据按照关联主键在(滚动、滑动、会话)窗口内进行inner join, 底层基于State存储,并支持处理时间和事件时间两种时间特征,看下源码:
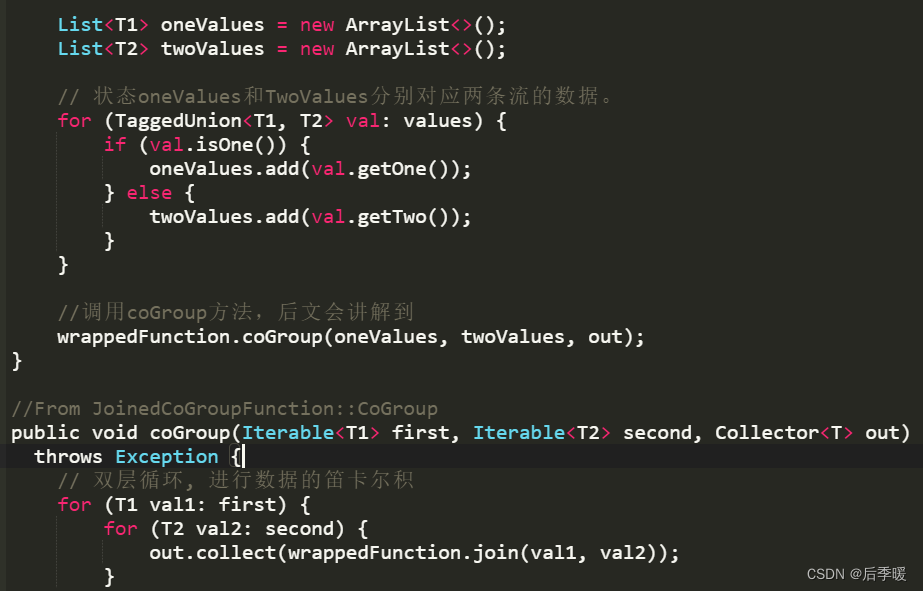
源码核心总结:windows窗口 + state存储 + 双层for循环执行join()
解决方案的适用场景
该种解决方案适用于可以评估出窗口内的关联率高的场景,如果窗口内关联率不高则不建议使用。
注意:这种方案由于上面说到的数据质量和时效性问题在实际生产环境中很少使用。
join、coGroup、connect区别及应用场景:
1. join算子:
- 行为: join算子用于在两个数据流之间执行内连接操作。它将两个流中的元素按照指定的条件进行连接,只有当两个流中的元素满足连接条件时,才会生成连接后的结果。
- 适用场景: 适用于两个流中的元素具有相同的键,并且只关心两个流中键匹配的元素。例如,连接两个订单数据流,只保留匹配的订单信息。
2. coGroup算子:
- 行为: coGroup算子用于在两个数据流之间执行分组连接操作。它会将两个流中具有相同键的元素放置在同一个分组中,并允许对每个分组执行自定义的连接操作。
- 适用场景: 适用于需要根据相同键将两个流中的元素分组,并且允许在分组内执行自定义连接逻辑的场景。例如,将两个数据流中具有相同键的元素分组,然后计算每个分组的平均值或其他聚合操作。
3. connect算子:
- 行为: connect算子用于连接两个不同类型的数据流。它可以将不同类型的数据流连接在一起,而不需要它们有相同的键。
- 适用场景: 适用于需要连接不同类型的数据流,并且需要在连接后的数据流上执行转换或其他处理的场景。例如,连接一个包含用户信息的流和一个包含产品信息的流,并在连接后的流上执行数据转换或其他业务逻辑。
当我们有两个数据流,一个代表用户点击事件,另一个代表广告展示事件时,我们可以使用 coGroup 和 join 算子来处理这两个数据流,从而得到点击事件和对应的广告展示事件。这里举一个简单的示例来说明两者的差距。
假设我们有以下两个数据流:
用户点击事件流(DataStream<UserClick>):
public class UserClick {public String userId;public String pageId;// constructor, getters, setters
}
广告展示事件流(DataStream<AdDisplay>):
public class AdDisplay {public String pageId;public String adId;// constructor, getters, setters
}
使用 join 算子:
DataStream<Tuple2<String, String>> resultStream = userClickStream.join(adDisplayStream).where((UserClick click) -> click.pageId).equalTo((AdDisplay adDisplay) -> adDisplay.pageId).window(TumblingEventTimeWindows.of(Time.seconds(10))).apply(new JoinFunction<UserClick, AdDisplay, Tuple2<String, String>>() {@Overridepublic Tuple2<String, String> join(UserClick click, AdDisplay adDisplay) {return new Tuple2<>(click.userId, adDisplay.adId);}});
在这个示例中,我们使用 join 算子连接了用户点击事件流和广告展示事件流,然后根据页面 ID 进行连接。只有当用户点击事件和广告展示事件中的页面 ID 相同时,才会进行连接操作。
使用 coGroup 算子:
DataStream<Tuple2<String, String>> resultStream = userClickStream.coGroup(adDisplayStream).where((UserClick click) -> click.pageId).equalTo((AdDisplay adDisplay) -> adDisplay.pageId).window(TumblingEventTimeWindows.of(Time.seconds(10))).apply(new CoGroupFunction<UserClick, AdDisplay, Tuple2<String, String>>() {@Overridepublic void coGroup(Iterable<UserClick> clicks, Iterable<AdDisplay> adDisplays, Collector<Tuple2<String, String>> out) {for (UserClick click : clicks) {for (AdDisplay adDisplay : adDisplays) {out.collect(new Tuple2<>(click.userId, adDisplay.adId));}}}});
在这个示例中,我们使用 coGroup 算子对用户点击事件流和广告展示事件流进行分组连接。无论是否有相同页面 ID 的事件,coGroup 都会将具有相同页面 ID 的事件分别放置在同一个分组中,然后执行自定义的连接操作。
通过这两个示例,可以看出 join 算子只连接两个流中满足连接条件的元素,而 coGroup 算子允许对具有相同键的元素进行自定义的连接操作,并且可以处理不匹配键的情况。
connect 是 Flink 中用于连接两个不同类型的数据流的方法。与 join 和 coGroup 不同,connect 可以连接不同类型的流,而不需要它们有相同的键。这使得 connect 更加灵活,可以用于连接不同类型的流,甚至可以连接不同类型的数据源。
connect 方法返回一个 ConnectedStreams 对象,该对象代表两个连接的数据流。然后,你可以通过调用 ConnectedStreams 对象上的 map、flatMap、filter 等方法对连接的数据流进行转换和处理。
下面是一个简单的示例,展示了如何在Flink 中使用 connect 连接两个数据流:
使用 connect 算子:
DataStream<String> stream1 = ...; // 第一个数据流
DataStream<Integer> stream2 = ...; // 第二个数据流// 连接两个数据流
ConnectedStreams<String, Integer> connectedStreams = stream1.connect(stream2);// 对连接的数据流进行转换和处理
DataStream<String> resultStream = connectedStreams.map(new CoMapFunction<String, Integer, String>() {@Overridepublic String map1(String value) throws Exception {// 对第一个流的元素进行处理,并返回结果return "Stream1: " + value;}@Overridepublic String map2(Integer value) throws Exception {// 对第二个流的元素进行处理,并返回结果return "Stream2: " + value.toString();}});
在这个示例中,我们使用 connect 方法连接了两个不同类型的数据流 stream1 和 stream2,然后使用 map 方法对连接的数据流进行了转换,分别处理了两个流的元素。
综上所述,这三个算子的主要区别在于它们的行为和适用场景。join算子适用于内连接操作,coGroup算子适用于分组连接操作,而connect算子适用于连接不同类型的数据流。具体选择哪个算子取决于你的业务需求和连接逻辑。
双流JOIN的优化与总结
- 为什么我的双流join时间到了却不触发,一直没有输出
检查一下watermark的设置是否合理,数据时间是否远远大于watermark和窗口时间,导致窗口数据经常为空
- state数据保存多久,会内存爆炸吗
state自带有ttl机制,可以设置ttl过期策略,触发Flink清理过期state数据。建议程序中的state数据结构用完后手动clear掉。
- 我的双流join倾斜怎么办
join倾斜三板斧: 过滤异常key、拆分表减少数据、打散key分布。当然可以的话我建议加内存!加内存!加内存!!
- 想实现多流join怎么办
目前无法一次实现,可以考虑先union然后再二次处理;或者先进行connnect操作再进行join操作,仅建议~
- join过程延迟、没关联上的数据会丢失吗
这个一般来说不会,join过程可以使用侧输出流存储延迟流;如果出现节点网络等异常,Flink checkpoint也可以保证数据不丢失。
2. Interval Joins
返回一个符合 join 条件和时间限制的简单笛卡尔积。Interval join 需要至少一个 equi-join 条件和一个 join 两边都包含的时间限定 join 条件。范围判断可以定义成就像一个条件(<, <=, >=, >),也可以是一个 BETWEEN 条件,或者两边表的一个相同类型(即:处理时间 或 事件时间)的时间属性 的等式判断。
-
Interval Join 又叫做区间Join
-
Interval Join 其也是将两条流的数据从无界数据变为有界数据,但是这里的有界和上节说到的 Flink Window Join 的有界的概念是不一样的,这里的有界是指两条流之间的有界
以 A 流 join B 流举例,interval join 可以让 A 流可以关联 B 流一段时间区间内的数据,比如 A 流关联 B 流前后 5 分钟的数据:
Interval Join特点
- 限定Join的窗口时间,对超出时间范围的数据进行清理,避免保留全量State
- 仅支持 event time
例如:如果订单是在被接收到4小时后发货,这个查询会把所有订单和它们相应的 shipments join 起来。
SELECT *
FROM Orders o, Shipments s
WHERE o.id = s.order_id
AND o.order_time BETWEEN s.ship_time - INTERVAL '4' HOUR AND s.ship_time
下面列举了一些有效的 interval join 时间条件:
ltime = rtimeltime >= rtime AND ltime < rtime + INTERVAL '10' MINUTEltime BETWEEN rtime - INTERVAL '10' SECOND AND rtime + INTERVAL '5' SECOND
对于流式查询,对比 regular join,interval join 只支持有时间属性的非更新表。 由于时间属性是递增的,Flink 从状态中移除旧值也不会影响结果的正确性。
那么该方案怎么解决regular join中说的两个问题呢?
流式数据到达计算引擎的时间不一定:数据已经被划分为窗口,无界数据变为有界数据,就和离线批处理的方式一样了,两个窗口的数据简单的进行关联即可
流式数据不知何时、下发怎样的数据:窗口结束(这里的窗口结束是指 interval 区间结束,区间的结束是利用 watermark 来判断的)就把数据下发下去,关联到的数据就下发 [A, B],没有关联到的数据取决于是否是 outer join 然后进行数据下发。
DataSteam API:
package No12_Join.DoubleStreamJoin;import No12_Join.Bean.JoinBean;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;/*** 只支持eventTime 和 keyedStream*/
public class NonWindowJoin01_IntervalJoin {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//todo 1.准备两个流DataStreamSource<String> DS1 = env.socketTextStream("hadoop102", 9999);SingleOutputStreamOperator<JoinBean> joinBeanDS1 = DS1.map(new MapFunction<String, JoinBean>() {@Overridepublic JoinBean map(String s) throws Exception {String[] fields = s.split(",");return new JoinBean(fields[0], fields[1], Long.parseLong(fields[2]));}}).assignTimestampsAndWatermarks(WatermarkStrategy.<JoinBean>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<JoinBean>() {@Overridepublic long extractTimestamp(JoinBean joinBean, long l) {return joinBean.getTs() * 1000;}}));DataStreamSource<String> DS2 = env.socketTextStream("hadoop102", 8888);SingleOutputStreamOperator<JoinBean> joinBeanDS2 = DS2.map(new MapFunction<String, JoinBean>() {@Overridepublic JoinBean map(String s) throws Exception {String[] fields = s.split(",");return new JoinBean(fields[0], fields[1], Long.parseLong(fields[2]));}}).assignTimestampsAndWatermarks(WatermarkStrategy.<JoinBean>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<JoinBean>() {@Overridepublic long extractTimestamp(JoinBean joinBean, long l) {return joinBean.getTs() * 1000;}}));//todo 双流joinSingleOutputStreamOperator<Tuple2<JoinBean, JoinBean>> joinDS = joinBeanDS1.keyBy(x -> x.getName()).intervalJoin(joinBeanDS1.keyBy(x -> x.getName())).between(Time.seconds(-5), Time.seconds(5))//ds2等ds1 ds1等ds2//.lowerBoundExclusive()//.upperBoundExclusive().process(new ProcessJoinFunction<JoinBean, JoinBean, Tuple2<JoinBean, JoinBean>>() {@Overridepublic void processElement(JoinBean joinBean, JoinBean joinBean2, ProcessJoinFunction<JoinBean, JoinBean, Tuple2<JoinBean, JoinBean>>.Context context, Collector<Tuple2<JoinBean, JoinBean>> collector) throws Exception {collector.collect(new Tuple2<>(joinBean, joinBean2));}});joinDS.print();env.execute();//8888 9999//1001 1// 1001 1 =>输出 1001 1 , 1001 1// 1001 2 =>输出 1001 1 , 1001 2//1002 10// 1001 3 =>输出 1001 1 , 1001 3// 1002 10 =>输出 1002 10, 1000 10// 1001 3 =>不输出 因为watermark已经到10了}
}Connect算子实现:
package No12_Join.DoubleStreamJoin;import No07_案例.Bean.OrderEvent;
import No07_案例.Bean.TxEvent;
import No07_案例.demo01._13_支付到账_keyBy后connect;
import No12_Join.Bean.JoinBean;
import org.apache.flink.api.common.functions.CoGroupFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.streaming.api.functions.co.KeyedCoProcessFunction;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;import java.util.Iterator;/*** coGroup 算子* 可以实现 inner join 、 outer join*/
public class NonWindowJoin02_Connect {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<String> order = env.readTextFile("D:\\IdeaProjects\\bigdata\\flink\\src\\main\\resources\\Data\\OrderLog.csv");DataStreamSource<String> receipt = env.readTextFile("D:\\IdeaProjects\\bigdata\\flink\\src\\main\\resources\\Data\\ReceiptLog.csv");//todo 1.两个流转成JavaBean 提取时间戳SingleOutputStreamOperator<OrderEvent> orderEventDS = order.flatMap(new FlatMapFunction<String, OrderEvent>() {@Overridepublic void flatMap(String s, Collector<OrderEvent> collector) throws Exception {String[] fields = s.split(",");OrderEvent orderEvent = new OrderEvent(Long.parseLong(fields[0]),fields[1],fields[2],Long.parseLong(fields[3]));if ("pay".equals(orderEvent.getEventType())) {collector.collect(orderEvent);}}}).assignTimestampsAndWatermarks(new AscendingTimestampExtractor<OrderEvent>() {@Overridepublic long extractAscendingTimestamp(OrderEvent orderEvent) {return orderEvent.getEventTime() * 1000;}});SingleOutputStreamOperator<TxEvent> txDS = receipt.map(new MapFunction<String, TxEvent>() {@Overridepublic TxEvent map(String s) throws Exception {String[] fields = s.split(",");return new TxEvent(fields[0], fields[1], Long.parseLong(fields[2]));}}).assignTimestampsAndWatermarks(new AscendingTimestampExtractor<TxEvent>() {@Overridepublic long extractAscendingTimestamp(TxEvent txEvent) {return txEvent.getEventTime() * 1000;}});KeyedStream<OrderEvent, String> orderEventKeyedDS = orderEventDS.keyBy(new KeySelector<OrderEvent, String>() {@Overridepublic String getKey(OrderEvent orderEvent) throws Exception {return orderEvent.getTxId();}});KeyedStream<TxEvent, String> txEventKeyedStream = txDS.keyBy(new KeySelector<TxEvent, String>() {@Overridepublic String getKey(TxEvent txEvent) throws Exception {return txEvent.getTxID();}});//todo 3.连接两个流 connect 实现SingleOutputStreamOperator<Tuple2<OrderEvent, TxEvent>> result = orderEventKeyedDS.connect(txEventKeyedStream).process(new _13_支付到账_keyBy后connect.OrderReceiptKeyProFunc());result.print();result.getSideOutput(new OutputTag<String>("支付数据没到"){}).print();result.getSideOutput(new OutputTag<String>("支付了 没到账"){}).print();env.execute();}private static class OrderReceiptKeyProFunc extends KeyedCoProcessFunction<String,OrderEvent,TxEvent,Tuple2<OrderEvent,TxEvent>> {ValueState<OrderEvent> orderValue;ValueState<TxEvent> TxValue;// 只要涉及删除定时器的都需要保存定时器时间ValueState<Long> ts;@Overridepublic void open(Configuration parameters) throws Exception {orderValue = getRuntimeContext().getState(new ValueStateDescriptor<OrderEvent>("orderState",OrderEvent.class));TxValue = getRuntimeContext().getState(new ValueStateDescriptor<TxEvent>("TxState",TxEvent.class));ts = getRuntimeContext().getState(new ValueStateDescriptor<Long>("timestamp",long.class));}//todo 处理订单数据@Overridepublic void processElement1(OrderEvent orderEvent, KeyedCoProcessFunction<String, OrderEvent, TxEvent, Tuple2<OrderEvent, TxEvent>>.Context context, Collector<Tuple2<OrderEvent, TxEvent>> collector) throws Exception {TxEvent Tx = TxValue.value();// 到账数据还没到,保存状态 注册定时器 10sif (Tx == null) {orderValue.update(orderEvent);long timestamp = (orderEvent.getEventTime() + 10) * 1000;context.timerService().registerEventTimeTimer(timestamp);ts.update(timestamp);} else {// 到账数据已经到// 1.输出collector.collect(new Tuple2<>(orderEvent, Tx));// 2.删除定时器context.timerService().deleteEventTimeTimer(ts.value());// 3.清空状态TxValue.clear();ts.clear();}}// todo 处理到账数据@Overridepublic void processElement2(TxEvent txEvent, KeyedCoProcessFunction<String, OrderEvent, TxEvent, Tuple2<OrderEvent, TxEvent>>.Context context, Collector<Tuple2<OrderEvent, TxEvent>> collector) throws Exception {OrderEvent order = orderValue.value();//下单数据没到if (order == null) {TxValue.update(txEvent);long time = (txEvent.getEventTime() + 5) * 1000;context.timerService().registerEventTimeTimer(time);ts.update(time);} else {collector.collect(new Tuple2<>(order, txEvent));// 2.删除定时器context.timerService().deleteEventTimeTimer(ts.value());// 3.清空状态orderValue.clear();ts.clear();}}@Overridepublic void onTimer(long timestamp, OnTimerContext ctx, Collector<Tuple2<OrderEvent, TxEvent>> out) throws Exception {OrderEvent order = orderValue.value();TxEvent tx = TxValue.value();//支付的数据超时了if (order == null) {ctx.output(new OutputTag<String>("支付数据没到") {},tx.getTxID() + "收到钱了 但是没收到支付数据");} else {ctx.output(new OutputTag<String>("支付了 没到账") {},order.getTxId() + "支付了 但没到账");}}}
}SQL API
select
*
from Orders o,Shipments s
where o.id = s.id
and s.shiptime between o.ordertime
and o.ordertime + INTERVAL '4' HOUR
interval join 的方案比 window join 方案在数据质量上好很多,但是其也是存在 join 不到的情况的。并且如果为 outer join 的话,outer 一测的流数据需要要等到区间结束才能下发。
2.5 解决方案的适用场景
该种解决方案适用于两条流之间可以明确评估出相互延迟的时间是多久的,这里我们可以使用离线数据进行评估,使用离线数据的两条流的时间戳做差得到一个分布区间。
比如在 A 流和 B 流时间戳相差在 1min 之内的有 95%,在 1-4 min 之内的有 4.5%,则我们就可以认为两条流数据时间相差在 4 min 之内的有 99.5%,这时我们将上下界设置为 4min 就是一个能保障 0.5% 误差的合理区间。
注意:这种方案在生产环境中还是比较常用的。
3. Temporal Joins
时态表(Temporal table)是一个随时间变化的表:在 Flink 中被称为动态表。时态表中的行与一个或多个时间段相关联,所有 Flink 中的表都是时态的(Temporal)。 时态表包含一个或多个版本的表快照,它可以是一个变化的历史表,跟踪变化(例如,数据库变化日志,包含所有快照)或一个变化的维度表,也可以是一个将变更物化的维表(例如,存放最终快照的数据表)。
事件时间 Temporal Join #
基于事件时间的 Temporal join 允许对版本表进行 join。 这意味着一个表可以使用变化的元数据来丰富,并在某个时间点检索其具体值。
Temporal Joins 使用任意表(左侧输入/探测端)的每一行与版本表中对应的行进行关联(右侧输入/构建端)。 Flink 使用 SQL:2011标准 中的 FOR SYSTEM_TIME AS OF 语法去执行操作。 Temporal join 的语法如下:
SELECT [column_list]
FROM table1 [AS <alias1>]
[LEFT] JOIN table2 FOR SYSTEM_TIME AS OF table1.{ proctime | rowtime } [AS <alias2>]
ON table1.column-name1 = table2.column-name1
有了事件时间属性(即:rowtime 属性),就能检索到过去某个时间点的值。 这允许在一个共同的时间点上连接这两个表。 版本表将存储自最后一个 watermark 以来的所有版本(按时间标识)。
例如,假设我们有一个订单表,每个订单都有不同货币的价格。 为了正确地将该表统一为单一货币(如美元),每个订单都需要与下单时相应的汇率相关联。
-- Create a table of orders. This is a standard
-- append-only dynamic table.
CREATE TABLE orders (order_id STRING,price DECIMAL(32,2),currency STRING,order_time TIMESTAMP(3),WATERMARK FOR order_time AS order_time - INTERVAL '15' SECOND
) WITH (/* ... */);-- Define a versioned table of currency rates.
-- This could be from a change-data-capture
-- such as Debezium, a compacted Kafka topic, or any other
-- way of defining a versioned table.
CREATE TABLE currency_rates (currency STRING,conversion_rate DECIMAL(32, 2),update_time TIMESTAMP(3) METADATA FROM `values.source.timestamp` VIRTUAL,WATERMARK FOR update_time AS update_time - INTERVAL '15' SECOND,PRIMARY KEY(currency) NOT ENFORCED
) WITH ('connector' = 'kafka','value.format' = 'debezium-json',/* ... */
);SELECT order_id,price,orders.currency,conversion_rate,order_time
FROM orders
LEFT JOIN currency_rates FOR SYSTEM_TIME AS OF orders.order_time
ON orders.currency = currency_rates.currency;order_id price currency conversion_rate order_time
======== ===== ======== =============== =========
o_001 11.11 EUR 1.14 12:00:00
o_002 12.51 EUR 1.10 12:06:00
注意: 事件时间 temporal join 是通过左和右两侧的 watermark 触发的; 这里的 INTERVAL 时间减法用于等待后续事件,以确保 join 满足预期。 请确保 join 两边设置了正确的 watermark 。
注意: 事件时间 temporal join 需要包含主键相等的条件,即:currency_rates 表的主键 currency_rates.currency 包含在条件 orders.currency = currency_rates.currency 中。
与 regular joins 相比,就算 build side(例子中的 currency_rates 表)发生变更了,之前的 temporal table 的结果也不会被影响。 与 interval joins 对比,temporal join没有定义join的时间窗口。 Probe side (例子中的 orders 表)的记录总是在 time 属性指定的时间与 build side 的版本行进行连接。因此,build side 表的行可能已经过时了。 随着时间的推移,不再被需要的记录版本(对于给定的主键)将从状态中删除。
处理时间 Temporal Join #
基于处理时间的 temporal join 使用处理时间属性将数据与外部版本表(例如 mysql、hbase)的最新版本相关联。
通过定义一个处理时间属性,这个 join 总是返回最新的值。可以将 build side 中被查找的表想象成一个存储所有记录简单的 HashMap<K,V>。 这种 join 的强大之处在于,当无法在 Flink 中将表具体化为动态表时,它允许 Flink 直接针对外部系统工作。
下面这个处理时间 temporal join 示例展示了一个追加表 orders 与 LatestRates 表进行 join。 LatestRates 是一个最新汇率的维表,比如 HBase 表,在 10:15,10:30,10:52这些时间,LatestRates 表的数据看起来是这样的:
10:15> SELECT * FROM LatestRates;currency rate
======== ======
US Dollar 102
Euro 114
Yen 110:30> SELECT * FROM LatestRates;currency rate
======== ======
US Dollar 102
Euro 114
Yen 110:52> SELECT * FROM LatestRates;currency rate
======== ======
US Dollar 102
Euro 116 <==== changed from 114 to 116
Yen 1
LastestRates 表的数据在 10:15 和 10:30 是相同的。 欧元(Euro)的汇率(rate)在 10:52 从 114 变更为 116。
Orders 表示支付金额的 amount 和currency的追加表。 例如:在 10:15 ,有一个金额为 2 Euro 的 order。
SELECT * FROM Orders;amount currency
====== =========2 Euro <== arrived at time 10:151 US Dollar <== arrived at time 10:302 Euro <== arrived at time 10:52
给出下面这些表,我们希望所有 Orders 表的记录转换为一个统一的货币。
amount currency rate amount*rate
====== ========= ======= ============2 Euro 114 228 <== arrived at time 10:151 US Dollar 102 102 <== arrived at time 10:302 Euro 116 232 <== arrived at time 10:52
目前,temporal join 还不支持与任意 view/table 的最新版本 join 时使用 FOR SYSTEM_TIME AS OF 语法。可以像下面这样使用 temporal table function 语法来实现(时态表函数):
SELECTo_amount, r_rate
FROMOrders,LATERAL TABLE (Rates(o_proctime))
WHEREr_currency = o_currency
注意 Temporal join 不支持与 table/view 的最新版本进行 join 时使用 FOR SYSTEM_TIME AS OF 语法是出于语义考虑,因为左流的连接处理不会等待 temporal table 的完整快照,这可能会误导生产环境中的用户。处理时间 temporal join 使用 temporal table function 也存在相同的语义问题,但它已经存在了很长时间,因此我们从兼容性的角度支持它。
processing-time 的结果是不确定的。 processing-time temporal join 常常用在使用外部系统来丰富流的数据。(例如维表)
与 regular joins 的差异,就算 build side(例子中的 currency_rates 表)发生变更了,之前的 temporal table 结果也不会被影响。 与 interval joins 的差异,temporal join 没有定义数据连接的时间窗口。即:旧数据没存储在状态中。
Temporal Table Function Join #
使用 temporal table function 去 join 表的语法和 Table Function 相同。
注意:目前只支持 inner join 和 left outer join。
假设Rates是一个 temporal table function,这个 join 在 SQL 中可以被表达为:
SELECTo_amount, r_rate
FROMOrders,LATERAL TABLE (Rates(o_proctime))
WHEREr_currency = o_currency
上述 temporal table DDL 和 temporal table function 的主要区别在于:
- SQL 中可以定义 temporal table DDL,但不能定义 temporal table 函数;
- temporal table DDL 和 temporal table function 都支持 temporal join 版本表,但只有 temporal table function 可以 temporal join 任何表/视图的最新版本(即"处理时间 Temporal Join")。
4. Lookup Join
lookup join 通常用于使用从外部系统查询的数据来丰富表。join 要求一个表具有处理时间属性,另一个表由查找源连接器(lookup source connnector)支持。
lookup join 和上面的 处理时间 Temporal Join 语法相同,右表使用查找源连接器支持。
下面的例子展示了 lookup join 的语法。
-- Customers is backed by the JDBC connector and can be used for lookup joins
CREATE TEMPORARY TABLE Customers (id INT,name STRING,country STRING,zip STRING
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://mysqlhost:3306/customerdb','table-name' = 'customers'
);-- enrich each order with customer information
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS oJOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS cON o.customer_id = c.id;
在上面的示例中,Orders 表由保存在 MySQL 数据库中的 Customers 表数据来丰富。带有后续 process time 属性的 FOR SYSTEM_TIME AS OF 子句确保在联接运算符处理 Orders 行时,Orders 的每一行都与 join 条件匹配的 Customer 行连接。它还防止连接的 Customer 表在未来发生更新时变更连接结果。lookup join 还需要一个强制的相等连接条件,在上面的示例中是 o.customer_id = c.id。
数组展开 #
返回给定数组中每个元素的新行。尚不支持 WITH ORDINALITY(会额外生成一个标识顺序的整数列)展开。
SELECT order_id, tag
FROM Orders CROSS JOIN UNNEST(tags) AS t (tag)
Table Function #
将表与表函数的结果联接。左侧(外部)表的每一行都与表函数的相应调用产生的所有行相连接。用户自定义表函数 必须在使用前注册。
INNER JOIN #
如果表函数调用返回一个空结果,那么左表的这行数据将不会输出。
SELECT order_id, res
FROM Orders,
LATERAL TABLE(table_func(order_id)) t(res)
LEFT OUTER JOIN #
如果表函数调用返回了一个空结果,则保留相应的行,并用空值填充未关联到的结果。当前,针对 lateral table 的 left outer join 需要 ON 子句中有一个固定的 TRUE 连接条件。
SELECT order_id, res
FROM Orders
LEFT OUTER JOIN LATERAL TABLE(table_func(order_id)) t(res)ON TRUE当然,维表关联还有别的方式,这里简单举例:







总结
常见的场景归类