Notations:
: model parameters at time step
or
: gradient at
: momentum accumulated from time step
to time step
, which is used to cpmpute
Optimization
What is Optimization about?
找到一组参数,使得
最小,或者说是找到一组参数
,使得
最小。
- On-line: one pair of
at a time step
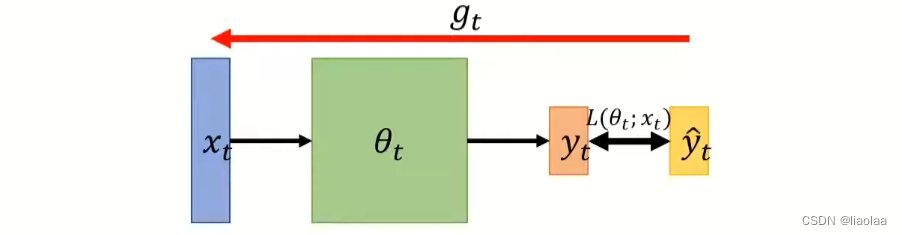
- Off-line: all pair of
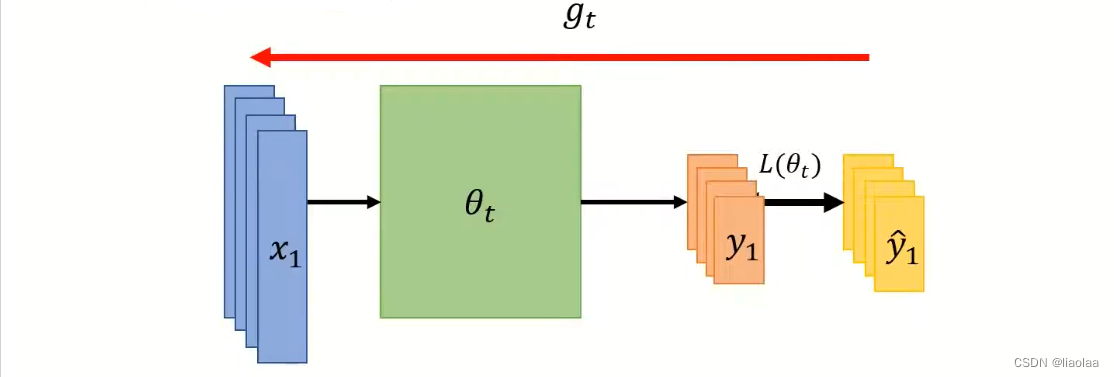
SGD
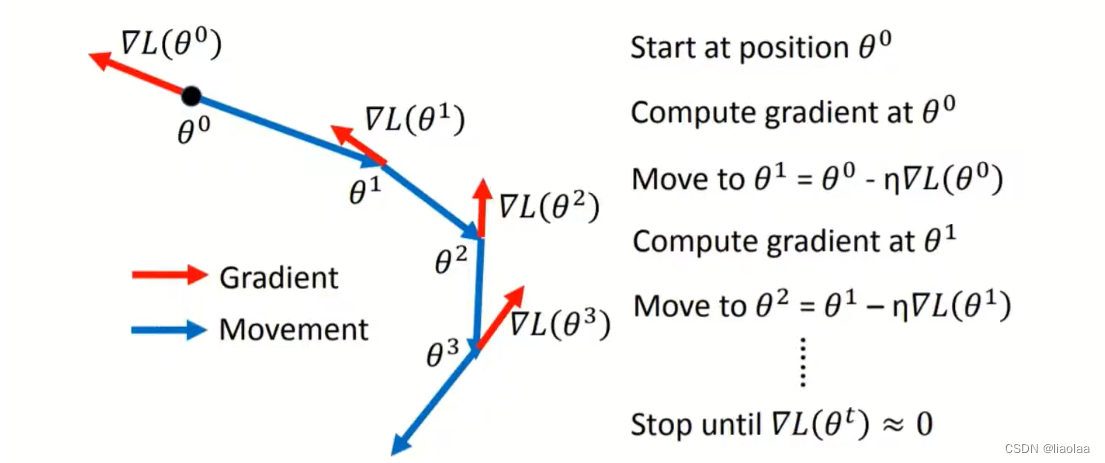
当SGD计算出Gradient非常接近于0的时候,更新会卡在这个点上,不能再继续更新,以及自适应Learning Rate问题。
SGD with Momentum(SGDM)
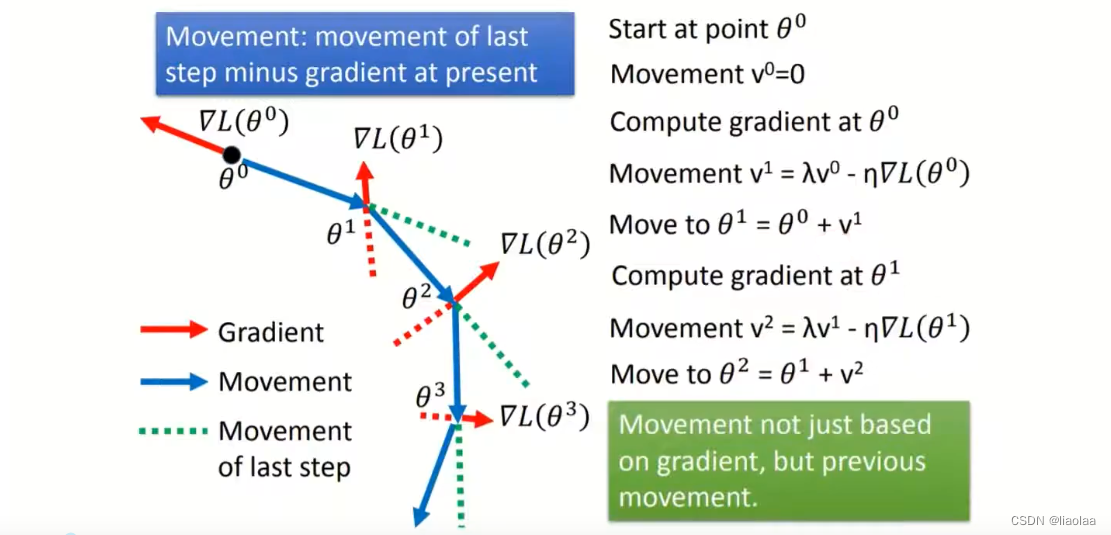
如果梯度计算出来非常接近于0的话,在SGD的情况下,不会再跟新卡在这个点上,但是SGDM,当前的Momentum会由上一次的Momentum和当前的Gradient决定,也就是说,当前的Gradient不仅会考虑到当前计算出的梯度本身还会考虑之前累积的Gradient。通过SGDM就算是在当前梯度很接近于0的点也不会卡住,因为之前的Momentum会像惯性一样不会马上停下来会带着它冲出这个点,但是仍然自适应Learning Rate问题。
Adagrad
考虑这样的情况,如果过去的Gradient都是很大的情况下,说明在这个区域的Error surface比较崎岖,就会有比较小的值,Movement会很小,走的步子慢一点。如果过去的Gradient都是很小的情况下,说明在这个区域的Error surface比较平缓,
就会有比较大的值,Movement会很大,走的步子大一点。
RMSProp
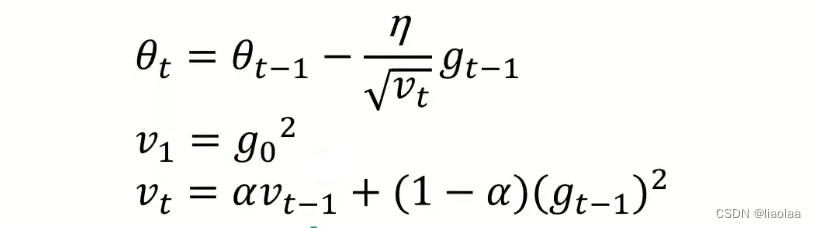
Adagrad有个问题,如果在一开始的Gradient太大的时候,Learning rate会很小,因为Gradient是从开始累积到当前时刻的,它可能没走几步就卡住。RMSProp加权和来缓解这个问题。
Adam
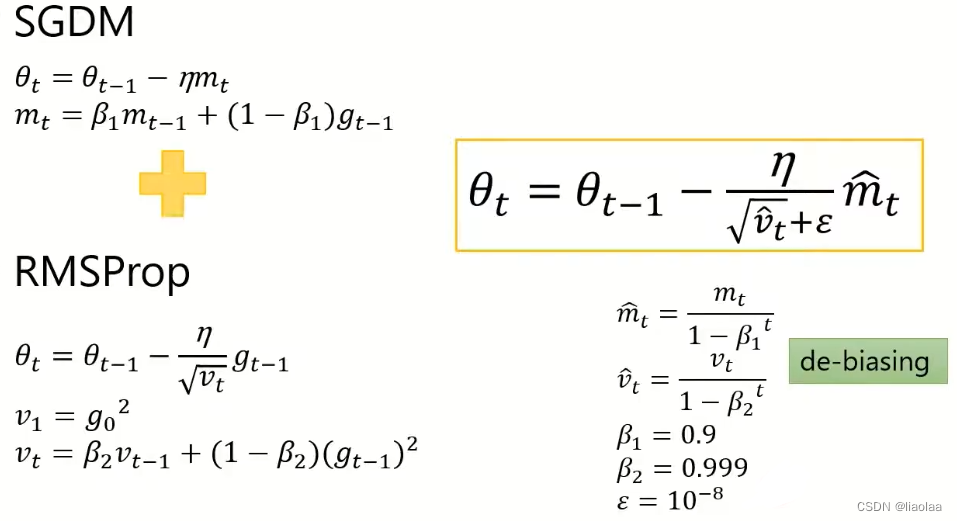
Adam是将SGDM和RMSProp做结合这样,刚开始所需动量比较大,后面模型基本稳定后,逐步减小对动量的依赖
Adam vs SGDM
- Adam: 训练速度更快,比较不稳定,泛化能力比较差,
- SGDM: 比较稳定,泛化能力比较好