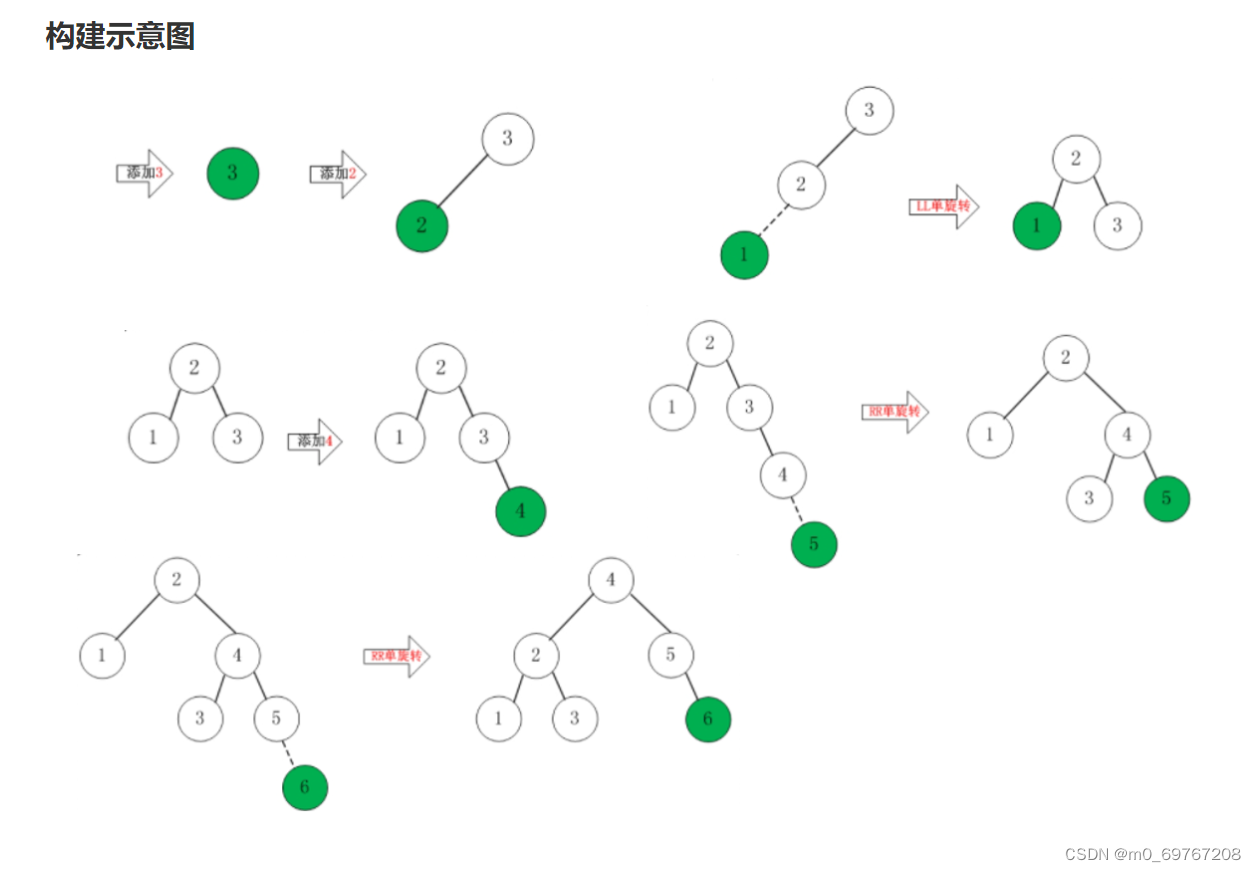
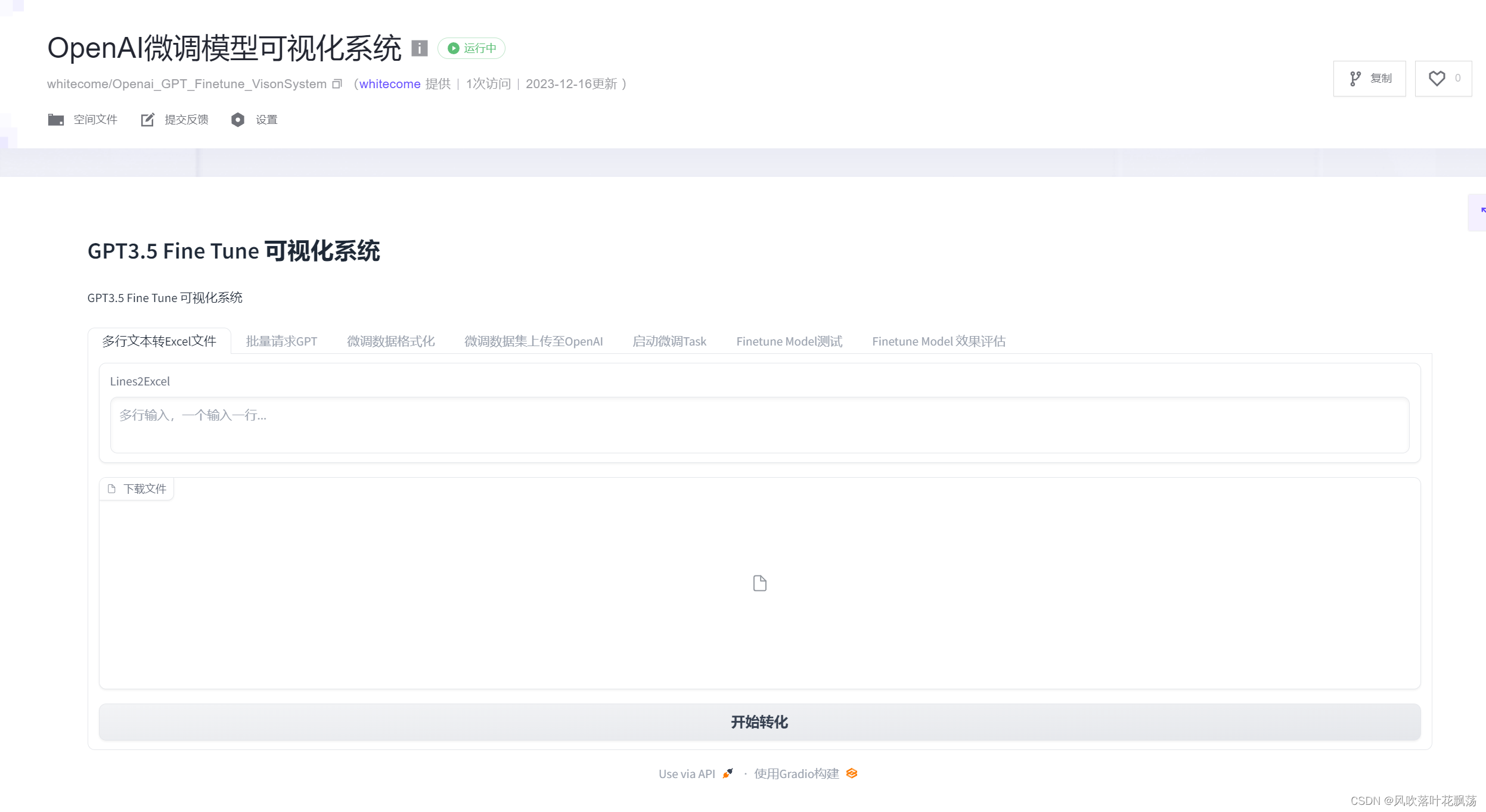
李云和李逵打了五七个回合,不分胜负,被朱富劝说也上了梁山。李云号人称青眼虎,朱富绰号庙笑面虎,宋江说李逵杀了四虎,梁山添了两个活虎,值得庆贺。
吴用对将领们进行了调配,朱富重掌山东酒店,又新开了三家酒馆,童威童猛兄弟在山西店,李立在山南店,石勇在山北店。令杜迁把守三大关,陶宗旺总监修路挖河。蒋敬管出纳;萧让管文书;金大坚管兵符印信。侯健管造衣袍铠甲,李云监造厅堂,马麟监管修造站船。令宋万白胜去金沙滩,王矮虎、郑天寿去鸭嘴滩。穆春朱富管山寨钱粮,吕方郭盛在聚义厅两边耳房安歇。宋清专管筵席筵宴。

梁山初具规模,大家分工合作。python里也专门用于xml解析和Base64编解码的模块。
Python XML解析和Base64编解码
Python解析XML文件本地文件版
XML(可扩展标记语言)是一种用于编码文档的标记语言,它被广泛用于数据的存储和传输。Python提供了多种库来帮助我们解析XML文件,其中最常见的是
xml.etree.ElementTree。在本说明文件中,我们将讨论如何使用
xml.etree.ElementTree库来解析XML文件,包括读取XML文件、遍历XML元素以及获取元素属性和文本内容等。一、读取XML文件
首先,我们需要导入
xml.etree.ElementTree模块,并使用parse()函数来读取XML文件。parse()函数返回一个Element对象,代表XML文档的根元素。首先写一个xml的例子文件,example.xml文件内容:
<?xml version="1.0" encoding="UTF-8"?> <bookstore> <book>book1<title lang="en">Harry Potter</title> <author>J. K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book>book2<title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore>解析XML代码:
import xml.etree.ElementTree as ET # 读取XML文件 tree = ET.parse('example.xml') # 获取根元素 root = tree.getroot()二、遍历XML元素
接下来,我们可以使用
iter()函数来遍历XML文档中的所有元素。iter()函数返回一个迭代器,它会产生XML文档中的所有元素。我们可以遍历这些元素并打印它们的标签名。# 遍历XML元素 for elem in root.iter(): print(elem.tag)如果我们只关心特定类型的元素,可以将标签名作为
iter()函数的参数。例如,如果我们只想遍历所有名为book的元素,可以这样做:# 遍历名为"book"的元素 for book in root.iter('book'): print(book.tag)
三、获取元素属性和文本内容
我们还可以通过元素的
attrib属性来获取元素的属性,以及使用text属性来获取元素的文本内容。# 遍历名为"book"的元素,并打印它们的title属性和text内容 for book in root.iter('book'): print(book.attrib['title']) print(book.text)注意,
text属性返回的是元素的直接文本内容。如果元素包含子元素,并且你希望获取这些子元素的文本内容,你需要递归地遍历这些子元素。四、总结
在本文中,我们介绍了如何使用
xml.etree.ElementTree库来解析XML文件。我们首先导入了xml.etree.ElementTree模块,并使用parse()函数来读取XML文件。然后,我们使用iter()函数来遍历XML文档中的所有元素,并打印它们的标签名。最后,我们展示了如何获取元素的属性和文本内容。希望这篇说明文件能帮助你更好地理解和使用Python的XML解析功能。如果你有任何疑问或需要进一步的帮助,请随时向我提问。
Python编码和解码Base64数据
Base64是一种用64个字符来表示任意二进制数据的方法。这64 个字符——大写字母 A-Z、小写字母 a-z、数字 0-9、符号 "+"、"/"(再加上作为垫字的 "=",实际上是 65 个字符,垫字是当生成的 Base64 字符串的个数不是 4 的倍数时,添加在尾部的字符),作为一个基本字符集。然后,其他所有符号都转换成这个字符集中的字符。它常用于在HTTP协议中编码数据,尤其是在电子邮件系统中。Python的内置模块
base64提供了编码和解码Base64数据的功能。在这篇说明文件中,我们将介绍如何使用Python的
base64模块来编码和解码Base64数据。一、编码Base64数据
要编码Base64数据,你可以使用
base64.b64encode()函数。这个函数接受一个字节串作为输入,并返回一个Base64编码的字节串。下面是一个简单的示例,演示如何将一个字符串编码为Base64:
import base64# 原始数据(需要是字节串) data = b"Hello, World!"# 编码为Base64 encoded_data = base64.b64encode(data)# 打印编码后的数据(通常是二进制,需要解码才能看到文本) print(encoded_data)# 如果需要查看文本形式的Base64编码,可以解码字节串 print(encoded_data.decode('utf-8'))输出将会是Base64编码的字符串:
b'SGVsbG8sIFdvcmxkIQ==' SGVsbG8sIFdvcmxkIQ==
二、解码Base64数据
要解码Base64数据,你可以使用
base64.b64decode()函数。这个函数接受一个Base64编码的字节串作为输入,并返回原始的字节串。下面是一个示例,演示如何将一个Base64编码的字符串解码为原始数据:
import base64 # Base64编码的数据(需要是字节串) encoded_data = b'SGVsbG8sIFdvcmxkIQ==' # 解码Base64 decoded_data = base64.b64decode(encoded_data) # 打印解码后的数据(通常是二进制,需要解码才能看到文本) print(decoded_data) # 如果需要查看文本形式的解码数据,可以解码字节串 print(decoded_data.decode('utf-8'))输出将会是解码后的原始数据:
b'Hello, World!' Hello, World!注意,
b64encode()和b64decode()函数都处理字节串,而不是字符串。如果你有一个字符串并且想要对其进行Base64编码或解码,你需要先将其转换为字节串(使用str.encode()方法),然后再将结果转换回字符串(如果需要的话,使用bytes.decode()方法)。这就是Python中编码和解码Base64数据的基本方法。 文档由文心一言辅助生成。
一天宋江提到公孙胜还没回来,请戴宗去打探他的下落。戴宗在沂水县附近,碰到一个人喊他“神行太保”,原来那人锦豹子杨林,数月之前见过公孙胜,并被引荐上梁山。
戴宗和杨林一起去找公孙胜,在饮马川见到了火眼羧猊邓飞、玉幡竿孟康和铁面孔目裴宣,三人也受邀入伙梁山。
戴宗杨林到了蓟州城,见到杨雄被张保欺负,石秀暴打不平,结识了拼命三郎石秀。石秀结识了病关索杨雄,两人结拜为兄弟。
欲知后事如何,且听下回分解。