第七章:文件操作
为了长期保存数据以便重复使用、修改和共享,必须将数据以文件的形式存储到外部存储介质(如磁盘、U盘、光盘或云盘、网盘、快盘等)中。
文件操作在各类应用软件的开发中均占有重要的地位:
- 管理信息系统是使用数据库来存储数据的,而数据库最终还是要以文件的形式存储到硬盘或其他存储介质上。
- 应用程序的配置信息往往也是使用文件来存储的,图形、图像、音频、视频、可执行文件等等也都是以文件的形式存储在磁盘上的。
按文件中数据的组织形式把文件分为文本文件和二进制文件两类。
- 文本文件:文本文件存储的是常规字符串,由若干文本行组成,通常每行以换行符'\n'结尾。常规字符串是指记事本或其他文本编辑器能正常显示、编辑并且人类能够直接阅读和理解的字符串,如英文字母、汉字、数字字符串。文本文件可以使用字处理软件如gedit、记事本进行编辑。
- 二进制文件:二进制文件把对象内容以字节串(bytes)进行存储,无法用记事本或其他普通字处理软件直接进行编辑,通常也无法被人类直接阅读和理解,需要使用专门的软件进行解码后读取、显示、修改或执行。常见的如图形图像文件、音视频文件、可执行文件、资源文件、各种数据库文件、各类office文档等都属于二进制文件。
7.1文件基本操作
■ 文件内容操作三部曲:打开、读写、关闭
open(file, mode='r', buffering =- 1, encoding=None(默认GBK), errors=None,newline=None, closefd=True, opener=None)
文件名指定了被打开的文件名称。
打开模式指定了打开文件后的处理方式。
缓冲区指定了读写文件的缓存模式。0表示不缓存,1表示缓存,如大于1则表示缓冲区的大小。默认值是缓存模式。
参数encoding指定对文本进行编码和解码的方式,只适用于文本模式,可以使用Python支持的任何格式,如GBK、utf8、CP936等等。
■ 如果执行正常,open()函数返回1个可迭代的文件对象,通过该文件对象可以对文件进行读写操作。如果指定文件不存在、访问权限不够、磁盘空间不够或其他原因导致创建文件对象失败则抛出异常。
■ 下面的代码分别以读、写方式打开了两个文件并创建了与之对应的文件对象。
f1 = open( 'file1.txt', 'r' ) #打开file1,以读方式;返回的是文件对象
f2 = open( 'file2.txt', 'w') #打开file2,本来没有创建一个新对象;本来存在覆盖原来的内容
■ 当对文件内容操作完以后,一定要关闭文件对象,这样才能保证所做的任何修改都确实被保存到文件中。
f1.close()
需要注意的是,即使写了关闭文件的代码,也无法保证文件一定能够正常关闭。例如,如果在打开文件之后和关闭文件之前发生了错误导致程序崩溃,这时文件就无法正常关闭。在管理文件对象时推荐使用with关键字(上下文管理语句),可以有效地避免这个问题。
■ 用于文件内容读写时,with语句的用法如下:
with open(filename, mode, encoding) as fp:
#这里写通过文件对象fp读写文件内容的语句
■ 另外,上下文管理语句with还支持下面的用法,进一步简化了代码的编写。
with open('test.txt', 'r') as src, open('test_new.txt', 'w') as dst: #同时打开两个文件
dst.write(src.read()) #读取其中一个写到另一个里面
■文件打开方式
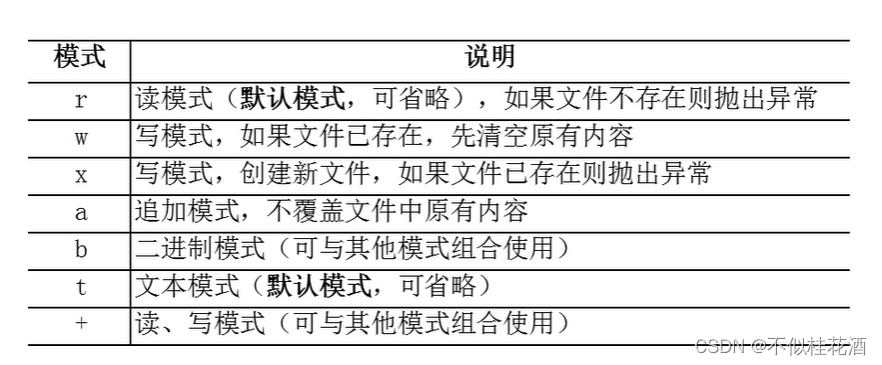
r、w、x:打开文件指针在头部
a:指针在尾部
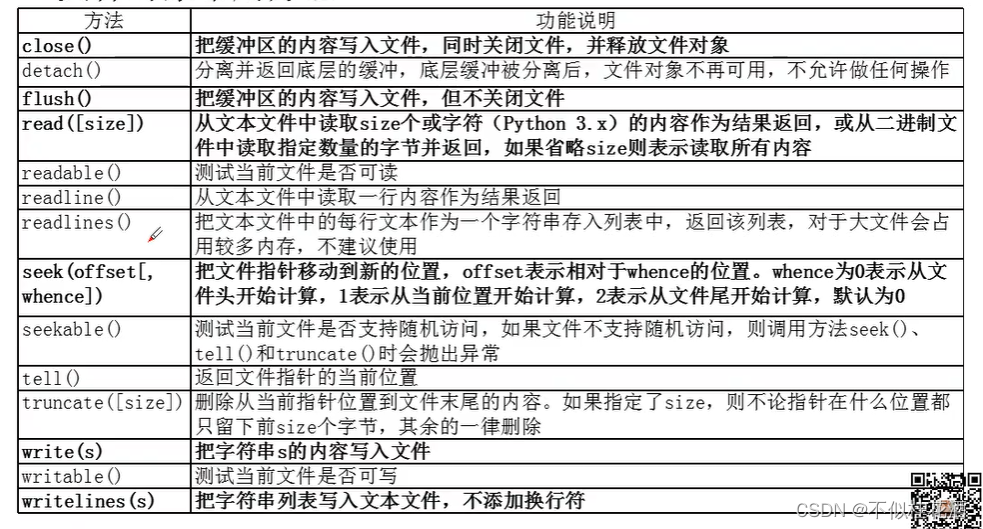
■文件对象常用属性

■文件对象常用方法
7.2文本文件操作案例精选
例7-1
向文本文件中写入内容,然后再读出。
#7-1
s='Hello world\n文本文件的读取方法\n文本文件的写入方法\n'
#with关键字:语句执行结束,自动关闭文件
with open('sample.txt','w') as fp: #open默认使用cp936编码fp.write(s)
with open('sample.txt') as fp:#没有指定打开的方式就是读print(fp.read())#读取文件所有内容并显示例7-2
读取并显示文本文件的前5个字符。
#读取并显示文本文件的前5个字符
with open('sample.txt','r') s f:s=f.read(5)
print('s=',s)
print('字符串s的长度(字符格式)=',len(s))例7-3
读取并显示文本文件所有行。
#读取并显示文本文件所有行
with open('sample.txt') as fp: #假设文件采用cp936编码for line in fp: #文件对象可以直接迭代print(line)例7-4
移动文件指针
seek:定位文件指针的,以字节为单位
#CP936编码格式兼容GBK:以2个字节表示1个汉字
>s='中国山东烟台SDIBT'
>fp=open(r'D:\python代码\第七章\sample.txt','w') #使用写方式打开一个文本文件
>fp.write(s) #将s这个字符串写进去
11 #交互模式下,往文本文件写入内容会返回一个数字:写进的字符数量
>fp.close() #将文件关闭
>fp=open(r'D:\python代码\第七章\sample.txt','r') #以读方式打开文件
>print(fp.read(3)) #读取前三个字符
中国山
>fp.seek(2) #将指针定位到下标为2的字节处(下标从0开始)
2
>print(fp.read(1)) #读取一个字符
国
>fp.seek(13) #文件指针定位到从头开始到13位置
13
>print(fp.read(1)) #读取一个字符
D
>fp.seek(3) #文件指针定位到从头开始到3位置
3
>print(fp.read(1)) #读取的是国和山的中间部分,报错
Traceback (most recent call last):
File "<pyshell#12>", line 1, in <module>
print(fp.read(1))
UnicodeDecodeError: 'gbk' codec can't decode byte 0xfa in position 0: illegal multibyte sequence
例7-5
读取文本文件data.txt(文件中每行存放一个整数)中所有整数,将其按升序排序后再写入文本文件data_asc.txt.
#7-5
with open('data.txt','r') as fp:#读取每一行,放到一个列表中,列表中是字符串,每个字符串是一行data=fp.readlines()
#删除两端的空白字符,转换成int
data=[int(line.strip()) for line in data]
data.sort() #升序排序
#写入另一个文本文件只能是字符串
#\n:换行符
data=[str(i)+'\n' for i in data]
#以写方式打开一个新文件
with open('data_asc.txt','w') as fp:fp.writelines(data)#把所有行写入到新文件中例7-6
编写程序,保存为demo6.py,运行后生成文件demo6_new.py,其中的内容与demo6.py一致,但是在每行的行尾加上了行号。
7-6
filename='demo6.py'
with open(filename,'r') as fp:#以读方式打开文件lines=fp.readlines() #所有行读出来
maxLength=len(max(lines,key=len)) #对读出来的每一行按长度求最大值
#删除每一行右边的空白字符
#加上若干个空格:最长的一行-当前这一行的长度
#index:行号,使用enumerate获取行号
#\n:换行符
lines=[line.rstrip()+' '*(maxLength-len(line))+'#'+str(index)+'\n'for index,line in enumerate(lines)]
#获取另外一个文件名,使用切片
with open(filename[:-3]+'_new.py','w') as fp:fp.writelines(line) #writelines:写入到另外一个文件中7.3二进制文件操作案例精选
数据库文件、图像文件、可执行文件、音视频文件、Office文档等等均属于二进制文件。
对于二进制文件,不能使用记事本或其他文本编辑软件进行正常读写,也无法通过Python的文件对象直接读取和理解二进制文件的内容。必须正确理解二进制文件结构和序列化规则,才能准确地理解二进制文件内容并且设计正确的反序列化规则。
所谓序列化,简单地说就是把内存中的数据在不丢失其类型信息的情况下转成对象的二进制形式的过程,对象序列化后的形式经过正确的反序列化过程应该能够准确无误地恢复为原来的对象。
Python中常用的序列化模块有struct、pickle、marshal和shelve。
7.3.1使用pickle模块
例7-8
写入二进制文件
#7-8写入二进制文件
import pickle
#i,a,s,lst,tu,coll,dic:需要往二进制文件写入的内容
i=13000000
a=99.056
lst=[[1,2,3],[4,5,6],[7,8,9]]
tu=(-5,10,8)
coll={4,5,6}
dic={'a':'apple','b':'banana','g':'grape','o':'orange'}
#把上面额东西都放到一个列表中
data=[i,a,s,lst,tu,coll,dic]#wb:w是写;b:二进制
with open('sample_pickle.dat','wb') as f:try:#pickle.dump:序列化len(data)的内容,写到f中pickle.dump(len(data),f)#表示后面将要写入的数据个数for item in data:pickle.dump(item,f)#每个元素序列化写入到文件中except:print('写文件异常!')#如果写文件异常则跳到此处执行例7-9
读取二进制文件
#7-9读取二进制文件
import pickle
#二进制文件的读方式打开文件
with open('sample_pickle.dat','rb') as f:#pickle.load:从文件读取并且序列化n=pickle.load(f) #读出文件的数据个数,读取同时进行反序列化for i in range(n):x=pickle.load(f)#读取,进行正确的反序列化print(x)7.3.2使用struct模块
例7-10
使用struct模块写入二进制文件
#7-10使用struct模块写入二进制文件
import structn=1300000000
x=96.45
b=True
s='a1@中共'
#struct模块有pack方法,把我们要序列化的n,x,b按照if?进行序列化
sn=struct.pack('if?',n,x,b) #序列化后,得到的是字节串
f=open('sample_struct.dat','wb') #wb模式创建一个二进制文件
f.write(sn) #把刚才序列化的字节串写进去
#字符串不用进行序列化,encode()直接编码为字节串写入
f.write(s.encode())
c.close() #关闭文件#使用struct序列化以后的二进制文件里面的信息读取出来
#使用struct的反序列化方法
import structf=open('sample_struct.dat','rb') #打开上面创建的文件
sn=f.read(9) #读取9个字节的字节串
#把刚才读到的9个字节串,以整数、实数、布尔值的形式进行反序列
tu=struct.unpack('if?',sn)
print(tu) #返回的是一个元组
n,x,b=tuple #序列解包
print('n=',n)
print('x=',x)
print('b1=',b1)
#再读取9个字节,使用字节串的decode方法,还原成字符串
s=f.read(9).decode()
f.close() #关掉文件
print('s=',s) #输出读到的字符串为什么反序列化的时候要读取9个字节,请看演示说明
>import struct #导入struct
>struct.pack('if?',13000,56.0,True) #将整数、实数、布尔值以if?的形式进行序列化
b'\xc82\x00\x00\x00\x00`B\x01' #序列化后是这样的字节串>len(_) #这个字节串有多长
9 #9个>len(struct.pack('if?',9999,5336.0,False)) #将整数、实数、布尔值更改,后再进行序列化
9 #得到的字节串长度还是9>x='a1@中国'
>len(x.encode()) #encode():将字符串直接编码为字节串
9 #发现是9#使用UTF-8:1个字节英文符号(a1@),3个字节中文,
7.3.3使用shelve序列化
Python标准库shelve也提供了二进制文件操作的功能,可以像字典赋值一样来写入二进制文件,也可以像字典一样读取二进制文件。
>import shelve #导入shelve模块
>zhangsan={'age':38,'sex':'Male','address':'SDIBT'} #创建字典
>lisi={'age':40,'sex':'Male','qq':'1234567','tel':'7654321'} #两个字典的长度不同#shelve模块的open()函数,打开一个二进制文件,返回的文件对象作为fp
>with shelve.open('shelve_test.dat') as fp: #with保证文件被关闭#fp就像个字典一样
#字典里有这个键,更新这个键;没有这个键,创建一个新的元素
fp['zhangsan']=zhangsan #把zhangsan的信息赋值给fpzhangsan
fp['lisi']=lisi #把lisi的信息赋值给fplisi
for i in range(5): #循环5次
fp[str(i)]=str(i)
#读取,使用shevel模块的open,打开二进制文件作为fp
>with shelve.open('shelve_test.dat') as fp:
print(fp['zhangsan']) #像字典一样,获取fp中zhangsan的信息
print(fp['zhangsan']['age']) #获取zhangsan的age信息
print(fp['lisi']['qq']) #获取lisi的qq信息
print(fp['3']) #获取字符串3对应的信息
{'age': 38, 'sex': 'Male', 'address': 'SDIBT'}
38
1234567
3
7.3.4使用marshal序列化
python标准库marshal也可以进行对象的序列化和反序列化。
>import marshal #导入模块
#从x1-x6,都是要序列化的信息对象
>x1=30
>x2=5.0
>x3=[1,2,3]
>x4=(4,5,6)
>x5={'a':1,'b':2,'c':3}
>x6={7,8,9}#把需要序列化的对象放到一个列表中
#i从1-6循环,x+i,eval函数进行求值
>x=[eval('x'+str(i)) for i in range(1,7)]
>x #得到x是我们要写入的对象
[30, 5.0, [1, 2, 3], (4, 5, 6), {'a': 1, 'b': 2, 'c': 3}, {8, 9, 7}]#创建二进制文件,使用wb方式
>with open('test.dat','wb') as fp:
#使用marsha的dump方法。把要序列化的数量写到文件里面去
marshal.dump(len(x),fp)
for item in x: #循环列表
marshal.dump(item,fp) #把里面的每个对象,使用dump写入文件
5
5
9
20
17
26
20
#读取
>with open('test.dat','rb') as fp: #以读方式打开二进制文件
n=marshal.load(fp) #使用load把第一个对象读出来,第一个对象是要写入的总数量
for i in range(n): #循环
print(marshal.load(fp)) #一边读取一边反序列化,同时输出
30
5.0
[1, 2, 3]
(4, 5, 6)
{'a': 1, 'b': 2, 'c': 3}
{8, 9, 7}
7.4文件级操作
如果需要处理文件路径,可以使用os.path模块中的对象和方法;
如果需要使用命令行读取文件内容可以使用fileinput模块;
创建临时文件和文件夹可以使用tempfile模块;
另外,Python 3.4之后版本的pathlib模块提供了大量用于表示和处理文件系统路径的类。
7.4.1os与os.path模块
os模块常用的文件操作函数
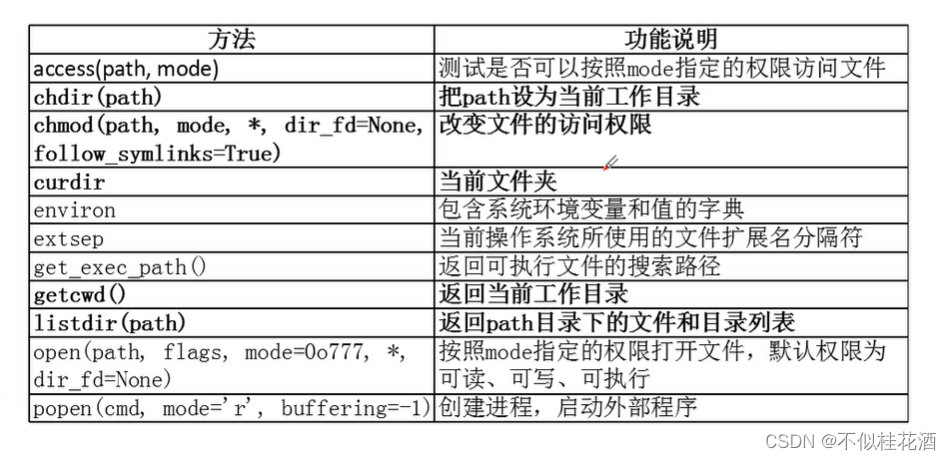
chdir(path):指定路径设置成当前工作路径
chmod():改变文件的访问权限
curdir:返回当前文件夹,当前工作目录
getcwd():返回当前工作目录
listdir(path):列出指定路径下文件和文件夹列表;不加参数,默认当前目录或当前工作文件夹
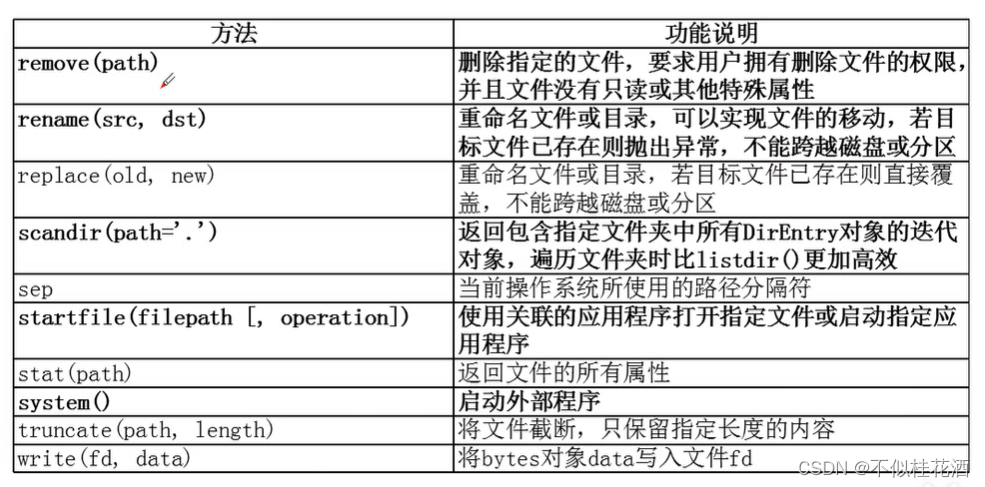
remove(path):删除一个文件(这个文件没有什么特殊属性,只读会抛出异常)
chmod(path)改变文件的访问权限,删除只读属性或是其他的一些属性
rename(src,dst):重命名文件或文件夹,也可以实现文件的移动;不能跨越磁盘和分区
scandir(path=‘.’):返回包含指定文件夹中所有的DirEntry对象的迭代对象,比listdir()快些
startfile(filepath [,operation]):启动指定的文件
system():启动外部程序,外部的可执行程序,系统的内置命令
os.path常用的文件操作函数
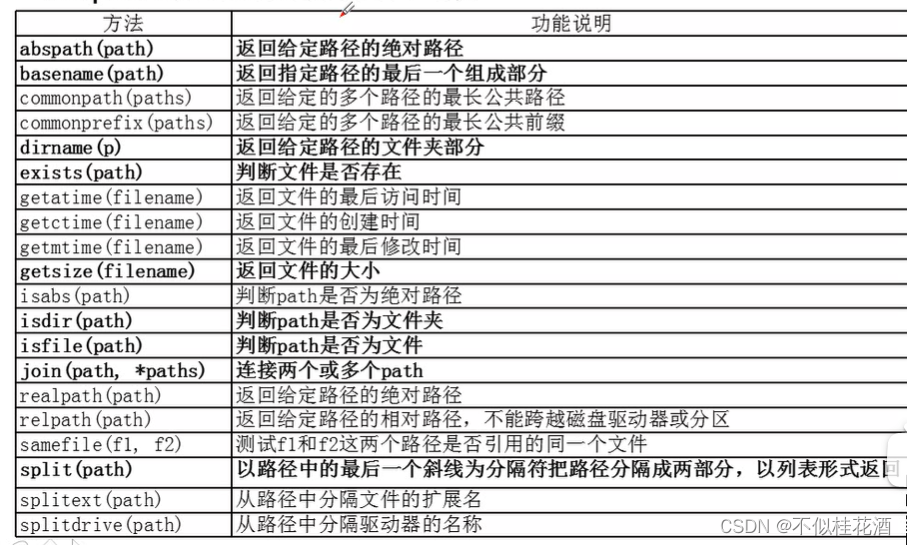 abspath(path):返回路径的绝对路径
abspath(path):返回路径的绝对路径
basename(path):返回路径的最后一个组成部分
dirname(p):的那会给定路径的文件夹部分
exists(path):判断文件是否存在
getatime(filename):返回文件的最后访问时间
getctime(filename):返回文件的创建时间
getmtime(filename):返回文件的最后修改时间
getsize(filename):获取文件的大小
isdir(path):判断给定的路径是否是一个文件夹
isfile(path):判断给定的路径是否是一个文件
join(path,*paths):把两个或多个路径连接到一起
split(path):把路径分隔开
splitext(path):从路径中分隔文件的扩展名
splitdrive(path):从路径中分隔驱动器的名称
>import os
>import os.path#os.path.exists():判断一个文件是否存在
>os.path.exists('test.txt') #没有写全路径,默认是相对路径(测试当前文件夹下是否存在test.txt)
False#os.rename(A,B):将A命名为B(原文件不存在抛出异常)
>os.rename('c:\\test1.txt','c:\\test2.txt')
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
os.rename('c:\\test1.txt','c:\\test2.txt')
FileNotFoundError: [WinError 2] 系统找不到指定的文件。: 'c:\\test1.txt' -> 'c:\\test2.txt'#test1.txt改名为test2.txt
>os.rename("D:\\python代码\\第七章\\test1.txt","D:\\python代码\\第七章\\test2.txt")
>os.path.exists("D:\\python代码\\第七章\\test1.txt")
False
>os.path.exists("D:\\python代码\\第七章\\test2.txt")
True
>path='D:\\python代码\\第七章\\test2.txt'
#os.path.dirname():获取路径中的文件夹部分
>os.path.dirname(path)
'D:\\python代码\\第七章'#os.path.split():把路径分成文件路径和文件名两部分
>os.path.split(path)
('D:\\python代码\\第七章', 'test2.txt')#os.path.splitdrive():只分割驱动器部分
os.path.splitdrive(path)
('D:', '\\python代码\\第七章\\test2.txt')#os.path.splitext():只分割文件路径中的扩展名
>os.path.splitext(path)
('D:\\python代码\\第七章\\test2', '.txt')
列出当前目录下所有扩展名为pyc的文件:
#使用列表推导式
#获取当前目录中的所有文件或子文件夹的名字;如果是一个文件and文件以pyc结束
>[fname for fname in os.listdir(os.getcwd()) if os.path.isfile(fname) and fname.endswith('.pyc')]
[]
将当前目录的所有扩展名为“html”的文件修改为扩展名为“htm”的文件:
#将当前目录的所有扩展名为“html”的文件修改为扩展名为“htm”的文件
import os
#os.listdir:返回的是列表,包含当前目录下所有文件和子文件夹(带.)列表
file_list=os.listdir(".")
#遍历当前目录下所有文件和子文件夹列表
for filename in file_list:#对于所有文件查找从右向左的第一个.pos=filename.rindex(".")#从.的下一个位置切片,看是不是htmlif filename[pos+1:]=="html":#是html的话,把主文件名字切下来,再加上htmnewname=filename[:pos+1]+"htm"#os.rename:把原来的名字改成新的名字os.rename(filename,newname)#给出提示:原来的文件名被改成另一个名字了print(filename+"更名为:"+newname)
也可以改写为下面的简洁而等价的代码:
#简洁而等价的代码
import os
#列表推导式,直接过滤不是要找的列表
#列出当前文件夹下所有文件和子文件列表,如果以.html结尾,留下
file_list=[filename for filename in os.listdir(".") if filename.endswith('.html')]
for filename in file_list:#从头切片到-4:从开始到.的为位置;加上htmnewname=filename[:-4]+'htm'#重命名文件,后面的文件名给前面的文件os.rename(filename,newname)print(filename+"更名为:"+newname)7.2.4shutil模块
使用该模块的copyfile()方法复制文件
>import shutil
>shutil.copyfile('C:\\dir.txt', 'C:\\dir1.txt')
将C:\Python34\Dlls文件夹以及该文件夹中所有文件压缩至D:\a.zip文件
>shutil.make_archive('D:\\a', 'zip', 'C:\\Python34', 'Dlls')
将刚压缩得到的文件D:\a.zip解压缩至D:\a_unpack文件夹
>shutil.unpack_archive('D:\\a.zip', 'D:\\a_unpack')
删除刚刚解压缩得到的文件夹
>shutil.rmtree('D:\\a_unpack')
7.5目录操作
os模块常用的目录操作函数
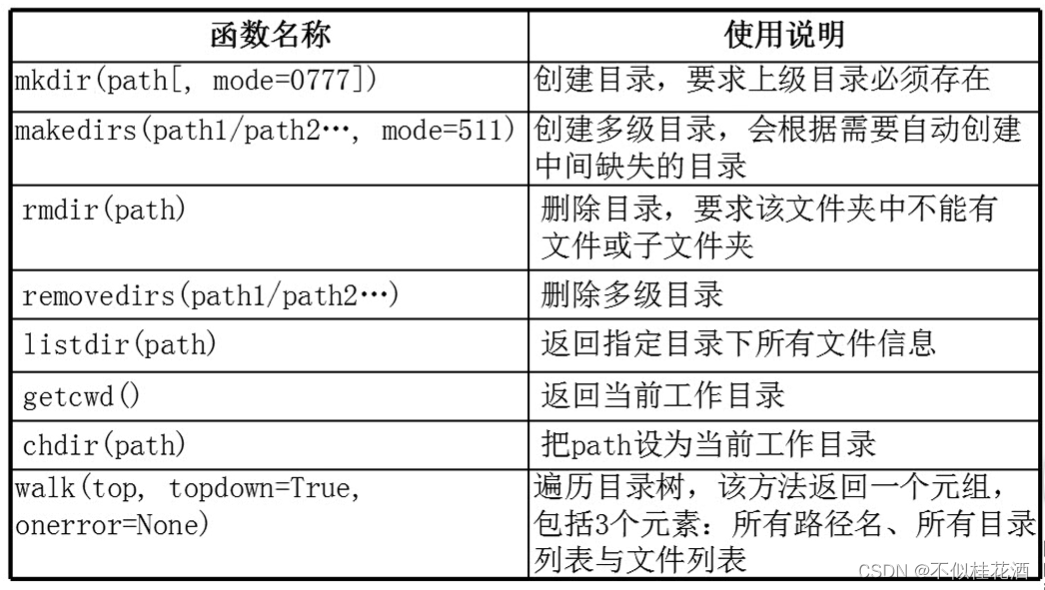
makdir(path):创建文件夹(我们要创建的文件夹必须存在上级目录)
makdirs(path)::创建多级文件夹(如果要创建的文件上级目录不存在,自动补缺失的部分)
rmdir(path):删除文件夹(要求文件夹是空的,否则失败)
removedirs(path):删除多级目录(要求文件夹是空的)
listdir(path):返回指定文件夹下所有文件和字文件夹信息
getcwd():返回当前工作目录
chdir(path):把指定的目录设置成当前工作目录
walk():遍历目录树,返回的是元组(所有路径名,所有目录列表,所有文件列表)
>import os
>os.getcwd() #看当前的工作目录(看当前工作的文件夹)
'D:\\python'
>os.mkdir(os.getcwd()+'\\temp') #在当前工作目录下创建一个文件夹temp
>os.chdir(os.getcwd()+'\\temp') #把共工作目录切换到上面创建的temp中
>os.getcwd() #看当前的工作目录
'D:\\python\\temp'
>os.mkdir(os.getcwd()+'\\test') #在当前目录下创建一个test子文件夹
>os.listdir('.') #列出当前文件夹下所有的文件和子文件夹列表
['test']
>os.rmdir('test') #删除上面创建的文件
>os.listdir('.') #列出当前文件夹下所有的文件和子文件夹列表
[]
递归遍历文件夹(深度优先)
#递归遍历文件夹(深度优先)
from os import listdir
from os.path import join,isfile,isdirdef listDirDepthFrist(directory):#listdir:列出这个文件夹下所有的文件和子文件夹列表for subPath in listdir(directory):#列出的父目录(directory),列出的子文件夹或文件(subPath)#中间用\连接path=join(directory,subPath)#isfile:判断path是不是一个文件if isfile(path):#是文件直接输出print(path)#isdir:是一个文件夹elif isdir(path):#先输出文件夹print(path)#将文件夹递归进去,一直把文件夹递归完了listDirDepthFirst(path)遍历指定文件夹(广度优先)
同级文件夹遍历完后,遍历其子文件夹
#遍历指定文件夹(广度优先)
#广度优先:先遍历文件夹from os import listdir
from os.path import join,isfile,isdirdef listDirWidthFrist(directory):#没遇到一个新的目录就添加到列表的尾部dirs=[directory]#如果还有没有遍历过的文件夹,继续循环while dirs:#弹出第一个current=dirs.pop(0)#listdir:列出current下的所有的文件for subPath in listdir(current):#join:连接父目录和子目录path=join(current,subPath)#isfile:判断path是不是一个文件if isfile(path):#是文件直接输出print(path)#isdir:是一个文件夹elif isdir(path):#先输出文件夹print(path)#把文件夹追加到列表的尾部dirs.append(path)使用os.walk函数遍历
#使用os.walk函数遍历
import os
#遍历的路径是path
def visitDir2(path):#判断path是不是一个文件夹,如果不是if not os.path.isdir(path):#返回一个错误信息print('Error: ",path," is not a directory or does not exist.')return#如果是一个文件夹,直接对路径进行os.walk操作,返回的是元组#元组中有三个元素:所有路径名,所有目录列表,所有文件列表list_dirs=os.walk(path)#序列解包,遍历walk返回的对象for root,dirs,files in list_dirs:#遍历所有的文件夹for d in dirs:#root和每一个文件夹连接起来,输出print(os.path.join(root,d))#遍历所有的文件for f in files:#绝对路径和文件名连接起来print(os.path.join(root,f))7.6案例精选
例7-12
计算CRC32值
p60 61 62 63