1.Spark SQL是Spark的一个模块,用于处理海量结构化数据
限定:结构化数据处理
RDD的数据开发中,结构化,非结构化,半结构化数据都能处理。
2.为什么要学习SparkSQL
SparkSQL是非常成熟的海量结构化数据处理框架。
学习SparkSQL主要在2个点:
a.SparkSQL本身十分优秀,支持SQL语言\性能强\可以自动优化\API兼容\兼容HIVE等
b.企业大面积在使用SparkSQL处理业务数据:离线开发,数仓搭建,科学计算,数据分析
3.SparkSQL的特点
a.融合性:SQL可以无缝的集成在代码中,随时用SQL处理数据
b.统一数据访问:一套标准的API可以读写不同的数据源
c.Hive兼容:可以使用SparkSQL直接计算并生成Hive数据表
d.标准化连接:支持标准化JDBC\ODBC连接,方便和各种数据库进行数据交互
4.SparkSQL和Hive的异同点
Hive和SparkSQL都是分布式SQL计算引擎,用于处理大规模结构化数据的。并且Hive和SparkSQL都可以运行在YARN之上。
不同点:
SparkSQL是内存计算,底层运行基于SparkRDD。Hive是基于磁盘迭代的,底层运行基于MapReduce。
SparkSQL不支持元数据管理。Hive有元数据管理服务(Metastore服务)
SparkSQL支持SQL和代码的混合执行。Hive仅能以SQL开发。
5.SparkSQL的数据抽象用的是什么
DataFrame:一个分布式的内部以二维表数据结构存储的数据集合。
6.RDD和DataFrame两种数据抽象的区别:
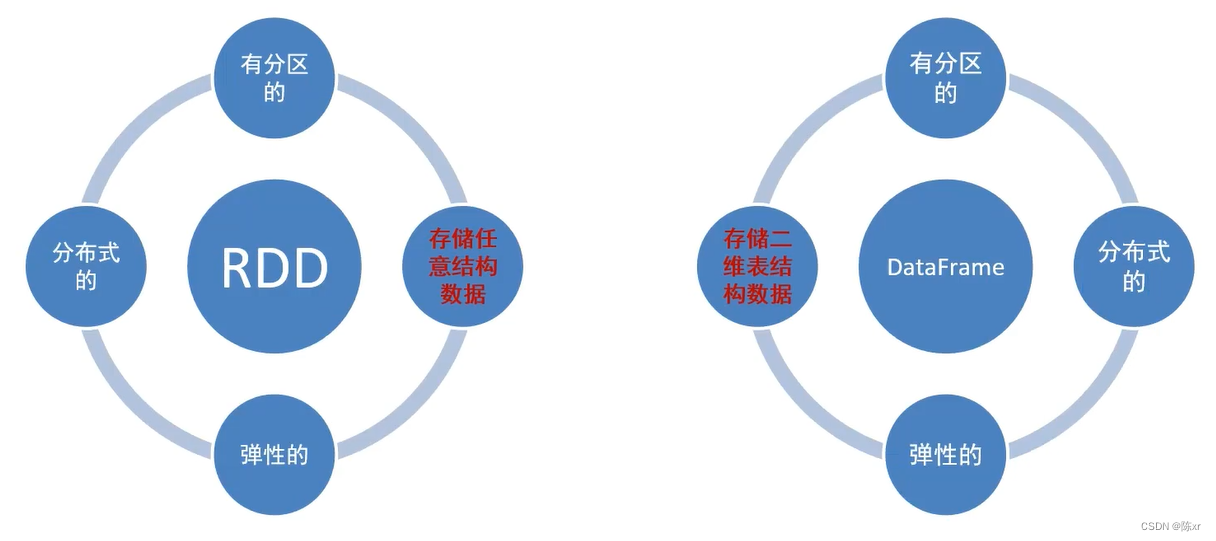
还有就是DataFrame存储数据时,是类似于mysql数据库一样的形式,按照二维表格存储。DataFrame是严格的按照SQL格式的格式来存储数据,所以DataFrame就更适合处理SQL数据
而RDD是按照数组对象的形式存储。RDD存储数据很随意,很多数据结构的数据都能存储。
7.SparkSession对象
在Spark的RDD阶段中,程序的执行入口是SparkContext对象。
在Spark 2.0之后,推出了SparkSession对象,来作为Spark编码的统一入口对象。
SparkSession对象可以:
a.用于SparkSQL编程作为入口对象
b.用于SparkCore编程,通过SparkSession对象中获取到SparkContext
8.总结
1)SparkSQL和Hive都是用在大规模SQL分布式计算的计算框架,均可以运行在YARN上,在企业中被广泛应用。
2)SparkSQL的数据抽象为:SchemaRDD(废弃),DataFrame(Python,R,Java,Scala),DataSet(Java,Scala)
3)DataFrame同样是分布式数据集,有分区可以并行计算,和RDD不同的是,DataFrame中存储的数据结构是以表格形式组织的,方便进行SQL运算。
4)DataFrame对比DataSet基本相同,不同的是DataSet支持泛型特性,可以让Java,Scala语言更好的利用到。
5)SparkSession是2.0之后推出的新的执行环境的入口对象,可以用于RDD,SQL等编程。
9.DataFrame的组成
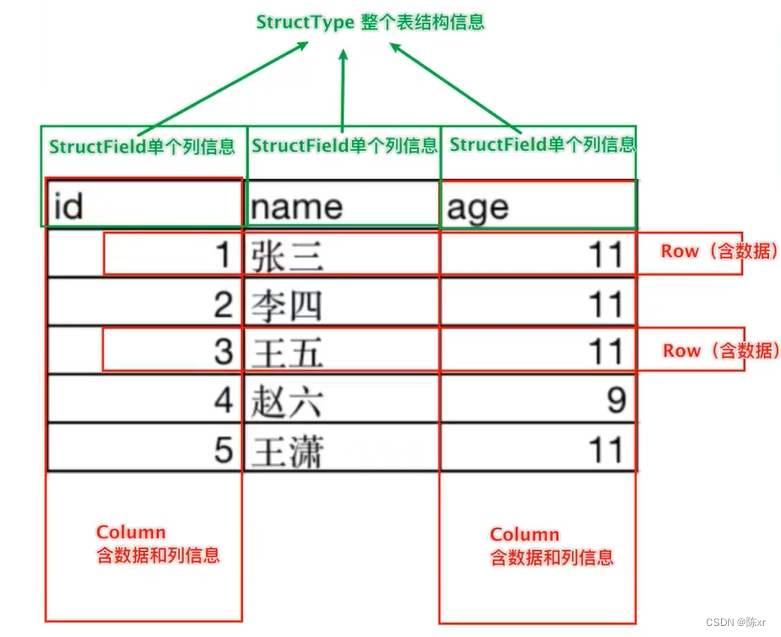
二维表结构
在结构层面:structType对象描述整个DataFrame的表结构;structField对象描述一个列的信息。
在数据层面:Row对象记录一行数据;Column对象记录一列数据并包含列的信息。
10.DataFrame的创建
1)基于RDD的方式1
DataFrame对象可以从RDD转换而来,都是分布式数据集合,其实就转换一下内部存储的结构,转换为二维表的结构。
通过SparkSession对象的createDataFrame方法来将RDD转换为DataFrame,这里只传入列名称,类型从RDD中进行推断,是否允许为空默认为允许(True)
2)基于RDD的方式2
通过StructType对象来定义DataFrame的“表结构”转换RDD
3)基于RDD的方式3
使用RDD的toDF方法转换为RDD
4)基于Pandas的DataFrame
将Pandas的DataFrame对象,转变为分布式的SparkSQL DataFrame对象。
11.DataFrame支持两种风格进行编程:
1)DSL风格:称之为领域特定语言,其实就是指DataFrame特有的API,DSL风格就是以调用API的方式来处理Data。比如:df.where().limit()
2)SQL语法功能:就是使用SQL语句处理DataFrame的数据。比如:spark.sql("select * from xxx")
11.总结
1)DataFrame在结构层面上由StructField组成描述,由StructType构造表描述。在数据层面上,Column对象记录列数据,Row对象记录行数据。
2)DataFrame可以从RDD转换,Pandas DF转换,读取文件,读取JDBC等方法构建。
3)spark.read.format()和df.write.format()是DataFrame读取和写出的统一化标准API
4)SparkSQL默认在shuffle(洗牌,理解为数据的整合)阶段200个分区,可以修改参数获得最好性能。
5)dropDuplicates可以去重,dropna可以删除缺失值,fillna可以填充缺失值
6)SparkSQL支持JDBC读写,可以用标准API对数据库进行读写操作。
12.SparkSQL定义UDF函数
无论是Hive还是SparkSQL分析处理数据的时候,往往需要使用函数,SparkSQL模块本身自带了很多实现公共功能的函数,在pyspark.sql.function中。SparkSQL和Hive一样支持定义函数:UDF和UDAF,尤其是UDF函数在实际项目中使用最为广泛。
13.SparkSQL的自动优化
RDD的运行完全会按照开发者的代码执行,如果开发者的水平有限,RDD的执行效率也会受影响。
而SparkSQL会对写完的代码,执行“自动优化”,以提高代码运行的效率,避免开发者水平影响到代码执行效率。
为什么SparkSQL可以优化,RDD不行?
因为RDD内含数据类型不限格式和结构,而DataFrame只有二维表结构,可以被针对。SparkSQL的自动优化,依赖于:Catalyst优化器。
14.Catalyst优化器
为了解决过多依赖Hive的问题,SparkSQL使用了一个新的SQL优化器代替Hive的优化器,这个优化器就是Catalyst,整个SparkSQL的优化架构如下:

1)API层简单地说就是Spark会通过一些API接受SQL语句
2)收到SQL语句后,将其交给Catalyst,Catalyst负责解析SQL,生成执行计划等
3)Catalyst的输出应该是RDD的执行计划
4)最终再交给集群去运行
15.SparkSQL的执行流程
1)提交SparkSQL代码
2)catalyst优化
a.生成原始的AST语法树
b.标记AST元数据
c.进行断言下推和列值裁剪,以及其他方面的优化作用在AST上
d.将最终的AST得到,生成执行计划
e.将执行计划翻译为RDD代码
3)Driver执行环境入口构建(SqlSession)
4)DAG调度规划逻辑任务
5)TASK调度区分配逻辑任务到具体Executor上工作并监控管理任务
6)Worker干活
DataFrame代码再怎么被优化,最终还是被转换为RDD去执行。
15.Spark on Hive
回顾Hive组件:
对于Hive来说,就两样东西:
1)SQL优化翻译器(执行引擎),翻译SQL到MapReduce并提交到YARN执行
2)MetaStore元数据管理中心
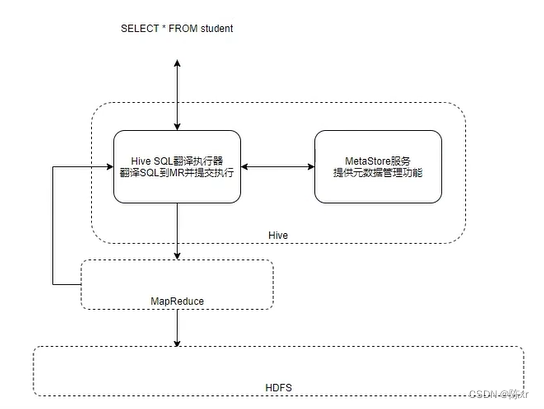
那么Spark on Hive是什么呢?请看下面的图:

由上图可知,Spark on Hive不外乎就是SparkSQL借用了Hive的元数据管理中心,也就是说Hive的MetaStore+SparkSQL就构成了Spark on Hive,然后执行的时候走的是SparkRDD代码这条支线,就不再走Hive老旧的MapReduce这条路线。以上就是Spark on Hive的基本原理。
16.ThriftServer服务(就是方便程序员使用,不需要程序员专门会写Spark或者DataFrame的API依然可以操作Spark)
该服务监听10000端口,该服务对外提供功能,使得我们可以用数据库工具或者代码连接上来,直接写SQL便可操作Spark。(底层是翻译成RDD运行的)
17.分布式SQL归纳
分布式SQL执行引擎就是使用Spark提供的ThriftServer服务,以“后台进程”的模式持续运行,对外提供端口。
可以通过客户端工具或者代码,以JDBC协议连接使用。
SQL提交后,底层运行的就是Spark任务。
分布式SQL大白话总结:相当于构建了一个以MetaStore服务为元数据,Spark为执行引擎的数据库服务,像操作数据库那样方便的操作SparkSQL进行分布式的SQL计算。
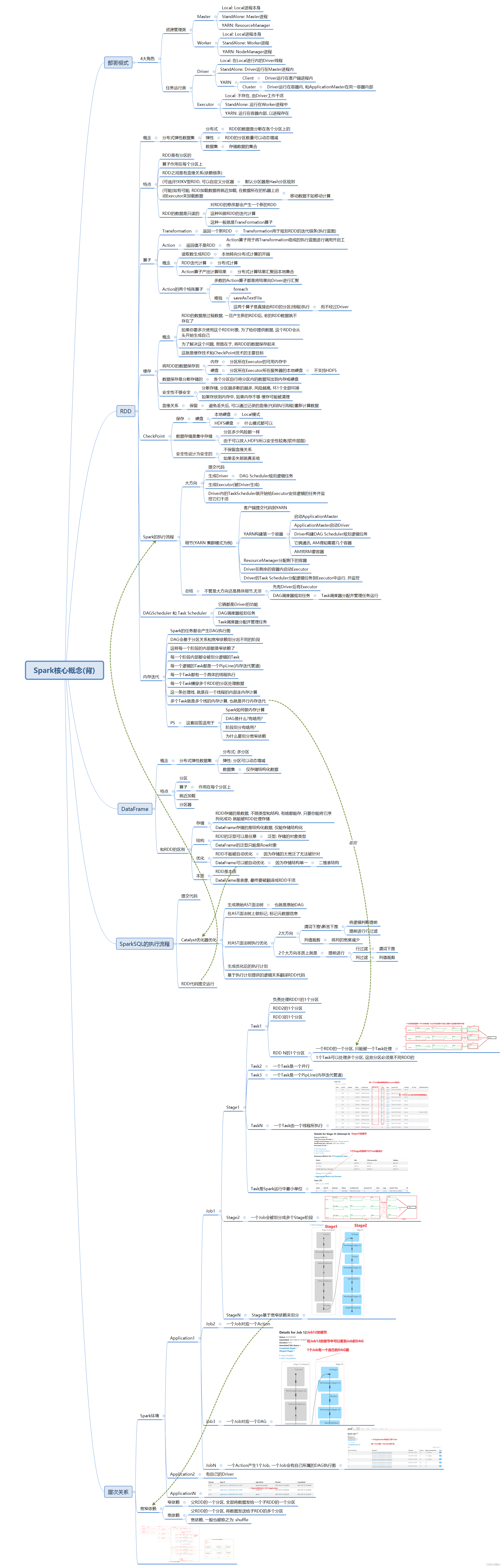
18.Spark层次关系概念图

19.Spark核心概念思维导图