本文是本人最近学习Python爬虫所做的小练习。
如有侵权,请联系删除。
页面获取url
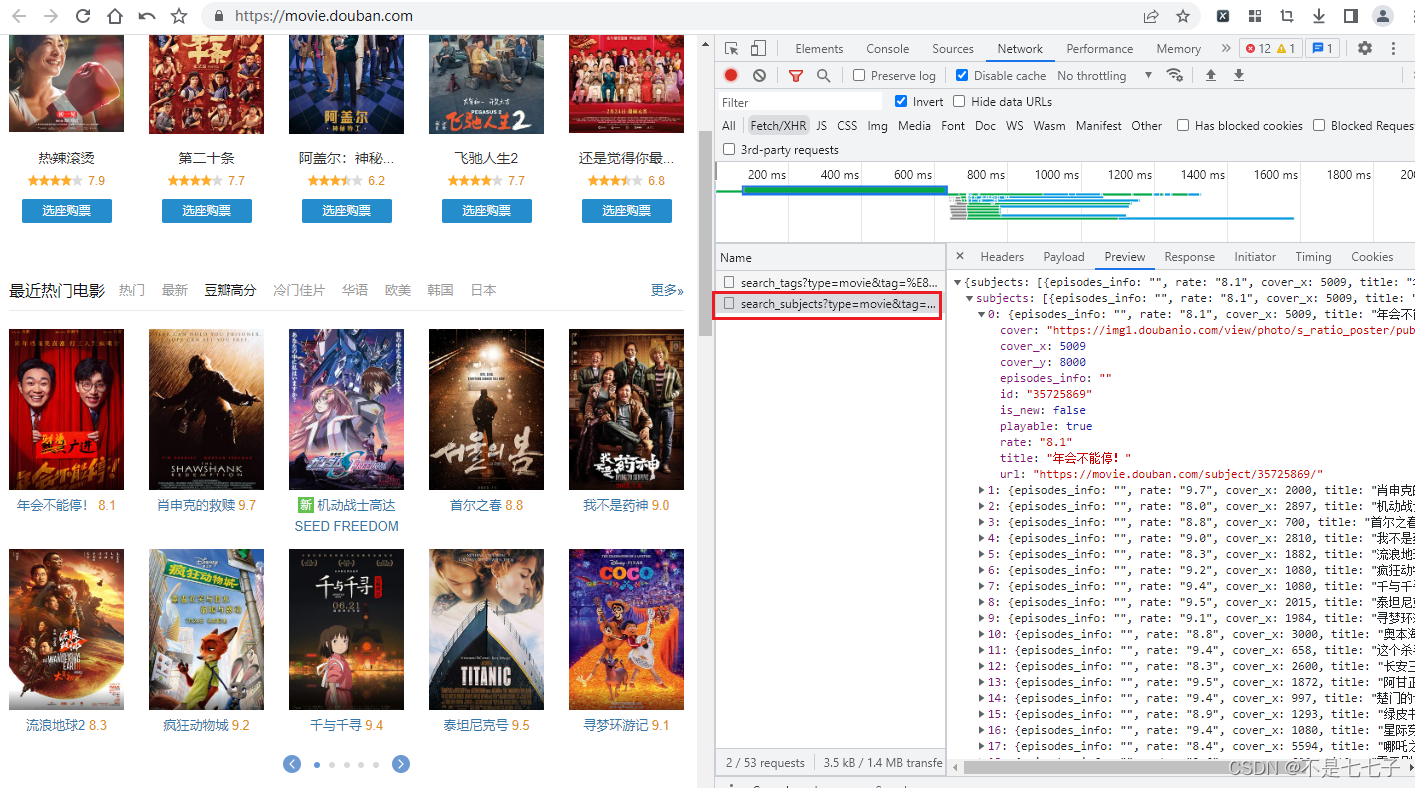
代码
import requests
import os
import re# 创建文件夹
path = os.getcwd() + '/images'
if not os.path.exists(path):os.mkdir(path)# 获取全部数据
def get_data():# 地址url = "https://movie.douban.com/j/search_subjects"# 传参params = {'type': 'movie','tag': '豆瓣高分','page_limit': 50,'page_start': 0}# 请求头headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'}# 发送请求response = requests.get(url, params=params, headers=headers)# json数据格式items = response.json()# 循环遍历for data in items['subjects']:# 标题title = data.get('title')# 封面cover = data.get('cover')# 下载图片到images文件夹,文件名:titleif title != '' and cover != '':download_image(title, cover)# 下载图片
def download_image(title, cover):# 请求头headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'}res = requests.get(cover, headers=headers)# 判断标题是否含有\/:*?"<>|,文件命名不能含有这些,如果有,则用下划线_取代new_title = validateTitle(title)with open(path + '/' + new_title + '.jpg', mode='wb') as f:# 图片内容写入文件f.write(res.content)print(f"正在下载图片,图片名:{title}.jpg")# 去除文件中的非法字符(正则表达式)
def validateTitle(title):pattern = r"[\\\/\:\*\?\"\<\>\|]"new_title = re.sub(pattern, '_', title)return new_titleif __name__ == '__main__':get_data()
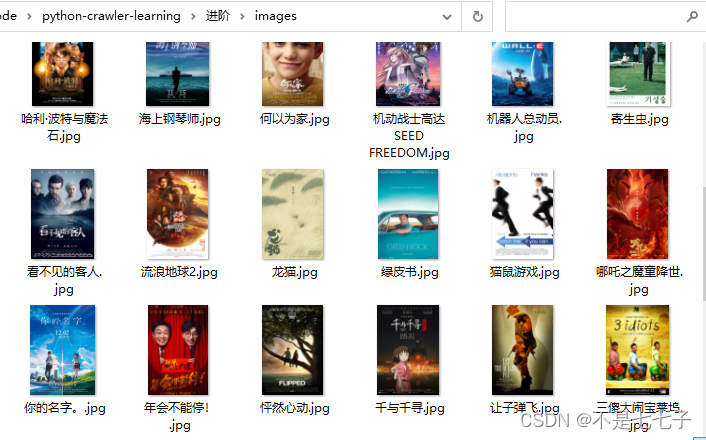
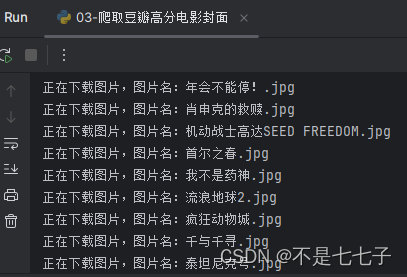
效果



![[linux][异常检测] hung task, soft lockup, hard lockup, workqueue stall](https://img-blog.csdnimg.cn/direct/2a73f5bce477440788668bdd4cf2b0f8.png)