前言
本文对应于 spark 系列的 Spark 的 WordCount
这里主要是 从宏观上面来看一下 flink 这边的几个角色, 以及其调度的整个流程
一个宏观 大局上的任务的处理, 执行
基于 一个本地的 flink 集群
测试用例
/*** com.hx.test.Test01WordCount** @author Jerry.X.He* @version 1.0* @date 2021/4/12 10:14*/
public class Test01WordCount {// com.hx.test.Test01WordCount// -Xmx100M -XX:+UseSerialGC -XX:+TraceClassUnloadingpublic static void main(String[] args) throws Exception {// ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();String jarPath = "D:\\IdeaWorkStations\\HelloFlink\\target\\HelloFlink-0.0.1.jar";ExecutionEnvironment env = ExecutionEnvironment.createRemoteEnvironment("127.0.0.1", 8081, jarPath);env.setParallelism(1);String inputPath = "D:\\IdeaWorkStations\\HelloFlink\\src\\main\\resources\\Test01WordCount.txt";DataSource<String> inputDs = env.readTextFile(inputPath);DataSet<Tuple2<String, Integer>> result = inputDs.flatMap(new MyFlatMapMapper()).map(new MyMapMapper()).groupBy(0).sum(1);result.print();System.gc();System.in.read();System.out.println(" end ");}/*** MyFlatMapMapper** @author Jerry.X.He* @version 1.0* @date 2021/4/12 10:24*/private static class MyFlatMapMapper implements FlatMapFunction<String, String> {private static List<byte[]> dummyBytes = new ArrayList<>();static {try {for (int i = 0; i < 10; i++) {byte[] tmpBytes = FileUtils.readAllBytes(Paths.get("D:\\IdeaWorkStations\\HelloFlink\\target\\logs\\ROOT.2021-12-27-9.log"));dummyBytes.add(tmpBytes);}} catch (Exception e) {e.printStackTrace();} finally {new Thread(new MyRunnable()).start();}}@Overridepublic void flatMap(String line, Collector<String> out) throws Exception {String[] splits = line.split("\\s+");for (String split : splits) {out.collect(split);}}}/*** MyRunnable** @author Jerry.X.He* @return* @date 2021/12/27 16:16*/public static class MyRunnable implements Runnable {@Overridepublic void run() {System.err.println(" MyRunnable.run before ");IoUtils.sleep(1000_000);System.err.println(" MyRunnable.run after ");}}/*** MyMapMapper** @author Jerry.X.He* @version 1.0* @date 2021/4/12 10:29*/private static class MyMapMapper implements MapFunction<String, Tuple2<String, Integer>> {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return new Tuple2<>(word, 1);}}}
Test01WordCount.txt 内容如下

整体交互流程
Driver 提交 Job 到 JobManager, JobManager 分配任务到 TaskManager
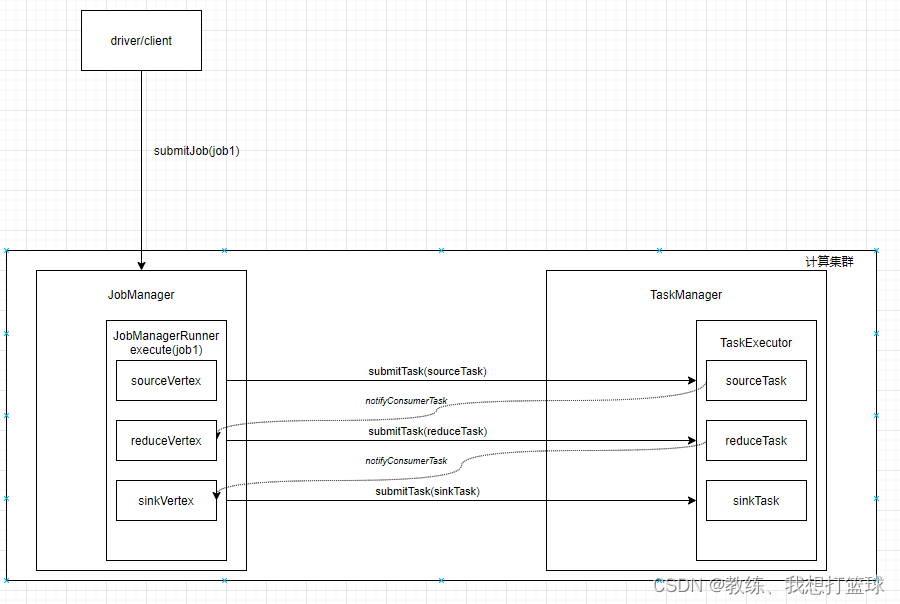
然后 TaskManager 和 JobManager 这边交互如下
Driver 这边的处理
这里是 driver 这边的根据 DataSet阶段 转换为 Plan阶段
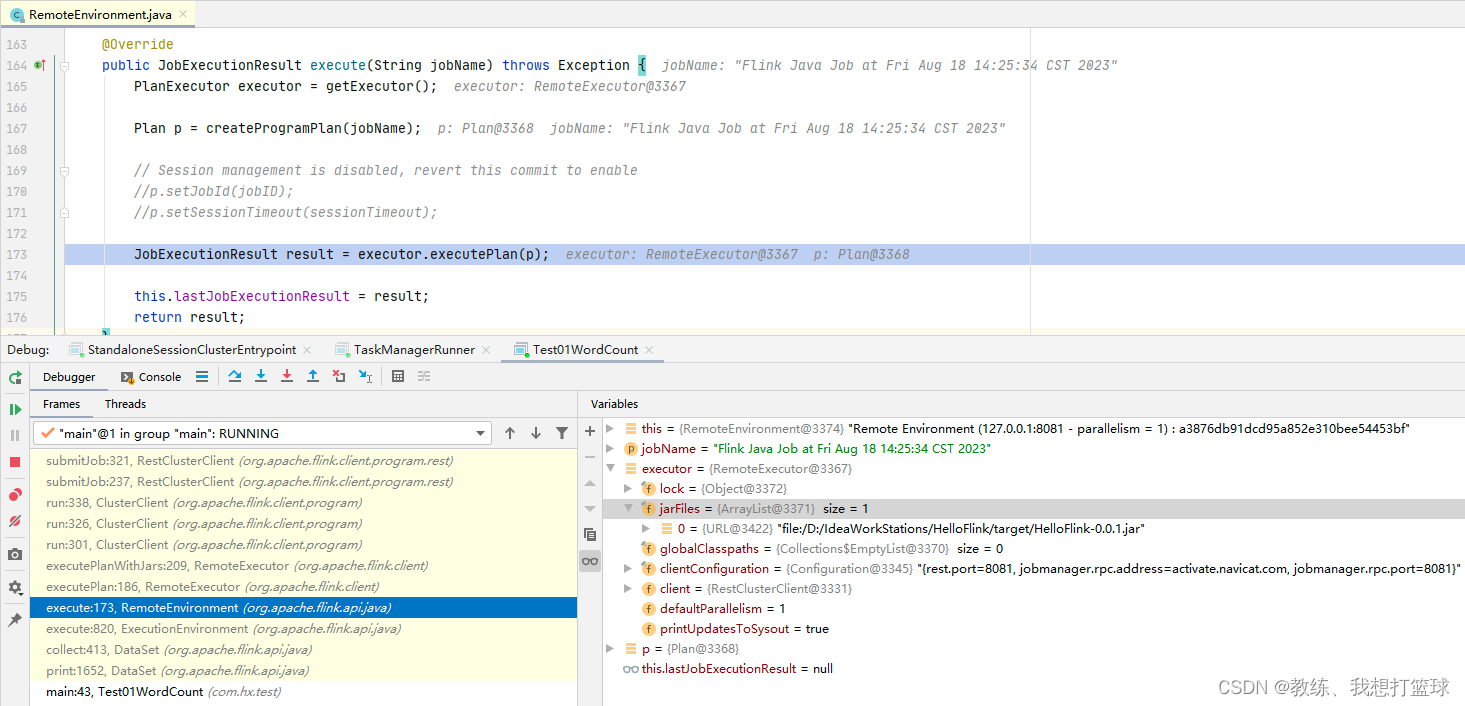
这里是 Plan阶段 转换为 OptimizedPlan阶段
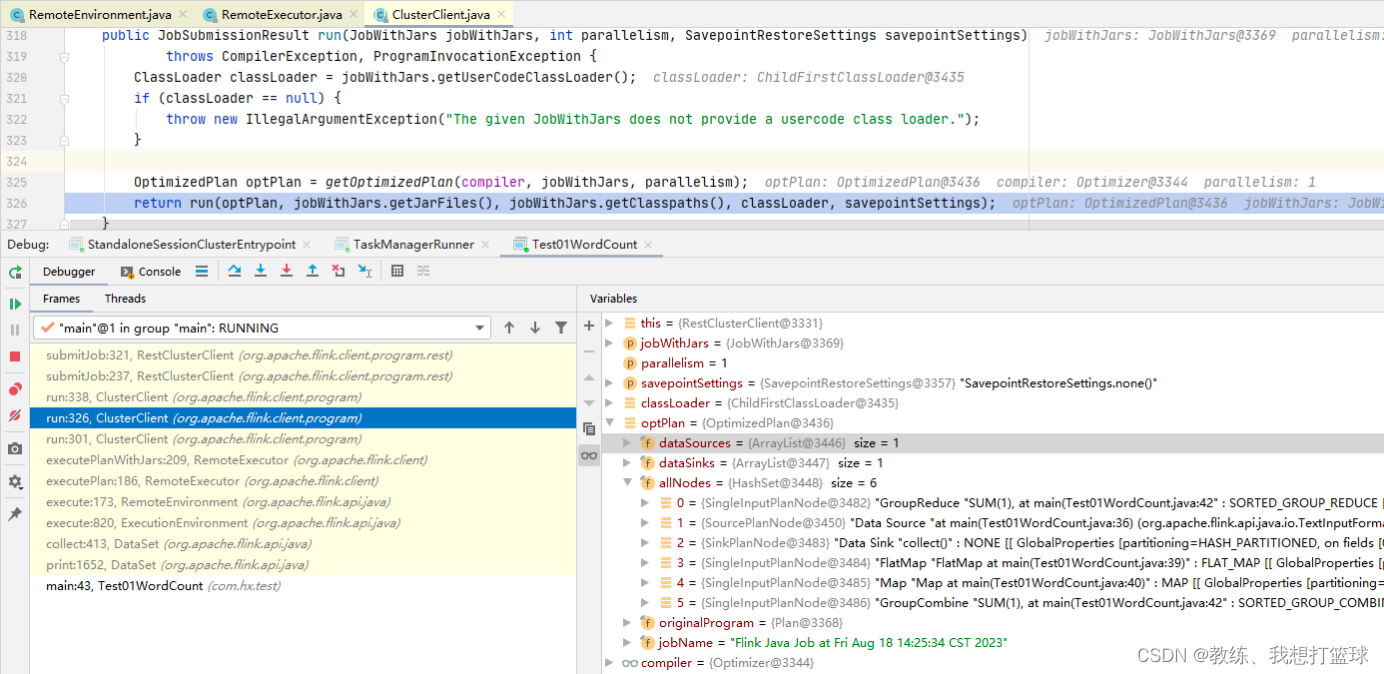
这里是 OptimizedPlan阶段 转换为 JobGraph阶段
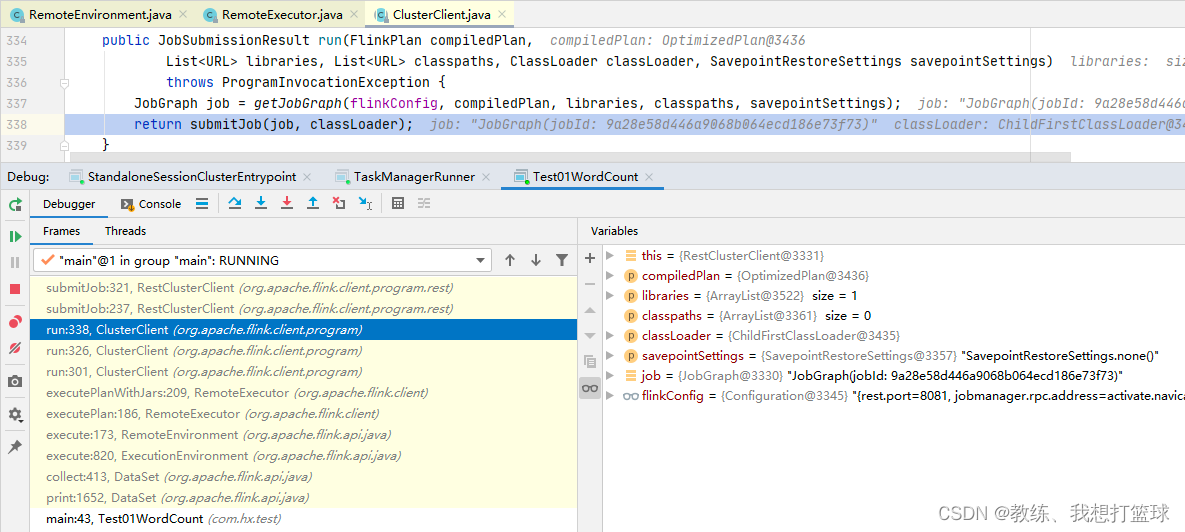
然后 提交的就是 JobGraph, 然后 等待集群响应结果信息
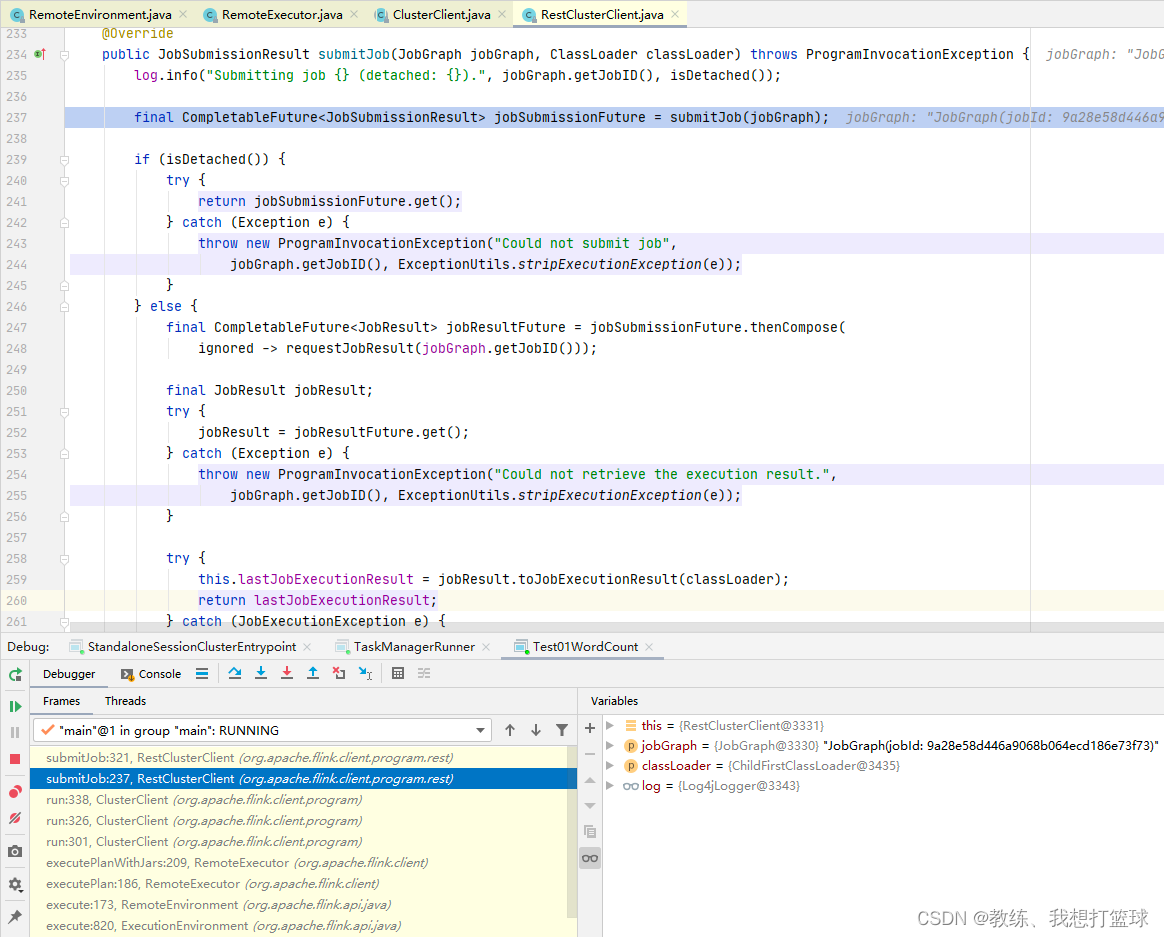
这里是将 JobGraph 序列化为 为一个临时文件, 然后提交给 flink 集群
然后 另外就是 job 这边需要使用的 jar 列表, 也需要提交给集群
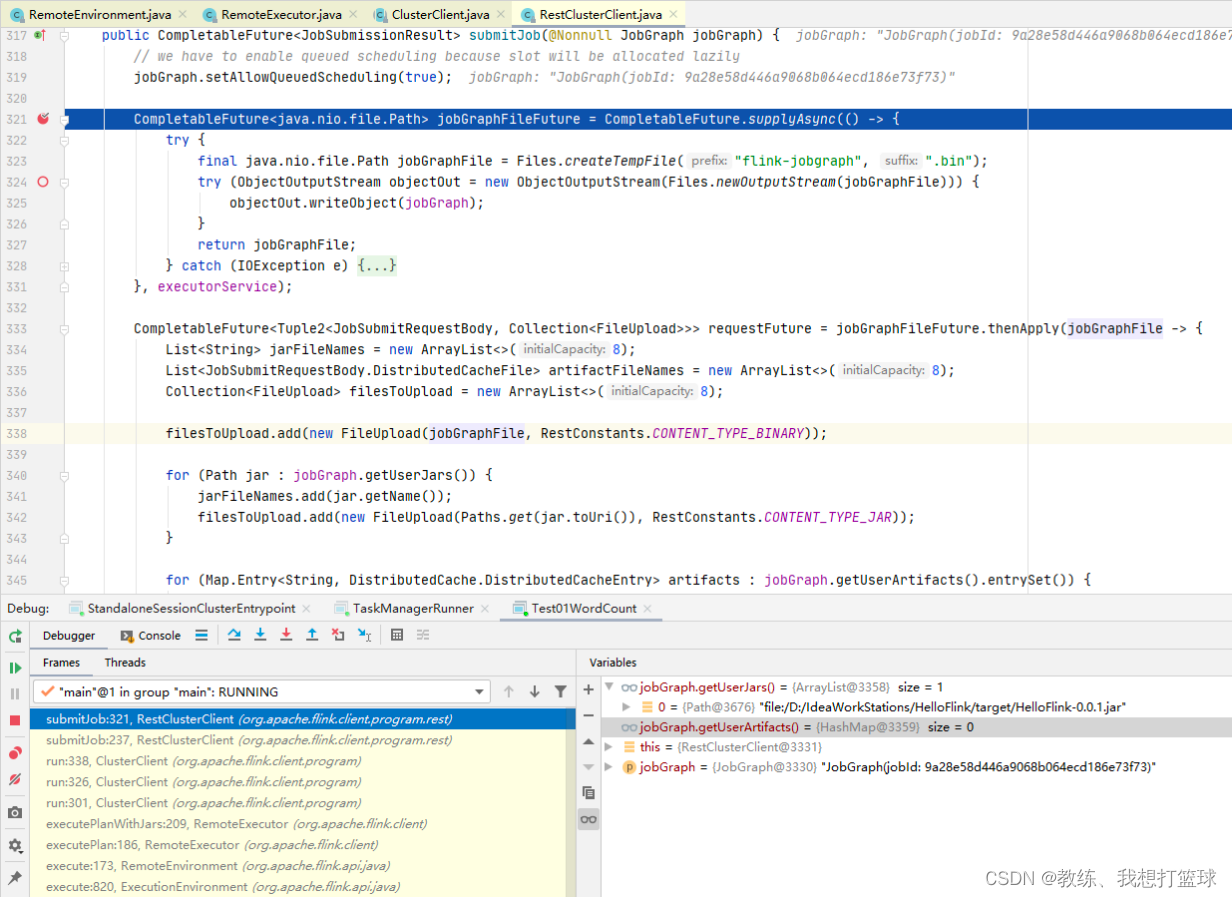
然后更详细的提交的请求内容如下, 合计传送了 47kb
然后传递的主要内容为 三部分
第一部分为元数据, 内容为 “{"jobGraphFileName": "flink-jobgraph126256148600228610.bin", "jobJarFileNames": ["HelloFlink-0.0.1.jar"], "jobArtifactFileNames": []}”
第二部分为 jobGraph 序列化之后的临时文件, “flink-jobgraph126256148600228610.bin”
第三部分为 job 执行需要的 jar 包, “HelloFlink-0.0.1.jar”
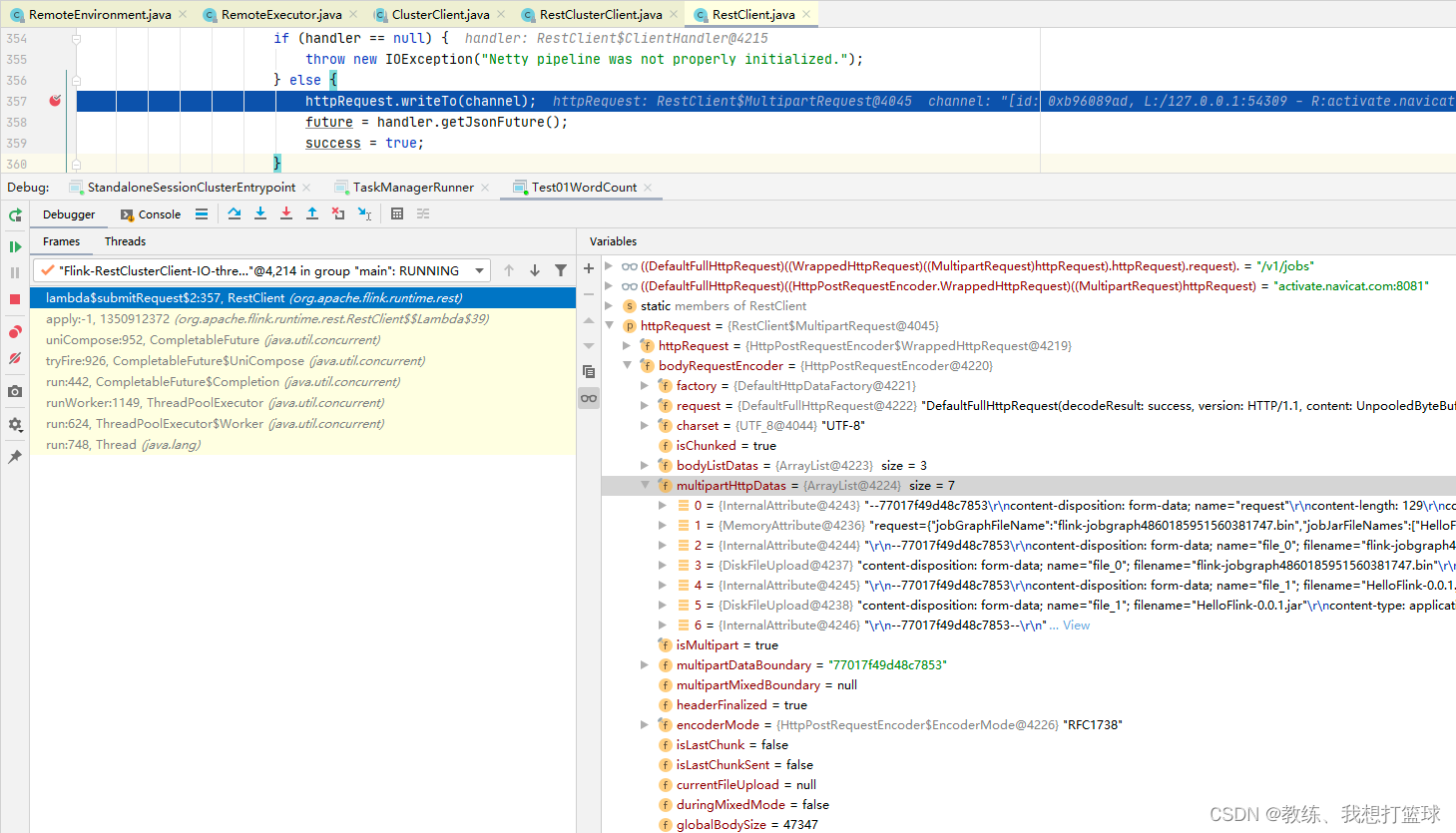
JobManager 这边的处理
JobManager 这边拿到如上 driver 这边提交的 HttpRequest 之后, 处理如下
根据 jobGraphFileName 反序列化 JobGraph, 上传 job 所需要的 jar 到 BlobServer
然后就是向 Dispatcher 提交 jobGraph
返回当前提交的 job 的相关信息, 主要是 jobId
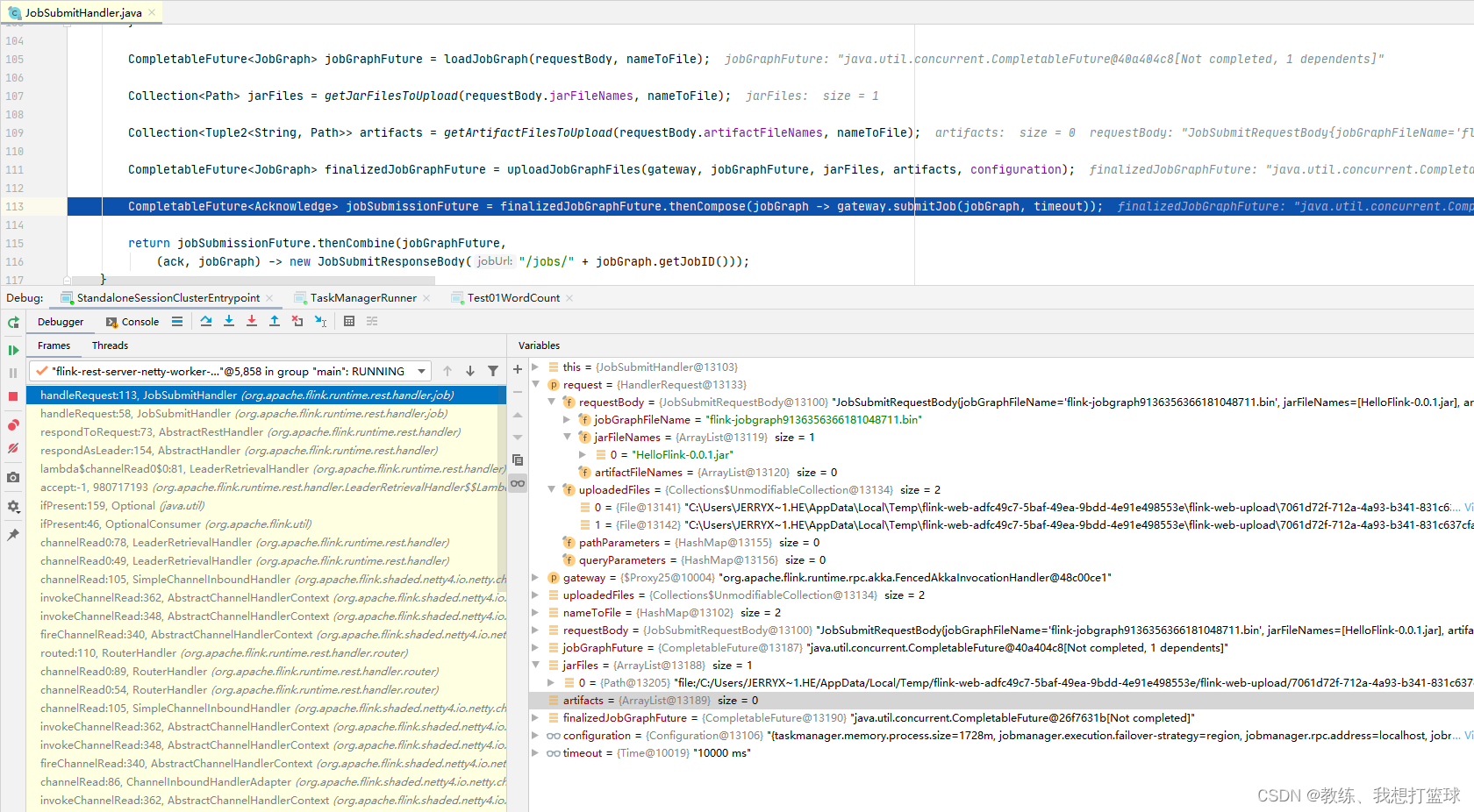
然后是 Dispatcher 这边 persistAndRunJob, 创建 JobManagerRunner, JobMaster
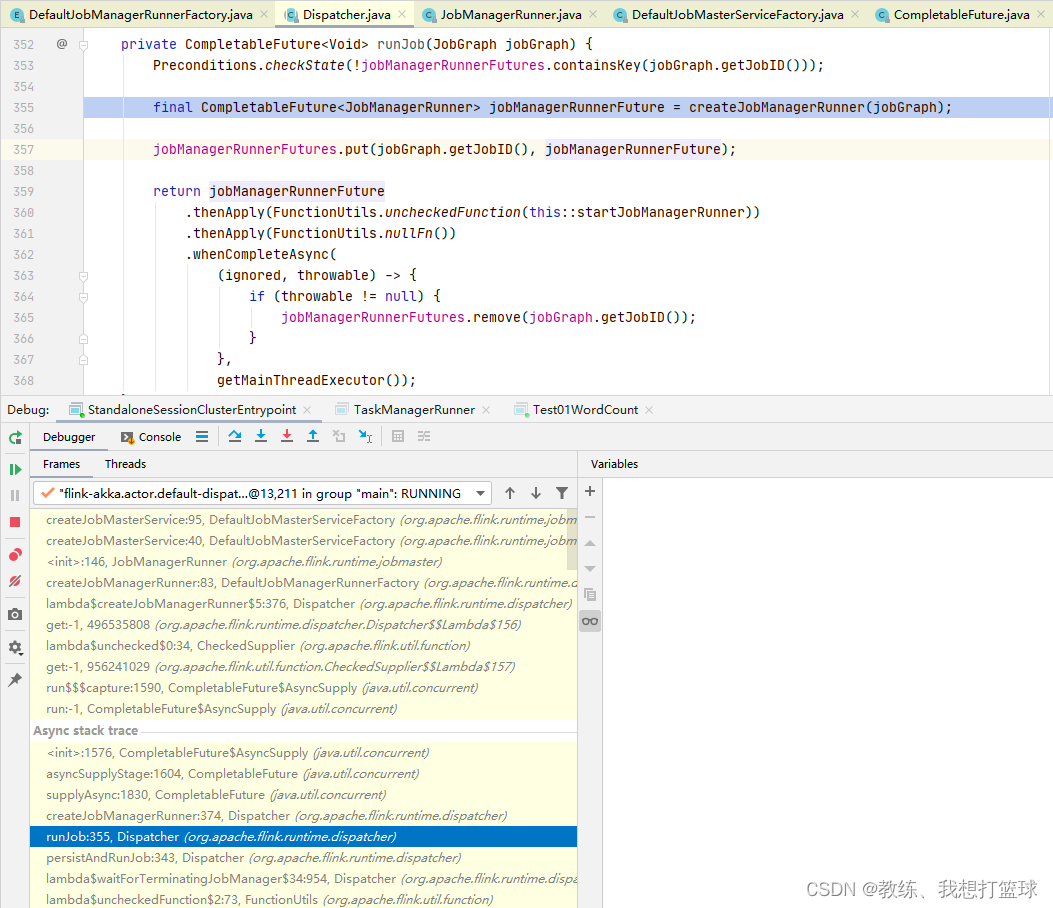
然后是 JobManagerRunner 启动 JobMaster
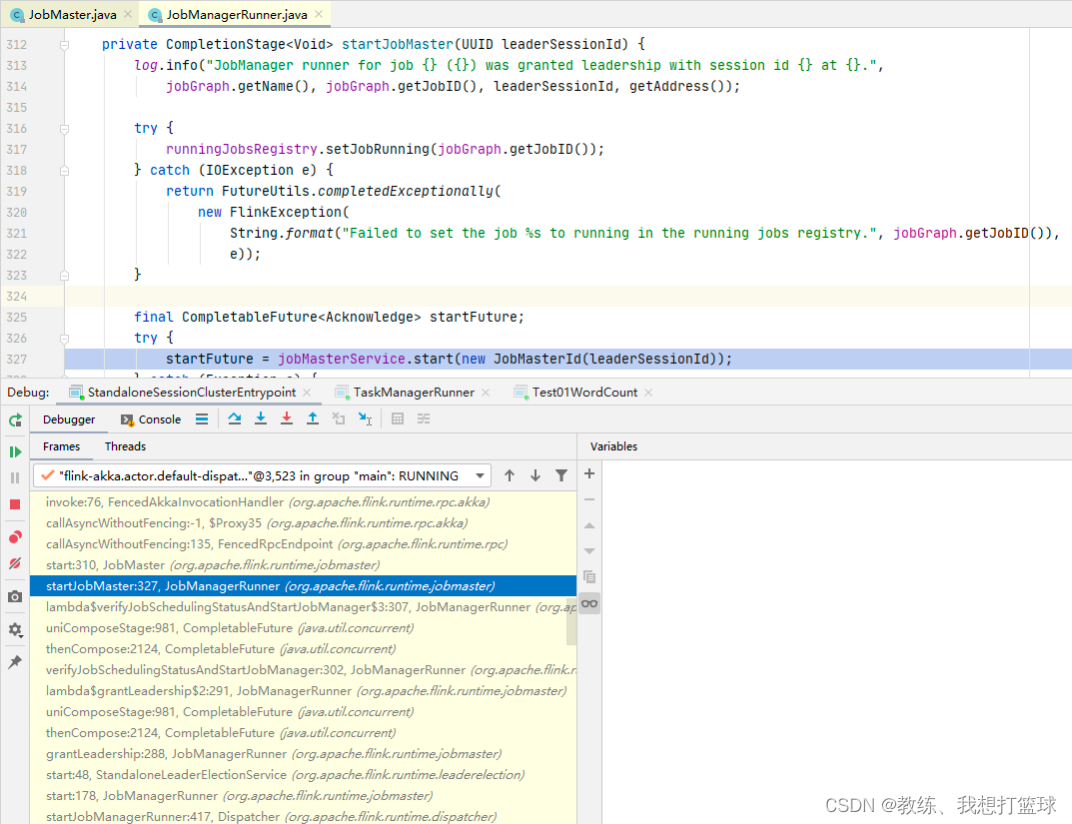
然后是 JobMaster 这边基于内部的 scheudlerNG 来开始调度任务
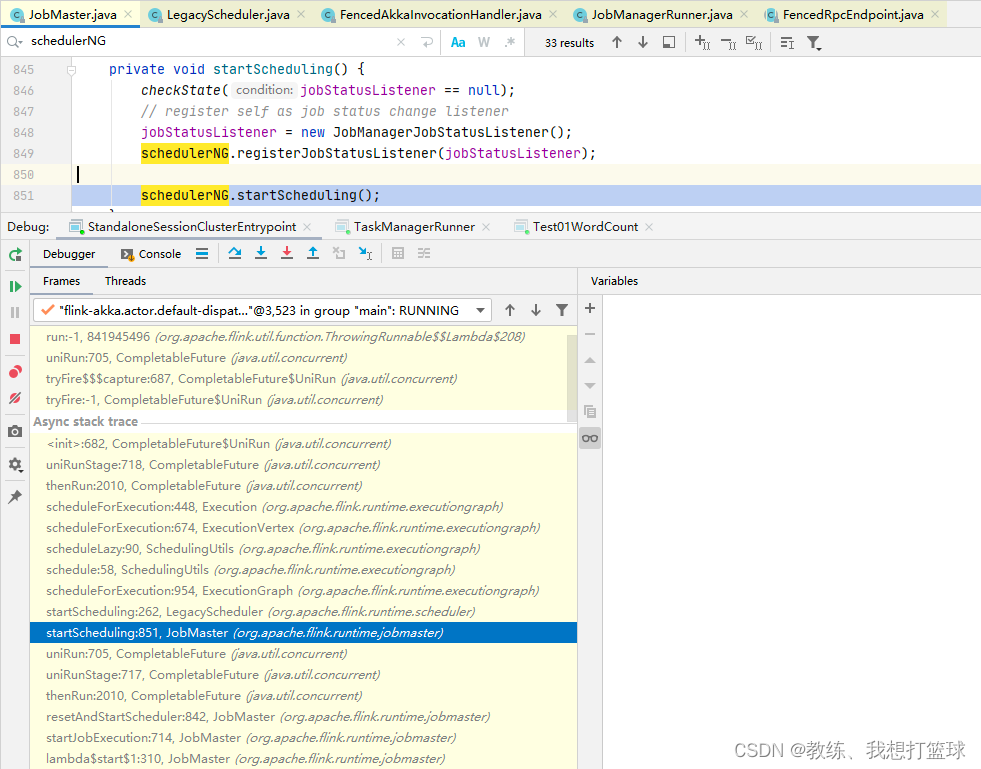
然后是根据 ExecutionVertex 封装 TaskDeploymentDescriptor, 然后 向 TaskManager 执行 job 拆解之后的任务
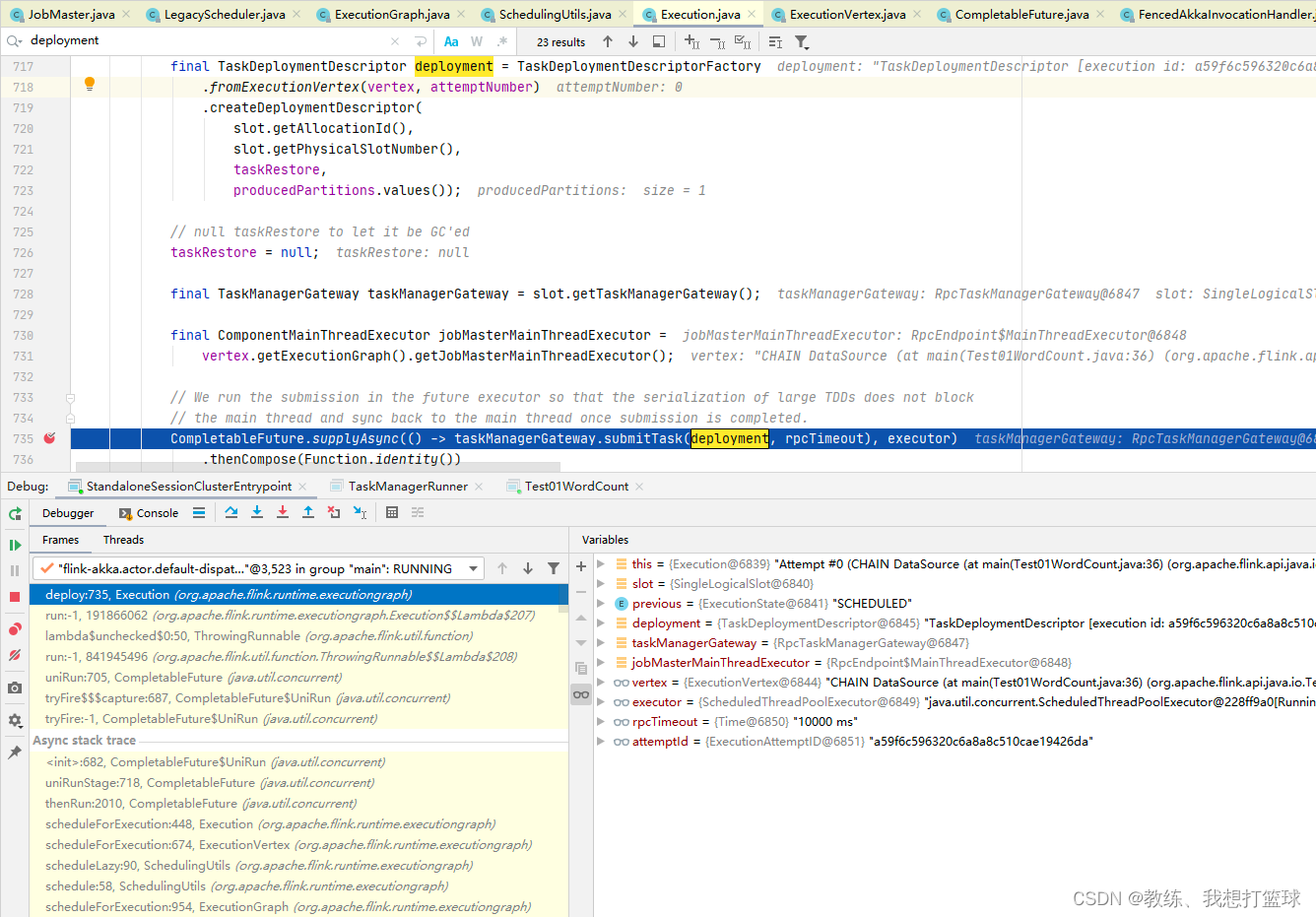
TaskManager 这边的处理
TaskExecutor 这边收到了 TaskDeploymentDescriptor 之后, 反序列化 jobInformation, taskInformation, 创建 Task, 然后执行 Task
这里可以从 taskInformation 的上下文信息, 可以看到当前 Task 属于哪一个 JobVertex, 以及改 JobVertex 总共有一个 SubTask, 以及当前 Task 是属于第几个 SubTask
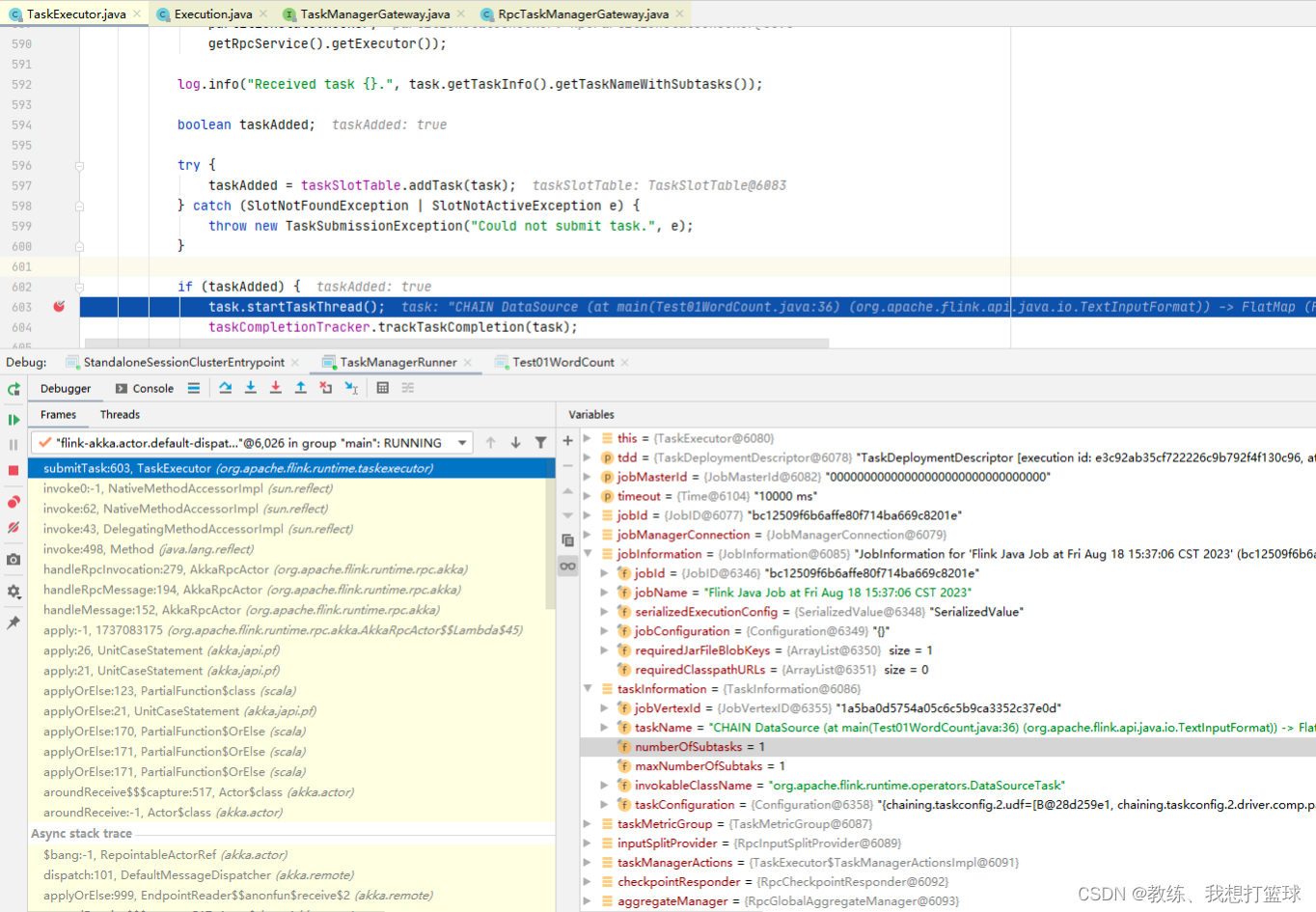
然后就是 Task 这边的执行
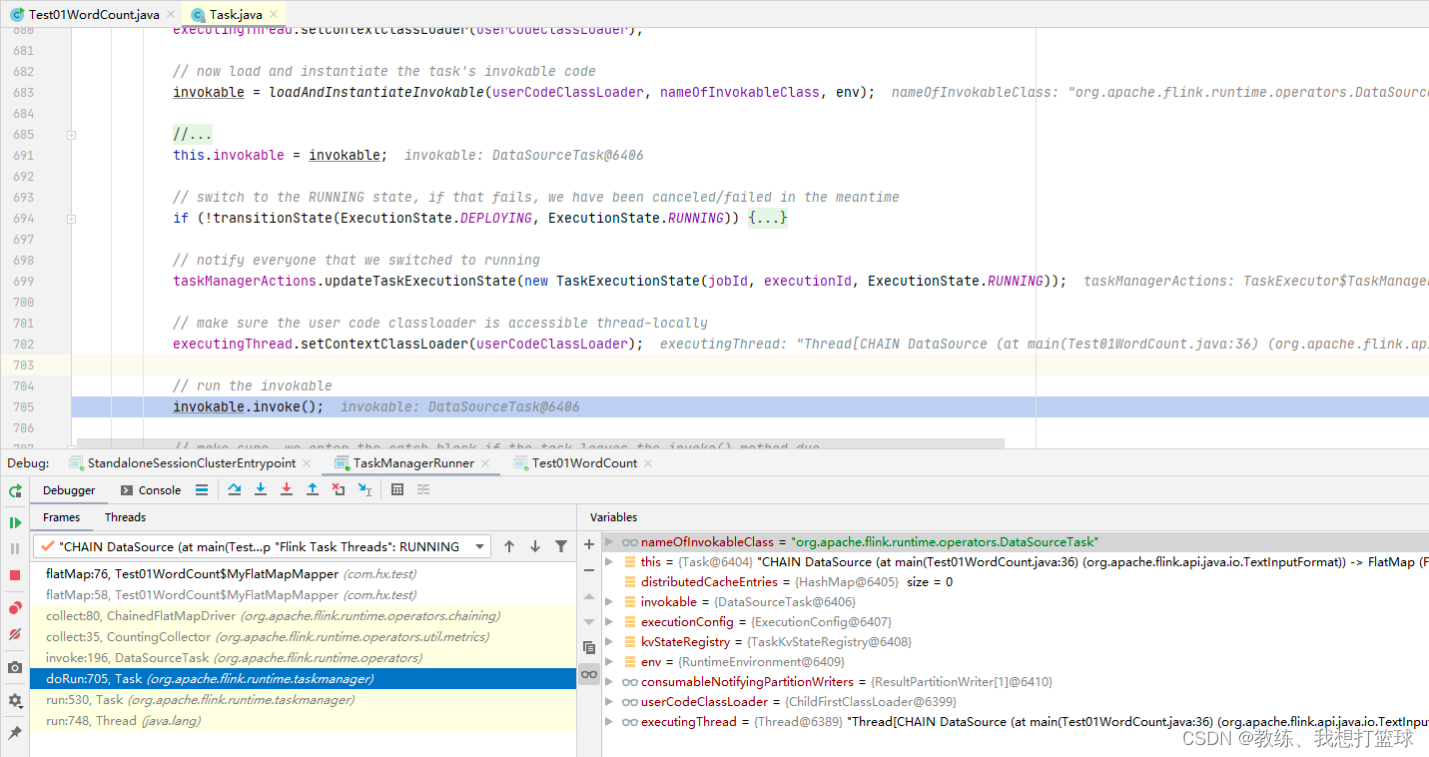
这边执行的就是基于 jar 包 和 DataSourceTask, ChainnedFlatMapDriver, ChainnedMapDriver 等等 来执行具体的业务处理
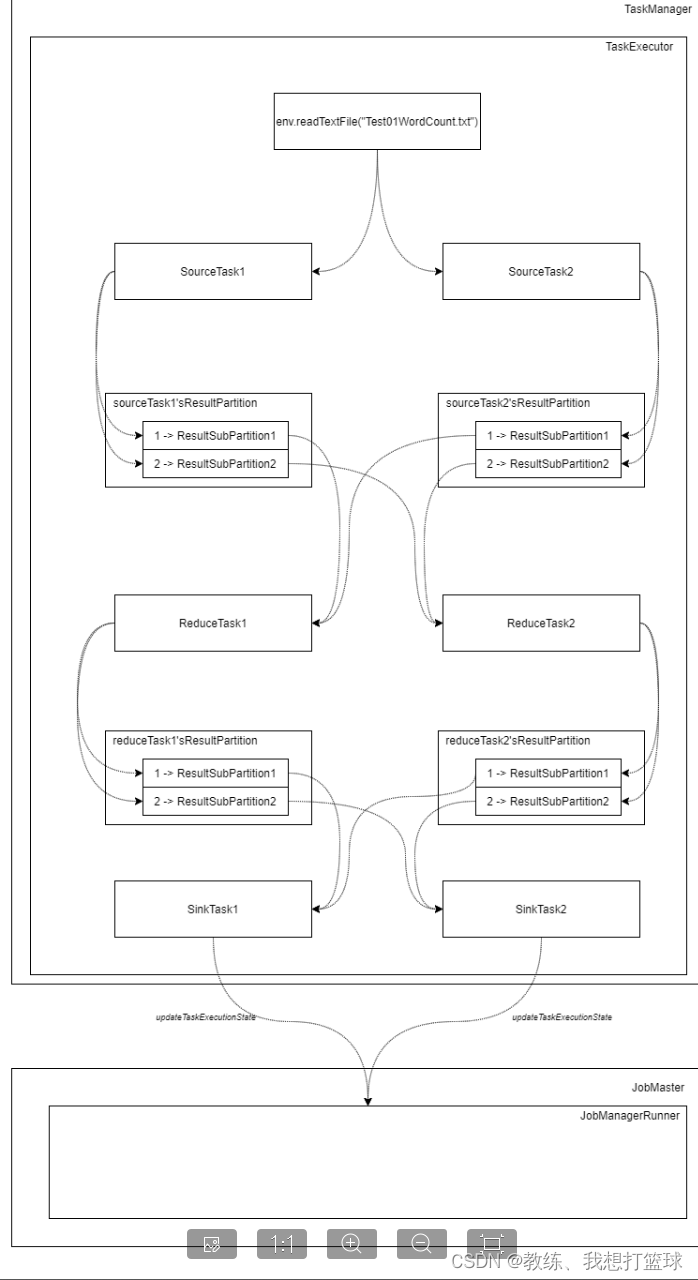
业务这边执行流程如下
DataSource 逐行读取 Test01WordCount.txt 中的字符串信息, 这里读取的是第一行 “123 234 456”
ChainedFlatMapDriver 这边是将一行的字符串转换为多行字符串, “123 234 456” 转换为 “123”, “234”, “456”
ChainedMapDriver 这边是将一个输入进行映射, 这里的是 “123” 转换为 (“123”, 1)
SynchronousChainedCombineDriver 这边是将到目前为止的结果, hash partition 之后输出到下游的 SubTask
SynchronousChainedCombineDriver 这边先是将记录写入到 sorter, 然后 close的时候, 在迭代记录将记录输出到下游
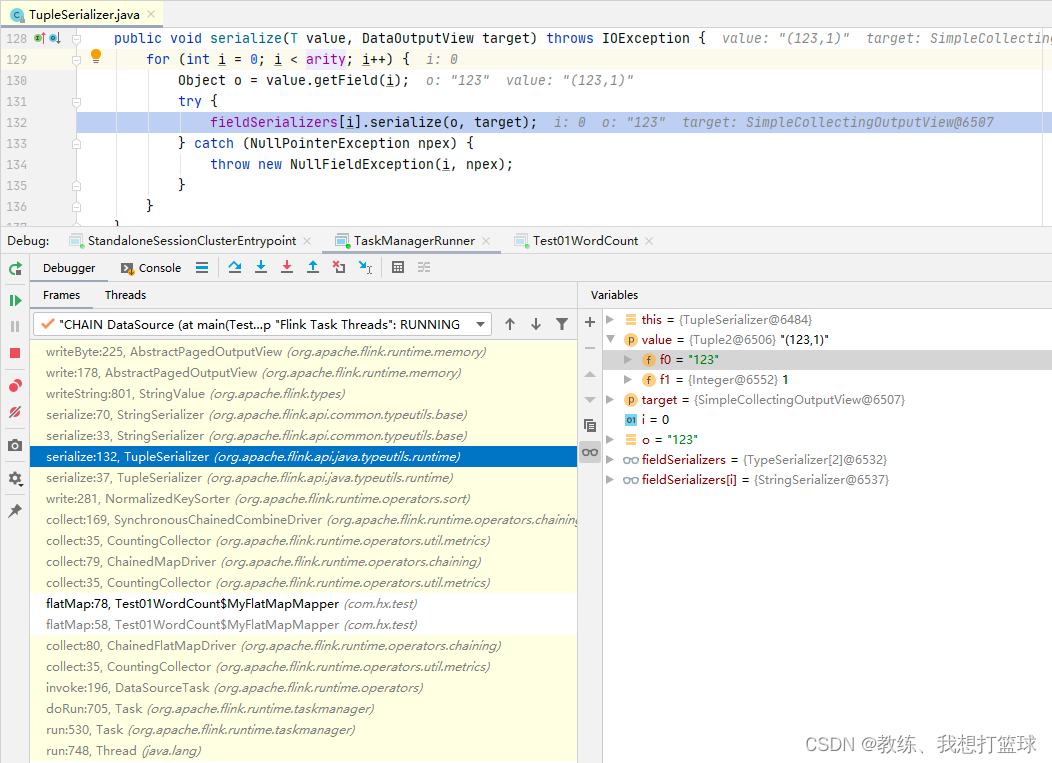
输出当前 Task 的各个记录的地方
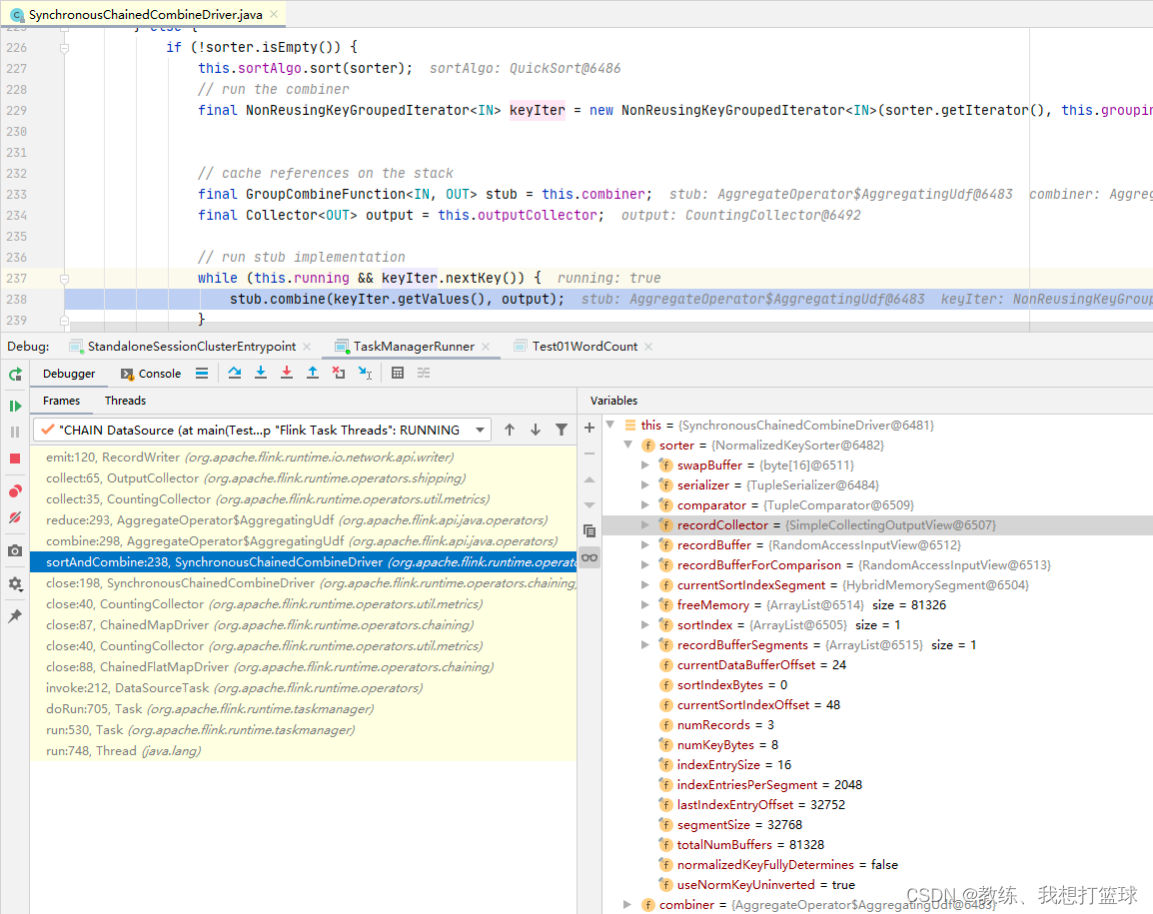
repartition 的地方
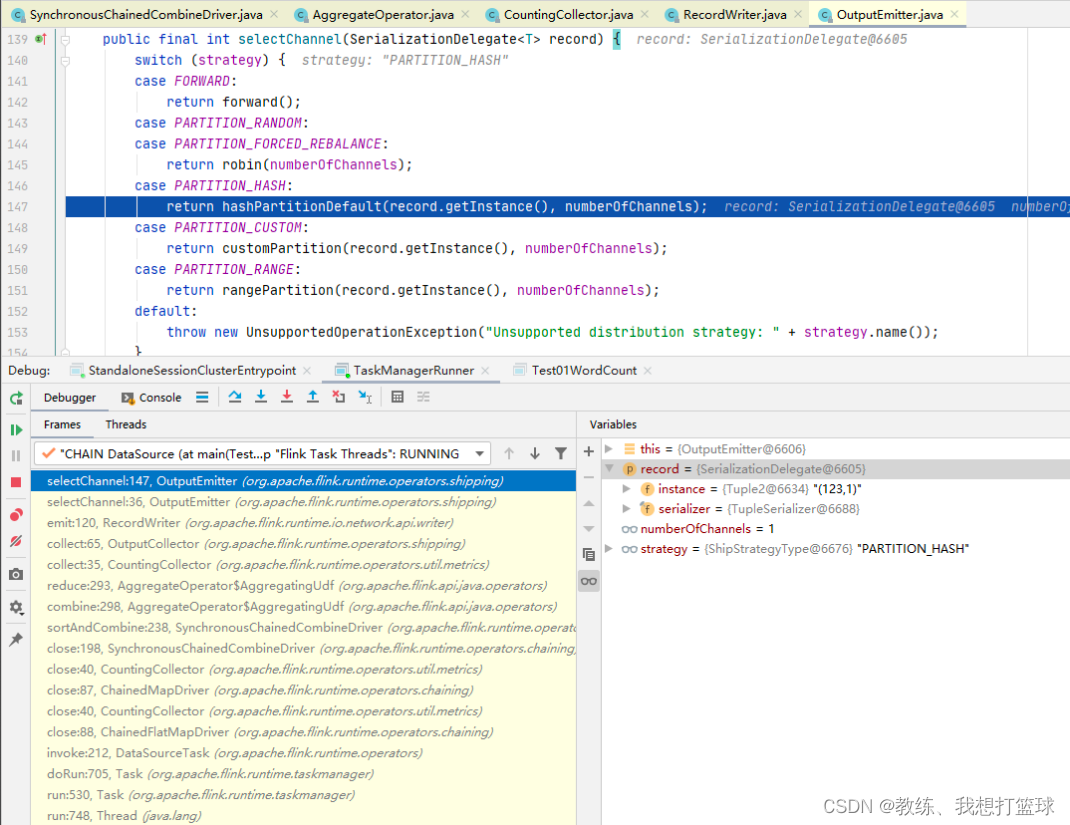
每一个 partition 的数据是写出到 RecordWriter 下面的 ReleaseOnSonsumptionResultPartition 下面的 subpartitions[partitionIndex]
然后这部分 ResultPartition 数据是维护在 ResultPartitionManager, 这个是每一个 TaskExecutor 维护一个 ResultPartitionManager 用于相同的任务之间的不同的 SubTask 的数据交互
所以说一个 SubTask 维护了一个 ReleaseOnSonsumptionResultPartition, 然后维护了 parallelism 个 subpartitions
然后下游的 SubTask 依次来遍历上游的 SubTask, 获取当前 SubTask 需要读取的 subpartitions[index] 来作为输入
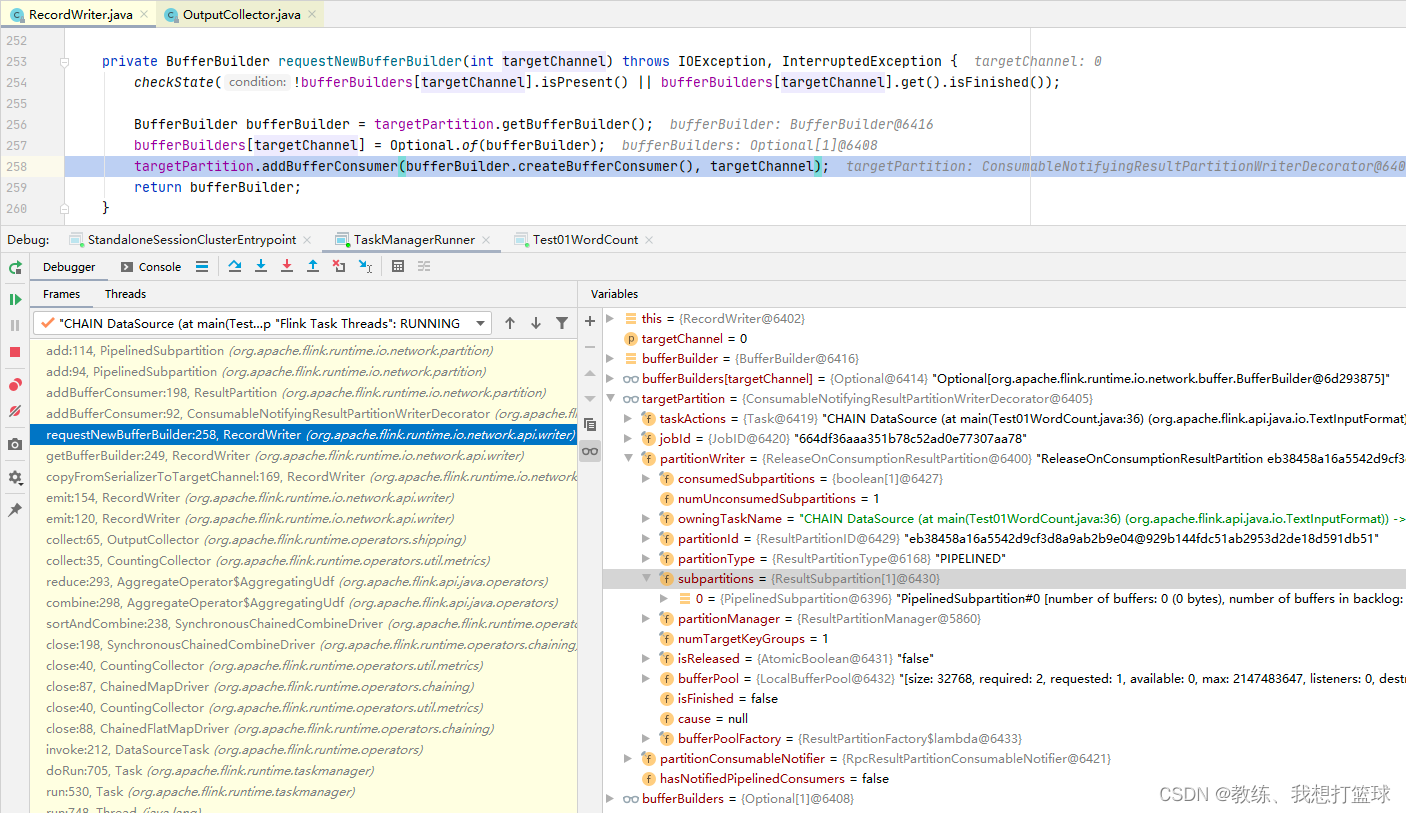
输出一条记录之后信息如下, bufferBuilder 中输出了 12 字节, 前面四个字节为长度标记 0x04 长度为 4
然后接下来 8个字节为 ”0431323300000001”, 表示的是 “123” + 1, 最前面的 0x04 表示 0x03 + 1[参见 StringValue.writeString]
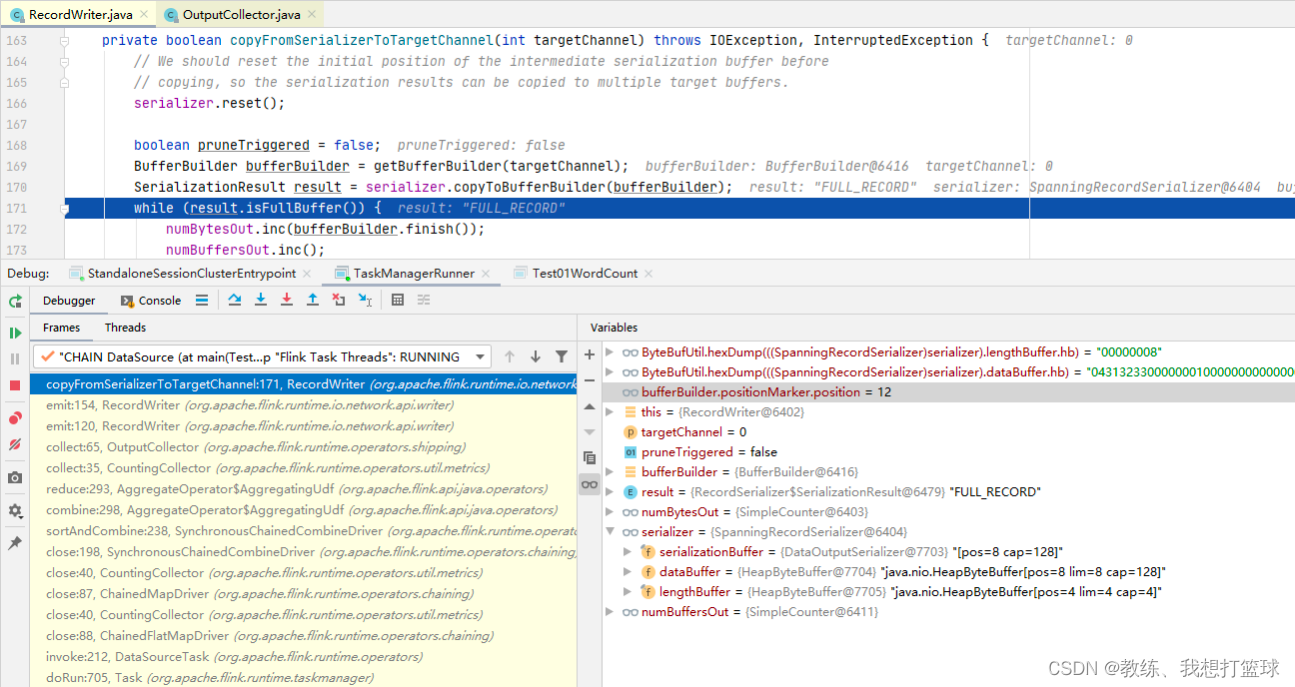
然后下游的 SubTask 这边读取的是上游的 N 个 SubTask 中的当前 subpartitionIndex 部分的输出, 这里的 partitionId 为上游输入 SubTask 的 partitionId
这里当前 SubTask 会对应 parallelism 个 InputChannel, 每一个分别关联上上游 SubTask 的输出
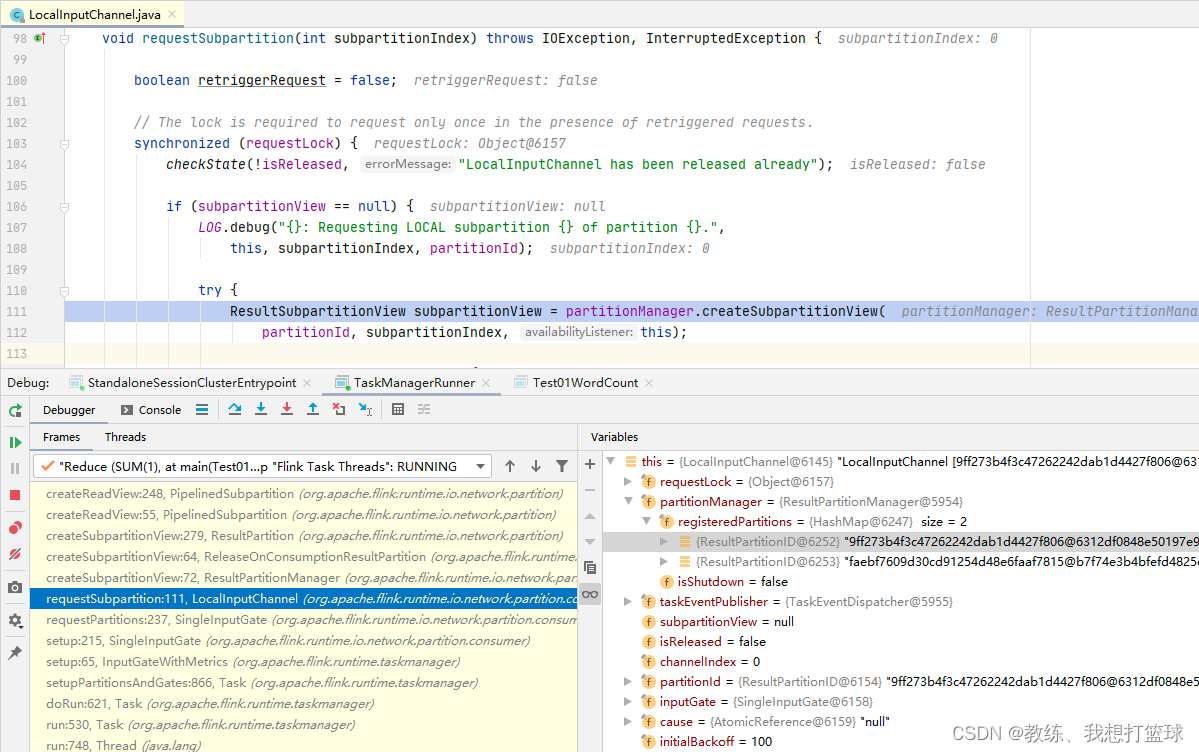
各个 SubTask 的数据交互
上游任务启动的时候, 会向 PartitionManager 注册输出的 ResultPartition 的信息
然后这里的 partition.getPartitionId 是来自于当前 SubTask 的 partition, 每一个 SubTask 单独生成一个
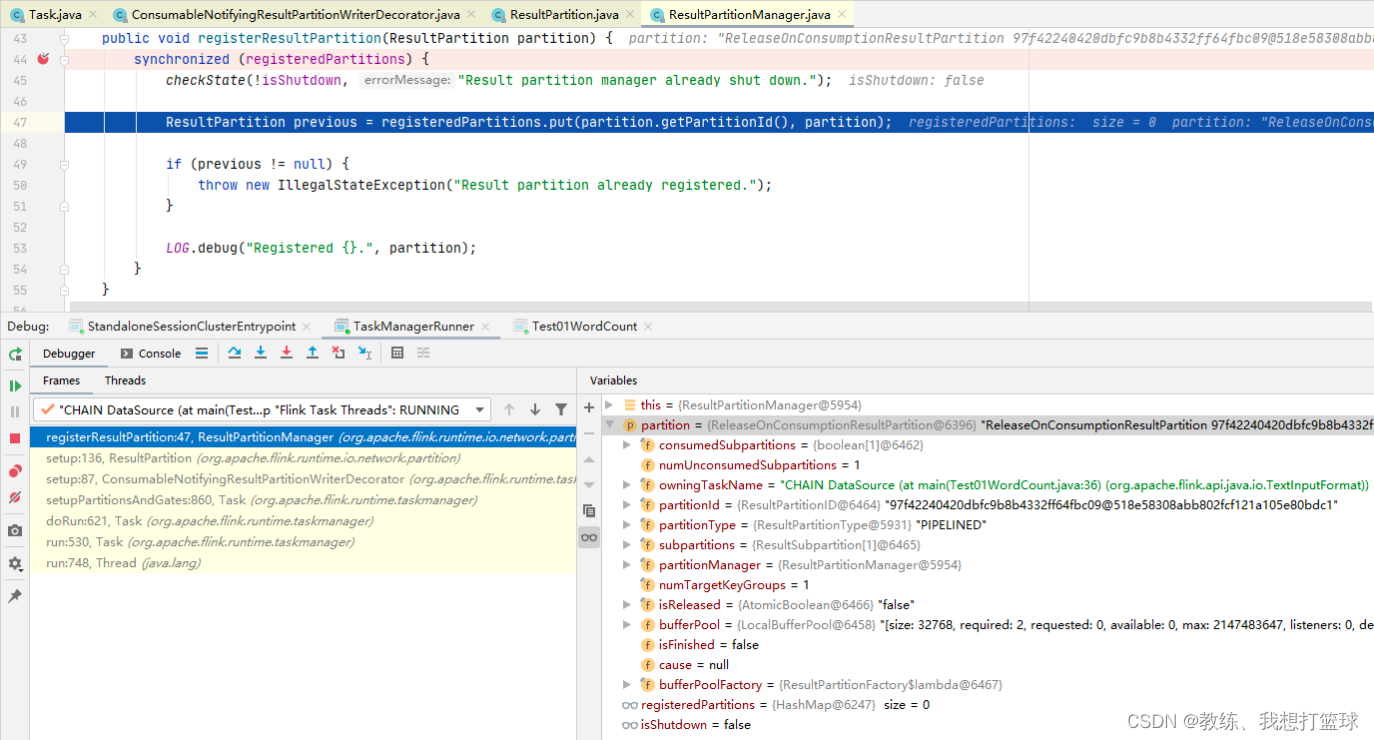
在 TaskManager 这边传递过程如下, TaskDeploymentDescriptor.producedPartitions.shuffleDescriptor.resultPartitionID -> ReleaseOnConsumptionResultPartition -> ResultPartition
然后再到 后面的 ResultPartition.setup 的向 PartitionManager 注册
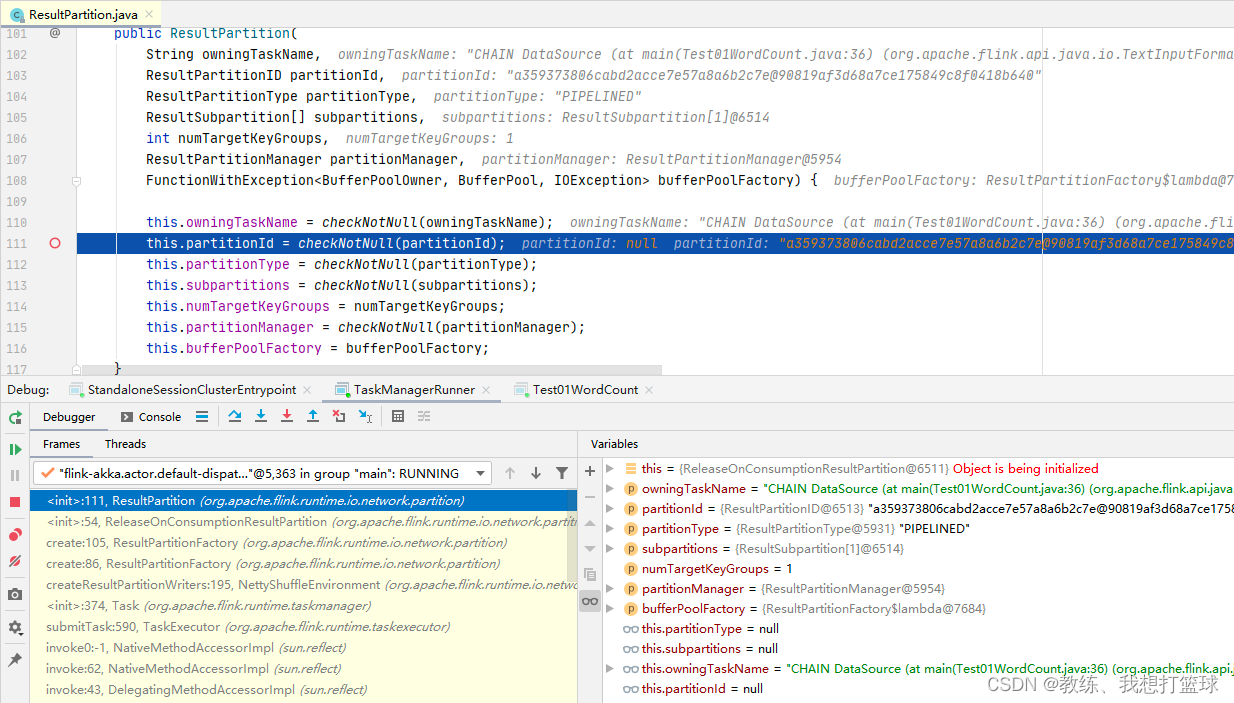
然后 JobManager 这边是生成这个 shuffleDescriptor 相关, 传递流程如下
IntermediateResultPartition -> Vertex.resultPartitions -> Partition -> PartitionDescriptor -> NettyShuffleDescriptor
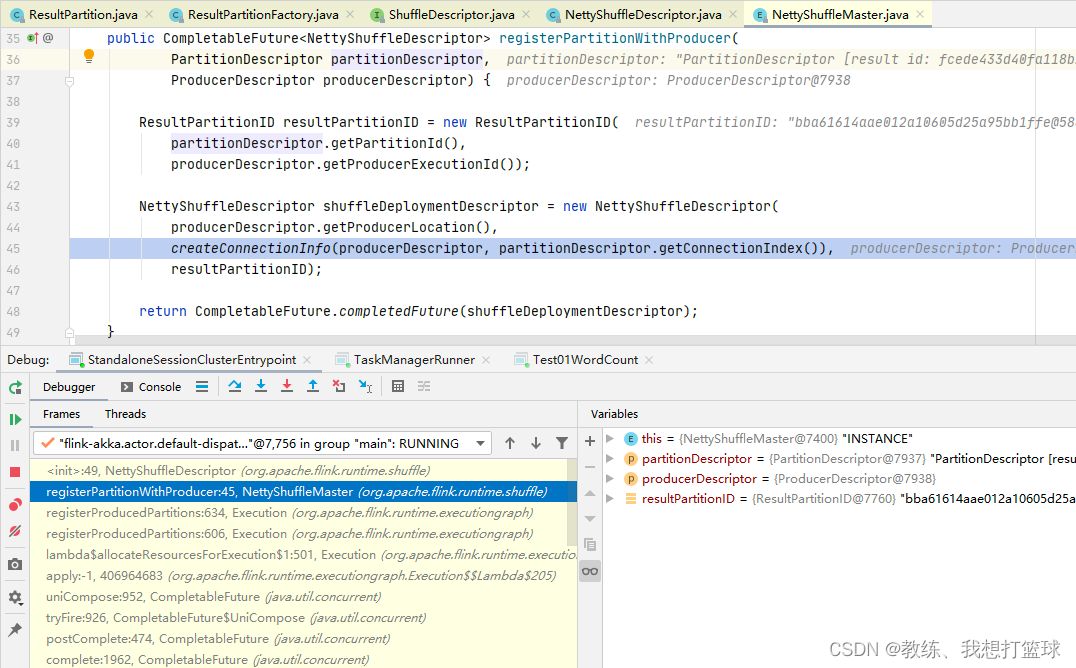
然后 Vertex.resultPartitions 这边初始化如下, 里面的组合了一个 IntermediateResultPartition, 它的 partitionId 是传递到后面 NettyShuffleDescriptor 的 partitionID, 然后这个 partitionId 是随机生成的
根据上下文来看, 就是每一个 SubTask 一个
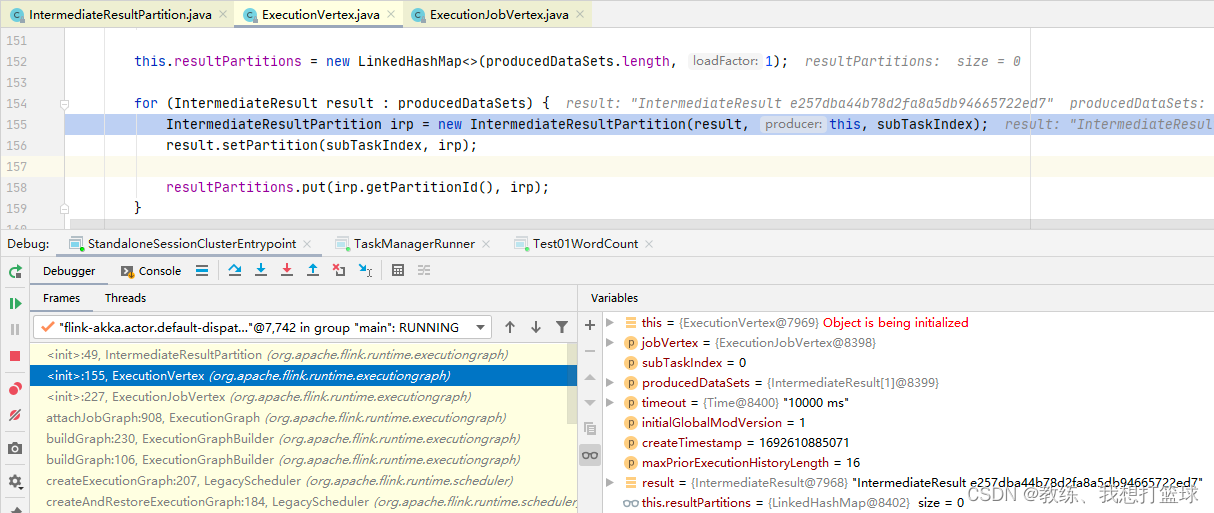
然后我们看一下 下游的 SubTask 这边来消费上游的 SubTask 的处理, 这里获取的是 InputChannel 的 partitionId
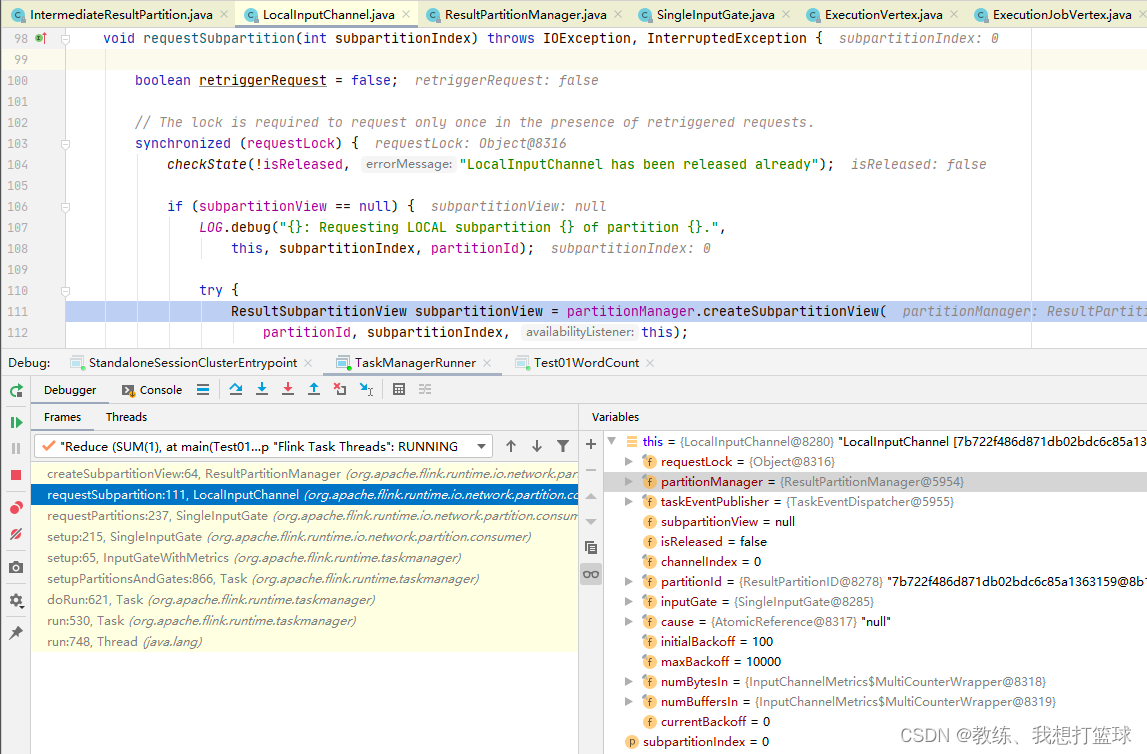
InputChannel 的 partitionId 是来自于上游的 inputChannelDescriptor.partitionId, 这样就把整个流程串联起来了
下游的 SubTask 可以读取到所有上游SubTask 的结果信息
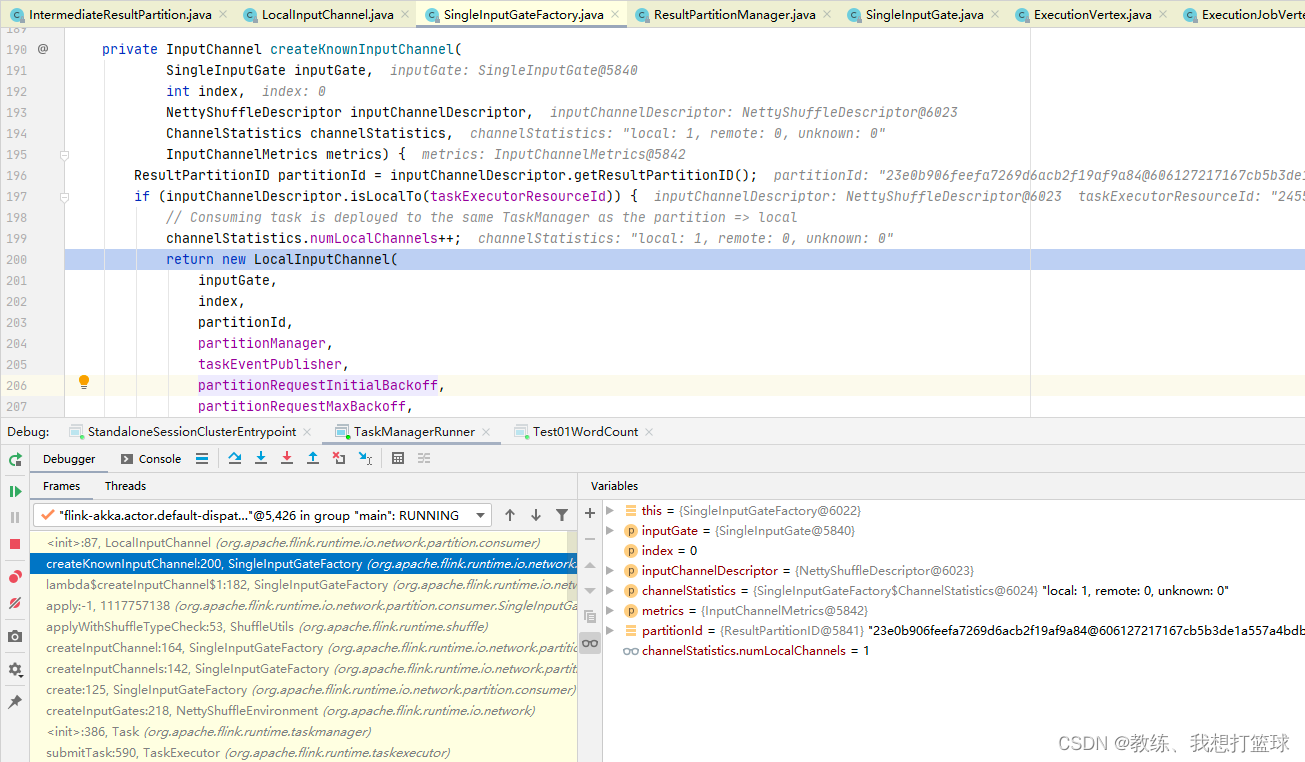
各个 Task 执行的通知
Task 和 Task 之间是有依赖关系的, 下游的 Task 相对于 上游的Task 称之为 consumers
当上游的 Task 有数据提交到之后, 这里会通知到 JobMaster 通知 partitionId 已经在产出数据了
然后 jobMaster 通知该 Task 的下游的 Task 开始执行
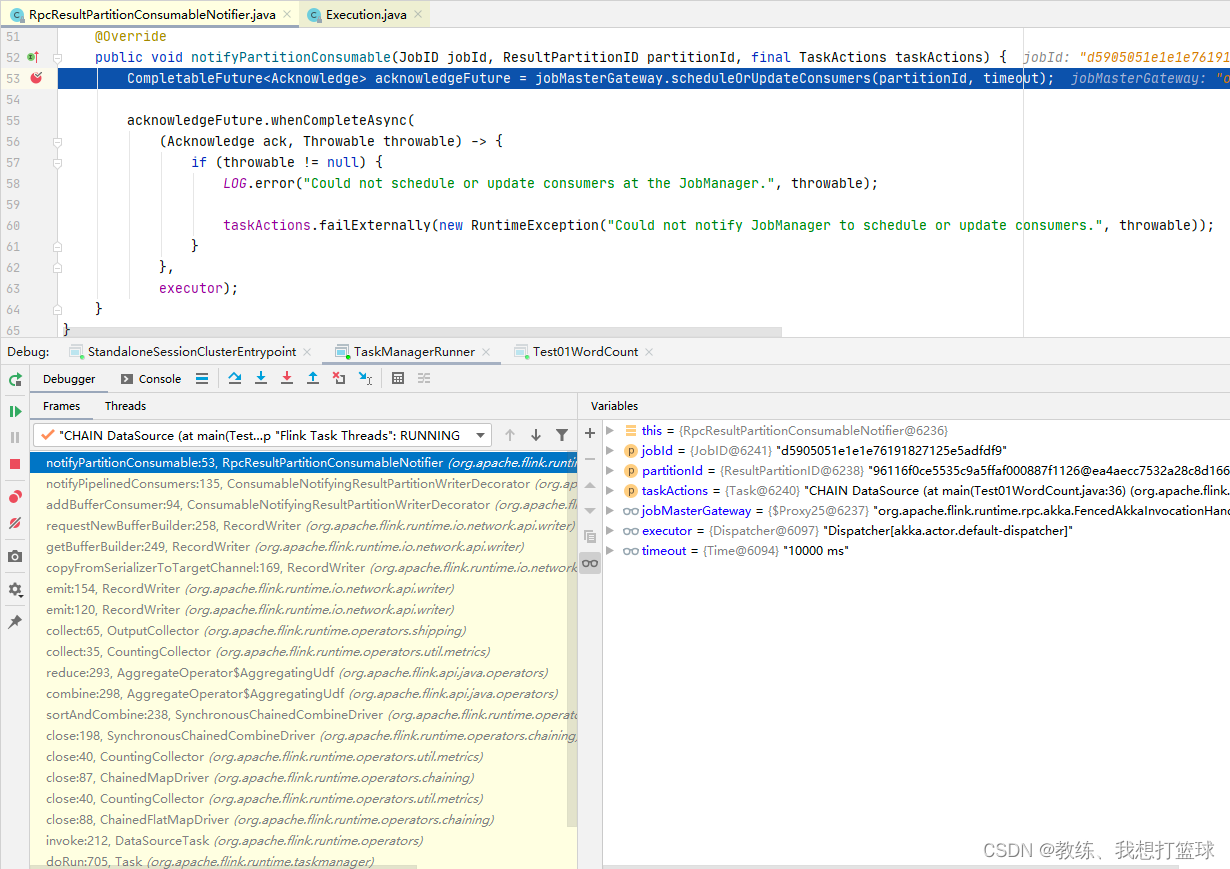
然后 JobMaster 这边收到 scheduleOrUpdateConsumers 之后的处理如下
开始 调度下游的 consumers, 即下游的 SubTask 开始申请资源, 然后 执行 等等
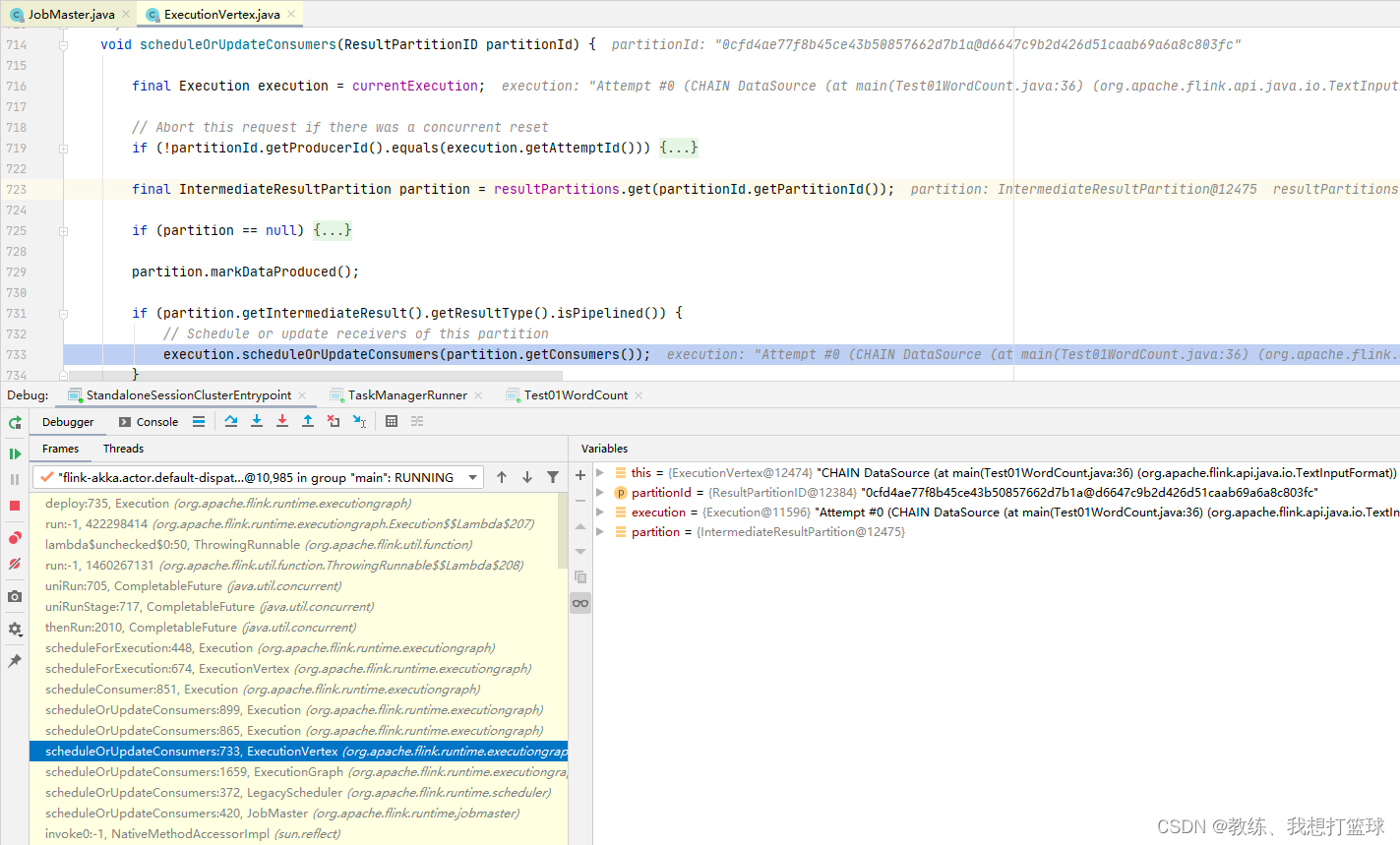
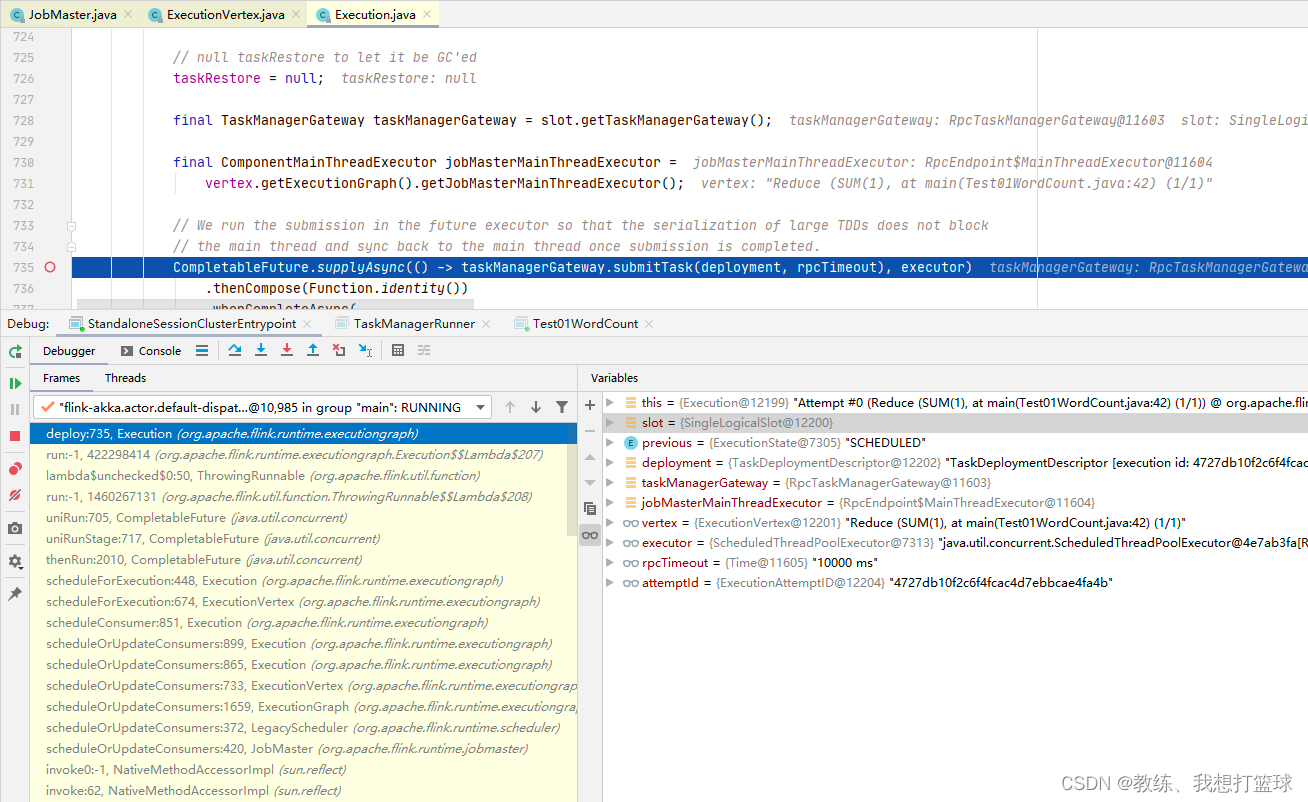
计算结果的交互
首先是 driver 这边
Job 提交了之后, 会执行 requestJobResult, 这里面是向 JobManager 这边发送 http 请求, 获取 给定的 Job 的执行结果
发送的 http 请求如下, 请求的是 “/v1/jobs/682debfc2ac22e73847c23b1953343e1/execution-result”
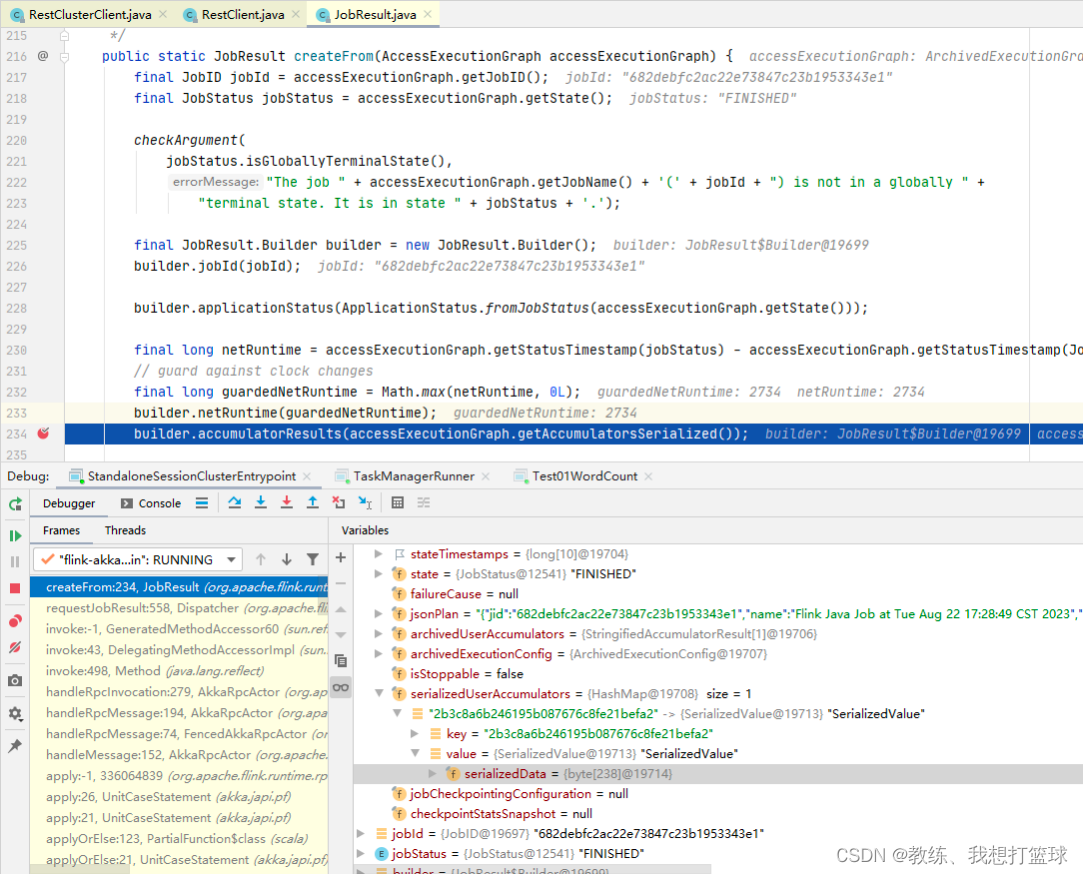
然后 JobMaster 这边的处理如下, 我们这里 需要关注的是 这个 accumulatorResults, 这里面暂存的我们计算的结果
然后这个 accumulatorResults 的数据来自于各个 Task 执行完成之后通知到 JobMaster 这边的 accumulators
如下图 这里是 Task 执行完成之后提交更新任务执行状态的请求到 JobMaster, state 中携带了 accumulators

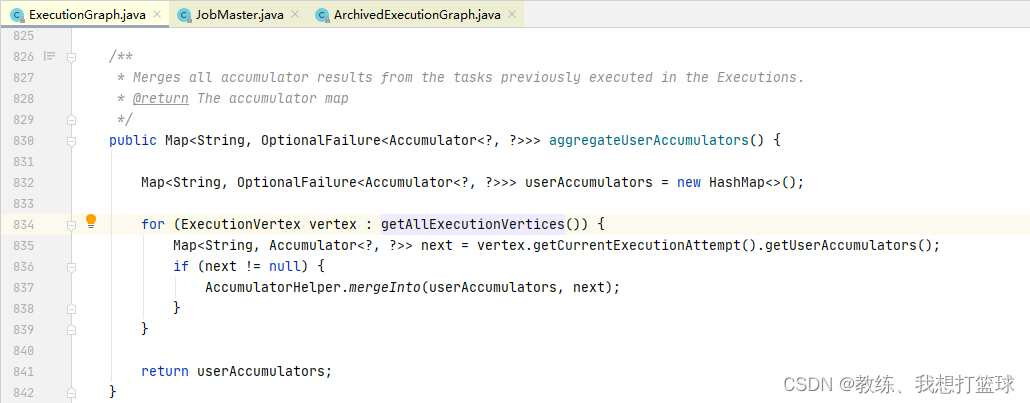
接下来是封装 ArchivedExecutionGraph, 这里封装的 accumulators 是使用的各个 Task 执行完成之后响应的 accumulators
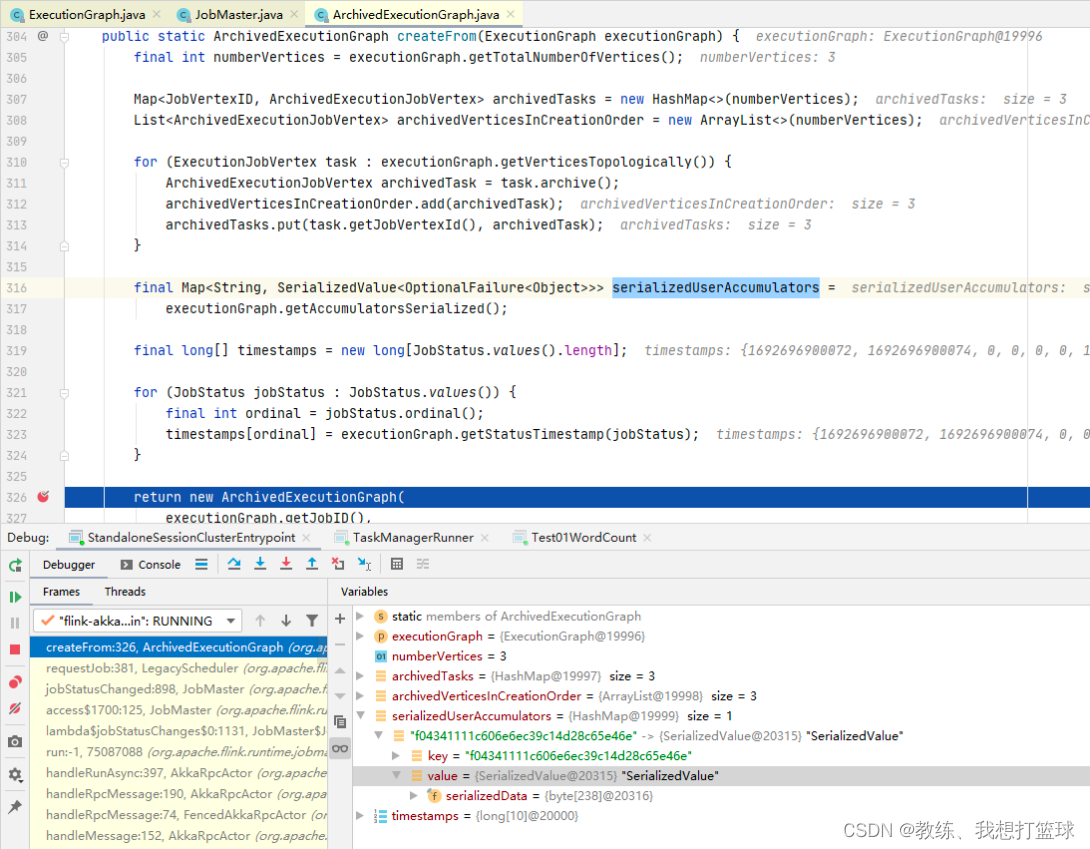
然后 executionGraph.getAccumulatorsSerialized 遍历的基础 accumulatos 是来自于如下, 可以看到的是遍历的当前执行计划的所有的 Vertex 的 accumulators
然后 结合上上一张图可以看到的是 这里是从 vertex.attempt 中获取的数据, 然后 vertex.attempt 的数据是来自于 ExecutionGraph.updateStateInternal
然后外层 JobMaster.jobStatusChanged 将这上面生成的 ArchivedExecutionGraph 设置到了 JobManagerRunner.resultFuture 中
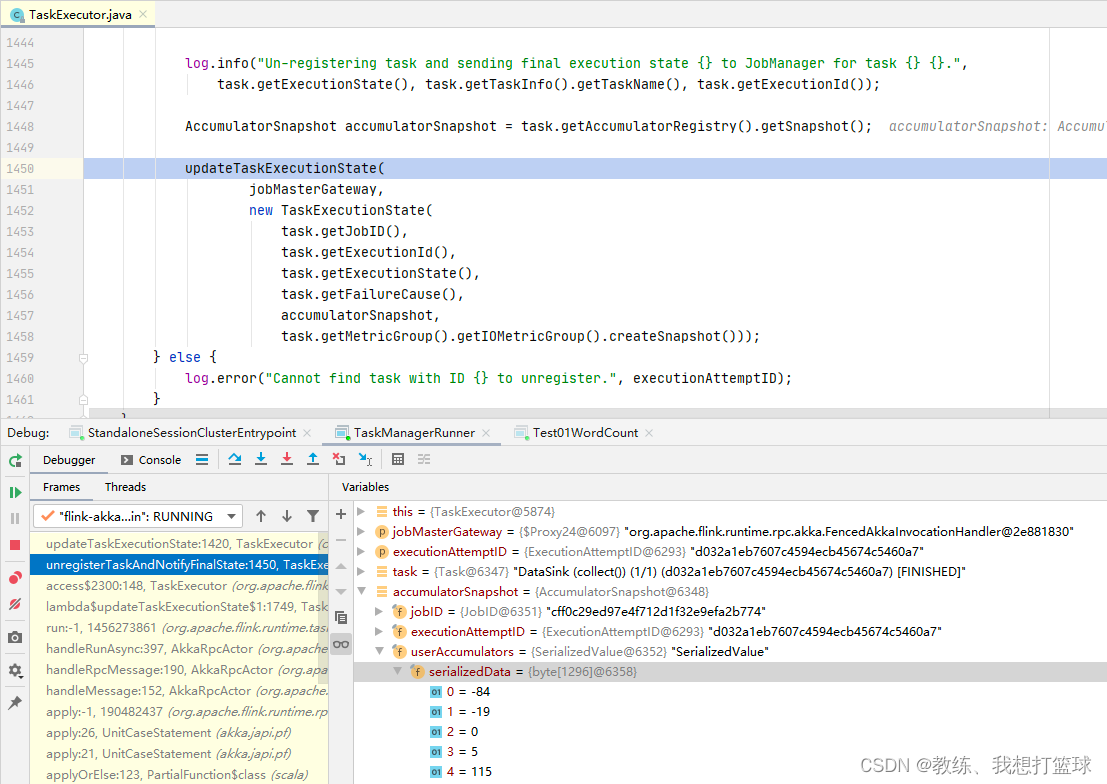
Task 这边, 任务执行完成之后, 将 accumulators 封装到 TaskExecutionState, 然后响应给 JobMaster
完