文章目录
- 一、什么是 Parquet
- 二、实现 Java 读写 Parquet 的流程
- 方式一:
- 遇到的坑:
- 坑1:ClassNotFoundException: com.fasterxml.jackson.annotation.JsonMerge
- 坑2:No FileSystem for scheme "file"
- 坑3:与 spark-sql 的引入冲突
- 方式二:
一、什么是 Parquet
Parquet 是一种列式存储格式,用于高效地存储和处理大规模数据集。它被广泛应用于大数据处理和分析场景中,例如 Apache Hadoop、Apache Spark 等。
与传统的行式存储格式(如CSV和JSON)相比,Parquet 能够显著提高读写性能和存储效率。它将数据按列进行存储,而不是按行存储,这样可以更好地利用存储空间,减少 I/O 开销,并提供更高的压缩比。
二、实现 Java 读写 Parquet 的流程
方式一:
Maven 依赖:
<dependency><groupId>org.apache.parquet</groupId><artifactId>parquet-avro</artifactId><version>1.12.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.3.1</version></dependency>
[root@local~]# vim schema.avsc
{"type": "record","name": "User","fields": [{"name": "field1","type": "string"}, {"name": "field2","type": "int"}]
}
import org.apache.avro.Schema;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericRecord;
import org.apache.hadoop.fs.Path;
import org.apache.parquet.avro.AvroParquetWriter;
import org.apache.parquet.hadoop.ParquetWriter;
import org.apache.parquet.hadoop.metadata.CompressionCodecName;import org.apache.parquet.avro.AvroParquetReader;
import org.apache.parquet.hadoop.ParquetReader;import java.io.File;
import java.io.IOException;public class WriteToParquet {public static void main(String[] args) {try {// 创建Schema对象Schema schema = new Schema.Parser().parse(new File("schema.avsc"));// 方式二:不需要读文件// Schema schema = new Schema.Parser().parse("{\"type\":\"record\",\"name\":\"User\",\"fields\":[{\"name\":\"field1\",\"type\":\"string\"},{\"name\":\"field2\",\"type\":\"int\"}]}");// 创建GenericRecord对象GenericRecord record = new GenericData.Record(schema);record.put("field1", "value1");record.put("field2", 123);// 创建ParquetWriter对象ParquetWriter<GenericRecord> writer = AvroParquetWriter.<GenericRecord>builder(new Path("output.parquet")).withSchema(schema).withCompressionCodec(CompressionCodecName.SNAPPY).build();// 将数据写入Parquet文件writer.write(record);// 关闭ParquetWriterwriter.close();// 创建ParquetReader对象ParquetReader<GenericRecord> reader = AvroParquetReader.<GenericRecord>builder(new Path("output.parquet")).build();// 读取Parquet文件中的数据// GenericRecord record;while ((record = reader.read()) != null) {// 处理每一条记录System.out.println(record.get("field1"));System.out.println(record.get("field2"));}// 关闭ParquetReaderreader.close();} catch (IOException e) {e.printStackTrace();}}
}
[root@local~ ]# java -cp /huiq/only-maven-1.0-SNAPSHOT-jar-with-dependencies.jar WriteToParquet
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
log4j:WARN No appenders could be found for logger (org.apache.htrace.core.Tracer).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
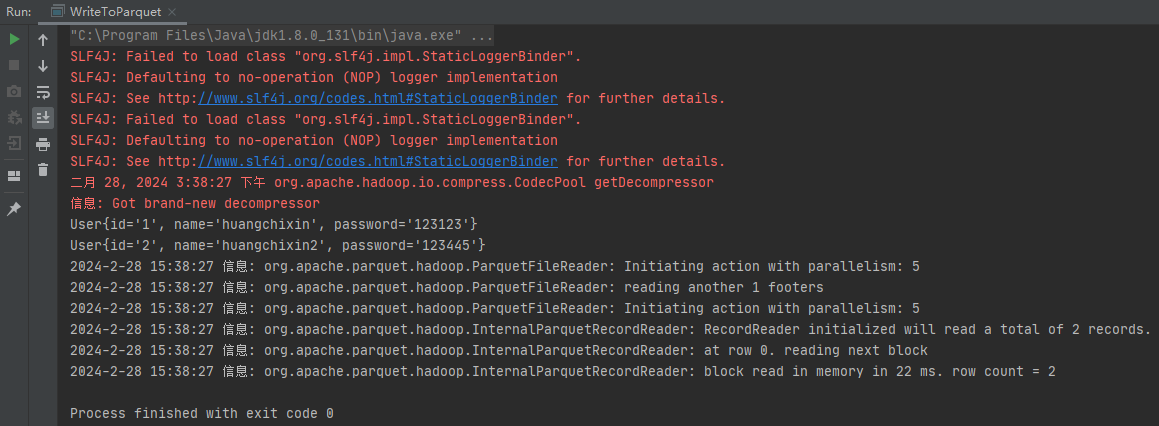
value1
123[root@local~ ]# ll -a
-rw-r--r-- 1 root root 51783396 Feb 27 17:45 only-maven-1.0-SNAPSHOT-jar-with-dependencies.jar
-rw-r--r-- 1 root root 615 Feb 27 17:45 output.parquet
-rw-r--r-- 1 root root 16 Feb 27 17:45 .output.parquet.crc
-rw-r--r-- 1 root root 147 Feb 26 17:24 schema.avsc
参考:
java写parquet
java parquet AvroParquetWriter
遇到的坑:
坑1:ClassNotFoundException: com.fasterxml.jackson.annotation.JsonMerge
一开始引入的依赖:
<dependency><groupId>org.apache.parquet</groupId><artifactId>parquet-avro</artifactId><version>1.12.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.0.0</version></dependency>
报错:
Exception in thread "main" java.lang.NoClassDefFoundError: com/fasterxml/jackson/annotation/JsonMergeat com.fasterxml.jackson.databind.introspect.JacksonAnnotationIntrospector.<clinit>(JacksonAnnotationIntrospector.java:50)at com.fasterxml.jackson.databind.ObjectMapper.<clinit>(ObjectMapper.java:351)at org.apache.avro.Schema.<clinit>(Schema.java:109)at org.apache.avro.Schema$Parser.parse(Schema.java:1413)at WriteToParquet.main(WriteToParquet.java:21)
Caused by: java.lang.ClassNotFoundException: com.fasterxml.jackson.annotation.JsonMergeat java.net.URLClassLoader.findClass(URLClassLoader.java:381)at java.lang.ClassLoader.loadClass(ClassLoader.java:424)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)at java.lang.ClassLoader.loadClass(ClassLoader.java:357)... 5 more
解决:
<dependency><groupId>org.apache.parquet</groupId><artifactId>parquet-avro</artifactId><version>1.12.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.0.0</version><exclusions><exclusion><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-annotations</artifactId></exclusion></exclusions></dependency>
原因:我看当引入 hadoop-client 3.3.1 版本的时候 maven 依赖库里是 jackson-annotations-2.11.3.jar,但引入 hadoop-client 3.0.0 版本的时候 maven 依赖库里是 jackson-annotations-2.7.8.jar 执行程序会报上面那个错,于是在 3.0.0 版本中去掉 jackson-annotations 依赖后看 maven 依赖库里就是 jackson-annotations-2.11.3.jar 了。后来测试 jackson-annotations-2.6.7.jar 也正常。
坑2:No FileSystem for scheme “file”
整合到项目中报错:org.apache.hadoop.fs.UnsupportedFileSystemException: No FileSystem for scheme "file"
解决:增加如下代码
Configuration conf = new Configuration();conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");conf.set("fs.file.impl", "org.apache.hadoop.fs.LocalFileSystem");// 或者
// conf.set("fs.hdfs.impl",
// org.apache.hadoop.hdfs.DistributedFileSystem.class.getName()
// );
// conf.set("fs.file.impl",
// org.apache.hadoop.fs.LocalFileSystem.class.getName()
// );FileSystem fs = FileSystem.get(conf); // 这行必须有虽然没有被引用
参考:
java.io.IOException: No FileSystem for scheme: file
MapReduce 踩坑 - hadoop No FileSystem for scheme: file/hdfs
FileSystem及其源码分析
坑3:与 spark-sql 的引入冲突
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>2.4.0</version></dependency>
报错:
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/parquet/schema/LogicalTypeAnnotationat org.apache.parquet.avro.AvroParquetWriter.writeSupport(AvroParquetWriter.java:157)at org.apache.parquet.avro.AvroParquetWriter.access$200(AvroParquetWriter.java:36)at org.apache.parquet.avro.AvroParquetWriter$Builder.getWriteSupport(AvroParquetWriter.java:190)at org.apache.parquet.hadoop.ParquetWriter$Builder.build(ParquetWriter.java:533)at com.heheda.app.SparkWriteCsvToParquet.main(SparkWriteCsvToParquet.java:46)
Caused by: java.lang.ClassNotFoundException: org.apache.parquet.schema.LogicalTypeAnnotationat java.net.URLClassLoader.findClass(URLClassLoader.java:381)at java.lang.ClassLoader.loadClass(ClassLoader.java:424)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)at java.lang.ClassLoader.loadClass(ClassLoader.java:357)... 5 more
一开始的思路:
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.11</artifactId><version>2.4.0</version><exclusion><groupId>org.apache.parquet</groupId><artifactId>parquet-column</artifactId></exclusion></dependency>
接着又报错:
Exception in thread "main" java.lang.AbstractMethodError: org.apache.parquet.hadoop.ColumnChunkPageWriteStore$ColumnChunkPageWriter.writePage(Lorg/apache/parquet/bytes/BytesInput;IILorg/apache/parquet/column/statistics/Statistics;Lorg/apache/parquet/column/Encoding;Lorg
/apache/parquet/column/Encoding;Lorg/apache/parquet/column/Encoding;)V at org.apache.parquet.column.impl.ColumnWriterV1.writePage(ColumnWriterV1.java:59)at org.apache.parquet.column.impl.ColumnWriterBase.writePage(ColumnWriterBase.java:387)at org.apache.parquet.column.impl.ColumnWriteStoreBase.flush(ColumnWriteStoreBase.java:186)at org.apache.parquet.column.impl.ColumnWriteStoreV1.flush(ColumnWriteStoreV1.java:29)at org.apache.parquet.hadoop.InternalParquetRecordWriter.flushRowGroupToStore(InternalParquetRecordWriter.java:172)at org.apache.parquet.hadoop.InternalParquetRecordWriter.close(InternalParquetRecordWriter.java:114)at org.apache.parquet.hadoop.ParquetWriter.close(ParquetWriter.java:308)at com.heheda.app.SparkWriteCsvToParquet.main(SparkWriteCsvToParquet.java:52)
注:文章里说不需要 Hadoop 也行,但我没成功,提交到有 Hadoop 环境的服务器上可以运行,但本地 Idea 中报错生成了 parquet 空文件或者没有文件生成:
Exception in thread "main" java.lang.RuntimeException: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblemsat org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:736)at org.apache.hadoop.util.Shell.getSetPermissionCommand(Shell.java:271)at org.apache.hadoop.util.Shell.getSetPermissionCommand(Shell.java:287)at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:978)at org.apache.hadoop.fs.RawLocalFileSystem$LocalFSFileOutputStream.<init>(RawLocalFileSystem.java:324)at org.apache.hadoop.fs.RawLocalFileSystem$LocalFSFileOutputStream.<init>(RawLocalFileSystem.java:294)at org.apache.hadoop.fs.RawLocalFileSystem.createOutputStreamWithMode(RawLocalFileSystem.java:439)at org.apache.hadoop.fs.RawLocalFileSystem.create(RawLocalFileSystem.java:428)at org.apache.hadoop.fs.RawLocalFileSystem.create(RawLocalFileSystem.java:459)at org.apache.hadoop.fs.ChecksumFileSystem$ChecksumFSOutputSummer.<init>(ChecksumFileSystem.java:433)at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:521)at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:500)at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:1195)at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:1175)at org.apache.parquet.hadoop.util.HadoopOutputFile.createOrOverwrite(HadoopOutputFile.java:81)at org.apache.parquet.hadoop.ParquetFileWriter.<init>(ParquetFileWriter.java:327)at org.apache.parquet.hadoop.ParquetWriter.<init>(ParquetWriter.java:292)at org.apache.parquet.hadoop.ParquetWriter$Builder.build(ParquetWriter.java:646)at WriteToParquet.main(WriteToParquet.java:33)
Caused by: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblemsat org.apache.hadoop.util.Shell.fileNotFoundException(Shell.java:548)at org.apache.hadoop.util.Shell.getHadoopHomeDir(Shell.java:569)at org.apache.hadoop.util.Shell.getQualifiedBin(Shell.java:592)at org.apache.hadoop.util.Shell.<clinit>(Shell.java:689)at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:79)at org.apache.hadoop.fs.FileSystem$Cache$Key.<init>(FileSystem.java:3741)at org.apache.hadoop.fs.FileSystem$Cache$Key.<init>(FileSystem.java:3736)at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:3520)at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:540)at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:288)at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:524)at org.apache.hadoop.fs.Path.getFileSystem(Path.java:365)at org.apache.parquet.hadoop.util.HadoopOutputFile.fromPath(HadoopOutputFile.java:58)at org.apache.parquet.hadoop.ParquetWriter$Builder.build(ParquetWriter.java:643)... 1 more
Caused by: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset.at org.apache.hadoop.util.Shell.checkHadoopHomeInner(Shell.java:468)at org.apache.hadoop.util.Shell.checkHadoopHome(Shell.java:439)at org.apache.hadoop.util.Shell.<clinit>(Shell.java:516)... 11 more
方式二:
网上许多写入 parquet 需要在本地安装 haddop 环境,下面介绍一种不需要安装 haddop 即可写入 parquet 文件的方式;
来自:列式存储格式之parquet读写
Maven 依赖:
<dependency><groupId>org.apache.avro</groupId><artifactId>avro</artifactId><version>1.8.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-core</artifactId><version>1.2.1</version></dependency><dependency><groupId>org.apache.parquet</groupId><artifactId>parquet-hadoop</artifactId><version>1.8.1</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.parquet/parquet-avro --><dependency><groupId>org.apache.parquet</groupId><artifactId>parquet-avro</artifactId><version>1.8.1</version></dependency>
public class User {private String id;private String name;private String password;public User() {}public User(String id, String name, String password) {this.id = id;this.name = name;this.password = password;}public String getId() {return id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public String getPassword() {return password;}public void setPassword(String password) {this.password = password;}@Overridepublic String toString() {return "User{" +"id='" + id + '\'' +", name='" + name + '\'' +", password='" + password + '\'' +'}';}
}
注:这种方式的 User 实体类和上面方式的 schema.avsc 文件中的 "name": "User" 有冲突,报错:
Exception in thread "main" org.apache.parquet.io.ParquetDecodingException: Can not read value at 1 in block 0 in file file:/heheda/output.parquetat org.apache.parquet.hadoop.InternalParquetRecordReader.nextKeyValue(InternalParquetRecordReader.java:254)at org.apache.parquet.hadoop.ParquetReader.read(ParquetReader.java:132)at org.apache.parquet.hadoop.ParquetReader.read(ParquetReader.java:136)at WriteToParquet.main(WriteToParquet.java:55)
Caused by: java.lang.ClassCastException: User cannot be cast to org.apache.avro.generic.IndexedRecordat org.apache.avro.generic.GenericData.setField(GenericData.java:818)at org.apache.parquet.avro.AvroRecordConverter.set(AvroRecordConverter.java:396)at org.apache.parquet.avro.AvroRecordConverter$2.add(AvroRecordConverter.java:132)at org.apache.parquet.avro.AvroConverters$BinaryConverter.addBinary(AvroConverters.java:64)at org.apache.parquet.column.impl.ColumnReaderBase$2$6.writeValue(ColumnReaderBase.java:390)at org.apache.parquet.column.impl.ColumnReaderBase.writeCurrentValueToConverter(ColumnReaderBase.java:440)at org.apache.parquet.column.impl.ColumnReaderImpl.writeCurrentValueToConverter(ColumnReaderImpl.java:30)at org.apache.parquet.io.RecordReaderImplementation.read(RecordReaderImplementation.java:406)at org.apache.parquet.hadoop.InternalParquetRecordReader.nextKeyValue(InternalParquetRecordReader.java:229)... 3 more
写入:
import org.apache.avro.reflect.ReflectData;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.parquet.avro.AvroParquetWriter;
import org.apache.parquet.hadoop.ParquetWriter;import java.io.IOException;
import java.util.ArrayList;
import java.util.List;import static org.apache.parquet.hadoop.ParquetFileWriter.Mode.OVERWRITE;
import static org.apache.parquet.hadoop.metadata.CompressionCodecName.SNAPPY;public class WriteToParquet {public static void main(String[] args) {try {List<User> users = new ArrayList<>();User user1 = new User("1","huangchixin","123123");User user2 = new User("2","huangchixin2","123445");users.add(user1);users.add(user2);Path dataFile = new Path("output.parquet");ParquetWriter<User> writer = AvroParquetWriter.<User>builder(dataFile).withSchema(ReflectData.AllowNull.get().getSchema(User.class)).withDataModel(ReflectData.get()).withConf(new Configuration()).withCompressionCodec(SNAPPY).withWriteMode(OVERWRITE).build();for (User user : users) {writer.write(user);}writer.close();} catch (IOException e) {e.printStackTrace();}}
}
Idea 本地执行:

读取:
import org.apache.avro.reflect.ReflectData;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.parquet.avro.AvroParquetReader;
import org.apache.parquet.hadoop.ParquetReader;import java.io.IOException;public class WriteToParquet {public static void main(String[] args) {try {Path dataFile = new Path("output.parquet");ParquetReader<User> reader = AvroParquetReader.<User>builder(dataFile).withDataModel(new ReflectData(User.class.getClassLoader())).disableCompatibility().withConf(new Configuration()).build();User user;while ((user = reader.read()) != null) {System.out.println(user);}} catch (IOException e) {e.printStackTrace();}}
}