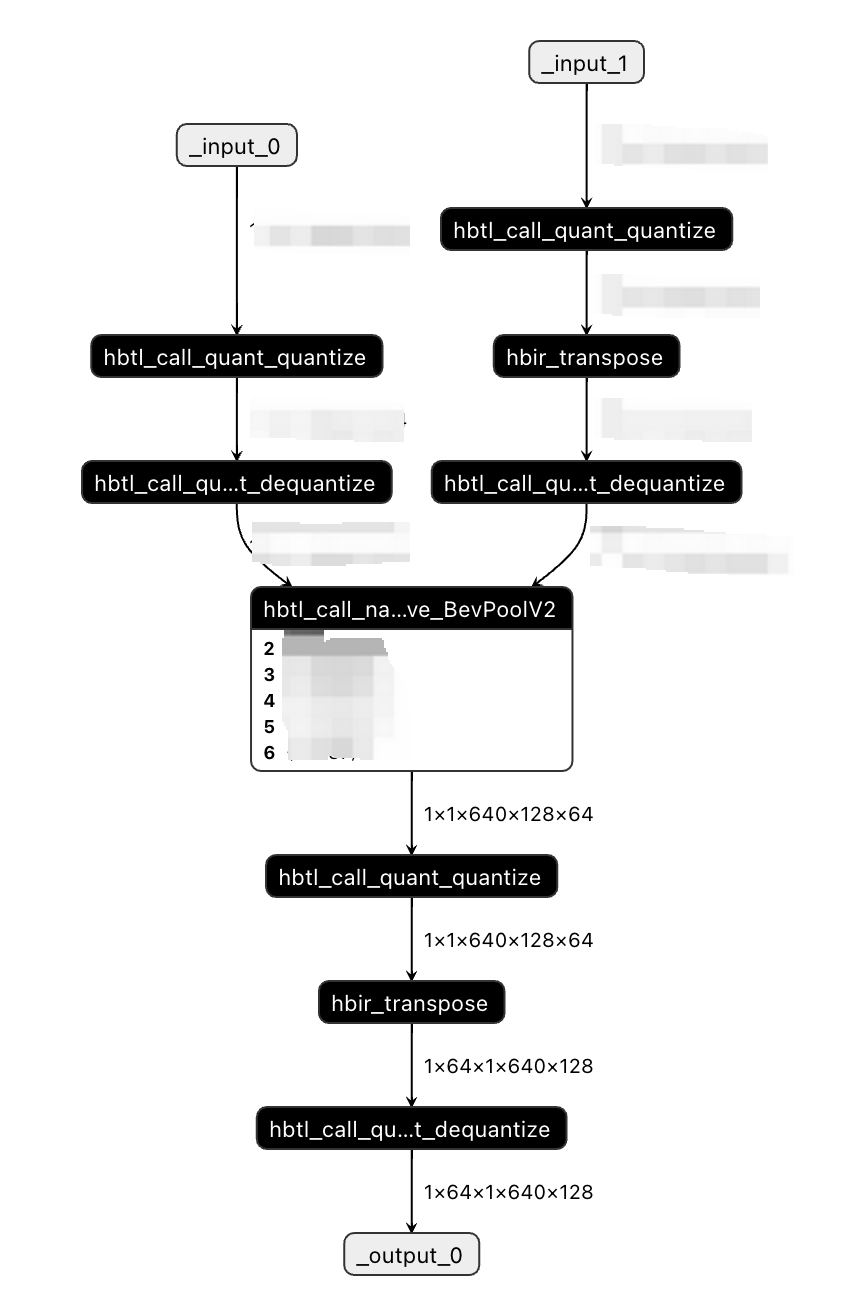
\((1)\)
答案中,为什么随着隐藏单元数的增多,训练集精确度不是单调增加?
当隐藏单元数目增多时,训练集精确度不单调增加的可能原因如下:
-
优化困难:
模型容量增加后,参数空间维度显著增大,优化器可能更难找到全局最优解,甚至陷入局部极小值或鞍点,导致训练收敛不稳定。 -
学习率不匹配:
更大的网络需要更小的学习率来稳定训练。若学习率未调整,可能导致参数更新震荡,使训练损失和准确度出现波动。 -
初始化敏感性:
隐藏单元增多时,权重初始化若未适配(如未使用He/Xavier初始化),可能导致梯度消失或爆炸,影响模型收敛能力。 -
正则化隐式影响:
某些框架可能默认启用正则化(如权重衰减),或训练过程中隐式正则化(如早停)。这会限制模型的过拟合能力,导致训练准确度无法持续提升。 -
训练数据规模限制:
若训练数据量不足,增加隐藏单元可能无法有效利用额外容量,反而因优化复杂度的提升导致训练效率下降。 -
随机性因素:
训练过程中的随机性(如参数初始化、数据打乱、Dropout等)可能在模型较大时被放大,导致结果波动。
总结:模型容量增加并不总能直接转化为训练性能的提升,优化难度、超参数配置、初始化策略等因素的综合作用可能导致训练准确度非单调变化。此时需通过调参(如学习率衰减、更好的初始化)、增加正则化或扩大数据集等手段平衡模型复杂度和训练稳定性。
测试集就更不用说了
\((2)\)
在其他参数不变的情况下,单纯增加隐藏层数可能导致准确率下降,主要原因如下:
1. 梯度消失/爆炸问题
- 梯度逐层衰减或放大:深层网络中,反向传播时梯度可能需要通过多个隐藏层传递。若激活函数(如 Sigmoid)或初始化方式不合适,梯度可能在传递过程中逐渐缩小(消失)或急剧增大(爆炸),导致浅层参数无法有效更新。
- 解决方案:使用 ReLU 及其变体(如 Leaky ReLU)、残差连接(ResNet)、梯度裁剪或批归一化(Batch Normalization)缓解此问题。
2. 优化难度剧增
- 参数交互复杂化:层数增加后,参数之间的依赖关系更复杂,优化器(如 SGD、Adam)可能难以找到全局最优解,甚至陷入局部极小值或鞍点。
- 学习率不匹配:深层网络通常需要更小的学习率或自适应优化策略(如学习率预热、衰减)。固定学习率可能导致参数更新不稳定。
- 示例:深层网络可能在前几层学到无意义的噪声,而后续层无法有效纠正。
3. 缺乏残差结构(Skip Connections)
- 信息传递受阻:在普通全连接网络或卷积网络中,深层信号可能逐渐退化。残差连接(如 ResNet 中的跳跃连接)能直接传递浅层特征到深层,避免信息丢失。
- 实验对比:若未引入残差结构,单纯堆叠层数会导致模型性能显著下降。
4. 初始化与激活函数不匹配
- 初始化不当:深层网络对初始化更敏感。例如,ReLU 激活函数需要 He 初始化,否则深层权重可能因初始化范围不合理导致激活值饱和(全为 0 或过大)。
- 激活函数选择:Sigmoid/Tanh 在深层网络中易引发梯度消失,而 ReLU 的“死神经元”问题可能随层数增加被放大。
5. 模型过参数化与欠拟合
- 数据量不足:深层网络需要更多数据充分训练。若训练数据有限,增加层数会导致模型无法有效学习有用特征,反而引入噪声。
- 隐式正则化不足:其他参数(如权重衰减、Dropout)未调整时,深层网络可能因参数过多而难以收敛,甚至欠拟合。
6. 计算资源限制
- 训练不充分:深层网络需要更多训练时间和计算资源。若训练轮次(epochs)不足或批量大小(batch size)未优化,模型可能未收敛到合理状态。
总结
增加隐藏层数本质上是在提升模型容量,但若缺乏配套的优化策略(如残差结构、批归一化、自适应学习率),模型可能因梯度问题、优化困难或数据不足而表现变差。实践建议:
- 引入残差连接和批归一化;
- 调整初始化方法和激活函数;
- 逐步增加层数并监控训练动态(如梯度幅值、损失曲线);
- 确保数据量和训练资源与模型复杂度匹配。