说明
上一篇介绍了基于算力租用的方式部署chatglm3, 见文章;本篇接着看如何使用API方式进行使用。
内容
1 官方接口
详情可见接口调用文档
调用有两种方式,SDK包和Http。一般来说,用SDK会省事一些。
以下是Python SDK包的git项目地址
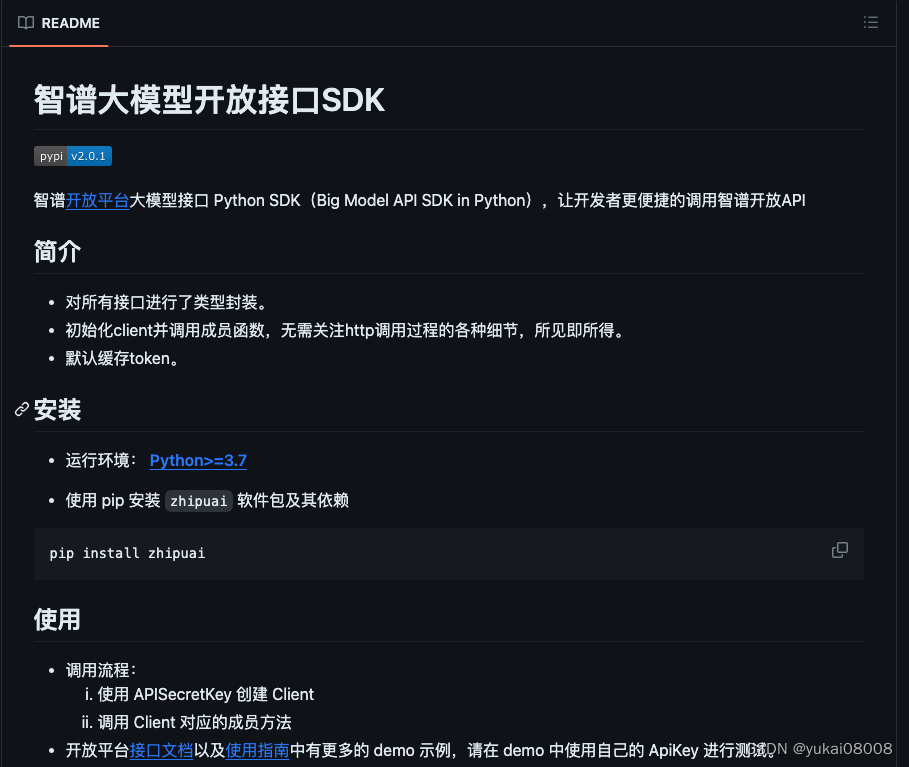
安装智谱的包
pip3 install zhipuai
三种调用方式:
- 1 同步
- 2 异步
- 3 SSE
SSE(Sever-Sent Event),就是浏览器向服务器发送一个HTTP请求,保持长连接,服务器不断单向地向浏览器推送“信息”(message),这么做是为了节约网络资源,不用一直发请求,建立新连接。

关于token: 可以理解为一种计算机的分词单位。
调用的关键参数是模型,文档里没有很清晰,不过在这里可以看到
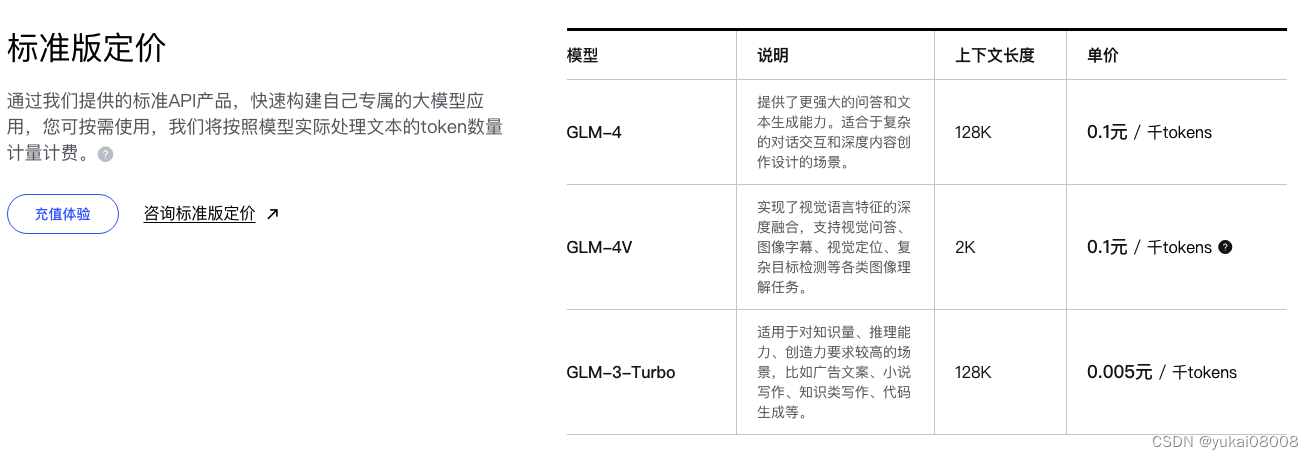
模型名称换成小写,调用成功
In [1]: from zhipuai import ZhipuAI...: client = ZhipuAI(api_key="YOURS") # 填写您自己的APIKey...: response = client.chat.completions.create(...: model="glm-3-turbo", # 填写需要调用的模型名称...: messages=[...: {"role": "user", "content": "作为一名营销专家,请为我的产品创作一个吸引人的slogan"},...: {"role": "assistant", "content": "当然,为了创作一个吸引人的slogan,请告诉我一些关于您产品的信息"},...: {"role": "user", "content": "智谱AI开放平台"},...: {"role": "assistant", "content": "智启未来,谱绘无限一智谱AI,让创新触手可及!"},...: {"role": "user", "content": "创造一个更精准、吸引人的slogan"}...: ],...: )...: print(response.choices[0].message)
content='"智谱AI,启迪创新,连接未来!"' role='assistant' tool_calls=None
好像聊天也要消耗Token,一天没怎么用就花了2000。这样如果是个人轻度使用,几年也够用;中度使用,假设一天用1万,那么够用3个月;重度使用的话可能一天能好几万,那么也就1个月。我觉得这种设计还是不错的,赠送的数量足够用户产生粘性,企业花费的额外cost又很低。

然后我又看了下其他的部署报价,云端3台推理机的成本估计在6万~30万左右吧,其他的都是小成本了。所以要能卖起来还是不错的,关键看怎么引用,我竟然觉得还不贵。由于大模型的训练还是有比较高的前期成本,所以毛利有很大一部分可以认为是分摊前期研发成本。
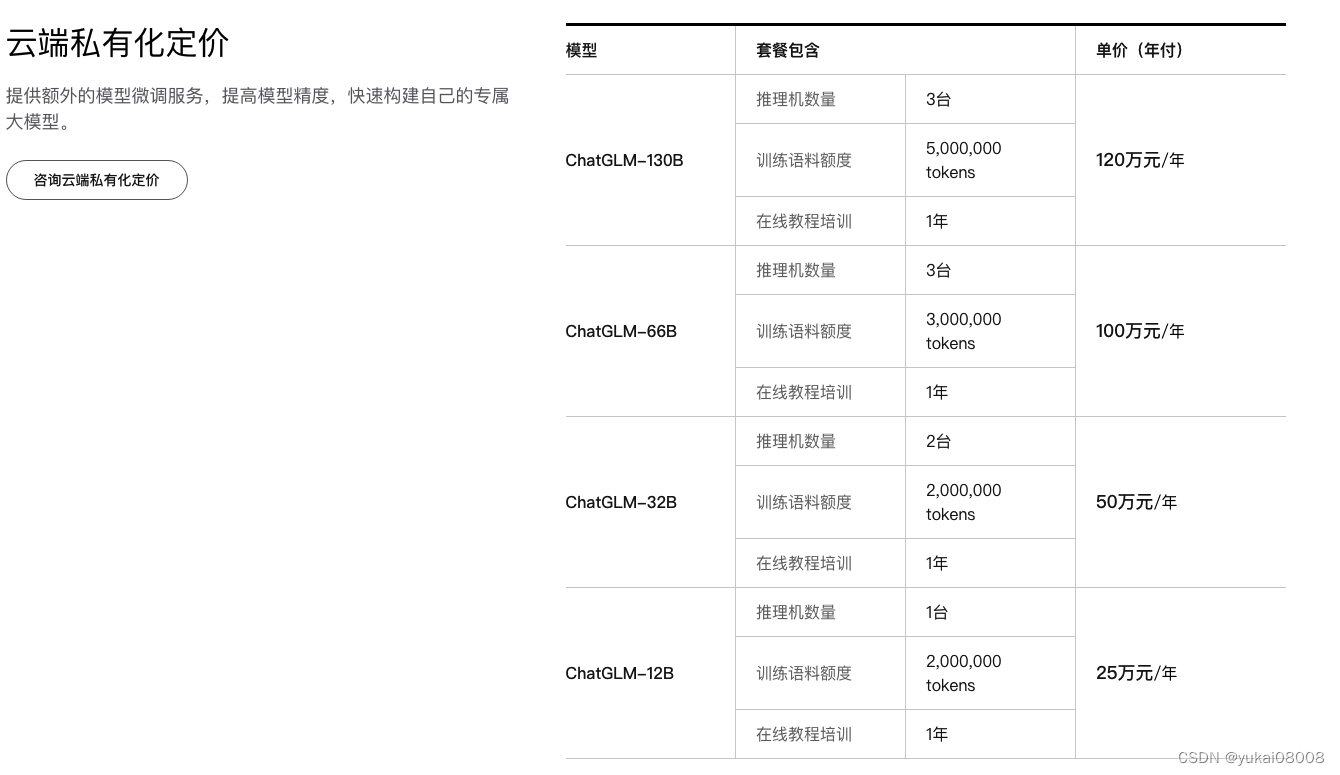
本地的成本主要就是人天了,按每天2万算的话,人天成本不到10%。

最优意思的是ChatGLM3-6B,也就是目前谈到的开源版,是可以免费商用授权的。整体上感觉还是不错的商业化模式。
如果是取代部分简单重复的劳动的话,对很多大型企业还是划的来的。如果能够形成市场,那么AI工作也就很容易量化了,有助于这个行业的成熟。
2 本地搭建
2.1 本地镜像
略。安装时间太长,镜像太大。参考
2.2 仙宫云
在用户目录下
- 1 安装环境依赖
vim requirements_chatglm3.txt 将项目的包文件拷贝pip3 install -r requirements_chatglm3.txt -i https://mirrors.aliyun.com/pypi/simple/
- 2 拷贝模型包
一个chatglm模型包,一个embeddign的模型包。
- 3 拷贝服务相关的两个py
utils.py
import gc
import json
import torch
from transformers import PreTrainedModel, PreTrainedTokenizer
from transformers.generation.logits_process import LogitsProcessor
from typing import Union, Tupleclass InvalidScoreLogitsProcessor(LogitsProcessor):def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:if torch.isnan(scores).any() or torch.isinf(scores).any():scores.zero_()scores[..., 5] = 5e4return scoresdef process_response(output: str, use_tool: bool = False) -> Union[str, dict]:content = ""for response in output.split("<|assistant|>"):metadata, content = response.split("\n", maxsplit=1)if not metadata.strip():content = content.strip()content = content.replace("[[训练时间]]", "2023年")else:if use_tool:content = "\n".join(content.split("\n")[1:-1])def tool_call(**kwargs):return kwargsparameters = eval(content)content = {"name": metadata.strip(),"arguments": json.dumps(parameters, ensure_ascii=False)}else:content = {"name": metadata.strip(),"content": content}return content@torch.inference_mode()
def generate_stream_chatglm3(model: PreTrainedModel, tokenizer: PreTrainedTokenizer, params: dict):messages = params["messages"]tools = params["tools"]temperature = float(params.get("temperature", 1.0))repetition_penalty = float(params.get("repetition_penalty", 1.0))top_p = float(params.get("top_p", 1.0))max_new_tokens = int(params.get("max_tokens", 256))echo = params.get("echo", True)messages = process_chatglm_messages(messages, tools=tools)query, role = messages[-1]["content"], messages[-1]["role"]inputs = tokenizer.build_chat_input(query, history=messages[:-1], role=role)inputs = inputs.to(model.device)input_echo_len = len(inputs["input_ids"][0])if input_echo_len >= model.config.seq_length:print(f"Input length larger than {model.config.seq_length}")eos_token_id = [tokenizer.eos_token_id,tokenizer.get_command("<|user|>"),]gen_kwargs = {"max_new_tokens": max_new_tokens,"do_sample": True if temperature > 1e-5 else False,"top_p": top_p,"repetition_penalty": repetition_penalty,"logits_processor": [InvalidScoreLogitsProcessor()],}if temperature > 1e-5:gen_kwargs["temperature"] = temperaturetotal_len = 0for total_ids in model.stream_generate(**inputs, eos_token_id=eos_token_id, **gen_kwargs):total_ids = total_ids.tolist()[0]total_len = len(total_ids)if echo:output_ids = total_ids[:-1]else:output_ids = total_ids[input_echo_len:-1]response = tokenizer.decode(output_ids)if response and response[-1] != "�":response, stop_found = apply_stopping_strings(response, ["<|observation|>"])yield {"text": response,"usage": {"prompt_tokens": input_echo_len,"completion_tokens": total_len - input_echo_len,"total_tokens": total_len,},"finish_reason": "function_call" if stop_found else None,}if stop_found:break# Only last stream result contains finish_reason, we set finish_reason as stopret = {"text": response,"usage": {"prompt_tokens": input_echo_len,"completion_tokens": total_len - input_echo_len,"total_tokens": total_len,},"finish_reason": "stop",}yield retgc.collect()torch.cuda.empty_cache()def process_chatglm_messages(messages, tools=None):_messages = messagesmessages = []if tools:messages.append({"role": "system","content": "Answer the following questions as best as you can. You have access to the following tools:","tools": tools})for m in _messages:role, content, func_call = m.role, m.content, m.function_callif role == "function":messages.append({"role": "observation","content": content})elif role == "assistant" and func_call is not None:for response in content.split("<|assistant|>"):metadata, sub_content = response.split("\n", maxsplit=1)messages.append({"role": role,"metadata": metadata,"content": sub_content.strip()})else:messages.append({"role": role, "content": content})return messagesdef generate_chatglm3(model: PreTrainedModel, tokenizer: PreTrainedTokenizer, params: dict):for response in generate_stream_chatglm3(model, tokenizer, params):passreturn responsedef apply_stopping_strings(reply, stop_strings) -> Tuple[str, bool]:stop_found = Falsefor string in stop_strings:idx = reply.find(string)if idx != -1:reply = reply[:idx]stop_found = Truebreakif not stop_found:# If something like "\nYo" is generated just before "\nYou: is completed, trim itfor string in stop_strings:for j in range(len(string) - 1, 0, -1):if reply[-j:] == string[:j]:reply = reply[:-j]breakelse:continuebreakreturn reply, stop_found这个是chat的解释

api_server.py
import os
import time
import tiktoken
import torch
import uvicornfrom fastapi import FastAPI, HTTPException, Response
from fastapi.middleware.cors import CORSMiddlewarefrom contextlib import asynccontextmanager
from typing import List, Literal, Optional, Union
from loguru import logger
from pydantic import BaseModel, Field
from transformers import AutoTokenizer, AutoModel
from utils import process_response, generate_chatglm3, generate_stream_chatglm3
from sentence_transformers import SentenceTransformerfrom sse_starlette.sse import EventSourceResponse# Set up limit request time
EventSourceResponse.DEFAULT_PING_INTERVAL = 1000# set LLM path
# MODEL_PATH = os.environ.get('MODEL_PATH', 'THUDM/chatglm3-6b')
MODEL_PATH = os.environ.get('MODEL_PATH', '/chatgml3_6b')
TOKENIZER_PATH = os.environ.get("TOKENIZER_PATH", MODEL_PATH)# set Embedding Model path
# EMBEDDING_PATH = os.environ.get('EMBEDDING_PATH', 'BAAI/bge-large-zh-v1.5')
EMBEDDING_PATH = os.environ.get('EMBEDDING_PATH', '/bge-large-zh-v1.5')@asynccontextmanager
async def lifespan(app: FastAPI):yieldif torch.cuda.is_available():torch.cuda.empty_cache()torch.cuda.ipc_collect()app = FastAPI(lifespan=lifespan)app.add_middleware(CORSMiddleware,allow_origins=["*"],allow_credentials=True,allow_methods=["*"],allow_headers=["*"],
)class ModelCard(BaseModel):id: strobject: str = "model"created: int = Field(default_factory=lambda: int(time.time()))owned_by: str = "owner"root: Optional[str] = Noneparent: Optional[str] = Nonepermission: Optional[list] = Noneclass ModelList(BaseModel):object: str = "list"data: List[ModelCard] = []class FunctionCallResponse(BaseModel):name: Optional[str] = Nonearguments: Optional[str] = Noneclass ChatMessage(BaseModel):role: Literal["user", "assistant", "system", "function"]content: str = Nonename: Optional[str] = Nonefunction_call: Optional[FunctionCallResponse] = Noneclass DeltaMessage(BaseModel):role: Optional[Literal["user", "assistant", "system"]] = Nonecontent: Optional[str] = Nonefunction_call: Optional[FunctionCallResponse] = None## for Embedding
class EmbeddingRequest(BaseModel):input: List[str]model: strclass CompletionUsage(BaseModel):prompt_tokens: intcompletion_tokens: inttotal_tokens: intclass EmbeddingResponse(BaseModel):data: listmodel: strobject: strusage: CompletionUsage# for ChatCompletionRequestclass UsageInfo(BaseModel):prompt_tokens: int = 0total_tokens: int = 0completion_tokens: Optional[int] = 0class ChatCompletionRequest(BaseModel):model: strmessages: List[ChatMessage]temperature: Optional[float] = 0.8top_p: Optional[float] = 0.8max_tokens: Optional[int] = Nonestream: Optional[bool] = Falsetools: Optional[Union[dict, List[dict]]] = Nonerepetition_penalty: Optional[float] = 1.1class ChatCompletionResponseChoice(BaseModel):index: intmessage: ChatMessagefinish_reason: Literal["stop", "length", "function_call"]class ChatCompletionResponseStreamChoice(BaseModel):delta: DeltaMessagefinish_reason: Optional[Literal["stop", "length", "function_call"]]index: intclass ChatCompletionResponse(BaseModel):model: strid: strobject: Literal["chat.completion", "chat.completion.chunk"]choices: List[Union[ChatCompletionResponseChoice, ChatCompletionResponseStreamChoice]]created: Optional[int] = Field(default_factory=lambda: int(time.time()))usage: Optional[UsageInfo] = None@app.get("/health")
async def health() -> Response:"""Health check."""return Response(status_code=200)@app.post("/v1/embeddings", response_model=EmbeddingResponse)
async def get_embeddings(request: EmbeddingRequest):embeddings = [embedding_model.encode(text) for text in request.input]embeddings = [embedding.tolist() for embedding in embeddings]def num_tokens_from_string(string: str) -> int:"""Returns the number of tokens in a text string.use cl100k_base tokenizer"""encoding = tiktoken.get_encoding('cl100k_base')num_tokens = len(encoding.encode(string))return num_tokensresponse = {"data": [{"object": "embedding","embedding": embedding,"index": index}for index, embedding in enumerate(embeddings)],"model": request.model,"object": "list","usage": CompletionUsage(prompt_tokens=sum(len(text.split()) for text in request.input),completion_tokens=0,total_tokens=sum(num_tokens_from_string(text) for text in request.input),)}return response@app.get("/v1/models", response_model=ModelList)
async def list_models():model_card = ModelCard(id="chatglm3-6b")return ModelList(data=[model_card])@app.post("/v1/chat/completions", response_model=ChatCompletionResponse)
async def create_chat_completion(request: ChatCompletionRequest):global model, tokenizerif len(request.messages) < 1 or request.messages[-1].role == "assistant":raise HTTPException(status_code=400, detail="Invalid request")gen_params = dict(messages=request.messages,temperature=request.temperature,top_p=request.top_p,max_tokens=request.max_tokens or 1024,echo=False,stream=request.stream,repetition_penalty=request.repetition_penalty,tools=request.tools,)logger.debug(f"==== request ====\n{gen_params}")if request.stream:# Use the stream mode to read the first few characters, if it is not a function call, direct stram outputpredict_stream_generator = predict_stream(request.model, gen_params)output = next(predict_stream_generator)if not contains_custom_function(output):return EventSourceResponse(predict_stream_generator, media_type="text/event-stream")# Obtain the result directly at one time and determine whether tools needs to be called.logger.debug(f"First result output:\n{output}")function_call = Noneif output and request.tools:try:function_call = process_response(output, use_tool=True)except:logger.warning("Failed to parse tool call")# CallFunctionif isinstance(function_call, dict):function_call = FunctionCallResponse(**function_call)"""In this demo, we did not register any tools.You can use the tools that have been implemented in our `tools_using_demo` and implement your own streaming tool implementation here.Similar to the following method:function_args = json.loads(function_call.arguments)tool_response = dispatch_tool(tool_name: str, tool_params: dict)"""tool_response = ""if not gen_params.get("messages"):gen_params["messages"] = []gen_params["messages"].append(ChatMessage(role="assistant",content=output,))gen_params["messages"].append(ChatMessage(role="function",name=function_call.name,content=tool_response,))# Streaming output of results after function callsgenerate = predict(request.model, gen_params)return EventSourceResponse(generate, media_type="text/event-stream")else:# Handled to avoid exceptions in the above parsing function process.generate = parse_output_text(request.model, output)return EventSourceResponse(generate, media_type="text/event-stream")# Here is the handling of stream = Falseresponse = generate_chatglm3(model, tokenizer, gen_params)# Remove the first newline characterif response["text"].startswith("\n"):response["text"] = response["text"][1:]response["text"] = response["text"].strip()usage = UsageInfo()function_call, finish_reason = None, "stop"if request.tools:try:function_call = process_response(response["text"], use_tool=True)except:logger.warning("Failed to parse tool call, maybe the response is not a tool call or have been answered.")if isinstance(function_call, dict):finish_reason = "function_call"function_call = FunctionCallResponse(**function_call)message = ChatMessage(role="assistant",content=response["text"],function_call=function_call if isinstance(function_call, FunctionCallResponse) else None,)logger.debug(f"==== message ====\n{message}")choice_data = ChatCompletionResponseChoice(index=0,message=message,finish_reason=finish_reason,)task_usage = UsageInfo.model_validate(response["usage"])for usage_key, usage_value in task_usage.model_dump().items():setattr(usage, usage_key, getattr(usage, usage_key) + usage_value)return ChatCompletionResponse(model=request.model,id="", # for open_source model, id is emptychoices=[choice_data],object="chat.completion",usage=usage)async def predict(model_id: str, params: dict):global model, tokenizerchoice_data = ChatCompletionResponseStreamChoice(index=0,delta=DeltaMessage(role="assistant"),finish_reason=None)chunk = ChatCompletionResponse(model=model_id, id="", choices=[choice_data], object="chat.completion.chunk")yield "{}".format(chunk.model_dump_json(exclude_unset=True))previous_text = ""for new_response in generate_stream_chatglm3(model, tokenizer, params):decoded_unicode = new_response["text"]delta_text = decoded_unicode[len(previous_text):]previous_text = decoded_unicodefinish_reason = new_response["finish_reason"]if len(delta_text) == 0 and finish_reason != "function_call":continuefunction_call = Noneif finish_reason == "function_call":try:function_call = process_response(decoded_unicode, use_tool=True)except:logger.warning("Failed to parse tool call, maybe the response is not a tool call or have been answered.")if isinstance(function_call, dict):function_call = FunctionCallResponse(**function_call)delta = DeltaMessage(content=delta_text,role="assistant",function_call=function_call if isinstance(function_call, FunctionCallResponse) else None,)choice_data = ChatCompletionResponseStreamChoice(index=0,delta=delta,finish_reason=finish_reason)chunk = ChatCompletionResponse(model=model_id,id="",choices=[choice_data],object="chat.completion.chunk")yield "{}".format(chunk.model_dump_json(exclude_unset=True))choice_data = ChatCompletionResponseStreamChoice(index=0,delta=DeltaMessage(),finish_reason="stop")chunk = ChatCompletionResponse(model=model_id,id="",choices=[choice_data],object="chat.completion.chunk")yield "{}".format(chunk.model_dump_json(exclude_unset=True))yield '[DONE]'def predict_stream(model_id, gen_params):"""The function call is compatible with stream mode output.The first seven characters are determined.If not a function call, the stream output is directly generated.Otherwise, the complete character content of the function call is returned.:param model_id::param gen_params::return:"""output = ""is_function_call = Falsehas_send_first_chunk = Falsefor new_response in generate_stream_chatglm3(model, tokenizer, gen_params):decoded_unicode = new_response["text"]delta_text = decoded_unicode[len(output):]output = decoded_unicode# When it is not a function call and the character length is> 7,# try to judge whether it is a function call according to the special function prefixif not is_function_call and len(output) > 7:# Determine whether a function is calledis_function_call = contains_custom_function(output)if is_function_call:continue# Non-function call, direct stream outputfinish_reason = new_response["finish_reason"]# Send an empty string first to avoid truncation by subsequent next() operations.if not has_send_first_chunk:message = DeltaMessage(content="",role="assistant",function_call=None,)choice_data = ChatCompletionResponseStreamChoice(index=0,delta=message,finish_reason=finish_reason)chunk = ChatCompletionResponse(model=model_id,id="",choices=[choice_data],created=int(time.time()),object="chat.completion.chunk")yield "{}".format(chunk.model_dump_json(exclude_unset=True))send_msg = delta_text if has_send_first_chunk else outputhas_send_first_chunk = Truemessage = DeltaMessage(content=send_msg,role="assistant",function_call=None,)choice_data = ChatCompletionResponseStreamChoice(index=0,delta=message,finish_reason=finish_reason)chunk = ChatCompletionResponse(model=model_id,id="",choices=[choice_data],created=int(time.time()),object="chat.completion.chunk")yield "{}".format(chunk.model_dump_json(exclude_unset=True))if is_function_call:yield outputelse:yield '[DONE]'async def parse_output_text(model_id: str, value: str):"""Directly output the text content of value:param model_id::param value::return:"""choice_data = ChatCompletionResponseStreamChoice(index=0,delta=DeltaMessage(role="assistant", content=value),finish_reason=None)chunk = ChatCompletionResponse(model=model_id, id="", choices=[choice_data], object="chat.completion.chunk")yield "{}".format(chunk.model_dump_json(exclude_unset=True))choice_data = ChatCompletionResponseStreamChoice(index=0,delta=DeltaMessage(),finish_reason="stop")chunk = ChatCompletionResponse(model=model_id, id="", choices=[choice_data], object="chat.completion.chunk")yield "{}".format(chunk.model_dump_json(exclude_unset=True))yield '[DONE]'def contains_custom_function(value: str) -> bool:"""Determine whether 'function_call' according to a special function prefix.For example, the functions defined in "tools_using_demo/tool_register.py" are all "get_xxx" and start with "get_"[Note] This is not a rigorous judgment method, only for reference.:param value::return:"""return value and 'get_' in valueif __name__ == "__main__":# Load LLMtokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True)model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True, device_map="auto").eval()# load Embeddingembedding_model = SentenceTransformer(EMBEDDING_PATH, device="cuda")uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)以下是chat的解读,对我们来说,只要修改模型具体的位置,然后启动就可以了python3 api_server.py

最后的使用则可以参考OpenAI或者ZhiPuAI的调用方法
"""
This script is an example of using the Zhipu API to create various interactions with a ChatGLM3 model. It includes
functions to:1. Conduct a basic chat session, asking about weather conditions in multiple cities.
2. Initiate a simple chat in Chinese, asking the model to tell a short story.
3. Retrieve and print embeddings for a given text input.
Each function demonstrates a different aspect of the API's capabilities,
showcasing how to make requests and handle responses.Note: Make sure your Zhipu API key is set as an environment
variable formate as xxx.xxx (just for check, not need a real key).
"""from zhipuai import ZhipuAIbase_url = "http://127.0.0.1:8000/v1/"
client = ZhipuAI(api_key="EMP.TY", base_url=base_url)def function_chat():messages = [{"role": "user", "content": "What's the weather like in San Francisco, Tokyo, and Paris?"}]tools = [{"type": "function","function": {"name": "get_current_weather","description": "Get the current weather in a given location","parameters": {"type": "object","properties": {"location": {"type": "string","description": "The city and state, e.g. San Francisco, CA",},"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},},"required": ["location"],},},}]response = client.chat.completions.create(model="chatglm3_6b",messages=messages,tools=tools,tool_choice="auto",)if response:content = response.choices[0].message.contentprint(content)else:print("Error:", response.status_code)def simple_chat(use_stream=True):messages = [{"role": "system","content": "You are ChatGLM3, a large language model trained by Zhipu.AI. Follow ""the user's instructions carefully. Respond using markdown.",},{"role": "user","content": "你好,请你介绍一下chatglm3-6b这个模型"}]response = client.chat.completions.create(model="chatglm3_",messages=messages,stream=use_stream,max_tokens=256,temperature=0.8,top_p=0.8)if response:if use_stream:for chunk in response:print(chunk.choices[0].delta.content)else:content = response.choices[0].message.contentprint(content)else:print("Error:", response.status_code)def embedding():response = client.embeddings.create(model="bge-large-zh-1.5",input=["ChatGLM3-6B 是一个大型的中英双语模型。"],)embeddings = response.data[0].embeddingprint("嵌入完成,维度:", len(embeddings))if __name__ == "__main__":simple_chat(use_stream=False)simple_chat(use_stream=True)embedding()function_chat()几个要点如下:
- 1 如果要上生产,可以加一些API Key的鉴权。
- 2 测试了4个功能:以离线方式调用、流调用、向量嵌入转换以及功能函数的调用。
通常来说,用第一种测试就可以了。
BTW,测试了一下,chatglm3还是有很多“老毛病”的,例如回答有时候会一半中文一半英文、答案大幅漂移等问题。