🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
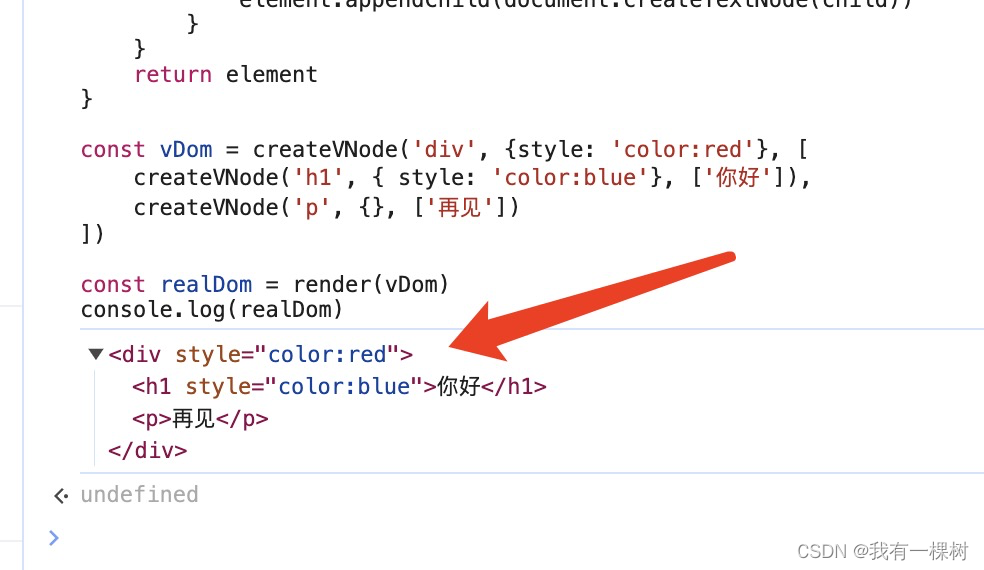
4.导入数据
5.数据可视化
文末推荐与福利
1.项目背景
一、研究背景
随着社交媒体的普及,人们越来越多地在网络上表达自己的情感和观点。这些情感和观点的汇聚,形成了一种宝贵的资源,即社交媒体情绪数据。这些数据反映了公众对于各种事件、产品、话题等的态度和情感倾向,因此具有极高的研究价值。近年来,越来越多的研究者开始关注社交媒体情绪数据的分析,以期揭示社会现象、预测市场趋势、了解公众情绪等。
然而,社交媒体情绪数据的分析面临诸多挑战。首先,社交媒体上的文本信息常常是非结构化的,需要经过适当的预处理才能进行有效的分析。其次,情感倾向的判断并不总是显而易见的,需要依赖特定的情感词典和算法进行判断。此外,由于社交媒体用户基数庞大,数据量极大,如何有效地处理和分析这些数据成为了一大难题。
为了解决这些问题,本研究采用数据可视化的方法对社交媒体情绪数据进行深入分析。通过可视化技术,我们可以直观地展示数据的分布、关联和动态变化,有助于我们更好地理解数据背后的规律和趋势。同时,可视化分析还能帮助我们快速识别异常值、发现数据中的模式和规律,从而提高数据分析的效率和准确性。
二、研究意义
本研究具有重要的理论和实践意义。首先,通过可视化分析社交媒体情绪数据,我们可以更深入地了解公众的情绪和观点,为相关领域的研究提供新的视角和方法。其次,通过对情绪数据的分析,我们可以预测市场趋势和社会现象,为企业决策提供依据。此外,通过对社交媒体情绪数据的可视化分析,我们还可以发现潜在的社会问题,为政策制定提供支持。
2.数据集介绍

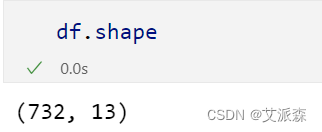
本数据集来源于Kaggle,社交媒体情绪分析数据集捕捉了各种社交媒体平台上充满活力的情绪、趋势和互动。该数据集提供了用户生成内容的快照,包括文本、时间戳、主题标签、国家/地区、点赞和转发。每个条目都揭示了世界各地的人们分享的独特故事——惊喜、兴奋、钦佩、兴奋、满足等等的时刻。原始数据集共732条,13个变量,各变量含义如下:
Text:用户生成的内容展示情感
Sentiment:情绪分类
Timestamp:日期和时间信息
User:贡献用户的唯一标识符
Platform:内容起源的社交媒体平台
Hashtags:识别热门话题和主题
Retweets:量化用户参与度(喜欢)
Likes:反映内容受欢迎程度(转发)
Country:每个帖子的地理来源
Year:职位年份
Month:帖子月份
Day :发帖日
Hour:发帖时间

3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.导入数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')df=pd.read_csv('sentimentdataset.csv')
df.head()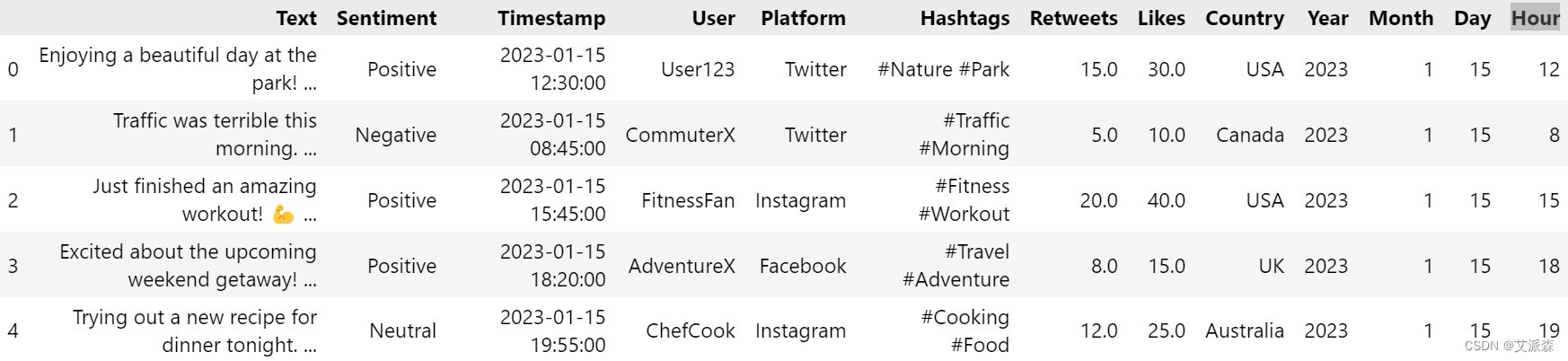
查看数据大小
查看数据基本信息
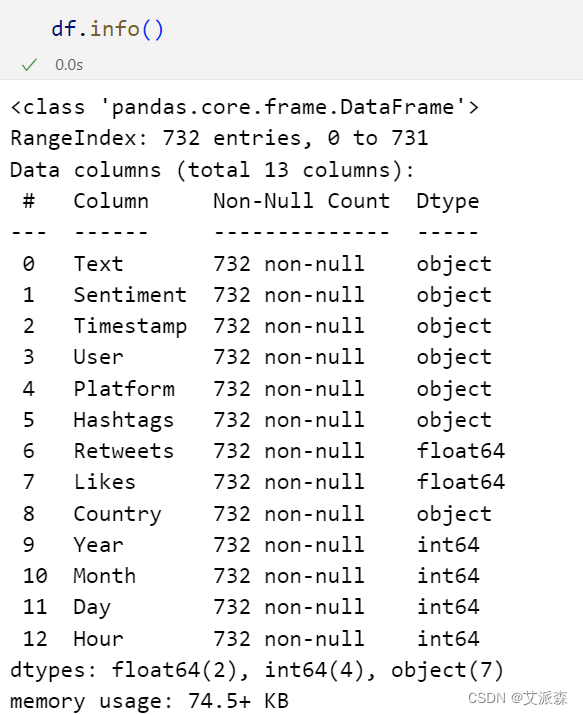
查看数值型变量描述性统计
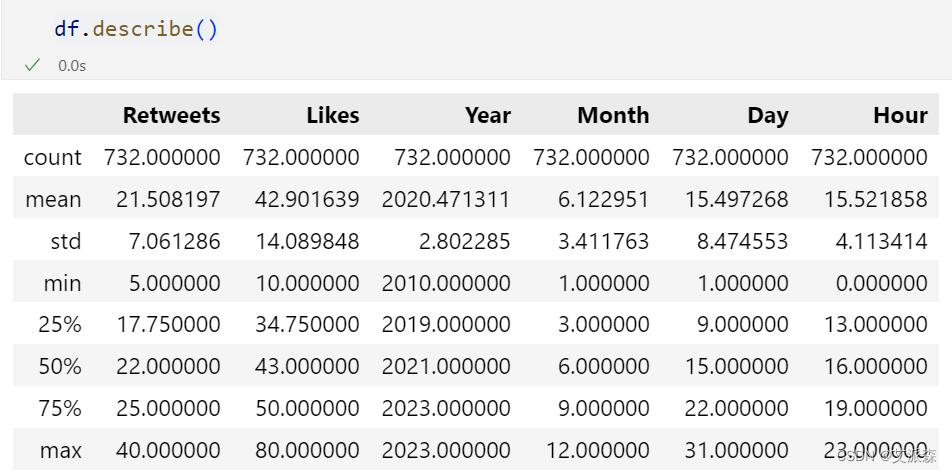
查看非数值型变量描述性统计

# 去除空格
df['Text']= df['Text'].str.strip()
df['Sentiment']= df['Sentiment'].str.strip()
df['User']= df['User'].str.strip()
df['Platform']= df['Platform'].str.strip()
df['Hashtags']= df['Hashtags'].str.strip()
df['Country']= df['Country'].str.strip()5.数据可视化
df['Sentiment'].value_counts().nlargest(10).plot(kind='bar')
plt.title('Top 10 Sentiments based on Text')
plt.xlabel('Sentiment')
plt.ylabel('Count')
plt.show()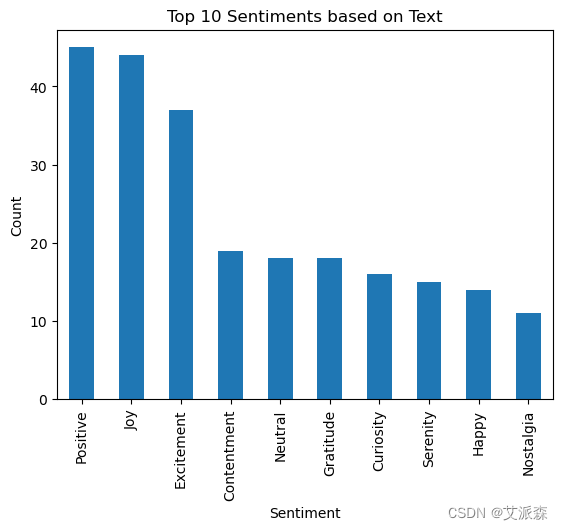
df['Platform'].value_counts().plot(kind='pie', autopct='%1.1f%%')
plt.title('Percentages of Platforms')
plt.legend()
plt.show()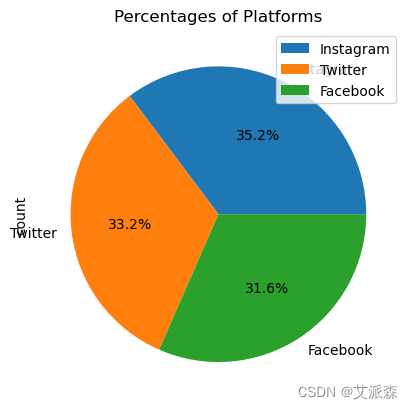
# 计算每个国家/地区每个平台的出现次数
platform_counts = df.groupby(['Country', 'Platform']).size().unstack(fill_value=0)
top_countries = platform_counts.sum(axis=1).sort_values(ascending=True).tail(10)
top_platform_counts = platform_counts.loc[top_countries.index]
plt.figure(figsize=(12, 8))
top_platform_counts.plot(kind='barh', stacked=True, ax=plt.gca())
plt.title('Top 10 Countries by Platform Counts')
plt.xlabel('Country')
plt.ylabel('Count')
plt.legend(title='Platform', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.show()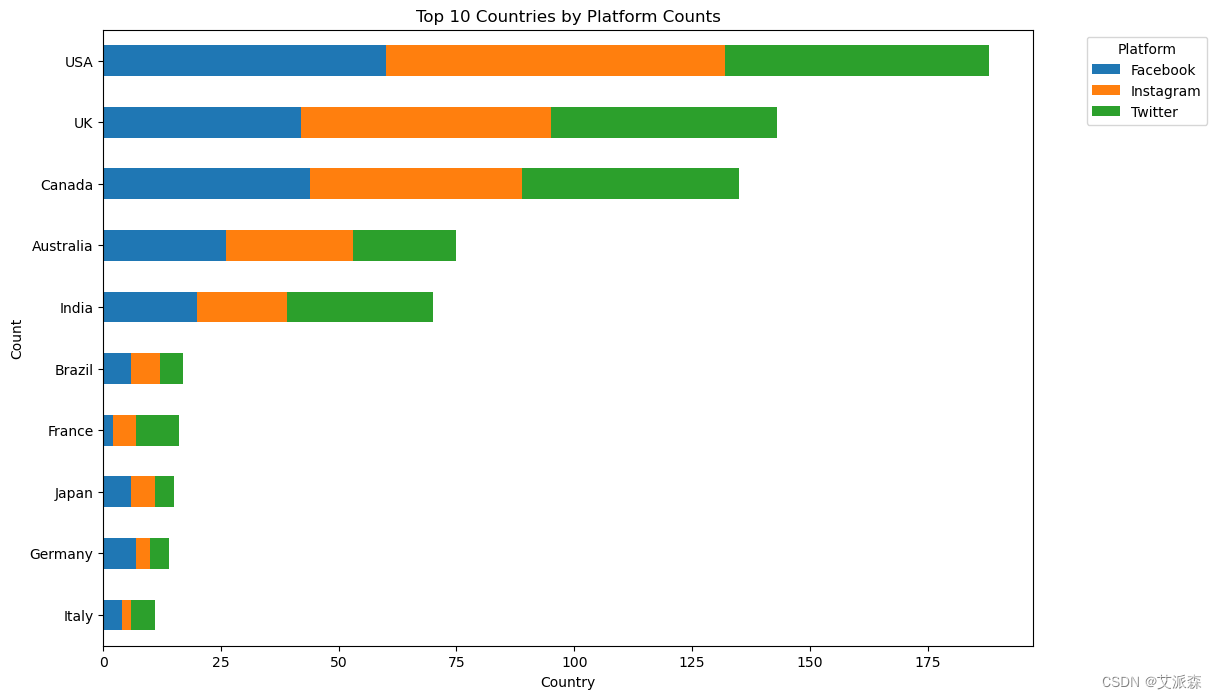
df['Country'].value_counts().nlargest(10).plot(kind='bar')
plt.title('Top 10 Country')
plt.legend()
plt.show()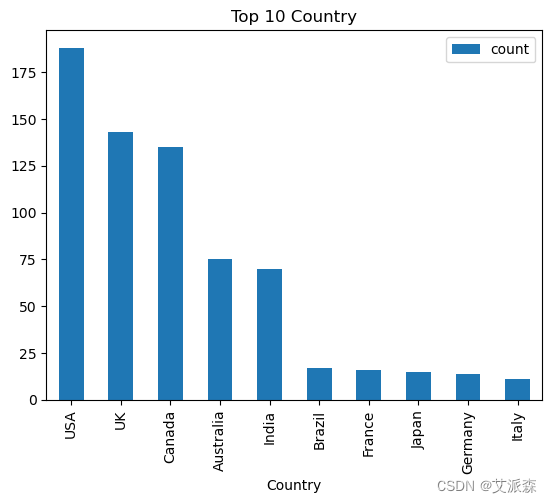
# 问题一:转发次数最多的10个话题标签
H_R = df.groupby('Hashtags')['Retweets'].max().nlargest(10).sort_values(ascending=False).plot(kind='bar')
plt.title('Top 10 hashtags retweeted')
plt.xlabel('Hashtags')
plt.ylabel('count')
plt.show()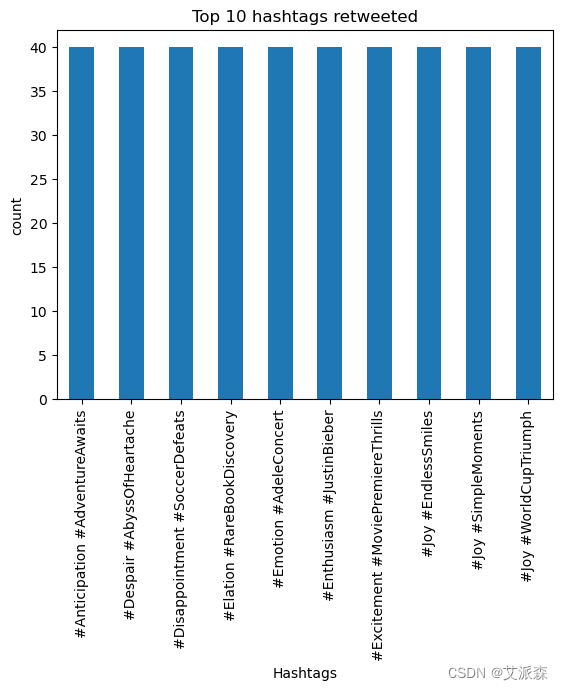
# Q2:用户喜欢的平台顶部是什么?
top_likes_platform = df.groupby('Platform')['Likes'].sum().nlargest(10)
top_likes_platform.plot(kind='bar')
plt.title('Top Platforms by Total Likes')
plt.xlabel('Platform')
plt.ylabel('Total Likes')
plt.show()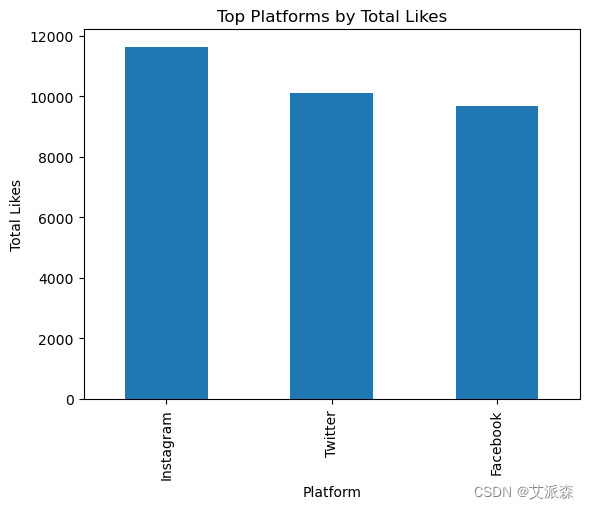
# 问题3:哪个国家的帖子被点赞最多?
top_country_likes=df.groupby('Country')['Likes'].sum().nlargest(10)
top_country_likes.plot(kind='bar')
plt.title('Top country likes')
plt.xlabel('Country')
plt.ylabel('count')
plt.show()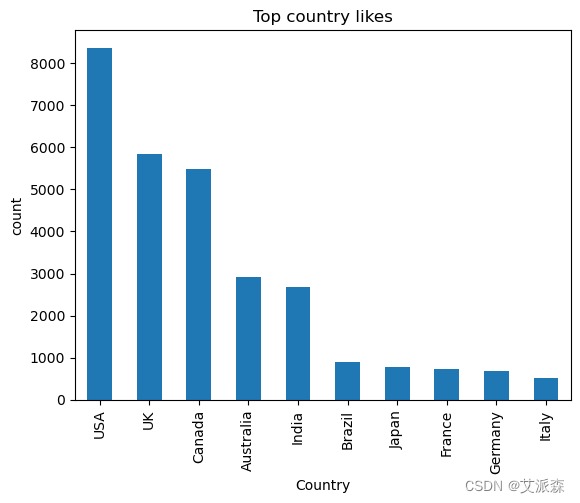
from wordcloud import WordCloud
text = ' '.join(df['Text'])
wordcloud = WordCloud(width=800, height=400, background_color='black').generate(text)
plt.figure(figsize=(10, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.title('Word Cloud for PlayerLine Column')
plt.tight_layout()
plt.show()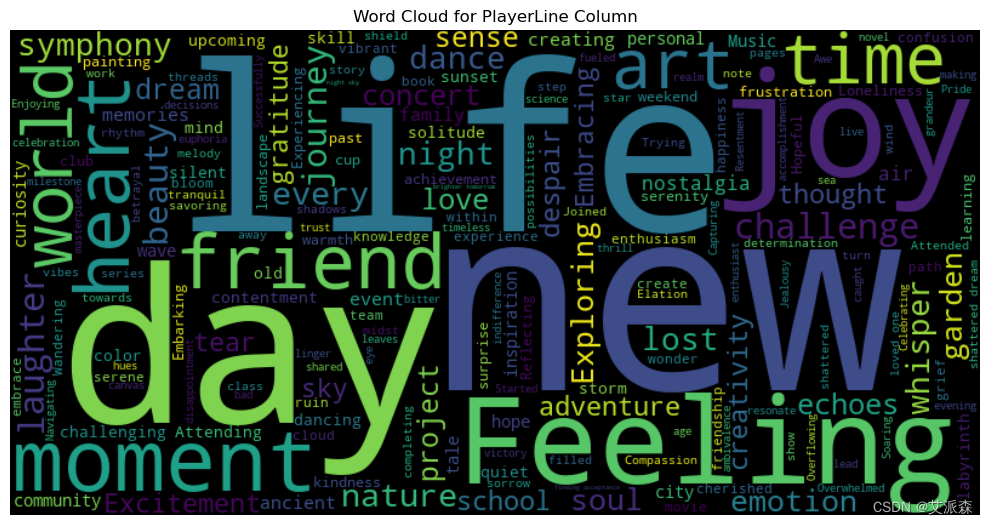
Facebook=df[df['Platform']=='Facebook']
Twitter=df[df['Platform']=='Twitter']
Instagram=df[df['Platform']=='Instagram']# 转发次数最多的10个标签
H_R_f=Facebook.groupby('Hashtags')['Retweets'].max().nlargest(10).sort_values(ascending=False)
H_R_f.plot(kind='bar')
plt.title('Top 10 hashtags retweeted in $/ Facebook $/')
plt.xlabel('Hashtags')
plt.ylabel('count')
plt.show()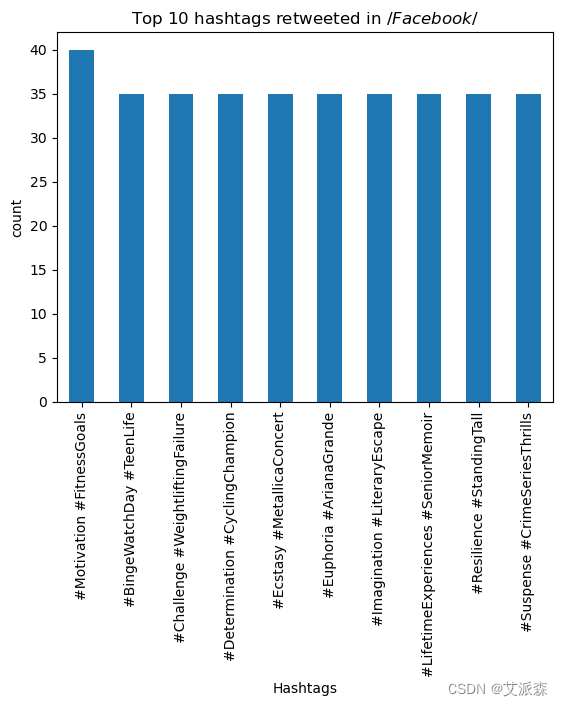
# 用户最喜欢谁?
top_likes_platform_F = Facebook.groupby('User')['Likes'].sum().nlargest(10)
top_likes_platform_F.plot(kind='bar')
plt.title('Top Users by Total Likes IN Facebook')
plt.xlabel('User')
plt.ylabel('Total Likes')
plt.show()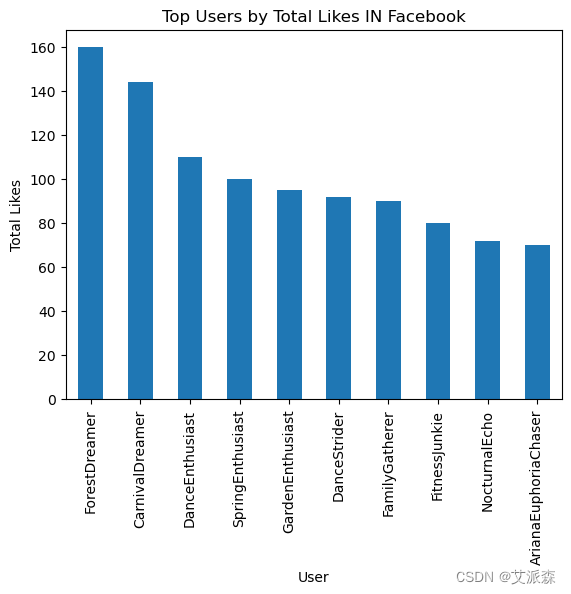
# 转发次数最多的10个标签
H_R_t=Twitter.groupby('Hashtags')['Retweets'].max().nlargest(10).sort_values(ascending=False)
H_R_t.plot(kind='bar')
plt.title('Top 10 hashtags retweeted in $/ Twitter $/')
plt.xlabel('Hashtags')
plt.ylabel('count')
plt.show()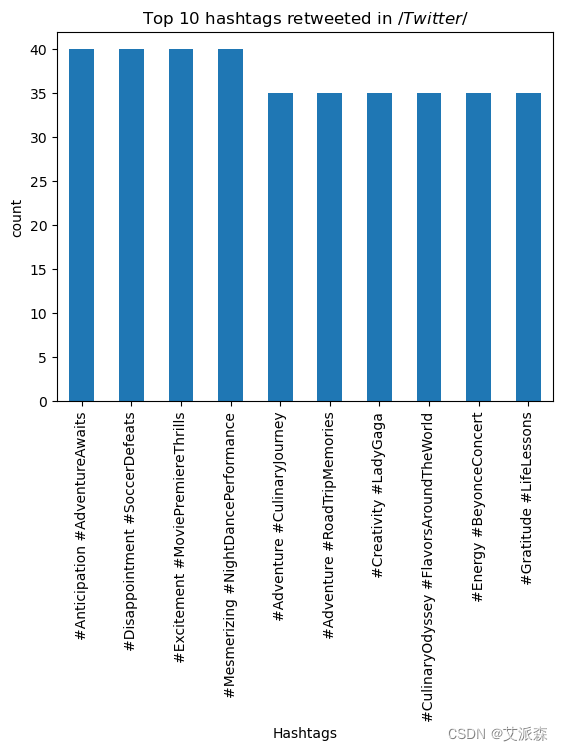
# 用户最喜欢谁?
top_likes_platform_t = Twitter.groupby('User')['Likes'].sum().nlargest(10)
top_likes_platform_t.plot(kind='bar')
plt.title('Top Users by Total Likes IN Twitter')
plt.xlabel('User')
plt.ylabel('Total Likes')
plt.show()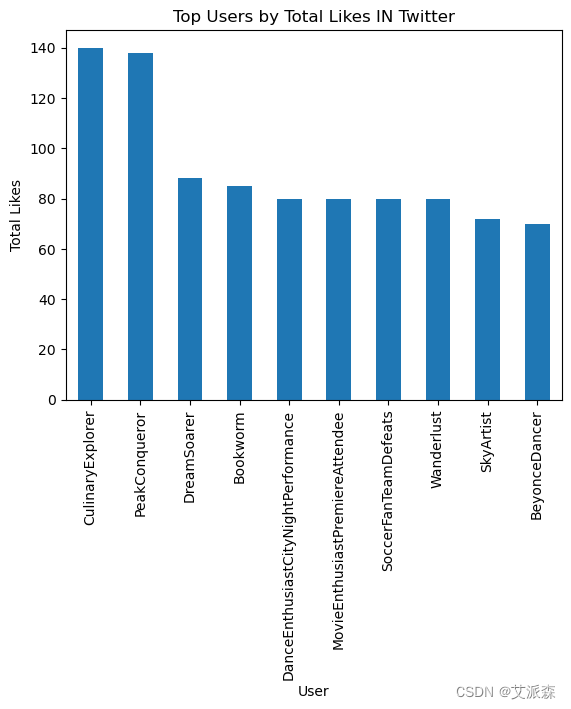
# 转发次数最多的10个标签
H_R_i=Instagram.groupby('Hashtags')['Retweets'].max().nlargest(15).sort_values(ascending=False)
H_R_i.plot(kind='bar')
plt.title('Top 15 hashtags retweeted in $/ Instagram $/')
plt.xlabel('Hashtags')
plt.ylabel('count')
plt.show()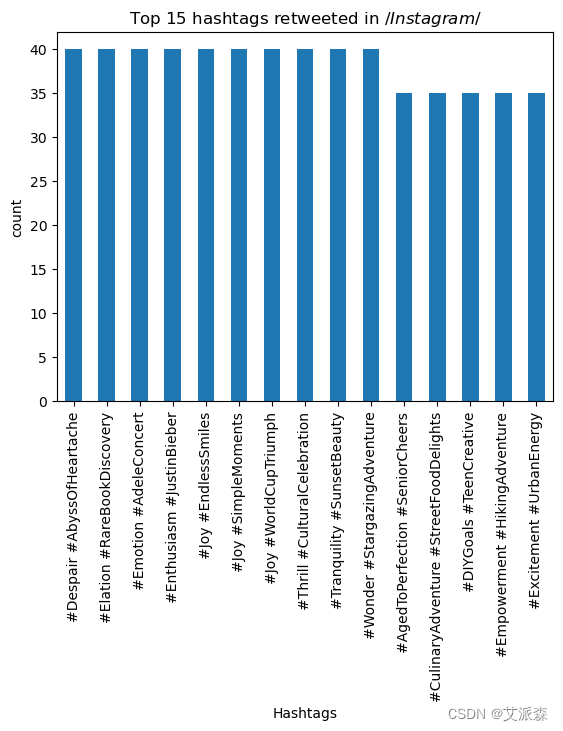
# 用户最喜欢谁?
top_likes_platform_i = Instagram.groupby('User')['Likes'].sum().nlargest(10)
top_likes_platform_i.plot(kind='bar')
plt.title('Top Users by Total Likes IN Instagram')
plt.xlabel('User')
plt.ylabel('Total Likes')
plt.show()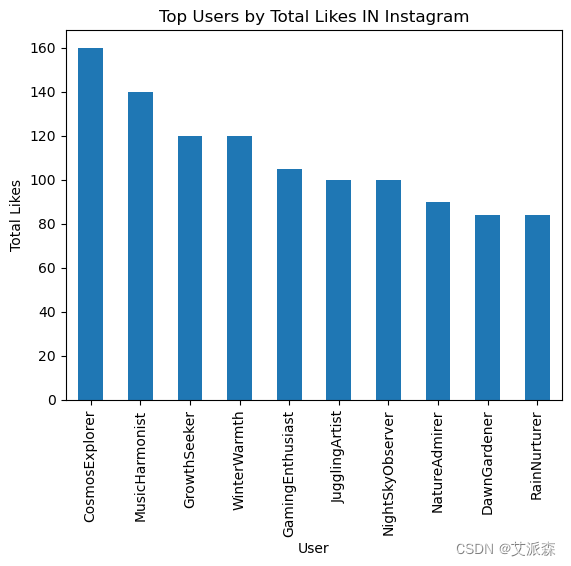
文末推荐与福利
《区块链与金融科技》免费包邮送出3本!

内容简介:
本书从回顾货币及金融发展史出发,分析了数字化货币诞生的必然性及必要性,以详细剖析具有开创性的比特币系统的基础技术、体系架构、数据结构、核心算法、通信协议的方式,解构其金融科技的本质和能力,以点带面、举一反三,揭示区块链技术和应用的演化发展规律,论述区块链作为数字底座对于金融科技及各领域数字化转型升级的关键性支撑作用,以及在实现数字身份、数字资产、审计监管、自治组织方面对当前数字经济、未来元宇宙的稳定性基石作用。
编辑推荐:
·由表及里:从货币变迁到加密技术,从根源细致剖析区块链原理
·以点带面:从区块链的原理到应用,以金融视角洞察区块链技术
·举一反三:从资产权属到数字身份,在数字化转型中落地区块链
·融会贯通:从区块链技术到元宇宙,实现虚拟与现实的辩证统一
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2024-3-2 20:00:00
京东链接:https://item.jd.com/14330972.html
当当链接:http://product.dangdang.com/29669683.html
名单公布时间:2024-3-2 21:00:00
资料获取,更多粉丝福利,关注下方公众号获取