搭建环境
多台linux主机搭建集群+CDH 6.3.2 (Parcel)版本+Apache DolphinScheduler1.3.2版本,本流程在CDH已搭建完成并可正常使用后,开启kerberos功能,Apache DolphinScheduler用于大数据任务管理与执行,是很不错的任务调度平台,是否提前部署均可!
开启kerberos目的:用于用户权限管理与安全认证,在开启kerberos之前的安全防护主要采取开启防火墙的方式,现在进行替换!
本流程开启kerberos后可正常运行的服务包括:
CDH集群正常启用
linux用户创建kerberos权限
hive、hbase、hdfs等服务在主机可正常执行
DolphinScheduler安装正常,任务正常执行,定时任务正常执行
dolphinscheduler的租户权限正常,可进行大数据服务运行和使用
部署kerberos
选择一台主机安装Kerberos服务,执行用户为root
#server端lz1.cmp14722.app
sudo yum install krb5-server krb5-libs krb5-auth-dialog krb5-workstation -y
同步执行集群主机安装client
#client lz1.cmp14722.app02 - lz5.cmp14722.app02
for item incat /etc/hosts | grep lz |awk '{print2}'; do sshitem "hostname; yum install krb5-devel krb5-workstation -y" ; done
如果没有设置ssh免密登录其他主机,需要手动输入每个主机登录密码,建议设置,后面也会用到,设置方法网上很多,暂略。(与一台台主机自己安装一样)
插播一句,如果ssh免密登录设置后还是不能登录,可检查所有登录主机用户目录下的.ssh文件夹权限(700)以及文件夹内authorized_keys(600)文件权限


配置文件
配置文件修改2个
- /etc/krb5.conf文件中default_realm对应的值随便起一个即可,realms部分选择服务主机,这里我选择安装主机对应hostname
sudo vi /etc/krb5.conf
# Configuration snippets may be placed in this directory as well
includedir /etc/krb5.conf.d/
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
[libdefaults]
dns_lookup_realm = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
rdns = false
pkinit_anchors = FILE:/etc/pki/tls/certs/ca-bundle.crt
default_realm =_BIGDATA.COM
_dns_lookup_kdc = false
#default_ccache_name = KEYRING:persistent:%{uid}
[realms]
BIGDATA.COM_= {_ kdc = lz1.cmp14722.app
admin_server = lz1.cmp14722.app
}
[domain_realm]
_.cmp14722.app =_BIGDATA.COM
_cmp14722.app =_BIGDATA.COM
- /var/kerberos/krb5kdc/kdc.conf文件我这里保持不变
sudo vi /var/kerberos/krb5kdc/kdc.conf
[kdcdefaults]
kdc_ports = 88
kdc_tcp_ports = 88
[realms]
EXAMPLE.COM_= {_ #master_key_type = aes256-cts
acl_file = /var/kerberos/krb5kdc/kadm5.acl
dict_file = /usr/share/dict/words
admin_keytab = /var/kerberos/krb5kdc/kadm5.keytab
supported_enctypes = aes256-cts:normal aes128-cts:normal des3-hmac-sha1:normal arcfour-hmac:normal camellia256-cts:normal camellia128-cts:normal des-hmac-sha1:normal des-cbc-md5:normal des-cbc-crc:normal
}
- 将krb5.conf分发到其他主机客户端
for item in
cat /etc/hosts | grep lz | grep -v 1 |awk '{print2}'; do scp /etc/krb5.confitem:/etc/ ; done
启动kerberos
- 创建kerberos数据库
sudo kdb5_util create -rBIGDATA.COM-s
#输入密码
#完成
- 启动kerberos
service krb5kdc start
service kadmin start
#查看服务状态
service krb5kdc status
service kadmin status
用户认证流程
- 创建kerberos认证用户
#进入kerberos服务
kadmin.local
#查看已有认证用户
listprincs
#新增root用户认证
addprinc root/admin@BIGDATA.COM
#输入密码
#确认密码
#完成
#创建root用户的keytab文件认证
ktadd -k /opt/keytab/root.keytab -norandkey root/admin@BIGDATA.COM
#创建集群认证用户cloudera-scm,用于后面cdh开启kerberos使用
addprinc cloudera-scm/admin@BIGDATA.COM
#查看认证用户
listprincs
#退出
quit
- root用户认证
#keytab认证
kinit -kt /opt/keytab/root.keytab root/admin@BIGDATA.COM
#查看当前生效token
klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: root/__admin@BIGDATA.COM
Valid starting Expires Service principal
_01/30/2023 11:13:08 01/31/2023 11:13:08_krbtgt/BIGDATA.COM@BIGDATA.COM
分发root的keytab到其他主机,实现root用户主机间的网络认证
for item in
cat /etc/hosts | grep lz | grep -v 1 |awk '{print2}'; do sshitem "mkdir /opt/keytab"; scp /opt/keytab/root.keytab $item:/opt/keytab/ ; done
CDH启用kerberos
进入CM界面,打开管理-》安全
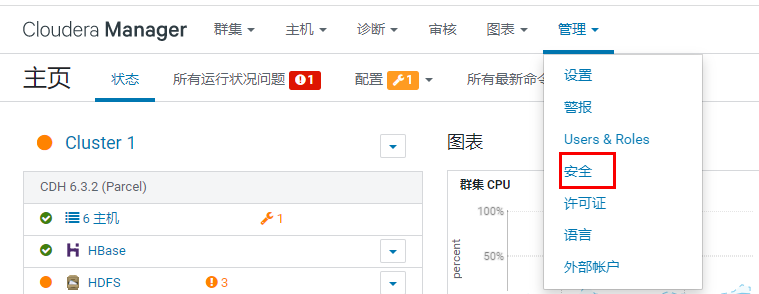
点击启用kerberos
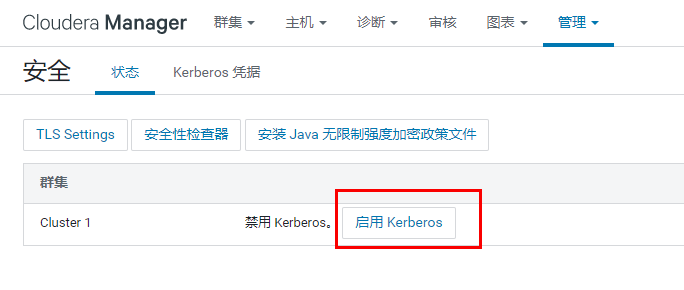
全部勾选是

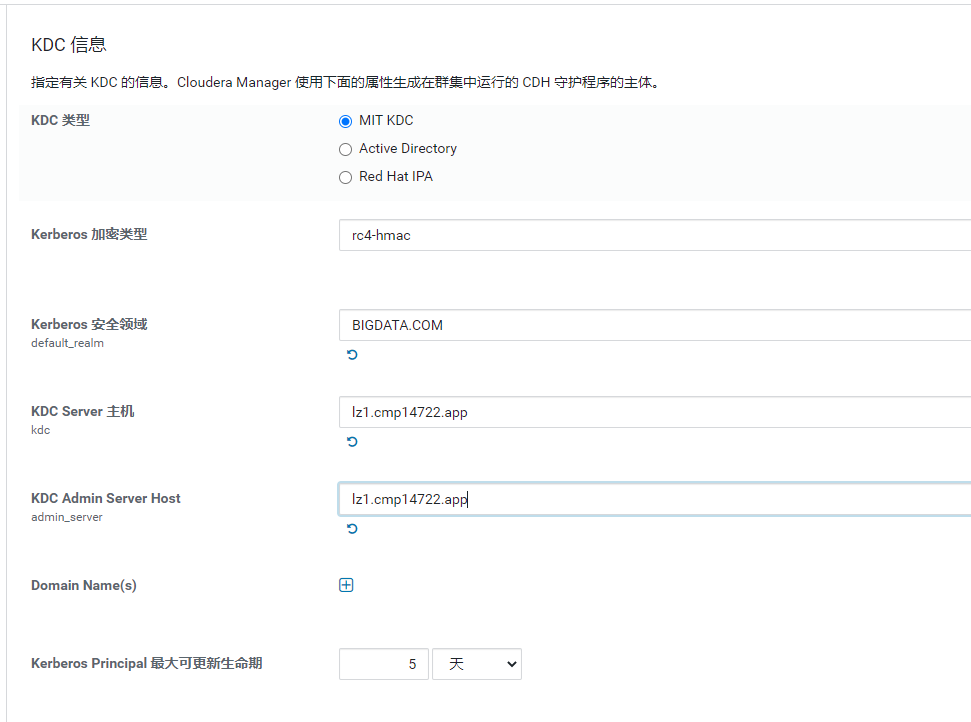
填写配置信息,server与上面krb5.conf中配置内容一致
下一步,这里可以不勾选
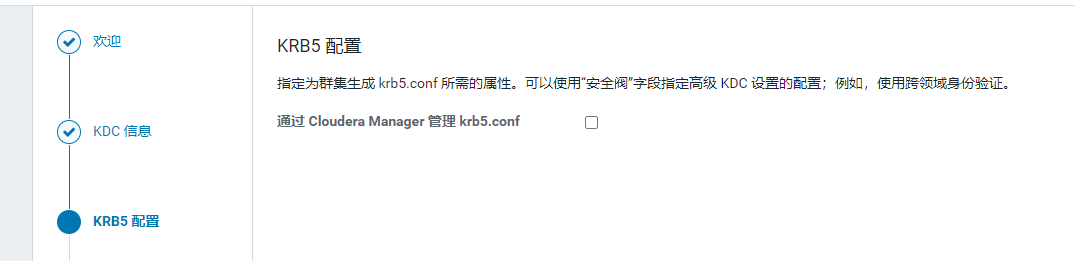
填写上面创建的账号与密码 cloudera-scm/admin@BIGDATA.COM
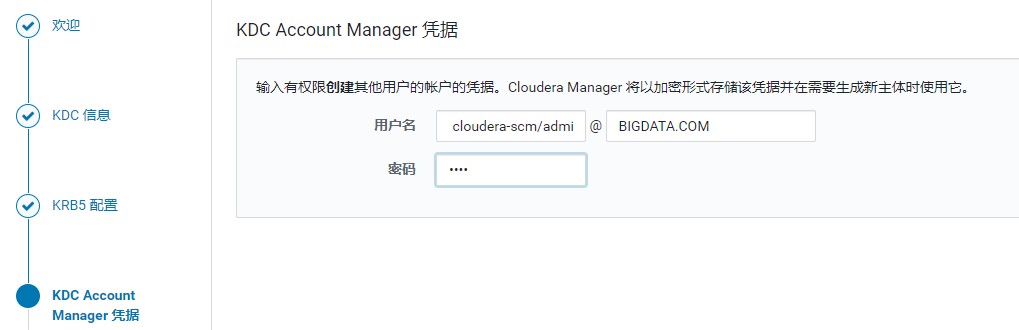
后面直接点继续,完成后,进行初始化,直至最终完成开启
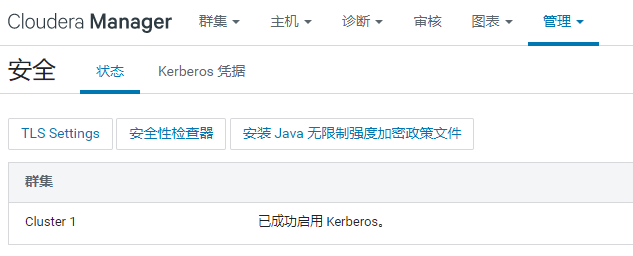
重启集群,查看集群服务状态
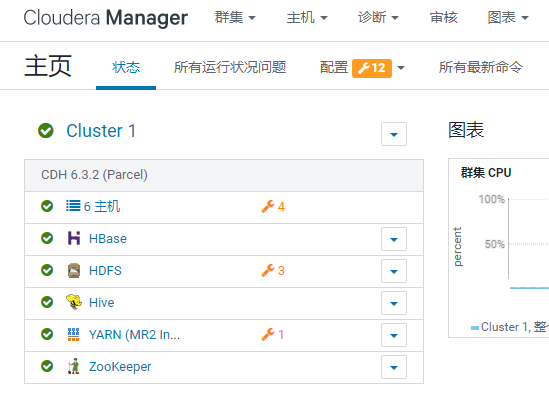
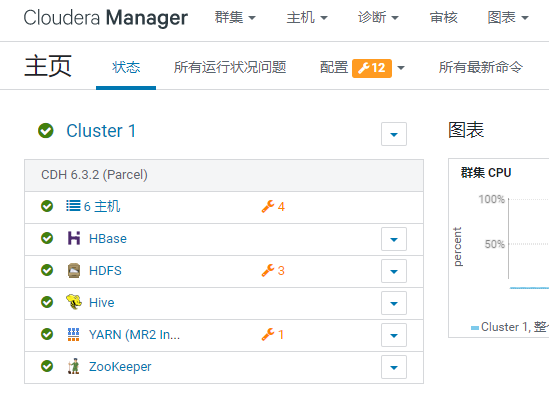
主机上验证集群服务
通过root用户执行hive、hbase、hdfs命令
#hive命令
hiveshow databases;
create database bigdata;
#hbase命令
hbase shell
list
#hdfs命令
hdfs dfs -ls /
如遇到某些命令没有权限或者无法通过TOKEN认证等问题,可以在kerberos服务主机上,创建对应的服务用户,进行keytab认证(参见上面用户认证流程),通过对应的服务认证,完成操作命令。认证不需要切换用户,如在root用户下可执行命令kinit -kt /opt/keytab/hbase.keytab hbase/admin@BIGDATA.COM,进行hbase的用户认证。
hbase服务也可进行用户权限授权,需要通过hbase用户的kerberos认证,作为管理员进行操作
#进入hbase
hbase shell
#查看现有用户权限user_permission
#对root用户赋权,R写、W读、X执行、C创建、A管理员
grant 'root', 'RWXCA'
禁用kerberos:如何禁用CDH集群Kerberos-腾讯云开发者社区-腾讯云
DolphinScheduler启用kerberos
配置文件
在进行Apache DolphinScheduler安装时,主要在install_config.conf的配置,参见官网的配置流程即可,如果已经安装完成,可以修改common.properties的配置文件,这里主要说kerberos的配置部分,其他部分这里不赘述
在Apache DolphinScheduler所在Master主机上进行配置文件修改即可
vi /opt/dolphinscheduler/conf/common.properties
# resource.storage.type=HDFS
resource.storage.type=HDFS
# whether kerberos starts
hadoop.security.authentication.startup.state=__true
# java.security.krb5.conf.path=/opt/dolphinscheduler/conf/krb5.conf
java.security.krb5.conf.path=/etc/krb5.conf
# login user from keytab username
login.user.keytab.username=__hdfs/admin@BIGDATA.COM
# loginUserFromKeytab path
login.user.keytab.path=__/opt/keytab/hdfs.keytab
这里主要涉及keytab认证选择的用户,用户需要对集群有操作权限,这里选择hdfs用户,确保已创建kdfs用户对应keytab;资源存储选择的HDFS方式(这里其他配置参考官网)
重启DolphinScheduler系统
sh stop-all.sh
sh start-all.sh
admin登录DolphinScheduler验证
可正常创建租户等其他操作
用租户bidata执行大数据任务
由于需要用linux的bidata用户执行任务,因此需要创建bidata用户的kerberos认证,方法同上,因为kerberos认证有有效期,保证任务和定时任务不失败,需要通过crontab创建定时认证
#创建定时任务
crontab -e
58 23 * * * kinit -kt /opt/keytab/bidata.keytab bidata/admin@BIGDATA.COM
定时任务在所有worker主机上均需要设置,因为dolphinscheduler的任务执行默认是随机分配的
遇到的问题
集群重启后hbase服务异常
hbase服务无法完成init过程,我通过删除zk中的hbase,完成了启动。
#进入zk,/bin/zookeeper-client或zk目录下执行sh zkCli.sh
zookeeper-client
[zk: localhost:2181(CONNECTED) 3] ls /
[dolphinscheduler, hive_zookeeper_namespace_hive, zookeeper, hbase]
[zk: localhost:2181(CONNECTED) 3] deleteall /hbase
#或逐个删除/hbase下的内容
重启后成功
用户无法访问集群服务
Caused by: java.io.IOException: org.apache.hadoop.security.AccessControlException: Client cannot authenticate via:[TOKEN, KERBEROS]
上面的错误是kerberos认证问题,当前用户没有进行kerberos认证或者本身对服务没有权限,需要具体服务具体授权,针对具体服务切换kerberos认证用户
用户实践案例
奇富科技 蜀海供应链 联通数科拈花云科
蔚来汽车 长城汽车集度长安汽车
思科网讯生鲜电商联通医疗联想
新网银行消费金融 腾讯音乐自如
有赞伊利当贝大数据
联想传智教育Bigo
通信行业 作业帮
迁移实践
Azkaban Ooize
Airflow (有赞案例) Air2phin(迁移工具)
Airflow迁移实践
Apache DolphinScheduler 3.0.0 升级到 3.1.8 教程
新手入门
选择Apache DolphinScheduler的10个理由
Apache DolphinScheduler 3.1.8 保姆级教程【安装、介绍、项目运用、邮箱预警设置】轻松拿捏!
Apache DolphinScheduler 如何实现自动化打包+单机/集群部署?
Apache DolphinScheduler-3.1.3 版本安装部署详细教程
Apache DolphinScheduler 在大数据环境中的应用与调优
参与Apache DolphinScheduler 社区有非常多的参与贡献的方式,包括:
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?
q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
本文由 白鲸开源科技 提供发布支持!






![[DEBUG] spring boot-如何处理链接中的空格等特殊字符](https://img-blog.csdnimg.cn/direct/e60366f9b91b4e4b87816495f750bff1.png)