ElasticSearch架构介绍及原理解析·文章目录
- 一、Elasticsearch是什么?
- 1.简介
- 2.历史与发展
- 3.有关概念
- 1.cluster
- 2.shards
- 3.replicas
- 4.recovery
- 5.river
- 6.gateway
- 7.discovery.zen
- 8.Transport
- 4.安装
- 二、ElasticSearch架构介绍及原理解析
- 1.基本架构
- 1.1 进程节点
- 1.2 负载均衡
- 1.3 高可用
- 1.4 可扩展
- 2.ElasticSearch原理解析
- 2.1 数据路由
- 2.2 数据写入
- 2.3 数据查询

一、Elasticsearch是什么?
Elasticsearch 是位于 Elastic Stack 核心的分布式搜索和分析引擎。Logstash 和 Beats 有助于收集、聚合和丰富您的数据并将其存储在 Elasticsearch 中。Kibana 使您能够以交互方式探索、可视化和分享对数据的见解,并管理和监控堆栈。
Elasticsearch 为所有类型的数据提供近乎实时的搜索和分析。无论您拥有结构化或非结构化文本、数字数据还是地理空间数据,Elasticsearch 都能以支持快速搜索的方式高效地存储和索引它。您可以超越简单的数据检索和聚合信息来发现数据中的趋势和模式。随着您的数据和查询量的增长,Elasticsearch 的分布式特性使您的部署能够随之无缝增长。
1.简介
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
Elasticsearch使用Lucene,并试图通过JSON和Java API提供其所有特性。它支持facetting和percolating,如果新文档与注册查询匹配,这对于通知非常有用。另一个特性称为“网关”,处理索引的长期持久性;例如,在服务器崩溃的情况下,可以从网关恢复索引。Elasticsearch支持实时GET请求,适合作为NoSQL数据存储,但缺少分布式事务。
2.历史与发展
Shay Banon在2004年创造了Elasticsearch的前身,称为Compass。在考虑Compass的第三个版本时,他意识到有必要重写Compass的大部分内容,以“创建一个可扩展的搜索解决方案”。因此,他创建了“一个从头构建的分布式解决方案”,并使用了一个公共接口,即HTTP上的JSON,它也适用于Java以外的编程语言。Shay Banon在2010年2月发布了Elasticsearch的第一个版本。
Elasticsearch BV成立于2012年,主要围绕Elasticsearch及相关软件提供商业服务和产品。2014年6月,在成立公司18个月后,该公司宣布通过C轮融资筹集7000万美元。这轮融资由新企业协会(NEA)牵头。其他投资者包括Benchmark Capital和Index Ventures。这一轮融资总计1.04亿美元
2015年3月,Elasticsearch公司更名为Elastic。
在2018年6月,Elastic提交了首次公开募股申请,估值在15亿到30亿美元之间。公司于2018年10月5日在纽约证券交易所挂牌上市。一些组织将Elasticsearch作为托管服务提供。这些托管服务提供托管、部署、备份和其他支持。大多数托管服务还包括对Kibana的支持。
Elasticsearch 自从诞生以来,其应用越来越广泛,特别是大数据领域,功能也越来越强大,但是如何有效的监控管理 Elasticsearch 一直是公司所面对的难题,由于 Elasticsearch 集群的稳定性,决定了其业务发展的高度,对于一个应用来说其稳定是第一目标,所以完善的监控体系是必不可少的。此外,Elasticsearch 写入和查询对资源的消耗都很大,如何合理有效地控制资源,既能满足写入和查询的需求,又能满足资源充分利用,这是公司必须面对的问题。
在国内,还没较为完善的面向 Elasticsearch 的监控管理平台,很多企业往往只关注搭建一套简单分布式的集群环境,而对这个集群的缺乏监控和管理,元数据混乱,写入和查询耦合,缺乏监控一旦集群出现问题,就会导致数据丢失,甚至很容易导致线上应用故障。相比于小公司,中大型公司的资金较为充足,所以中大型公司,会选择为每个应用去维护一套集群,但是这每当资源不够需要扩容或者缩容时,极其不方便,需要增加删除节点,其运维成本过高。而且对每个应用来说,可能不能够充分利用资源,但是如果和其他应用混合部署,但是又涉及到复杂的资源分配问题,而且随着应用的发展,资源经常需要变动。在国外,ELasticsearch 的应用也很广泛,也有对 Elasticsearch 进行很好的监控和管理,Amazon AWS中也有基于 Elasticsearch 构建的平台服务,帮助电商应用程序,网站等提供安全、高可靠、低成本、低延时、高吞吐量的个性化搜索。虽然,对集群进行了监控和管理,但是管理的维度还是集群级别的,而对于应用往往是模板级别的,如果应用无法与集群一一对应,那就无法进行更高效的管理。这无法满足公司级别想要高效利用资源,集群内部能支持多个应用的场景。
3.有关概念
1.cluster
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
2.shards
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
3.replicas
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
4.recovery
代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
5.river
代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的。
6.gateway
代表es索引快照的存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘。gateway对索引快照进行存储,当这个es集群关闭再重新启动时就会从gateway中读取索引备份数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
7.discovery.zen
代表es的自动发现节点机制,es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
8.Transport
代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
4.安装
以windows操作系统和ES0.19.7版本为例:
①下载elasticsearch-6.4.1.zip
②直接解压至某目录,设置该目录为ES_HOME环境变量
③安装JDK,并设置JAVA_HOME环境变量
④在windows下,运行 %ES_HOME%\bin\elasticsearch.bat即可运行
以head插件为例:
联网时,直接运行%ES_HOME%\bin\plugin --install mobz/elasticsearch-head。
不联网时,下载elasticsearch-head的zipball的master包,然后运行%ES_HOME%\bin\plugin --url file:///[path-to-downloadfile] --install head,其中[path-to-downloadfile]是下载后master包的绝对路径。
安装完成,重启服务,在浏览器打开 http://localhost:9200/_plugin/head/ 即可。
二、ElasticSearch架构介绍及原理解析
1.基本架构
1.1 进程节点
在生产环境部署Elasticsearch时,都是一台机器上启动一个Elasticsearch进程实例,比如我们有三台机器,那么三个ES进程实例就构成了一个ES集群,每个实例我们把它叫做一个节点:
1.2 负载均衡
当我们建立Index索引时,必须指定索引有几个primary shard,以及primary shard的replica shard数量。
比如,创建一个名称为 test_index的索引,共有3个primary shard,每个primary shard都有2个replica shard,那总共就是9个shard:
- test_index索引的数据会被均匀分布到3个primary shard—— P1、P2、P3上,而3个primary shard又会被负载均衡到ES节点上。我们现在有三个ES进程节点,那么primary shard的分布就是类似下面这样的,每个ES节点上分布1个primary shard:
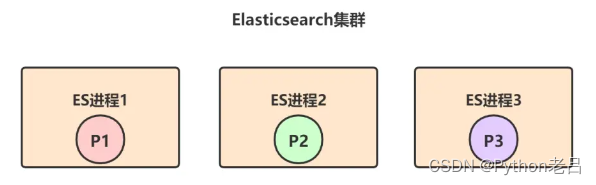
- 每个primary shard都有两个replica shard,replica shard其实就是个数据备份,类似于msater/slave模式中的slave节点。所以6个replica shard也会被负载均衡到各个ES进程节点上,最终的shard分布可能是下面这样的:
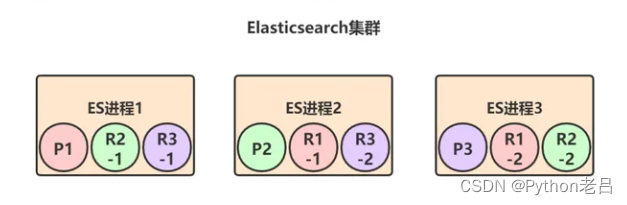
上图中,颜色相同的代表一个primary shard和它的所有replica shard,比如对于 P1这个primary shard,它有两个replica shard: R1-1和 R1-2。
Elasticsearch有一个原则:primary shard和它对应的replica shard不能全部署在同一个节点上,否则节点挂了的话,数据和拷贝都会丢失。
1.3 高可用
Elasticsearch保证集群高可用的方式和大多数分布式框架类似,就是采用主从模式+选举的方式。每个primary shard都有其所属的replica shard作为副本,如果primary shard挂了,就会从所有replica shard中选举出一个新的Leader作为primary shard。
以下图的部署来具体看下Elasticsearch是如何保证集群的高可用的:
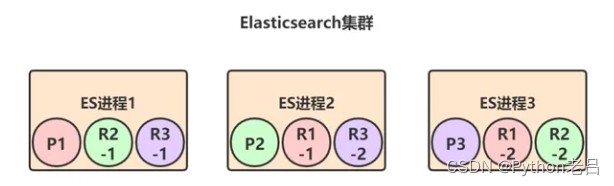
初始情况下,三个ES进程节点都正常运行,此时集群的状态就是green,也就是完全正常状态。
假设ES进程1节点宕机了,我们来看下整个集群的可用性:
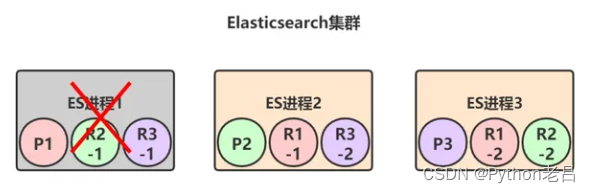
上图中,节点1宕机了,所以对于P1这个primary shard,就是非active状态,此时集群状态转为red。但是节点2和节点3上仍然保存着完整的数据,就算再挂掉一个节点,只剩下一个节点2或节点3,整个集群也还是可用的。
当集群状态变为red后,P1的两个副本——R1-1和R1-2就会开始一轮选举,胜出者成为新的primary shard,比如我们假设R1-1胜出:
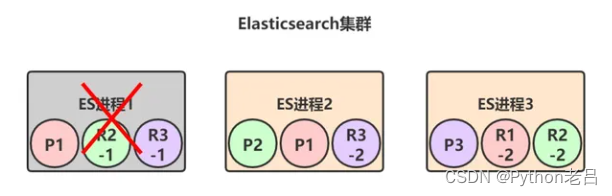
选举完成后, test_index索引的三个primary shard都是存活的,但是P1只有一个repilca shard是active状态,所以此时集群的状态变成yellow。
最后,当宕机的那个节点1恢复后,上面的shard又会重新加入到集群中,原来的P1发现节点2上已经有了新的primary shard,自己就会变成repilca shard,并进行数据同步:
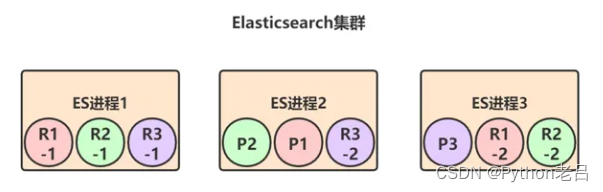
1.4 可扩展
Elasticsearch实现水平扩展的方式就是数据分散集群模式,也就是数据分片。
一个索引的数据会被均匀分布到它的primary shard中,比如 test_index索引一共有3T的数据,那么每个primary shard就有1T数据。replica shard是primary shard的副本,所以也包含1T数据,此时集群的情况可能是下面这样的:
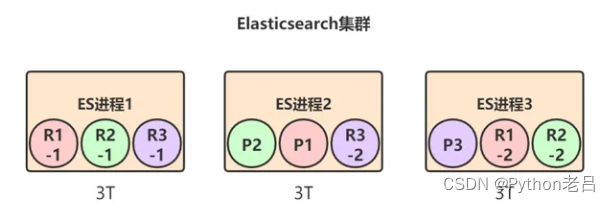
如果每个ES节点的磁盘容量总共也就3T多怎么办?此时所有节点的磁盘都几乎撑满了。
Elasticsearch可以透明的实现节点水平扩展,只要再找台机器,启动一个Elasticsearch进程,将其加入到当前集群中,那么上面的shard重新在节点上自动均匀分布。比如我们再加三台机器:
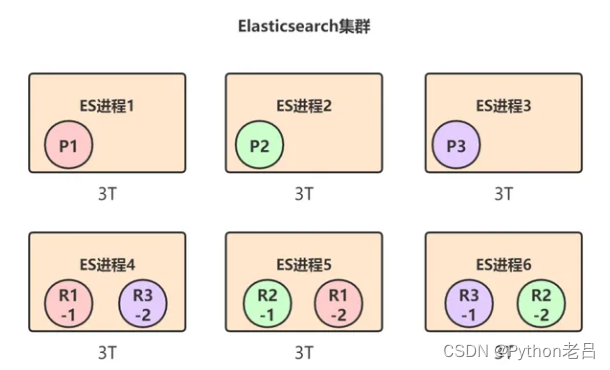
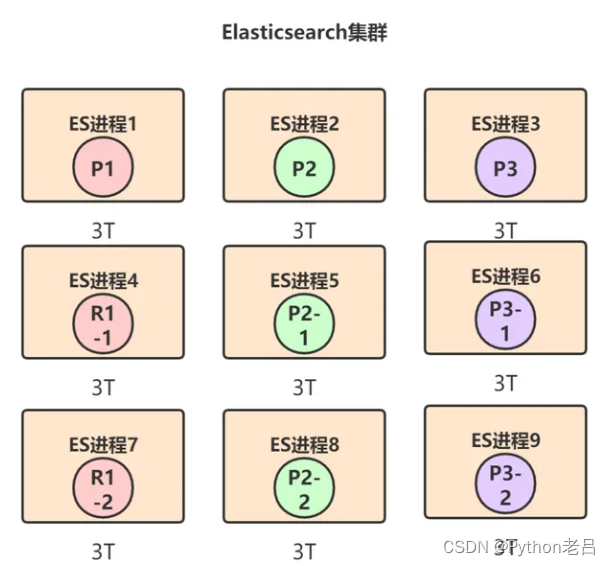
通过这种方式,最多可以加到9台机器,刚好对应9个shard:
2.ElasticSearch原理解析
在Elasticsearch中,记录是以document为单位存储在shard上的。比如,一个名称为 test_index的索引,共有3个primary shard,那么对于任意一条document记录,只能存在于其中的某一个primary shard上,如下图(为简便起见,省略了replica shard):
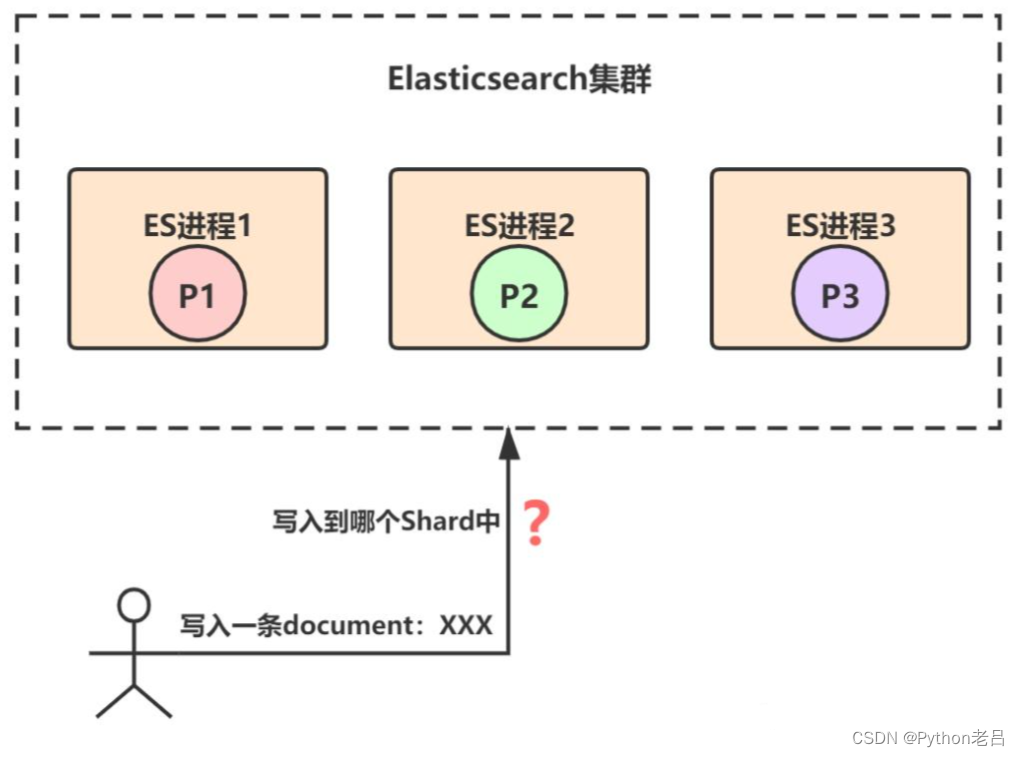
那么,问题来了,对于任意一条document记录,到底该分配到哪个shard上呢?
2.1 数据路由
事实上,Elasticsearch就是采用了hash路由算法,对document记录的id标识进行计算,产生了一个shard序号,通过这个shard序号就可以立即确认写到哪个shard里面。
举个例子,假设我们往 test_index这个索引里面写入了一条document记录(id=1024),然后按照路由算法 shard=hash(routing_key)%number_of_primary_shards,计算出shard=1,那么就写到序号为1的那个primary shard中。
我们也可以手动指定document的routingkey值,那么routingkey相同的document就会路由到同一个shard中。
2.2 数据写入
假设我们ES集群是下面这个样子的,3个primary shard,每个primary shard都有一个副本。初始时,客户端(集成了Elasticsearch Client SDK)发起了一条document的写入请求,请求可能hit到任意某个ES节点上,hit到的这个节点也叫做coordinate node(协调节点):
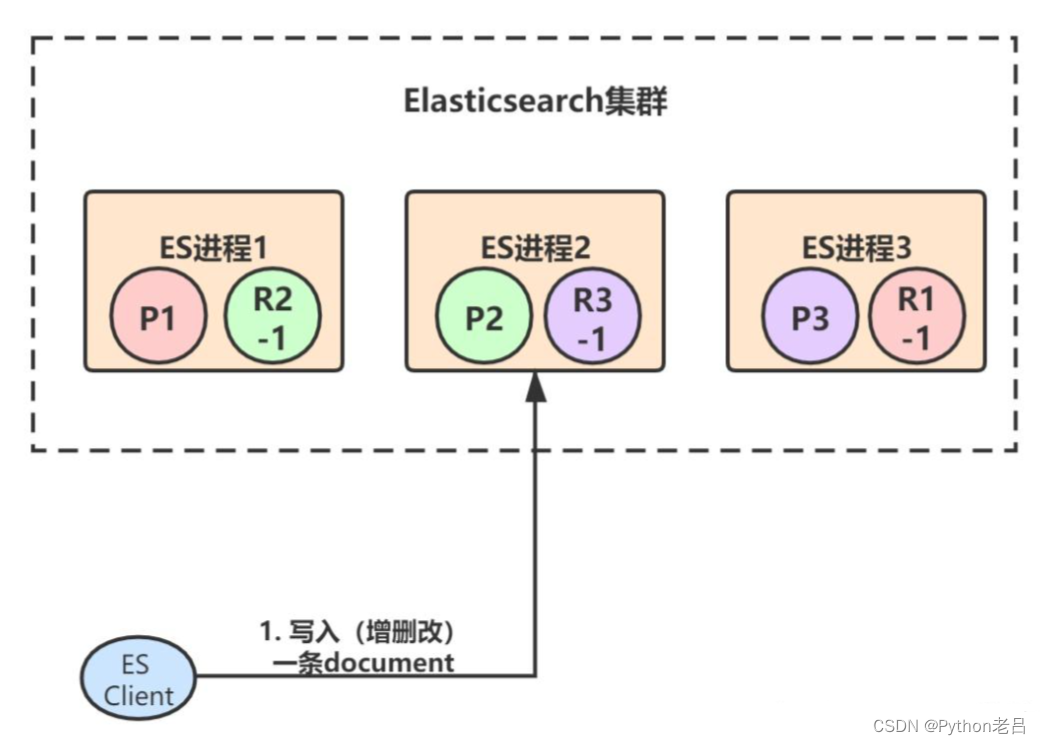
由于ES进程1、2、3构成了一个集群,所以每个ES节点其实都知道集群中的其它节点的信息,包括集群中一共有多少primary/replica shard,每个节点上分配着哪些primary/replica shard。
假设ES进程2节点(协调节点)接受到了请求,于是根据document的id进行hash计算,发现结果是3,也就是应该由P3这个primary shard处理这个请求,所以就会把请求转发给ES进程3节点上的P3:
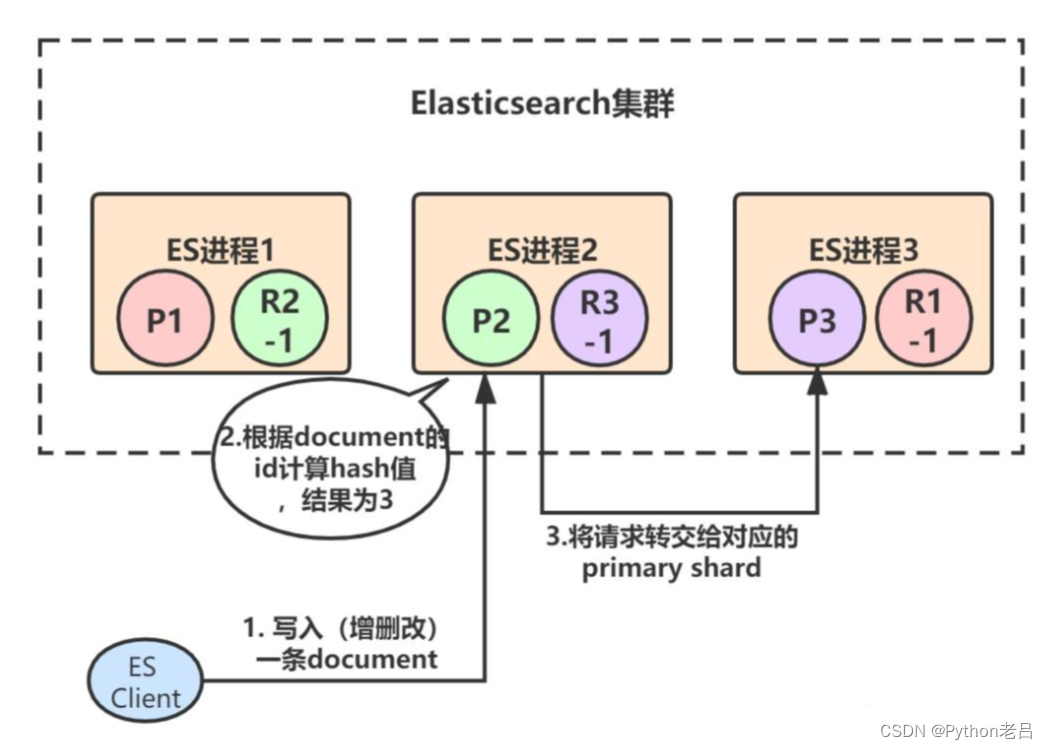
primary shard 3处理完请求后,会将数据同步到自己的replica shard(R3-1),同步完后响应ES进程2:
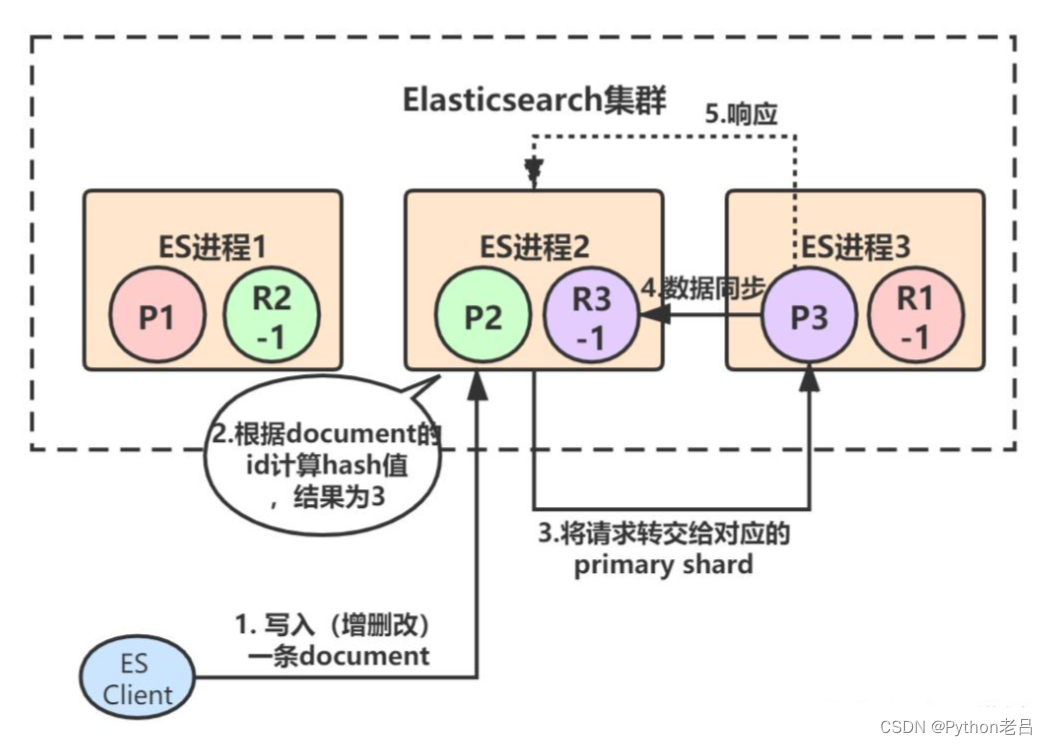
最后,ES进程2(协调节点)收到响应后,返回给ES client结果:
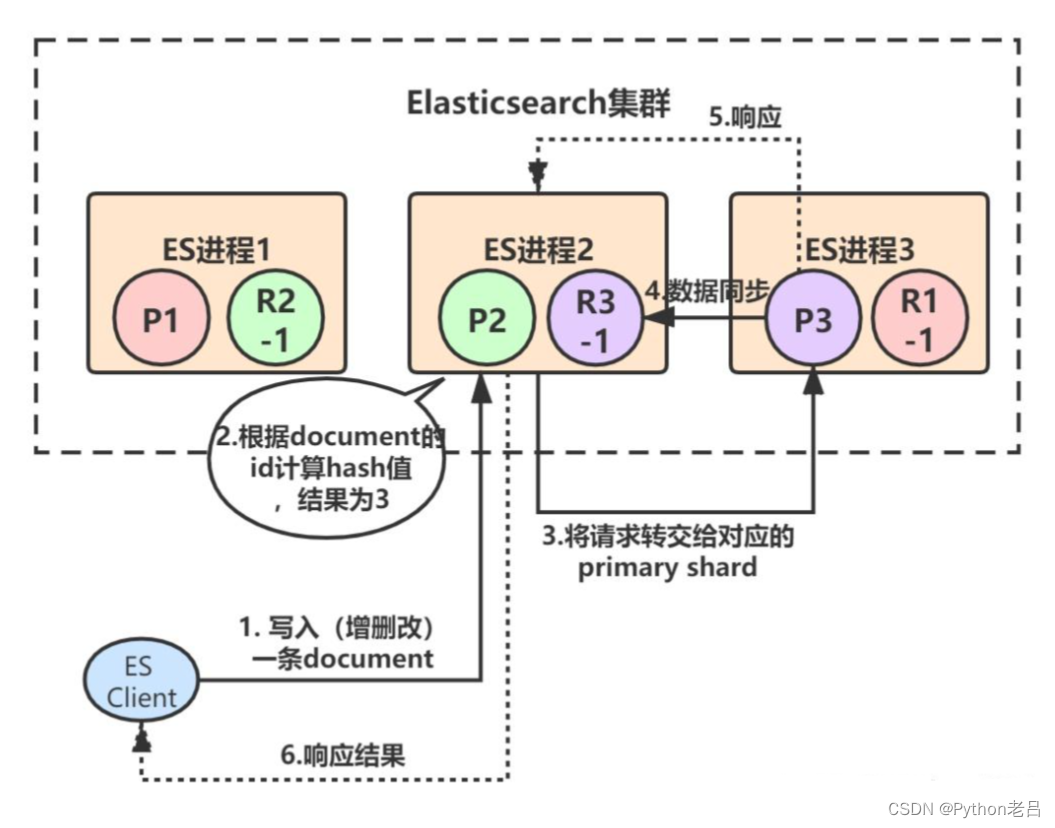
从上述流程也可以看出,Elasticsearch对于写请求,最终都是转交给primary shard去处理的。
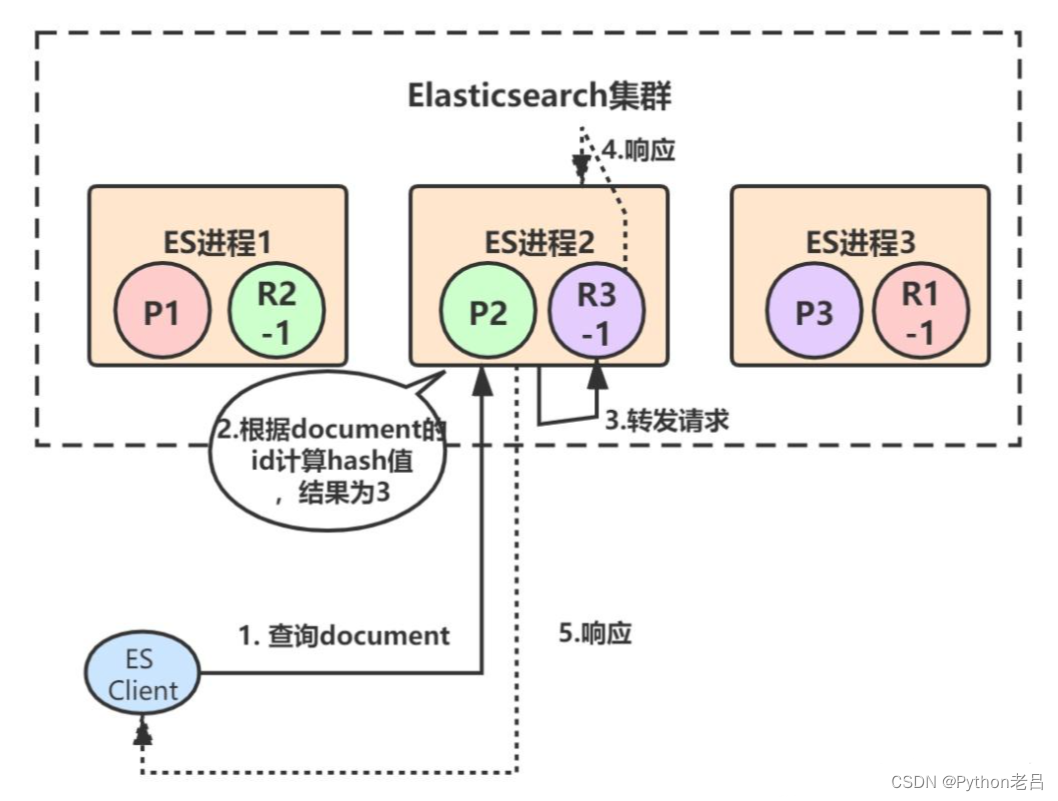
2.3 数据查询
document数据查询的原理基本和写入类似,只不过查询请求既可以由primary shard处理,也可以由replica shard处理,这样就提高了系统的吞吐量和性能。
coordinate node(协调节点)在接受到查询请求后,会采用round-robin算法,在对应的primary shard及其所有replica中随机选择一个发送请求,以达到读请求负载均衡的目的。
我们继续通过流程图来看,首先客户端发起查询某个document的请求,假设命中到ES进程2,ES进程2根据document Id计算出应该由primary shard 3来处理:
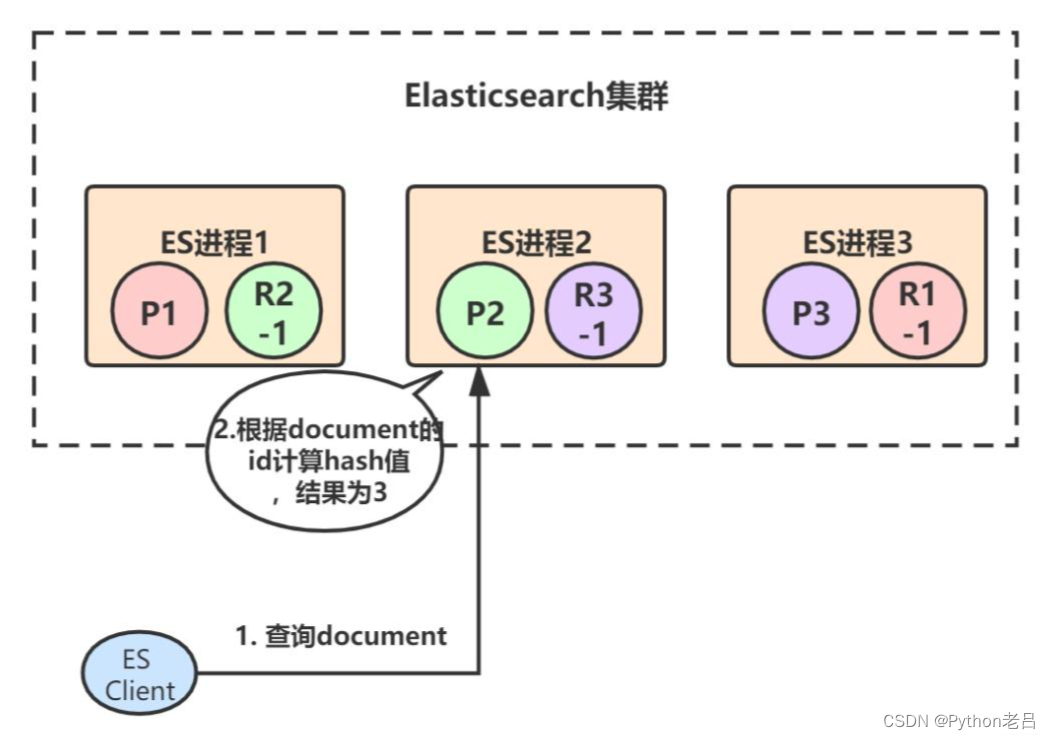
primary shard 3有一个replica,所以协调节点会采用round-robin算法选取其中一个转发请求,比如选择了R3-1,然后将请求转发给它,R3-1查询得到结果后返回,最终ES进程2将结果返回给客户端:
![[HackmyVM]靶场 W140](https://img-blog.csdnimg.cn/direct/5615bb768cfb42e28500ef712575e2e9.png)