DT个人理解
emmm, 这里的Transformer 就和最近接触到的whisper一样,比起传统Transformer,自己还设计了针对特殊情况的tokens。比如whisper里对SOT,起始时间,语言种类等都指定了特殊tokens去做Decoder的输入和输出。
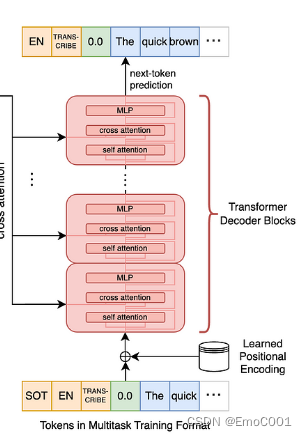
DT这里的作为输入的Tokens由RL里喜闻乐见的历史数据:State,Action,Reward组成。输出只是简单的Actions(历史+即将需要的)
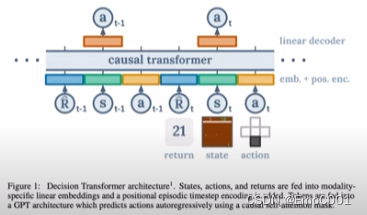
这里的输入是基于“Retures to go”的设计:Sum of remaining future returns. 类似于从当下的此时此刻开始,到目的地结束,你有N条路径可以走,但是,你需要在训练过程中,让model学习预测当下到未来可获得的最高reward。但因为你对未来是空白的,Monte carlor 是一种喜闻乐见的方式去疯狂采样模拟来估计,目前自己能想到的,但是还没看到后面,作者到底是怎么处理这一步的。好吧,不是我想的那样,也对,不然猴年马月才能得到最高的reward。作者在这里的处理是将reward直接放进0-1之间,并且取1作为目标。So called “Goal conditioning”,就是先设定目标,再根据离目标做出学习调整。
~ 自己就是RL开始的,后来