目录
🌼整体思路
🎂基础API
fputs
可变参数宏 __VA_ARGS__
fflush
🚩流程图与日志类定义
流程图
日志类定义
🌼功能实现
生成日志文件 && 判断写入方式
日志分级与分文件
🌼整体思路
日志系统分两部分,
一:单例模式与阻塞队列的定义
二:日志类的定义与使用
这里介绍日志类的定义与使用,具体涉及基础API,流程图与日志类的定义,功能实现
- 基础API
描述 fputs,可变参数宏__VA__ARGS__,fflush - 流程图与日志类定义
描述日志系统整体运行流程,介绍日志类的具体定义 - 功能实现
结合代码分析同步 / 异步写文件逻辑,分析超行,按天分文件和日志分级的具体实现
🎂基础API
更好的源码阅读体验~
fputs
#include<stdio.h>
int fputs(const char *str, FILE *stream);
- str,一个数组,包含要写入的 以空字符终止的字符序列
- stream,指向FILE对象的指针,该FILE对象标识了要被写入字符串的流
可变参数宏 __VA_ARGS__
__VA_ARGS__,可变参数的宏,定义宏时,定义中参数列表的最后一个参数为省略号,实际使用中有时会加##,有时不加
myprintf("CSDN zhanghm1995")
-> printf("CSDN zhanghm1995")
myprintf("CSDN zhanghm1995 is %d years", 2)
-> printf("CSDN zhanghm1995 is %d years", 2)// 最简单的定义
#define my_print1(...) printf(__VA_ARGS__)// 搭配va_list的format使用
#define my_print2(format, ...) printf(format, __VA_ARGS__)
#define my_print3(format, ...) printf(format, ##__VA_ARGS__)__VA_ARGS__ 宏前面加上 ## 的作用:
当可变参数个数为 0,这里的 printf 参数列表中的 ## 回把前面多余的 , 去掉
否则会编译出错
建议用第二种带 ## 的,程序更加健壮
补充解释👇
C++中可变参数宏定义用法实践_c++可变宏-CSDN博客
处理任意数量的参数:可变参数宏可以接受不定数量的参数,使得宏在调用时可以传入任意数量的参数。
使用省略号表示:在宏定义中,使用省略号
...表示可变数量的参数,这样就可以在宏中处理不确定数量的实参。利用递归或辅助函数处理参数:为了处理可变数量的参数,通常会结合使用递归函数或辅助函数来逐个处理每个参数。
宏展开后形成单一代码块:为避免在宏展开时产生意外的行为,通常在宏定义中使用
do...while(0)结构,将宏展开后形成单一的代码块。提高代码复用性:通过可变参数宏,可以实现一次宏定义,多处调用,提高代码的复用性和可维护性。
#include <iostream> // 包含输入输出流库
#include <sstream> // 包含字符串流库// 定义一个可变参数宏 PRINT,用于打印任意数量的参数
/*
定义 PRINT 宏,使用反斜杠表示换行继续宏定义
定义宏展开后的代码块开始
创建一个字符串流对象
用辅助函数处理可变参数并将结果存入字符串流
将字符串流中的内容输出到标准输出流
宏展开后的代码块结束,用 do...while(0) 结构避免宏在使用时产生意外的行为
*/
#define PRINT(...) \
do { \ std::stringstream ss; \ print_helper(ss, __VA_ARGS__); \ std::cout << ss.str() << std::endl; \
} while(0) // 辅助函数,用于将可变参数格式化为字符串
template <typename T>
void print_arg(std::ostream& os, const T& arg) { // 辅助函数,将单个参数输出到指定输出流os << arg; // 输出参数到指定输出流
}// 递归模板函数,将多个参数格式化为字符串
template <typename T, typename... Args>
void print_arg(std::ostream& os, const T& firstArg, const Args&... args) { // 递归模板函数,处理多个参数的输出os << firstArg << " "; // 输出第一个参数到指定输出流,并添加空格分隔print_arg(os, args...); // 递归调用自身,处理剩余参数
}// 模板函数,调用递归函数开始处理多个参数
template <typename... Args>
void print_helper(std::ostream& os, const Args&... args) { // 模板函数,调用递归函数开始处理多个参数print_arg(os, args...); // 调用递归函数开始处理多个参数
}int main() {// 使用 PRINT 宏输出多个参数PRINT("Hello, ", "World!"); // 使用 PRINT 宏输出多个参数PRINT("The answer is", 42, "and", 3.14); // 使用 PRINT 宏输出多个参数return 0; // 返回执行成功
}
Hello, World!
The answer is 42 and 3.14fflush
#include<stdio.h>
int fflush(FILE *stream);fflush() 会强迫将 缓冲区 的数据,写回参数 stream 指定的文件中,如果参数 stream 为 NULL,fflush() 会将所有打开的文件数据更新
在使用多个输出函数,连续进行多次输出到控制台时,有可能下一个数据的上一数据还没输出完毕,还在输出缓冲区中时,下一个 printf 就把另一个数据加入输出缓冲区,结果冲掉了原来的数据,出现错误
在 printf() 后加上 fflush(stdout); 强制马上输出到控制台,可以避免上述错误
🚩流程图与日志类定义
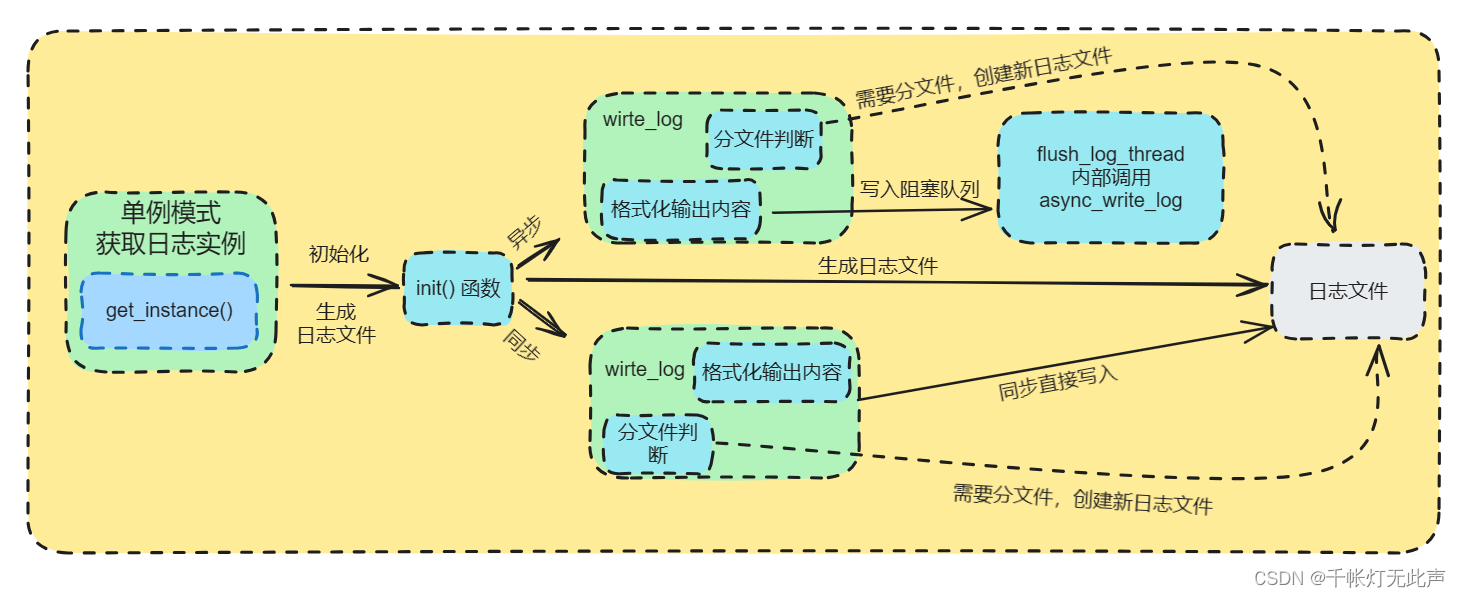
流程图
- 日志文件
- 局部变量的懒汉模式获取实例
- 生成日志文件,并判断同步和异步写入方式
- 同步
- 判断是否分文件
- 直接格式化输出内容,将信息写入日志文件
- 异步
- 判断是否分文件
- 格式化输出内容,将内容写入阻塞队列,创建一个写线程,从阻塞队列取出内容写入日志文件
下面的图,是我在这个网站上画的👇 比语雀好用一丢丢
Excalidraw | Hand-drawn look & feel • Collaborative • Secure
日志类定义
通过局部变量的懒汉单例模式,创建日志实例,对其进行初始化生成日志文件后,格式化输出内容,并根据不同的写入方式,完成对应逻辑,写入日志文件
日志类包括以下方法👇
- 公有的实例获取方法
- 初始化日志文件方法
- 异步日志写入方法,内部调用私有异步方法
- 内容格式化方法
- 刷新缓冲区
- ....
class Log
{
public:// C++11以后,使用局部变量懒汉不用加锁static Log *get_instance() // 获取Log类的唯一实例{static Log instance; // 静态局部变量,保证线程安全的懒汉单例模式return &instance; // 返回实例指针}// 可选的参数有 日志文件,日志缓冲区大小,最大行数,// 和 最长日志条队列bool init(const char *file_name, int log_buf_size = 8192,int split_lines = 5000000, int max_queue_size = 0); // 初始化日志系统// 异步写日志公有方法,调用私有方法 async_write_logstatic void *flush_log_thread(void *args) // 刷新日志的线程函数{// Log类的唯一实例指针// 类内访问静态成员,也需要声明作用域 ::Log::get_instance()->async_write_log(); // 调用日志实例的异步写日志方法}// 将输出内容按照标准格式整理// ... 表示 可变参数列表void write_log(int level, const char *format, ...); // 写日志方法// 强制刷新缓冲区void flush(void); // 强制刷新日志缓冲private:Log(); // 构造函数virtual ~Log(); // 虚析构函数// 异步写日志方法void *async_write_log() // 异步写日志方法{string single_log; // 单条日志字符串// 从阻塞队列中取出一条日志内容,写入文件while (m_log_queue->pop(single_log)) // 从阻塞队列中取出日志{m_mutex.lock(); // 加锁fputs(single_log.c_str(), m_fp); // 将日志内容写入文件m_mutex.unlock(); // 解锁}}private:char dir_name[128]; // 路径名char log_name[128]; // log文件名int m_split_lines; // 日志最大行数int m_log_buf_size; // 日志缓冲区大小long long m_count; // 日志行数记录int m_today; // 按天分文件,记录当前时间哪一天FILE *m_fp; // 打开log的文件指针char *m_buf; // 要输出的内容block_queue<string> *m_log_queue; // 阻塞队列bool m_is_async; // 是否同步标志位locker m_mutex; // 同步类
};// 可变参数宏定义
// 以下,4 个宏定义在其他文件使用,主要用于不同类型的日志输出// 调试日志输出宏
#define LOG_DEBUG(format, ...) Log::get_instance()->write_log(0, format, __VA_ARGS__)
// 信息日志输出宏
#define LOG_INFO(format, ...) Log::get_instance()->write_log(1, format, __VA_ARGS__)
// 警告日志输出宏
#define LOG_WARN(format, ...) Log::get_instance()->write_log(2, format, __VA_ARGS__)
// 错误日志输出宏
#define LOG_ERROR(format, ...) Log::get_instance()->write_log(3, format, __VA_ARGS__)#endif
日志类中的方法都不会被其他程序直接调用,末尾的四个可变参数宏,提供了其他程序的调用方法
前述方法对日志等级进行分类,包括DEBUG,INFO,WARN 和 ERROR 四种级别的日志
🌼功能实现
init() 函数实现日志创建,写入方式的判断
write_log() 函数完成写入日志文件中的具体内容,实现 日志分级,分文件,格式化输出内容
生成日志文件 && 判断写入方式
通过单例模式获取唯一的日志类,调用 init() 方法,初始化生成日志文件,服务器启动按当前时刻创建日志,前缀为时间,后缀为自定义 log 文件名,并记录创建日志的时间 day 和 行数 count
写入方式通过初始化时,是否设置队列大小(表示在队列中可以放几条数据)来判断,若队列大小为 0,则为同步,否则为异步
// 异步需要设置阻塞队列的长度,同步不需要设置
bool Log::init(const char *file_name, int log_buf_size,int split_lines, int max_queue_size)
{// 如果设置了 max_queue_size,则设置为 异步if (max_queue_size >= 1) {// 设置写入方式 flagm_is_async = true;// 创建并设置阻塞队列长度m_log_queue = new block_queue<string>(max_queue_size);pthread_t tid;// flush_log_thread 为回调函数,这里表示创建线程异步写日志pthread_create(&tid, NULL, flush_log_thread, NULL);}// 输出内容长度m_log_buf_size = log_buf_size;m_buf = new char[m_log_buf_size];memset(m_buf, '/0', sizeof(m_buf));// 日志最大行数m_split_lines = split_lines;time_t t = time(NULL); // 获取当前时间struct tm *sys_tm = localtime(&t); // 获取本地时间struct tm my_tm = *sys_tm; // 复制本地时间// 从后往前找到第一个 / 的位置const char *p = strrchr(file_name, '/'); // 查找最后一个斜杠的位置char log_full_name[256] = {0}; // 初始化日志文件名数组// 相当于自定义日志名// 若输入的文件名没有 /,则直接将时间 + 文件名作为日志名if (p == NULL) snprintf(log_full_name, 255, "%d_%02d_%02d_%s", // 格式化生成日志文件名my_tm.tm_year + 1900, my_tm.tm_mon + 1,my_tm.tm_mday, file_name);else {// 将 / 的位置向后移动一个位置,然后复制到 logname 中// p - file_name + 1 是文件所在路径文件夹的长度// dirname 相当于 ./strcpy(log_name, p + 1); // 复制文件名部分strncpy(dir_name, file_name, p - file_name + 1); // 复制路径部分// 后面的参数跟 format 有关snprintf(log_full_name, 255, "%s%d_%02d_%02d_%s", // 格式化生成日志文件名dir_name, my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday, log_name);}m_today = my_tm.tm_mday; // 记录今天日期m_fp = fopen(log_full_name, "a"); // 以追加模式打开日志文件if (m_fp == NULL) // 如果打开文件失败return false;return true;
}
代码解释👇
这段代码是日志系统的初始化函数,根据传入的参数初始化日志系统
异步和同步模式选择:
- 通过判断传入的
max_queue_size参数是否大于等于1 来确定日志系统是以同步模式还是异步模式运行- 如果
max_queue_size大于等于1,则表示使用异步模式,会创建一个阻塞队列用于存储日志消息,并启动一个线程异步写日志日志文件相关设置
- 初始化日志系统的缓冲区大小为
log_buf_size- 设置日志分割的最大行数为
split_lines生成日志文件名
- 获取当前时间
t,并将其转换成本地时间sys_tm- 判断传入的
file_name是否包含路径分隔符/,若无则直接以当前日期和传入的文件名作为日志文件名;若有,则从路径中提取出文件名和路径部分- 根据日期、文件名和路径信息构建完整的日志文件名
log_full_name记录今天的日期
- 将当天的日期存储在变量
m_today中,用于后续判断是否需要切换日志文件打开日志文件
- 使用追加模式打开生成的日志文件,如果打开失败则返回
false
日志分级与分文件
日志分级的实现,一般提供 5 种级别👇
- Debug,调试代码时输出,系统实际运行时一般不使用
- Warn,这种警告与调试时终端的 warning 类似,同样是调试代码时使用
- Info,报告系统当前状态,当前执行的流程或接收的信息
- Error 和 Fatal,输出系统的错误信息
上述方法,会根据开发具体情况改变
TinyWebServer 中,给出了除Fatal外的四种分级,实际使用了 Debug,Info 和 Error
超行,按天分文件 的逻辑具体是👇
- 日志写入前会判断当前 day 是否为创建日志的时间,行数是否超过最大行限制
- 若为创建日志时间,写入日志,否则按当前时间创建心 log,更新创建时间和行数
- 若行数超过最大行限制,在当前日志的末尾加 count / max_lines 为后缀,创建新log
将系统信息格式化后输出,具体为:格式化时间 + 格式化内容
void Log::write_log(int level, const char *format, ...)
{struct timeval now = {0, 0};gettimeofday(&now, NULL); // 获取当前时间time_t t = now.tv_sec; // 获取秒数struct tm *sys_tm = localtime(&t); // 转换为本地时间struct tm my_tm = *sys_tm; // 复制本地时间char s[16] = {0}; // 存储日志级别字符串// 日志分级switch (level) {case 0:strcpy(s, "[debug]:"); // 调试级别break;case 1:strcpy(s, "[info]:"); // 信息级别break;case 2:strcpy(s, "[warn]:"); // 警告级别break;case 3:strcpy(s, "[error]:"); // 错误级别break;case 4:strcpy(s, "[fatal]:"); // 致命错误级别break;} m_mutex.lock(); // 加锁,保证线程安全// 更新现有行数m_count++;// 如果日志不是今天或者写入的日志行数是最大行的倍数// m_split_lines 为最大行数if (m_today != my_tm.tm_mday || m_count % m_split_lines == 0){char new_log[256] = {0}; // 存储新的日志文件名fflush(m_fp); // 刷新文件流fclose(m_fp); // 关闭文件char tail[16] = {0}; // 存储时间部分的字符串// 格式化日志名中的时间部分snprintf(tail, 16, "%d_%02d_%02d_", my_tm.tm_year + 1900,my_tm.tm_mon + 1, my_tm.tm_mday);// 如果时间不是今天,就创建今天的日志,更新 m_today 和 m_countif (m_today != my_tm.tm_mday) {snprintf(new_log, 255, "%s%s%s", dir_name, tail, log_name);m_today = my_tm.tm_mday; // 更新为今天日期m_count = 0; // 重置行数为0}else {// 超过最大行,在之前的日志名基础上,加后缀// m_count / m_split_linessnprintf(new_log, 255, "%s%s%s.%lld", dir_name, tail,log_name, m_count / m_split_lines);}m_fp = fopen(new_log, "a"); // 打开新的日志文件}m_mutex.unlock(); // 解锁va_list valst; // 创建可变参数列表va_start(valst, format); // 初始化可变参数列表string log_str; // 存储日志内容的字符串m_mutex.lock(); // 加锁// 写入内容格式:时间 + 内容// 时间格式化int n = snprintf(m_buf, 48, "%d-%02d-%02d %02d:%02d:%02d.%06ld %s ",my_tm.tm_year + 1900, my_tm.tm_mon + 1, my_tm.tm_mday,my_tm.tm_hour, my_tm.tm_min, my_tm.tm_sec, now.tv_usec, s);// 内容格式化int m = vsnprintf(m_buf + n, m_log_buf_size - 1, format, valst);m_buf[n + m] = '\n'; // 添加换行符m_buf[n + m + 1] = '\0'; // 添加字符串终止符log_str = m_buf; // 将格式化后的内容存入字符串m_mutex.unlock(); // 解锁// 若 m_is_async 为 true 表示异步,默认同步// 若异步,就将日志信息加入阻塞队列,同步就加锁向文件中写if (m_is_async && !m_log_queue->full()) {m_log_queue->push(log_str); // 异步写入日志队列} else {m_mutex.lock(); // 加锁fputs(log_str.c_str(), m_fp); // 同步写入日志文件m_mutex.unlock(); // 解锁}va_end(valst); // 结束可变参数列表
}
补充解释
1)
char *strcpy(char *dest, const char *src);dest表示目标字符串的地址,src表示源字符串的地址。strcpy会把源字符串(src指向的字符串)的内容复制到目标字符串(dest指向的字符串)中,并以'\0'(空字符)作为结束符
上面的代码中,通过strcpy函数将不同日志级别对应的字符串(比如"[debug]:"、"[info]:")复制到变量s中,以便后续拼接成完整的日志信息