论文结论:
echo embeddings将句子重复拼接送入到decoder-only模型中,将第二遍出现的句子特征pooling作为sentence embedding效果很好,优于传统方法
echo embeddings与传统embedding方法区别,如图所示:
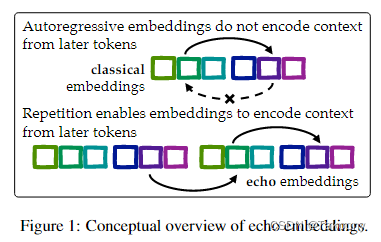
Classical embeddings: Feed sentence x to
the language model and pool the contextu-
alized embeddings of sentence x.
Echo embeddings: Feed a prompt such
as “Rewrite the sentence: x, rewritten sen-
tence: x” to the language model and pool
the contextualized embeddings of the sec-
ond occurence of x
为什么会有这样的效果呢?
因为decoder-only架构存在的缺陷:在自回归模型中,由于因果注意力掩码(causal attention mask)的存在,特定输入标记的上下文化标记嵌入(即在句子中特定位置的标记的最后隐藏层激活向量)不能包含来自句子后部标记的信息。这导致了一个问题,即当早期标记在表面上相似但在关键信息上变得不相似时,这些嵌入可能无法适当地确定相似性。
有哪些相关研究?
这篇论文提到了以下几类相关研究:
-
神经文本嵌入:这些嵌入在信息检索(IR)、语义相似度估计、分类和聚类等现代方法中起着关键作用。例如,文档检索通常利用低维嵌入进行高效查找,通过将查询和文档编码为向量,其中语义关系通过在某个度量空间中的相似性来描述。
-
掩蔽语言模型与双向注意力:以往的研究主要集中在使用掩蔽语言模型(如BERT)和双向注意力机制来构建嵌入。这些模型通常通过对比学习目标(如InfoNCE或SimCSE)进行训练。
-
自回归语言模型:最近的研究开始将这些算法扩展到现代自回归语言模型,如LLaMA和Mistral。这些模型在许多任务上是可用的最高质量模型。
-
零样本嵌入:大多数关于句子嵌入的研究都集中在改进微调上。然而,Jiang等人(2023b)是唯一一篇构建自回归语言模型的零样本嵌入的论文。
-
对比学习:在自回归语言模型中构建高质量嵌入的一系列论文。例如,Muennighoff(2022)和Zhang等人(2023a)将S-BERT的微调方法应用于GPT作为主干架构。Ma等人(2023)采用了类似的方法,但针对的是LLaMA-2。
-
提示改进:一些工作提出了包括提示以改进特定任务的嵌入性能。例如,Jiang等人(2022)和Su等人(2022)。
-
多任务训练目标:一些论文提出了结合多个训练目标和方法。例如,Xiao等人(2023a)和Li等人(2023)。
通过这种方法,作者成功地克服了自回归语言模型在嵌入任务中的一个关键限制,并展示了回声嵌入在实际应用中的潜力。
论文做了哪些实验?
论文中进行了以下几类实验来评估和验证“回声嵌入”(echo embeddings)方法的有效性:
-
玩具数据实验:通过构建一个简单的控制合成设置,作者测试了回声嵌入是否能够使早期标记捕获有关后续标记的信息。在这个实验中,作者构造了具有相似开头但结尾不同的句子对,并观察了回声嵌入与经典嵌入在区分这些句子时的表现。
-
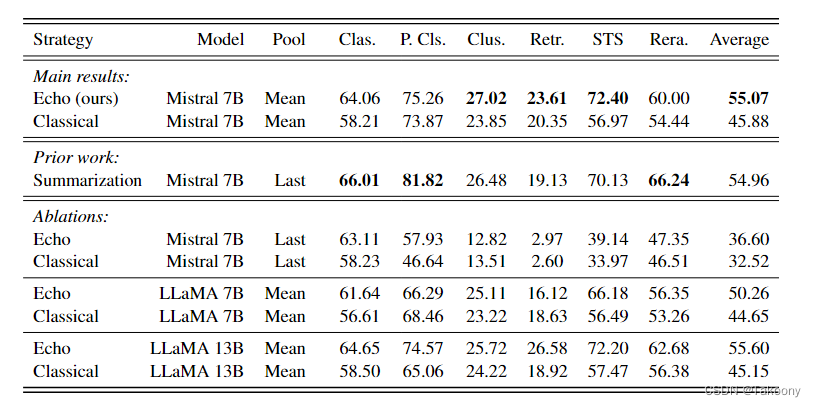
零样本设置下的MTEB评估:作者在零样本设置下,使用MTEB(Massive Text Embedding Benchmark)的英语子集对回声嵌入和经典嵌入进行了评估。这包括了多种任务,如分类、聚类、检索、句子相似性(STS)等。
-
微调设置下的MTEB评估:为了进行公平比较,作者在相同的数据集上对回声嵌入和经典嵌入进行了微调,并报告了结果。这包括了对比先前的基于掩蔽语言模型(MLM)的嵌入方法和基于自回归语言模型的嵌入方法。
-
不同提示策略的敏感性分析:作者研究了不同的提示策略对零样本MTEB任务性能的影响,并比较了回声嵌入、经典嵌入和摘要方法的敏感性。
-
不同模型的比较:作者比较了在不同模型(如Mistral-7B、LLaMA-2-7B和LLaMA-2-13B)上回声嵌入和经典嵌入的性能。
-
不同池化策略的比较:作者还探讨了平均池化和最后标记池化策略在回声嵌入和经典嵌入中的作用。
-
双向架构的实验:为了测试架构本身是否足以提高性能,作者尝试在去除因果注意力掩码的Mistral-7B上进行微调,以创建一个具有双向注意力的模型,并比较了其性能。
这些实验结果表明,回声嵌入在多种任务和模型上都能显著提高性能,并且在零样本和微调设置下都能保持这种优势。此外,这些实验还揭示了回声嵌入在处理具有相似开头的句子时的优越性,这是经典嵌入方法的一个已知弱点。
有什么可以进一步探索的点?
尽管论文中的回声嵌入方法取得了显著的成功,但仍有一些方面可以进一步探索:
-
理解回声嵌入的机制:尽管回声嵌入在实验中表现出色,但其背后的确切机制尚未完全理解。未来的工作可以深入研究为什么回声嵌入在微调后仍然优于经典嵌入,以及这种改进是如何在不同的任务和数据集上实现的。
-
优化输入重复策略:论文中使用了简单的重复输入策略,但可能存在更复杂的策略来进一步提高性能。例如,可以考虑不同的重复模式、间隔或其他结构化的方法来传递信息。
-
计算效率:回声嵌入方法需要将输入传递给模型两次,这可能会增加计算成本。研究如何减少这种额外成本,例如通过更高效的模型架构或优化的输入处理策略,是一个有价值的方向。
-
不同模型架构的适用性:虽然论文主要关注自回归模型,但回声嵌入方法是否可以应用于其他类型的语言模型,如Transformer-XL或BERT等,也是一个值得探索的问题。
-
跨语言和跨领域的泛化能力:研究回声嵌入在不同语言和领域中的泛化能力,以及如何调整方法以适应特定的应用场景。
-
与其他嵌入技术的结合:考虑将回声嵌入与其他先进的嵌入技术(如对比学习、多任务学习等)结合,以进一步提高嵌入的质量。
-
实际应用的评估:在实际应用中,如搜索引擎、推荐系统或自然语言理解任务中,评估回声嵌入的性能和实用性。
-
可解释性和透明度:提高嵌入的可解释性,使得用户能够理解嵌入背后的语义和决策过程,这对于嵌入技术的接受度和信任度至关重要。
通过探索这些方向,研究者可以进一步提高文本嵌入技术的性能和适用性,同时也为理解语言模型的工作原理提供更深入的见解。
总结一下论文的主要内容
-
问题定义:论文指出自回归大型语言模型(LLMs)在提取文本嵌入时存在一个限制,即早期标记的上下文化嵌入不能包含来自句子后部的信息。这可能导致在语义相似性估计上的失败。
-
方法提出:为了解决这个问题,作者提出了一种名为“回声嵌入”的方法。这种方法通过在上下文中重复输入两次,并从第二次出现的文本中提取嵌入,从而使早期标记能够编码关于后续标记的信息。
-
实验设计:作者在大规模文本嵌入基准(MTEB)上进行了实验,包括零样本和微调设置,以评估回声嵌入与传统嵌入方法的性能。
-
结果分析:实验结果表明,回声嵌入在多种任务和模型上显著优于传统嵌入方法。在零样本设置中,回声嵌入的性能提升超过9%,而在微调设置中,平均提升约为0.7%。
-
对比实验:论文还与先前的开源模型进行了对比,展示了回声嵌入在不利用合成微调数据的情况下,能够实现与先前模型相匹配甚至更优的性能。
-
局限性讨论:尽管回声嵌入取得了成功,但论文也指出了其局限性,包括需要双倍的推理成本,以及在微调后性能提升的具体机制尚不明确。
-
未来工作:论文提出了未来研究的方向,包括理解回声嵌入的工作原理、优化输入重复策略、提高计算效率、探索跨语言和跨领域的泛化能力等。
总的来说,这篇论文提出了一种新的文本嵌入方法,通过在自回归语言模型中重复输入来克服信息编码的局限性,并在多个任务上展示了其有效性。