目录
编辑
0.前言
1.栈的基本概念
2.栈的实现
2.1数组OR链表?
2.2静态栈的实现
2.3动态栈的实现
3.栈的应用
4.结语
(图片由AI生成)
0.前言
在计算机科学中,数据结构是组织、管理和存储数据的有效方式,以便可以高效地访问和修改数据。栈是一种基本的数据结构,它遵循特定的操作顺序,即后进先出(LIFO)。由于其简单和高效的特性,在许多算法和系统功能中都有应用,如系统调用栈、表达式求值和回溯算法等。
1.栈的基本概念
栈是一种特殊的线性数据结构,它遵循特定的操作顺序,即后进先出(Last In First Out, LIFO)。这意味着最后添加到栈中的元素将是第一个被移除的元素。栈的这种特性使得它在处理具有递归性质的问题和算法中非常有用。
特点
- 后进先出:栈的基本操作确保了最后被添加的元素总是第一个被移除。
- 单端操作:所有的添加和移除操作仅在栈的同一端进行,这一端被称为“栈顶”,另一端称为“栈底”。
基本操作
栈的操作通常包括以下几种:
- Push(入栈):将一个元素添加到栈顶。这是一个添加操作,将元素放置在栈的最上方。
- Pop(出栈):从栈顶移除一个元素,并返回被移除的元素。这是一个移除操作,它删除并返回栈顶元素。
- Peek 或 Top(查看栈顶元素):返回栈顶元素,但不从栈中移除它。这允许我们查看栈顶的元素而不改变栈的状态。
- IsEmpty(检查栈是否为空):确定栈是否为空。如果栈中没有元素,此操作返回 true;否则,返回 false。
- Size(获取栈的大小):返回栈中元素的数量。这允许我们了解栈中存储了多少元素。
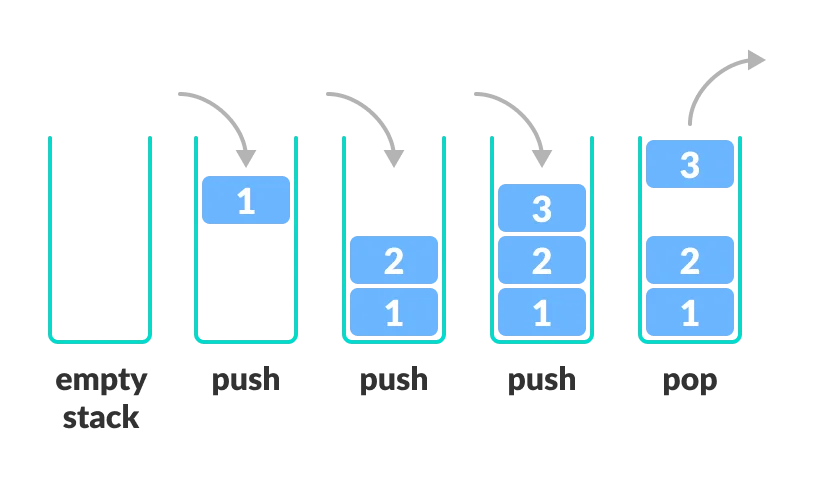
下面这幅图片能够更好地反映栈的结构以及上面的操作:(图源网络,侵删)
2.栈的实现
2.1数组OR链表?
实现栈的两种常见方法是使用数组和链表。每种方法都有其独特的优势和劣势,选择哪种方式取决于具体的应用场景和需求。下面我们将详细探讨使用数组和链表实现栈的优势和劣势,并解释为什么在某些情况下数组可能是更好的选择。
使用数组实现栈的优势:
- 随机访问:数组提供了O(1)的时间复杂度来访问任何一个元素,这使得访问栈顶元素非常快速。
- 内存连续性:数组在内存中是连续存储的,这有助于提高空间和缓存的效率。
- 简单性:使用数组实现栈的代码通常更简单直观,特别是在栈操作不频繁或栈大小固定时。
使用数组实现栈的劣势:
- 固定大小:数组的大小在初始化时就固定了,这限制了栈的最大容量,可能会导致栈溢出。
- 扩容问题:如果栈满了需要扩容,就必须创建一个更大的数组并复制原数组的元素,这个过程的时间复杂度是O(n)。
使用链表实现栈的优势:
- 动态大小:链表实现的栈可以动态地增长和缩小,不受固定大小的限制,从而避免了栈溢出的问题。
- 内存利用率:链表是非连续存储的,它可以更好地利用分散的内存空间,理论上可以达到系统内存的限制。
使用链表实现栈的劣势:
- 内存开销:链表的每个元素都需要额外的空间来存储指向下一个元素的指针。
- 时间开销:相比数组实现,链表访问和操作元素(特别是非栈顶元素)的时间开销较大。
- 缓存不友好:由于链表的元素在内存中是非连续存储的,它不如数组那样缓存友好。
为什么数组更好?
在特定的应用场景下,数组实现的栈可能更受青睐,主要是因为以下几点:
- 性能:对于栈顶元素的操作,数组提供了更快的访问速度,尤其是在需要频繁访问或操作栈顶元素的情况下。
- 简单性和高效性:数组实现的栈在代码上更直观简单,且由于内存连续性,它在空间和缓存效率上通常表现更好。
- 可预测的性能:数组的固定大小虽然是一个限制,但也意味着栈的性能是可预测的,不会因为动态扩容而出现性能波动。
2.2静态栈的实现
静态栈的实现通常基于一个固定大小的数组,以及一个变量来跟踪栈顶元素的位置。下面是一个简单的C语言实现示例,包括基本的栈操作:入栈(Push)、出栈(Pop)、查看栈顶元素(Peek)和检查栈是否为空(IsEmpty)。
下面是示例代码:
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h> // 用于bool类型#define MAX_SIZE 10 // 定义栈的最大容量// 栈的结构体定义
typedef struct {int items[MAX_SIZE]; // 存储栈元素的数组int top; // 栈顶元素的索引
} Stack;// 创建栈
Stack* createStack() {Stack* S = (Stack*)malloc(sizeof(Stack));S->top = -1; // 初始化栈为空return S;
}// 检查栈是否满
bool isFull(Stack* S) {return S->top == MAX_SIZE - 1;
}// 检查栈是否为空
bool isEmpty(Stack* S) {return S->top == -1;
}// 入栈操作
void push(Stack* S, int element) {if (isFull(S)) {printf("Stack is full. Cannot push %d into the stack\n", element);return;}S->items[++S->top] = element; // 先递增栈顶指针,再存储元素printf("%d pushed to stack\n", element);
}// 出栈操作
int pop(Stack* S) {if (isEmpty(S)) {printf("Stack is empty. Cannot pop element\n");return INT_MIN; // INT_MIN在limits.h中定义,表示int类型可能的最小值}return S->items[S->top--]; // 返回栈顶元素,然后递减栈顶指针
}// 查看栈顶元素
int peek(Stack* S) {if (isEmpty(S)) {printf("Stack is empty\n");return INT_MIN;}return S->items[S->top];
}// 主函数,展示如何使用上述栈
int main() {Stack* myStack = createStack(); // 创建栈push(myStack, 10);push(myStack, 20);push(myStack, 30);printf("%d popped from stack\n", pop(myStack));printf("Top element is %d\n", peek(myStack));if (isEmpty(myStack)) {printf("Stack is empty\n");} else {printf("Stack is not empty\n");}return 0;
}这段代码定义了一个栈的结构体Stack,包含一个整数数组items用于存储栈的元素,以及一个整数top用于跟踪栈顶元素的索引。createStack函数用于创建并初始化一个栈。push函数实现了向栈中添加一个新元素的功能,pop函数实现了移除栈顶元素的功能,peek函数用于返回栈顶元素但不移除它,isEmpty函数检查栈是否为空。
这个静态栈的实现是基于一个固定大小的数组,因此它有一个最大容量MAX_SIZE,超过这个容量的入栈操作将被拒绝。这个简单的实现演示了静态栈的基本操作和使用方法。
2.3动态栈的实现
动态栈的实现通过动态分配的数组来支持栈的操作,允许栈在运行时根据需要增长和缩小。这种实现方式通过使用realloc函数动态地调整数组的大小,从而克服了静态栈固定容量的限制。下面是动态栈实现的详细介绍:
结构定义
动态栈通过一个结构体stack来定义,包含以下成员:
_a:指向动态分配的数组,用于存储栈中的元素。_top:表示栈顶元素的下标。栈为空时,_top为0。_capacity:表示栈的当前容量,即数组_a可以容纳的元素数量。
初始化(stackInit)
初始化函数为栈分配初始容量,并将_top设置为0,表示栈为空。初始容量可以根据需要和预期的使用情况进行设置,示例代码中设置为4。
销毁(stackDestroy)
销毁函数释放动态分配的数组_a并将指针设置为NULL,同时将_top和_capacity重置,以确保栈结构体不再指向已释放的内存。
入栈(stackPush)
入栈操作首先检查栈是否已满(即_top等于_capacity)。如果栈已满,则进行扩容操作,将容量加倍,并使用realloc重新分配内存。扩容后,新元素被添加到栈顶位置,_top递增。
出栈(stackPop)
出栈操作首先确保栈非空,然后递减_top,移除栈顶元素。注意,出栈操作并不实际删除元素,而是通过调整_top的值来逻辑上移除元素。
栈的大小(stackSize)
返回栈的大小,即栈中元素的数量,这通过返回_top的值来实现。
检查栈是否为空(stackEmpty)
检查栈是否为空,如果_top为0,则栈为空,返回1;否则,返回0。
查看栈顶元素(stackTop)
返回栈顶元素,即位于_top - 1位置的元素。在访问前应确保栈非空。
下面为示例代码:
//stack.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int STDataType;
typedef struct stack
{STDataType* _a;//动态开辟的数组int _top;//栈顶的下标int _capacity;//容量
}stack;void stackInit(stack* pst);//初始化
void stackDestroy(stack* pst);//销毁
void stackPush(stack* pst, STDataType x);//入栈
void stackPop(stack* pst);//出栈
int stackSize(stack* pst);//返回栈的大小
int stackEmpty(stack* pst);//返回0表示非空,返回1表示空
STDataType stackTop(stack* pst);//返回栈顶元素#define _CRT_SECURE_NO_WARNINGS 1#include"stack.h"// 初始化函数
void stackInit(stack* pst) {assert(pst); // 确保栈指针有效pst->_a = (STDataType*)malloc(sizeof(STDataType) * 4); // 动态分配初始容量为4的数组pst->_top = 0; // 初始化栈顶为0,表示栈为空pst->_capacity = 4; // 初始化栈的容量为4
}// 销毁栈函数
void stackDestroy(stack* pst) {assert(pst); // 确保栈指针有效free(pst->_a); // 释放动态分配的数组内存pst->_a = NULL; // 将数组指针设置为NULLpst->_top = pst->_capacity = 0; // 重置栈顶和容量
}// 入栈函数
void stackPush(stack* pst, STDataType x) {assert(pst); // 确保栈指针有效if (pst->_top == pst->_capacity) { // 如果栈已满pst->_capacity *= 2; // 容量加倍STDataType* tmp = (STDataType*)realloc(pst->_a, sizeof(STDataType) * pst->_capacity); // 重新分配更大的内存空间if (tmp == NULL) { // 如果重新分配失败printf("realloc fail\n"); // 打印错误信息exit(-1); // 异常退出}pst->_a = tmp; // 更新栈的数组指针}pst->_a[pst->_top] = x; // 在栈顶位置添加新元素pst->_top++; // 栈顶上移
}// 出栈函数
void stackPop(stack* pst) {assert(pst); // 确保栈指针有效assert(pst->_top > 0); // 确保栈非空pst->_top--; // 栈顶下移,移除栈顶元素
}// 获取栈的大小
int stackSize(stack* pst) {assert(pst); // 确保栈指针有效return pst->_top; // 返回栈中元素的数量
}// 检查栈是否为空
int stackEmpty(stack* pst) {assert(pst); // 确保栈指针有效return pst->_top == 0 ? 1 : 0; // 如果栈顶为0,表示栈为空,返回1;否则返回0
}// 获取栈顶元素
STDataType stackTop(stack* pst) {assert(pst); // 确保栈指针有效assert(pst->_top > 0); // 确保栈非空return pst->_a[pst->_top - 1]; // 返回栈顶元素
}
3.栈的应用
栈是一种非常实用的数据结构,它的后进先出(LIFO)特性使得它在多种计算机科学领域和实际应用中非常有用。以下是栈的一些主要应用:
1. 程序执行的函数调用栈
在大多数编程语言中,函数调用的执行是通过栈来管理的。每当一个函数被调用时,一个新的记录(称为"栈帧")被推入调用栈中,包含了函数的参数、局部变量和返回地址。当函数执行完成后,其对应的栈帧就会被弹出栈,并控制权返回到函数的调用点。这个机制支持了函数的嵌套调用和递归执行。
2. 括号匹配
在编程和文档编辑中,括号匹配是一个常见的问题。栈可以用来确保所有的开放括号(如(, [, {)都能找到相应的闭合括号(如), ], })。每次遇到开放括号时,就将其推入栈中,遇到闭合括号时,就检查栈顶的括号是否与之匹配,如果匹配则弹出栈顶括号,否则表示括号不匹配。
3. 深度优先搜索(DFS)
在图和树的遍历中,深度优先搜索(DFS)是一种重要的算法,它可以使用栈来实现。算法从一个起点开始,尽可能深地沿着树的分支进行搜索,直到达到叶节点,然后回溯并探索下一条路径。栈用来保存从起点到当前位置的路径。
4. 递归
尽管递归函数直接由调用栈支持,但在某些情况下,使用栈将递归算法转换为非递归形式是有用的,这可以减少函数调用的开销,特别是对于深层递归的情况。
4.结语
栈是一种简单而强大的数据结构,它在算法设计和系统实现中扮演着重要的角色。通过静态或动态的方式实现栈,可以在不同的应用场景中有效地利用其后进先出的特性。深入理解栈的工作原理和应用,对于学习更复杂的数据结构和算法是非常有帮助的。
另外,我们需要注意的是,我们做算法题需要使用栈、队列等数据结构时不需要每次都“手搓”出一份C语言数据结构代码来。实际上,C++中的STL(标准模板库)中有vector,list,stack,queue等容器接口,我们直接调用即可。这些内容会在我未来的C++博客中作详细介绍。