redis 是不是单线程
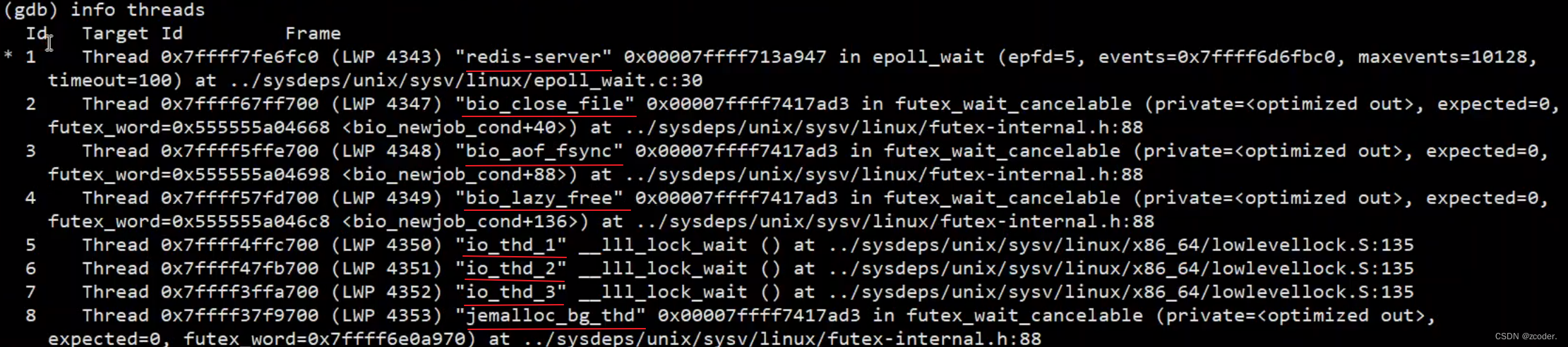
redis 单线程指的是命令处理在一个单线程中。- 主线程
- redis-server:命令处理、网络事件的监听。
- 辅助线程
- bio_close_file:异步关闭大文件。
- bio_aof_fsync:异步 aof 刷盘。
- bio_lazy_free:异步清理大块内存。
- io_thd_*:io 多线程。
- jemalloc_bg_thd:后台线程,进行内存分配,内存释放。
- 辅助线程负责处理阻塞的操作,这样可以不阻塞主线程,让主线程最大限度地处理命令,优化性能。
命令处理为什么是单线程
- 单线程的局限:不能有耗时的操作,比如 CPU 运算、阻塞的 IO;对于 redis 而言会影响响应性能。
- redis 处理 IO 密集型:
- 磁盘 IO:
- fork 进程,在子进程做持久化。
- 使用 bio_aof_fsync,另起线程做持久化(异步 aof 刷盘)。
- 网络 IO:
- 服务多个客户端,造成 IO 密集;数据请求或返回数据量比较大。
- 开启 IO 多线程。
- 磁盘 IO:
- redis 处理 CPU 密集型
- 数据结构切换:redis 会根据当前数据量的大小,选择一个数据结构去存储。
- 渐进式数据迁移:当数据量小的时候,会分配一个小的内存,当数据量大的时候,会分配一个大的内存(翻倍扩容),那么就需要将原来内存中的数据迁移到新的内存中,redis 不会将原数据一次性都挪过去,而是采用一定的策略逐渐挪过去。
- 为什么不采用多线程
- 加锁复杂、锁粒度不好控制。
- 频繁的 CPU 上下文切换,抵消多线程的优势。
redis 单线程为什么快
- 高效的 reactor 网络模型
- 数据结构高效
- 在执行效率与空间占用间保持平衡,可以进行数据结构切换。
- redis 是内存数据库,大部分情况下:操作完内存后会立刻返回给客户端,不需要关注写磁盘的问题。特殊情况:使用 aof 持久化方式 + always 策略:每一次操作完内存后,都必须持久化到磁盘中,然后再返回给客户端。
- 数据组织方式
typedef struct redisDb {dict *dict; // 存储所有的 key 和 valuedict *expires; // 存储所有过期的 keydict *blocking_keys; // 存储阻塞连接的 keydict *ready_keys; dict *watched_keys; // 被检测的 key ( MULTI/EXEC ) }struct dict {dictType *type;dictEntry **ht_table[2];unsigned long ht_used[2];long rehashidx; // 默认为 -1,记录迁移的位置int16_t pauserehash;signed char ht_size_exp[2]; }- redis 支持 16 个 db,默认使用 db0,可以通过
use选择某一个 db。 - redis 内部会分配一个指针数组(每一个数组元素都对应一个链表)。key 通过 hash 函数会生成一个 64 位的整数,这个整数对该数组的长度取余,得到一个该数组的索引值,然后将 key 和 value 存储在该索引位置的链表中。
- ht_size_exp 记录指针数组长度 2 n 2^n 2n 中 n n n 的值,指针数组长度为什么是 2 n 2^n 2n ?
- 因为要把取余运算优化为位运算,优化的前提是 s i z e = 2 n size = 2^n size=2n ;当 s i z e = 2 n size = 2^n size=2n 时,
hash(key) % size = hash(key) & (size - 1)。 - 取余运算中会有除法运算,计算机做除法运算会比较慢,做位运算会很快。 2 n 2^n 2n 又可以优化为 1 < < n 1<<n 1<<n 。
- 因为要把取余运算优化为位运算,优化的前提是 s i z e = 2 n size = 2^n size=2n ;当 s i z e = 2 n size = 2^n size=2n 时,
- 负载因子 = used / / /size,used 是指针数组存储元素的个数,size 是指针数组的长度。负载因子越小哈希冲突越小,负载因子越大哈希冲突越大。
- 扩容操作
- 第一次分配指针数组空间长度为 4( 1 < < 2 1<<2 1<<2)。
static int _dictExpandIfNeeded(dict *d) {if (dictIsRehashing(d)) return DICT_OK;if(DICTHT_SIZE(d->ht_size_exp[0]) == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE) } - 当负载因子 ≥ 1 \geq 1 ≥1 时,即
used / size >= 1,为了减小哈希冲突,会进行翻倍扩容。第二次扩容会准备一个空间长度为 8 的指针数组,然后将原来数组中的元素迁移到扩容后的数组中。如果正在 fork(在 rdb、aof 复写以及 rdb-aof 混用的情况下),会阻止扩容,但是此时若负载因子 > 5 >5 >5,索引效率大大降低,则会马上扩容。
- 第一次分配指针数组空间长度为 4( 1 < < 2 1<<2 1<<2)。
- 缩容操作
- 当负载因子 < 0.1 < 0.1 <0.1 时,即
(size > 4) && ((used / size) < 0.1),会进行缩容,缩容后的数组长度恰好大于元素个数并且为 2 n ≥ 4 2^n \geq 4 2n≥4 。
- 当负载因子 < 0.1 < 0.1 <0.1 时,即
- 扩容操作和缩容操作都需要 rehash,因为 key-value 对的存储位置发生了变化。
- 一个 dict 结构包含两个散列表(散列表 = 哈希函数 + 指针数组),为什么要准备两个 ht_table ?
- 为了防止迁移元素较多时,迁移任务变为 CPU 密集型。
- 使用两个 ht_table 可以将原来数组中的元素逐渐迁移到扩容后的数组中,而不是一次性将元素全部挪过去;当原来数组中的元素全部挪过去后,会
free原数组;如果free的空间比较大,会使用 bio_lazy_free 另起线程去 free 这块空间。
- 渐进式 rehash
处于渐进式 rehash 阶段时,不会发生扩容缩容- 当指针数组中的元素过多的时候,不能一次性 rehash 到 ht_table[1],这样会长期占用 redis,其它命令得不到响应,所以需要使用渐进式 rehash。
- 步骤:将 ht_table[0] 中的元素重新经过 hash 函数生成 64位整数,再对 ht_table[1] 的长度进行取余,从而映射到 ht_table[1]。
- 策略:
- 在每次增删改查的时候,迁移一个索引单位。
- 在服务器空闲的时候,会迁移 1ms ,以 100 个索引单位为步长。
int dictRehashMilliseconds(dict *d, int ms) {if (d->pauserehash > 0) return 0; long long start = timeInMilliseconds();int rehashes = 0;while(dictRehash(d, 100)) {rehashes += 100;if (timeInMilliseconds() - start > ms) break;}return rehashes; }
- redis 支持 16 个 db,默认使用 db0,可以通过
redis io 多线程工作原理
- redis 采用 reactor 网络模型。

- redis 配置
# redis.conf io-threads 4 io-threads-do-reads yes