由于上一节我们提到的,关键词检索的局限性,现在我们引出向量检索,
关键词检索有语义上的缺陷,因为我们说法不一样,但是意思一样的话,那么,关键词如果在es库中没有,那么会导致,找不到答案的情况.所以我们引出向量检索,要求语义一样的词,去检索都能找到答案.

我们来说一下这个文本向量是什么意思?
可以看到左侧是一组句子,可以看到,每个数据,首先我们把它转换为向量也就是一组数,这一组数
可以是2维的,可以是多维度的,其实对于不同的模型,转换是不一样的,比如OpenAI是1536亿个特征对吧.有几个特征就转换成这样的一组数.
然后假如是2维的,可以看到在右边,红点,那么这几个句子,对应的在,2维空间中的距离,因为他们语义相近,那么距离肯定越近.
那么我们就可以利用这个特性,先去找到这个句子对应es中有没有,如果es库中没有,那么再去看
他对应的语义相近的,文档在es库中有没有对吧,这样一个过程.

那么现在我们需要的就是,如果我们有一个句子,我们如何能得到对应的
这个句子对应的一组数对吧?也就上面的参数
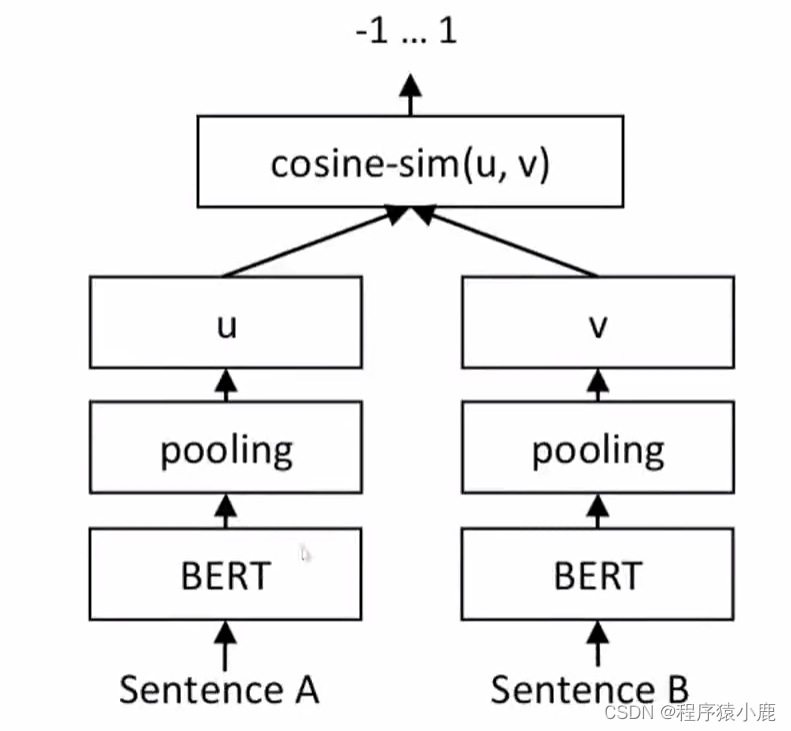
这个双塔式的训练模型是这个意思:
首先训练资料是以一对一对出现的,也就是训练数据,肯定是一块喂给这个模型两个句子,
可


![[VSCode插件] 轻量级静态博客 - MDBlog](https://img-blog.csdnimg.cn/direct/8eb2110aad1d436e83a604c295385219.png)