参考
k8s 官方文档
- https://kubernetes.io/zh-cn/docs/reference/
- https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.29/
重点
-
Kubernetes源码学习-kubernetes基础数据结构 - 知乎 重点
-
Kubernetes类型系统 | 李乾坤的博客 重点
-
k8s源码学习-三大核心数据结构_51CTO博客_c++数据结构 重点
-
Kubernetes源码分析(二)----资源Resource_kubernetes resources-CSDN博客 重点
-
浅说Kubernetes中API的概念_kubernetes api-CSDN博客
-
Kubernetes API Server源码学习(二):OpenAPI、API Resource的装载、HTTP Server具体是怎么跑起来的?_apiserver openapi-CSDN博客 重点
-
Kubernetes API 概念 | Kubernetes
-
3.1.3 访问kubernetes REST API · Kubernetes Documentation
-
Kubernetes源码分析(二)----资源Resource_kubernetes resources-CSDN博客
-
K8s 的核心是 API 而非容器(二):从开源项目看 k8s 的几种 API 扩展机制(2023) 重点
-
【k8s基础篇】k8s基础2之GVK与GVR-CSDN博客
-
Kubernetes API Server源码学习(二):OpenAPI、API Resource的装载、HTTP Server具体是怎么跑起来的?_apiserver openapi-CSDN博客 重点
-
Kubernetes源码开发之旅三:API Server源码剖析_哔哩哔哩_bilibili blibli 视频教学,不错
-
Kubernetes API Server handler 注册过程分析 | 云原生社区(中国) 重点
-
源码解析:K8s 创建 pod 时,背后发生了什么(三)(2021)
-
一文读懂 Kubernetes APIServer 原理 - k8s-kb - 博客园
-
【k8s基础篇】k8s基础3之接口文档_k8s接口文档-CSDN博客
-
【k8s基础篇】k8s基础2之GVK与GVR_gvk gvr-CSDN博客
次要
- REST: Part 1 - HTTP API 设计思路 - ZengXu’s BLOG
- kubernetes官方案例sample-controller详解
- Kubernetes API Server handler 注册过程分析 | 云原生社区(中国)
- 面向API server CRUD的探索
- K8S中为什么需要Unstructured对象
- Kubernetes编程——client-go基础—— 深入 API Machinery —— Golang 类型转换为 GVK、GVR 和 HTTP 路径,API Machinery概览 - 左扬 - 博客园
- Kubernetes CRD 系列:Api Server 和 GVK®
- Kubernetes CRD 系列:Client-Go 的使用
- kubernetes二次开发系列(1):client-go
- Kubernetes源码 - 随笔分类 - 人艰不拆_zmc - 博客园
- k8s中的所有api-resources类型简介 - 知乎
- Kubernetes的Group、Version、Resource学习小记 - 掘金
- sample-apiserver分析 - 简书
- kube-apiserver代码分析 - API多版本初探 - 刘达的博客
- 理解 Kubernetes 对象 | Kubernetes学习笔记
- Kubernetes 中的资源对象 · Kubernetes 中文指南——云原生应用架构实战手册
- 从 Kubernetes 中的对象谈起 - 面向信仰编程
- 理解Kubernetes的RBAC鉴权模式-腾讯云开发者社区-腾讯云
- Kubectl exec 的工作原理解读 - 米开朗基杨 - 博客园
- Kubernetes RESTMapper源码分析 - 人艰不拆_zmc - 博客园
理解 Restful API(简单了解一下)
-
理解RESTful架构 - 阮一峰的网络日志
-
怎样用通俗的语言解释REST,以及RESTful? - 知乎
-
什么是REST风格? 什么是RESTFUL?(一篇全读懂)_rest风格和restful风格区别-CSDN博客
REST之所以晦涩难懂,是因为前面主语(Resource )被去掉了。
全称是: Resource Representational State Transfer。
指的是客户端通过操作资源的表现形式(Representation)来实现状态(State)的转移。这个概念强调了在 RESTful 架构中,客户端通过与资源的交互来实现应用程序状态的转移,而不需要服务器端保持客户端的状态信息分解开来讲解:
Resource:资源,在 REST 中指的是网络中的任何实体,可以是一个文档、一张图片、一个视频、一个人员、一个部门等等。每个资源都有一个唯一的标识符(URI或URL, 通常是 URL,这两个可以认为是一个东西,URL 是 URI 的子集)用于标识和定位。;
Representational:资源的呈现形式,通常是通过某种媒体类型(如 JSON、XML、HTML 等)来表示资源的数据。客户端通过获取资源的表现形式,并在需要时对其进行操作,来实现状态的转移;
State Transfer:状态变化。指的是客户端通过与资源的交互,改变了资源的状态。这种状态转移通常通过标准的 HTTP 方法(如 GET、POST、PUT、DELETE 等)来实现,每个 HTTP 方法都对应了一种不同的状态转移操作。Rest 是一种架构风格,就是一种设计思想,其落地的方案需要依托底层传输协议,一般采用 HTTP 协议,其形成的 API 也就叫做 Restful API(称之为 Rest 风格 API)
简单总结(说人话):
-
通过操作资源的表现形式来实现状态的转移
- 向 URL (资源)发送请求,请求的内容(一般为 json 形式,表现形式),来获取服务端存储的对象内容或更新服务端存储的内容(状态的转移,若是 GET 请求就是获取,POST 或 PUT 就是更新或新建,DELETE 就是删除)
-
你会想,上面描述不就是正常发起一个 http 请求嘛( 请求某个 URL,请求内容就是 Body 为 json 形式)
- 其实这么理解没错,但是相对于以往 http 有些不同
- REST 强调两个重要概念【资源和状态转移】,资源可以理解为 URL,状态转移可以理解依靠HTTP 方法(如 GET、POST、PUT、DELETE 等)来实现
-
下面举例
-
# 1. 以往 API 设计 # 获取 id=3 的文件 POST 127.0.0.1:8080/unrestful/getFile?id=3 # 获取所有文件 POST 127.0.0.1:8080/unrestful/getAllFiles # 删除 id=3 的文件 POST 127.0.0.1:8080/unrestful/deleteFile?id=3 # 更新 id=3 的文件 POST 127.0.0.1:8080/unrestful/updateFile?id=3# 2. Restful API 设计 # 获取 id=3 的文件 GET 127.0.0.1:8080/restful/files?id=3 # 获取所有文件 GET 127.0.0.1:8080/restful/files # 删除 id=3 的文件 DELETE 127.0.0.1:8080/restful/files?id=3 # 更新 id=3 的文件 POST 127.0.0.1:8080/restful/files?id=3# 总结 # 1. UnRestful API,将资源和对资源的操作耦合在一起,只采用 POST HTTP 操作,因此 URL 很复杂 # 2. Restful API,将资源和对资源的操作解耦,用不同 HTTP 方法(GET/POST/UPDATE)来代表对资源的不同操作,URL仅代表资源,因此更加清晰易懂 # 3. 当程序员调用 UnRestful API 时,需要记住资源的不同操作方法(getFile、getAllFiles、deleteFile、updateFile),若是新增了一个对象,如 Student,同时 API 设计不规范的话(如 getAllStudents 写为 getStudents,getFile 写成 fetchStudent),那会更增加理解、记忆、及编程难度 # 4. 当程序员调用 Restful API 时,只需要记住 HTTP 方法(GET/POST/UPDATE)和对应的资源名称(files),若新增了 Students,那么只需要记住新增的名称 students(注意,一般在 URL 中都是小写字母)
-
-
总结,记住这几句话
- 看 URL 就知道要什么(资源)
- 看 HTTP Method 就知道干什么(对资源的操作)
- 看 HTTP Status Code 就知道结果如何(操作后的结果)
-
看了上面内容,能理解 URL 就是资源(Resource)就可以,这个有助于理解下面 K8S 中的 Resource
理解 K8S 各资源术语及概念
总览
| 简称 | 全称(或翻译) | 作用 |
|---|---|---|
| Kind | 资源类型 | 用于确定创建哪种资源, 并结合 Group、Version,形成 GVK 在 Schema 中寻找对应的数据结构, 从而进行资源对象的创建 |
| Object | 资源对象 | GVK 创建的存储在 etcd 中的资源实体,称之为资源对象 |
| Resource | APIResource (接口资源) | Kind 的小写字母复数形式,该结构具有多种属性字段 (如是否具有 Namespace 概念,如 Pod 具有,ClusterRole 不具有) 主要用于结合 Group、Version,形成 GVR ,从而生成资源 URI (HTTP Path、URL) |
| Version | APIVersion (接口版本) | 用于管理 Resource 和 Kind 资源,相当于版本管理 Resource 和 Kind 资源可以多个 Version,如 v1aplha1、v1beta1、v1 等, 相当于版本管理,每个版本可能在上一版本新增了某些属性(字段) |
| Group | APIGroup (接口组) | 用于管理 Resource 和 Kind 资源,相当于功能职责管理 应该出于这种考虑,Resource 和 Kind 有多种功能,同种或类似功能的放在一个 Group(比如认证相关放在rbac.authorization.k8s.io Group 中,网络相关放在 networking.k8s.io Group 中,部署相关放在 apps 组中等) |
| 因此形成了如此组织结构:Group --> Version --> Kind 或 Resource | ||
| apiserver | 串联上面概念 | apiserver 可以理解为【 http Server】,那么就需要 http path --> handler 的映射关系 外部只有知道 http path (GVR)才能发起请求(如创建、更改、删除等),可以说认为此 http path 就是 Resource(可以查看上面 Restful API 介绍),之后 handler 收到请求后,进行后来处理(此处是内部逻辑 GVK),创建对应的资源对象实体(Object)进行存储 |
| 以 Pod 创建说明此过程 | ||
| 0. 首先 apiserver 预先注册了 http path 与 handler 的对应关系,然后对外提供服务 | ||
| 1. 用户提交 Pod yaml,创建 Pod,其中制定了 GVK | ||
| 2. Pod yaml 相当于请求的 body 内容,提交到哪个 http path 呢? 首先通过 yaml 获取 GVK,然后通过 RestMapper 机制(k8s内部逻辑)转换为 GVR,之后将 GVR 转换为 http path | ||
| 3. 之后该 http path 对应的 handler 该处理了,首先通过 GVK 查询 Schema (k8s 内部的注册表,记录了 GVK 与资源数据结构的对应关系)知道到此次创建的是 Pod Struct,而不是 Deployment,之后将 Pod yaml 中的信息填写到此 Pod Struct 字段中 | ||
| 4. 之后需要持久化,将该 Pod Struct 进行持久化处理,存入到 etcd 数据库中,该存储实体称之为 Object |
- kube-apiserver作为整个Kubernetes集群操作etcd的唯一入口,负责Kubernetes各资源的认证&鉴权、校验以及CRUD等操作,提供RESTful APIs,供其它组件调用:
- 一文读懂 Kubernetes APIServer 原理 - k8s-kb - 博客园
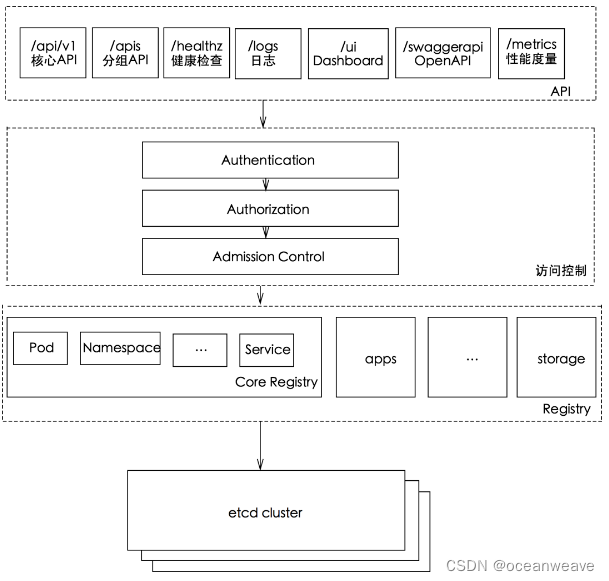
- Create 请求的流程可以总结为下图
- Kubernetes API Server handler 注册过程分析 | 云原生社区(中国)
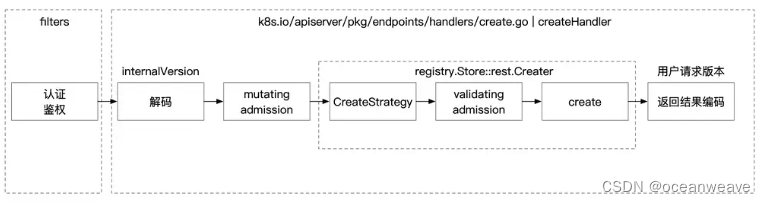
对象(OBJECT) 和 资源(RESOURCE) 的区别
-
K8S - API 对象 - 潜水滴海军的blog
-
RESTful API 中的基本概念是资源,每个资源都分配有唯一标识它的 URI 或统一资源标识符(或称之为 http path 、http 端点、URL,本文中以下这几个名称表达意思相同)。
例如,在 Kubernetes API 中,应用程序部署由部署资源表示。
集群中所有部署的集合是在/api/v1/deployments. 当您使用该 GET 方法向此 URI 发送 HTTP 请求时,您会收到一个列出集群中所有部署实例的响应。
每个单独的部署实例也有自己唯一的 URI,通过它可以对其进行操作。因此,单个部署作为另一个 REST 资源公开。您可以通过向资源 URI 发送 GET 请求来检索有关部署的信息,并且可以使用PUT请求对其进行修改。
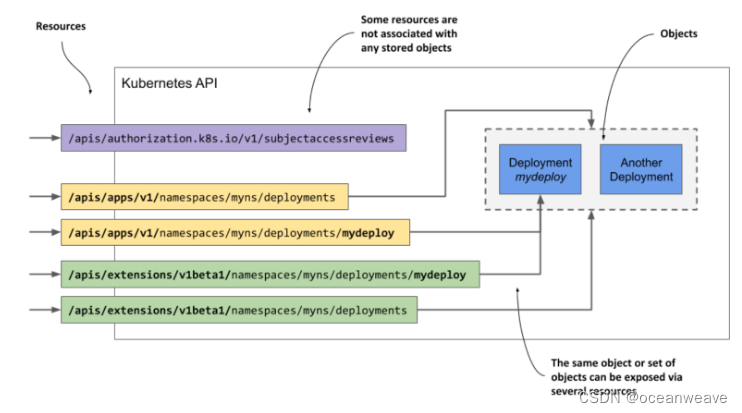
因此,一个对象可以通过多个资源公开。如图所示:
- 当您查询
deployments资源时(/apis/apps/v1/namespces/myns/deployments),命名的 Deployment 对象实例mydeploy作为集合元素返回 - 当您直接查询单个资源 URI 时(/apis/apps/v1/namespces/myns/deployments/mydeploy),则作为单个对象返回。
在某些情况下,资源根本不代表任何对象。
这方面的一个例子是:
Kubernetes API 允许客户端验证主体(人或服务)是否被授权执行 API 操作的方式。这是通过向资源提交POST请求到 /apis/authorization.k8s.io/v1/subjectaccessreviews 来完成的。接口响应表明了主体是否被授权了,执行请求正文中指定的操作。这里的关键是 POST 请求没有创建任何对象。
上述例子表明,资源 和 对象 并不是完全相同的。如果你熟悉关系型数据库,你可以把 资源 和 对象 比作 视图 和 表。资源 就是你与对象进行交互的 “视图”。
用故事理解 GVK/GVR/Object/Schema/RestMapper
现在有无数个硬盘,用户需要创建文件存储到这些硬盘中,目前由如下规则
- 每个硬盘命名为 Group 名,
- 用户通过 Kind 指定创建文件的种类(Kind 为了便于识别,都采用首字母大写,如 Sh、Doc、Docx、Ppt、Txt、Json 文件等,对应的文件后缀为 sh、doc、docx、ppt、txt、json等,)
现在假如有两个硬盘,
- group1 硬盘(支持Kind 为 Sh、Doc、Txt )和 group2(支持 Kind 为 Sh、Ppt),
- 这两个硬盘都具有 Kind 为 Sh 的种类,就是都能创建 sh 文件(不过这两个硬盘的 sh 用处不一样,因此文件权限不一样,【group1 中的 sh 文件可以执行,group2 中的 sh 文件不能执行】),
Group、Version、Kind 概念的引入
Group 表示功能职责管理,不同职责功能的 Kind 放入到不同 Group 中
Version 表示 版本管理
Kind 表示 资源的类型(创建何种类型资源)
- 两个硬盘都具有 Kind 为 Sh 的种类,那若此时创建 Kind=Sh 的名为 test1 文件,该存储到哪个硬盘中?
- 所以引入 Group 概念,创建时候应该说清出,创建【可以执行的】 sh 文件(即指定 Group=group1、Kind=Sh);但因为 group1 有多个 Kind (Sh、Doc、Txt),所以创建一个 shs 文件夹( Kind 小写字母复数形式,表示保存此类型文件,且数量较多),所以该 sh 文件目前的存储路径应该为
group1硬盘\shs\test1.sh - 但同时我们还有个规划,后续 Kind=Sh 的文件存储到 group1 中会自动加上水印,因此我们将目前这个无水印版本称之为 v1alpha1 版本,后续有水印版本称之为 v1 版本,那怎么区分呢?
- 答:在 Kind 的上一级创建 Version (版本)文件夹,无水印版本创建 v1alpha1 文件夹,有水印版本创建 v1 文件夹,所以 test1.sh 对应的文件夹路径应改为
group1硬盘\v1alpha1\shs\test1.sh
- 答:在 Kind 的上一级创建 Version (版本)文件夹,无水印版本创建 v1alpha1 文件夹,有水印版本创建 v1 文件夹,所以 test1.sh 对应的文件夹路径应改为
- 那就带来一个问题,若现在创建一个【可执行的、有水印的、Kind=Sh】名为 test2 的文件,只是指定 Group=group1 和 Kind=Sh ,也无法确定该 sh 该存储到哪个文件夹中,所以引入 Version 的概念,指定【Group=group1、Version=v1、 Kind=Sh】,这样便可以直到存储路径应为
group1硬盘\v1\shs,最后的文件路径为group1硬盘\v1\shs\test2.sh
Namespace 概念引入
Namespace 用于 资源隔离
上面需求刚解决完成,又来个需求,user1 用户创建的 sh 文件想要和 user2 创建的 sh 文件分隔开,而现在所有用户创建【可执行的 Group=group1、有水印的Version=v1、Kind=Sh】,都存储在group1硬盘\v1\shs 路径下,没有隔离性,user1 分不清这些文件中哪个是自己创建的,哪个是 user2 创建的,比如 user1 和 user2 都创建个【可执行的 Group=group1、有水印的Version=v1、Kind=Sh】名为 test3 的文件,就会冲突
- 为了解决这个问题,我们提出个 Namespace 的概念,在 Kind 的上一级创建 Namespace 文件夹,比如 user1 的 Namespace 文件夹命名为 user1,user2 的 Namespace 文件夹命名为 user2,这样就分隔开了, user1 存储路径为
group1硬盘\v1\user1\shs\test3.sh - 这样解决了【user1和user2创建文件冲突的问题】,但还有不足,就是
group1硬盘\v1\user1\shs\test3.sh路径可读性不强,从后往前读可知,test3.sh 前面是 shs,说明 test3.sh 文件时 Kind=Sh 类型,但 user1 我们就不太清楚是什么概念,同时有的用户名若是乱码如sdfsf,那就编程group1硬盘\v1\sdfsf\shs\test3.sh,就更不清楚该路径的语义,而 Group 硬盘名 和 Version 名数量是有限的,而且用户无法自定义,同时命名也是易懂的,所以不需要上层概念就能理解;- 所以为了解决此问题,我们在 Version 文件夹下一级增加 namespaces 文件夹(表名下一层级是 Namespace 概念,复数表示有众多 Namespace 文件夹),然后 namespaces 文件夹中创建【用户名对应的 Namespace 文件夹】,形式如下
Group硬盘名\Version名\namespaces\用户自定义Namespace文件夹\Kind文件夹\Kind文件,因此 user1 创建的 test3.sh 对应的路径为group1硬盘\v1\namespaces\user1\shs\test3.sh
- 所以为了解决此问题,我们在 Version 文件夹下一级增加 namespaces 文件夹(表名下一层级是 Namespace 概念,复数表示有众多 Namespace 文件夹),然后 namespaces 文件夹中创建【用户名对应的 Namespace 文件夹】,形式如下
全局概念引入
仍需要保留【非Namespace】的概念,有的资源需要全局独一份,用于全局管控,如 ClusterRole
上面解决了用户隔离问题,但同时还有个新的需求,group1 硬盘中 Version=v1、Kind=Doc 的文件是可全局访问到的、是重要的,同时需要保证唯一性;因此 user1 创建 doc 文件保存到 user1 Namespace 中,user2 创建 doc 文间保存到 user2 Namespace 中,都是存储在自己的 Namespace 文件夹中,因为文件夹的权限控制,user2 无法问到 user1 的 Namespace 文件夹、user1 也无法访问到 user2 的 Namespace 文件夹;
- 因此创建 Doc 文件需要考虑放到一个公共的文件夹,这样所有 user 都可以访问,同时保证 doc 文件的唯一(同一个文件夹不会有重名文件)
- 基于此需求,我们对 Doc 文件的创建取消 Namespace 的概念,如创建【Group=group1硬盘、Version=v1、Kind=Doc、名为 test4】,那么对应的路径为
group1硬盘\v1\docs\test4.doc
Resource 概念引入
由于由【Namespace】和【非Namespace】情况存在,GVK 无法判断出资源 URI 中是否要携带 Namespace 路径
而 GVR 可以解决此问题,Resource 中预先写入【控制信息】(如 Pod 的 Namespaced = True,ClusterRole 的 Namespaced = False)
所以也分清了职责
- GVK 专注于定位到资源的数据结构
- GVR 专注于生成资源描述符(URI),用于找到资源对象(Object)
上面共用问题也解决了,但也带来个问题,何时创建 Namespace 文件夹(或说哪种资源该创建 Namespace,同时应该如何控制)
-
【Group=group1硬盘、Version=v1、Kind=Sh】,这种资源该创建 Namespace 文件夹
-
但 【Group=group1硬盘、Version=v1、Kind=Doc】,这种资源不该创建 Namespace 文件夹
-
而通过这种 GVK 的组合,创建资源时无法判断是否应该创建 Namespace 文件夹;不过也有种方法解决,【在后台将判断逻辑写死 Kind=Sh 就创建 Namespace 文件夹,Kind=Doc 就不创建 Namespace 文件夹,但这种方式不够灵活,程序是写死的,若后续这两情况反过来,还需要重新编译程序】 —— 因此为了解决这个问题,提出了 Resource 的概念
-
Resource ,也可以称之为 APIResource ,是 Kind 的同名小写复数形式(如 Kind=Sh,Resource=shs;Kind=Doc,Resource=docs),同时该 Resource 结构不同于 Kind,Kind 是 string 字符串,Resource 是结构体,Resource 内部具有个 Namespaced 属性(若 Namespaced=True 表示创建该资源时会创建 Namespace 文件夹,反之不会创建);如 Kind=Sh 对应的 shs Resource 结构就具有 Namespaced=True,这样提交 【Group=group1硬盘、Version=v1、Kind=Sh、user1、文件名为 test5】的创建请求时,GVK 会自动转换为 GVR,根据 GVR 中 Resource 的设置,形成相应的存储路径
group1硬盘\v1\namespaces\user1\shs\test5.sh;而Kind=Doc 对应的 docs Resource 结构就具有 Namespaced=False,后续不会创建 Namespace 文件夹,不在详解
Rest 映射、Schema、Object
Rest 映射( RestMapper):实现 GVK 和 GVR 的互相转换
Schema:GVK 和 资源数据结构的映射表
Object:资源对象,也可以称为 资源存储实体
-
那 GVK 和 GVR 具体是如何转换的呢? —— 答:Rest 映射,有个 RestMapper 结构,此处不在详解
-
Group/Version/Kind (Rest 映射–>)Group/Version/Resource (GVR 形成–>)路径(path) group1硬盘/v1/Sh group1硬盘/v1/shs(Namespaced=True) group1硬盘\v1\namespaces\{{user自定义那namespace}}\shs\{{用户创建的sh文件}} group1硬盘/v1/Doc group1硬盘/v1/docs(Namespaced=False) group1硬盘\v1\docs\{{用户创建的doc文件}}
-
-
最后还有个问题,GVK 相当于指定创建【何种类型的文件】,但这么多 GVK 和文件类型的对应关系,我该如何记住呢 —— 答:引入了 Schema 概念,可将 Schema 理解为一个记录表,记录 GVK 与创建文件类型的关系
-
Group/Version/Kind 文件类型 group1硬盘/v1alpha1/Sh 无水印的 sh 文件 group1硬盘/v1/Sh 有水印的 sh 文件 省略若干 GVK 介绍 group1硬盘/v1/Doc 有水印的 Doc 文件
-
-
还差一个概念 Object,就是 GVK 对应创建出的真实文件,可理解为实际的存储
故事总结
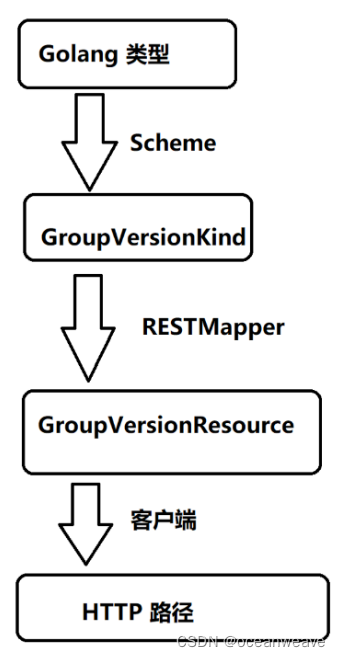
-
Group 组、Version版本、Namespace 命名空间,这些都很容易理解,都是为了隔离,资源版本隔离(Group、Version)和用户资源隔离(Namespace)
-
Kind 对象类型,如 Kind=Sh 对应 sh 类型文件,Kind=Doc 对应 doc 类型文件
-
Resource 可以理解为 Kind 的含义补充,用于获取真正的资源对象;GVK 专注于类型定义,确定是哪种资源对象,GVR 专注于获取资源对象或对资源对象进行操作;GVR 可转换为资源对象的存储路径 Path,对应实际中就是 http path(对应 Restful API 中 URI、URL 的概念,可以说是文件资源标识),我们拿到了 URL 或 PATH,自然就可以访问到资源实体,所以称之为 Resource 很合理
-
Object 就是 GVK 创建的真正的资源存储实体,也是通过 GVR 形成 Path 所要访问的资源实体
-
Schema 是记录 GVK 与 资源结构的映射,知道 GVK 便知道要创建的资源对象的数据结构
-
GVK 和 GVR 是通过 Rest 进行映射,GVK 只专注于类型定义,GVR 包含构建资源路径的各种细节(比如是否要添加 namespace 路径等)
-
为什么这么定义?
-
可将 apiserver 理解为一个普通的 http server
-
外部视角:用户通过 URL 才能访问到对应的资源吧,因此会认为 URL(HTTP PATH) 为 Resource(Restful API 中也是将 URL 定义为 Resource,所以 GVR 相当于一个用于生产外部 URL Resource 的概念)
-
内部视角:用户提交指定 GVK 的 yaml,通过 GVK 检索(Schema)到对应的资源结构(Go Struct),才能创建资源,并完成持久化存储(Object)
-
apiserver 视角:本身是个 http Server,在启动前预先注册了 http path --> handler 的映射关系(就是用户向指定 http path 提交请求时,需要有对应的 handler 处理);通过 http path 可知道 GVR,但 GVR 不知道对应的资源结构(Go Struct),所以 GVR 和 GVK 存在个互相转换机制(RestMapper),这样通过 GVK 可知道该 http path 请求对应的资源结构(Go Struct),之后便交给 handler 处理;同时有时候只知道 GVK,但需要向指定路径 http path 发起请求,就需要通过互相转换机制(RestMapper)将 GVK 转换为 GVR,从而生成 http path
-
k8s 实操来理解概念
准备工作
# 开启 8080 端口,用于 http 访问
-> % kubectl proxy --port=8080
Starting to serve on 127.0.0.1:8080
案例一(支持 Namespace 的 Deployment, apps 组,apis 前缀)
# 案例一(支持 Namespace 的 Deployment, apps 组,apis 前缀)
# 创建 deployment 名为 encode-deploy
kubectl create deployment encode-deploy --image=busybox --replicas=1 -- /bin/sh -c "while true; do sleep 3600; done"# deployment 的 GVK 为 apps/v1/Deployment
# 对应的 GVR 为 apps/v1/dployments,同时 deployment 支持 Namespace 隔离,而且该 deployment 在 default Namespace 下创建
# 所以 GVR 形成的路径为 apps/v1/namespaces/default/deployments/encode-deploy
# 同时有个知识点需要注意:因为 k8s 开始没有 Group 的概念,后来才有,所以 k8s 的基础资源如 Pod 的 Group 都为空,称之为 core,但在路径中没有表示,所以又创建个 api 和 apis 概念,api 只放置 core 组,其余后续的 Group 都在 apis 组
# 所以上面路径变为 apis/apps/v1/namespaces/default/deployments/encode-deploy
# 再补上 apiserver 的地址 http://localhost:8080
# 组成全路径,获取 encode-deploy 信息
$ curl http://localhost:8080/apis/apps/v1/namespaces/default/deployments/encode-deploy
# 返回的结果
{"kind": "Deployment","apiVersion": "apps/v1","metadata": {"name": "encode-deploy","namespace": "default","uid": "0bfd0275-cd3c-4602-81be-f996cc055cb2","resourceVersion": "204043","generation": 3,"creationTimestamp": "2024-02-28T08:08:52Z","labels": {"app": "encode-deploy"},"annotations": {"deployment.kubernetes.io/revision": "1"},......
}
案例二(支持 Namespace 的 Pod, core 组,api 前缀)
# 案例二(支持 Namespace 的 Pod, core 组,api 前缀)
# 创建 pod 名为 encode-po
$ kubectl run encode-po --image=busybox -- /bin/sh -c "while true; do sleep 3600; done"
# 按照上面讲解的,pod 的 GVK 为 Group=空 Version=v1 Kind=Pod, Group=空 称之为 core 组 对应的路径为 api 开头
# 同时 Pod 的 Resource 支持 Namespace 隔离,所以 GVR 对应的 Path 为
# api/v1/namespaces/default/pods/encode-po
$ curl http://localhost:8080/api/v1/namespaces/default/pods/encode-po
# 返回的结果
{"kind": "Pod","apiVersion": "v1","metadata": {"name": "encode-po","namespace": "default","uid": "13dd4951-321c-45e5-bcb2-33b1e60f3954","resourceVersion": "193006","creationTimestamp": "2024-02-28T03:17:20Z","labels": {"run": "encode-po"},... ...
}
案例三(不支持 Namespace 的 ClusterRole, core 组,api 前缀)
- 扩展内容
- 为什么 core Group,在路径中不显示 core,而路径前面多了 api?
- 为什么非 core Group,在路径前面多了 apis 前缀?
# 扩展内容
# - 会奇怪 Pod 为什么只有 v1,没有 Group,因为最开始 k8s 没有 Group 概念,后续新增的,所以最早的基础资源 Group=空,称之为 core Group(核心组),但实际创建 Pod 时候不会写为 core/v1(仍是写为 v1),称之为 core Group 只是为了便于读和理解,总不能说是 Pod 属于【空Group】吧?这样太难理解了。。。
# 而且还有个问题,记得 GVR 转换 http path 的 规则吧
# Resource 支持 Namespace 时
# GVK --> GVR --> HTTP PATH: /Group名/Version名/namespaces/namesapce名/Resouces名(Kind小写复数形式)/具体对象名称
# Resource 不支持 Namespace 时
# GVK --> GVR --> HTTP PATH: /Group名/Version名/Resouces名(Kind小写复数形式)/具体对象名称
# 按照转换规则 Pod GVK(Group=空,Version=v1,Kind=Pod)对应的 Path 为,default namespace 下名为 encode-po Pod 对应的 http path 为 v1/namespaces/default/pods/encode-po
# 按照转换规则 Deployment GVK(Group=apps,Version=v1,Kind=Pod)对应的 Path 为,default namespace 下名为 encode-deploy Deployment 对应的 http path 为 apps/v1/namespaces/default/deploy/encode-deploy
# 可以看出,Pod 相比于 Deploy 少了个 Group 前缀,不易于理解,所以为了便于理解,在 Group 前面增加 api 和 apis 概念,规则就是只有 core Group 添加 api 前缀,其余 Group 都添加 apis 前缀,相当于一个再次分类,毕竟 Pod 等 core Group 中的资源属于【老员工】,有个独立的【api办公室】是可以理解的
# 所以演变为:
# core Group 资源路径:v1/namespaces/default/pods/encode-po --> api/v1/namespaces/default/pods/encode-po
# 非 core Group 资源路径: apps/v1/namespaces/default/deploy/encode-deploy --> apis/apps/v1/namespaces/default/deploy/encode-deploy
- 案例三
# 案例三(不支持 Namespace 的 ClusterRole, core 组,api 前缀)
# 不知道 ClusterRole 是哪个组,可以采用 kubectl-apiresources 命令进行搜索
# 返回的内容:记录了 GVR 和 GVK 的对应关系,还有 Resource 是否支持 Namespace 信息
# 第一列 Resource 名称(可以看出是小写字母复数形式)
# 第二列 该 Resource 的缩写,比如 pods 的缩写为 po,因此 kubectl get pods 等同于 kubectl get po,但同时需要注意有的没有缩写
# 第三列 该 Resource 和 Kind,所属于的 Group/Version,v1 代表 core Group 没有 Group 名
# 第四列 该 Resource 是否支持 Namespace 隔离,Namespaced=True 表示支持
# 第五轮 Kind 名称(包含大写字母)$ kubectl api-resources
NAME SHORTNAMES APIVERSION NAMESPACED KIND
bindings v1 true Binding
componentstatuses cs v1 false ComponentStatus
configmaps cm v1 true ConfigMap
endpoints ep v1 true Endpoints
events ev v1 true Event
pods po v1 true Pod
podtemplates v1 true PodTemplate
limitranges limits v1 true LimitRange
daemonsets ds apps/v1 true DaemonSet
deployments deploy apps/v1 true Deployment
replicasets rs apps/v1 true ReplicaSet
statefulsets sts apps/v1 true StatefulSet
... ...# 上面信息太多,想要知道 ClusterRole 属于哪个 Group Version,可以看到如下命令
# 另外,可以看到 ClusterRole 对应的 Namespced=False, 不具备 Namespace 隔离,符合我们的测试要求
$ kubectl api-resources | grep clusterroleclusterrolebindings rbac.authorization.k8s.io/v1 false ClusterRoleBinding
clusterroles rbac.authorization.k8s.io/v1 false ClusterRole# 随意查看个已有的 ClusterRole
$ bectl get clusterrole
NAME CREATED AT
admin 2024-01-30T09:53:07Z
cluster-admin 2024-01-30T09:53:07Z
... ...# 以 admin ClusterRole 为例, 按照上面构建路径,并发起请求,符合预期
curl http://localhost:8080/apis/rbac.authorization.k8s.io/v1/clusterroles/admin
{"kind": "ClusterRole","apiVersion": "rbac.authorization.k8s.io/v1","metadata": {"name": "admin","uid": "37abf107-240e-474e-a65b-5827aff7cf00","resourceVersion": "336","creationTimestamp": "2024-01-30T09:53:07Z","labels": {"kubernetes.io/bootstrapping": "rbac-defaults"},"annotations": {"rbac.authorization.kubernetes.io/autoupdate": "true"},... ...
}
SubResource 概念的引入
- 相信你已理解上面 Resource 的概念,那 subResource 概念是什么意思呢?
- 现在可以简单理解为,通过 curl GVR 形成的 http path 可以获取到一个 Deployment (此处示例为 default Namespace 下名为 encode-deploy 的 Deploy)的所有信息
curl http://localhost:8080/apis/apps/v1/namespaces/default/deployments/encode-deploy- 此时会带来几个考虑
- 用户1只想更改 encode-deploy 的副本数 replicas,觉得返回一堆信息没必要,增加更改复杂度
- 用户2比较危险,需求只想更改 encode-deploy 的副本数 replicas,但现在其可以更改该 Deployment 的所有字段
- 所以给 deployments Resource 增加了 scale Resource 用于更改 Deployment 的副本数
- 路径变为了
curl http://localhost:8080/apis/apps/v1/namespaces/default/deployments/encode-deploy/scale - 通过此路径,可以更改 Deployment 的副本数,也就是 replicas 字段
- 以往在 RBAC 中只能赋予
deployments权限,现在可以赋予deployments/scale权限,让用户只能更改副本数,无法更改其余字段
- 路径变为了
subresource 作用
Question1 : 可以通过 kubectl edit 更改 deployment 副本数,为什么还提出一个 scale subresource(子资源)
- API 一致性和规范性:Kubernetes 的设计哲学之一是提供统一的 API。通过为资源引入 scale 子资源,可以使得副本数的管理变得更加规范和统一,无论是通过 kubectl、API 或者其他工具,用户都可以使用相同的方法来管理副本数。这种一致性有助于降低用户学习成本,并简化资源管理。
- 权限控制和安全性:引入 scale 子资源可以使得 Kubernetes 更加灵活地进行权限控制。通过 RBAC(基于角色的访问控制)机制,管理员可以精确地控制哪些用户或服务账号具有修改副本数的权限,而不必担心他们能否编辑整个 Deployment 对象或其他资源。
- 自动缩放支持:许多 Kubernetes 集群中使用了自动缩放功能,例如 HorizontalPodAutoscaler (HPA)。HPA 可以根据资源使用率或自定义指标动态调整副本数。scale 子资源为这种自动缩放功能提供了支持,HPA 可以通过 scale 子资源查询和调整资源的副本数,从而实现自动化的水平扩展和收缩。
简而言之(说人话):
- 明显 kubectl edit 对应的 curl 比 kubectl scale 繁琐
- API 统一:scale subresource 出现后,statefulset、deployment、daemonset 扩缩容发起 http 请求时,只需要关注 scale 子资源,就是 curl …/scale,很统一
- 若采用 kubectl edit 进行扩容,用户需要具有【修改整个 deployment 对象的 update 权限,过大】,而采用 kubectl scale,用户只需要具有【deployment/scale 子资源的 update 权限,范围缩小,更安全】
- 增加了 scale 子资源后,便于进行自动缩放功能
Question2: 为什么 curl 更改 scale subresource 后,就可以进行 deployment 的扩缩
curl -X PUT
-H “Content-Type: application/json”
–data ‘{“apiVersion”:“autoscaling/v1”,“kind”:“Scale”,“metadata”:{“name”:“encode-deploy”,“namespace”:“default”},“spec”:{“replicas”:2}}’
http://localhost:8080/apis/apps/v1/namespaces/default/deployments/encode-deploy/scale
- 增加 scale subresource,其实就相当于【增加一个 http path 端点】
- 以往 deployment http 端点为 http://localhost:8080/apis/apps/v1/namespaces/default/deployments/encode-deploy
- 而该新增的 scale http path 端点,对应的 http handler ,其实功能很简单,就是更改指定 deployment 的 spec.replicas(此例子是 encode-deploy 的 replicas),之后逻辑就很好理解了,deployment Controller 监控到 encode-deploy replicas 副本数的变化,便会进行相应的扩缩容
k8s 实操 subresource
# 开启 8080 端口,用于 http 访问
-> % kubectl proxy --port=8080
Starting to serve on 127.0.0.1:8080# 创建 deployment 名为 encode-deploy
kubectl create deployment encode-deploy --image=busybox --replicas=1 -- /bin/sh -c "while true; do sleep 3600; done"# 对 encode-deploy 进行扩容
# 方法1: 通过 scale subresource 进行扩容,对 scale http 端点发请求
-> % curl -X PUT \-H "Content-Type: application/json" \--data '{"apiVersion":"autoscaling/v1","kind":"Scale","metadata":{"name":"encode-deploy","namespace":"default"},"spec":{"replicas":2}}' \http://localhost:8080/apis/apps/v1/namespaces/default/deployments/encode-deploy/scale
# 成功执行
{"kind": "Scale","apiVersion": "autoscaling/v1","metadata": {"name": "encode-deploy","namespace": "default","uid": "0bfd0275-cd3c-4602-81be-f996cc055cb2","resourceVersion": "203932","creationTimestamp": "2024-02-28T08:08:52Z"},"spec": {"replicas": 2},"status": {"replicas": 1,"selector": "app=encode-deploy"}
}%# kubectl scale(等同于上面,只是进行了封装,内部逻辑相同,实际代码执行逻辑等同于上面 curl)
-> % kubectl scale deploy encode-deploy --replicas=2
deployment.apps/encode-deploy scaled# 方法2: 利用 kubectl edit 进行扩容,更改该 deploy 中的 spec.replicas 为 2
# 实际等同于,以下3步(未验证,可做参考),相比于 scale subresource 繁琐
# 1. 获取当前 yaml 配置:curl http://localhost:8080/apis/apps/v1/namespaces/default/deployments/encode-deploy -o deployment.yaml
# 2. 修改 yaml 配置:接下来,编辑 deployment.yaml 文件,将 spec.replicas 字段的值修改为 2
# 3. 上传新的 yaml 配置:curl -X PUT -H "Content-Type: application/yaml" --data-binary "@deployment.yaml" http://localhost:8080/apis/apps/v1/namespaces/default/deployments/encode-deploy
kubectl edit deploy encode-deploy
# 修改 spec.replicas 为 2 ,保存 esc :wq
获取 subresource
- Where can I get a list of Kubernetes API resources and subresources? - Stack Overflow
- 由于无法直接查看到 Resource 有哪些 subResource,通过此脚本可以看到有哪些 subResource
# 1. 开启 proxy 8080 端口,http 不安全访问
$ kubectl proxy --port=8080# 2. 执行如下脚本获取 subresource
# 若不执行第一步,未开启8080端口,那么将 curl -s $SERVER/ 替换为 kubectl get --raw / 即可正常执行
#!/bin/bash
SERVER="localhost:8080"APIS=$(curl -s $SERVER/apis | jq -r '[.groups | .[].name] | join(" ")')# do core resources first, which are at a separate api location
api="core"
curl -s $SERVER/api/v1 | jq -r --arg api "$api" '.resources | .[] | "\($api) \(.name): \(.verbs | join(" "))"'# now do non-core resources
for api in $APIS; doversion=$(curl -s $SERVER/apis/$api | jq -r '.preferredVersion.version')curl -s $SERVER/apis/$api/$version | jq -r --arg api "$api" '.resources | .[]? | "\($api) \(.name): \(.verbs | join(" "))"'
done# 3. 执行结果举例
...
core pods: create delete deletecollection get list patch update watch
core pods/attach: create get
core pods/binding: create
core pods/ephemeralcontainers: get patch update
core pods/eviction: create
core pods/exec: create get
core pods/log: get
core pods/portforward: create get
core pods/proxy: create delete get patch update
core pods/status: get patch update
...
理解 k8s 主要 go 库作用
- Kubernetes类型系统 | 李乾坤的博客
k8s中Apimachinery、Api、Client-go库之间的关系k8s.io/client-go, k8s.io/api, k8s.io/apimachinery 是基于Golang的 Kubernetes 编程的核心,是 schema 的实现。kubernetes 中 schema 就是 GVK 的属性约束 与 GVR 之间的映射。
- apimachinery 是最基础的库,包括核心的数据结构,比如 Scheme、Group、Version、Kind、Resource,以及排列组合出来的 常用的GVK、GV、GK、GVR等等,再就是编码、解码等操作。类似于Java 中的Class/Method/Field 这些。
- api 库,这个库依赖 apimachinery,提供了k8s的内置资源,以及注册到 Scheme 的接口,这些资源比如:Pod、Service、Deployment、Namespace
- client-go 库,这个库依赖前两个库,提供了访问k8s 内置资源的sdk,最常用的就是 clientSet。底层通过 http 请求访问k8s 的 api-server,从etcd获取资源信息


![LeetCode 刷题 [C++] 第226题.翻转二叉树](https://img-blog.csdnimg.cn/direct/b95f6cf4db03439380eca20a6b2eecfa.png)