主要参考
https://zhuanlan.zhihu.com/p/366592542
https://mp.weixin.qq.com/s/b-_M8GPK7FD7nbPlN703HQ其他参考
原理 https://zhuanlan.zhihu.com/p/627448301
多头注意力机制 https://zhuanlan.zhihu.com/p/611684065
https://blog.csdn.net/shizheng_Li/article/details/131721198
面试概念
https://zhuanlan.zhihu.com/p/425336990
RNN
RNN 循环神经网络(Rerrent Neural Network,RNN),能够将之前的信息储存在隐藏层中,从而与后面的信息进行计算。
问题是:不能并行计算,而且对于长序列,容易出现记忆丢失的问题,也就是梯度消失

RNN 的关键点之一就是他们可以用来连接先前的信息到当前的任务上,例如使用过去的视频段来推测对当前段的理解。
LSTM
长短期记忆网络(LSTM,Long Short-Term Memory)是一种时间循环神经网络,是为了解决一般的RNN(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的RNN都具有一种重复神经网络模块的链式形式。
输入门,记忆门,遗忘门。
后来还提出了双向LSTM ,BILLSTM,来解决后面序列信息对前面的影响
Transformer
attention
注意力机制, 分为self-attention, multi-head attention等。
输入是query和 key-value,注意力机制首先计算query与每个key的关联性(compatibility),每个关联性作为每个value的权重(weight),各个权重与value的乘积相加得到输出。
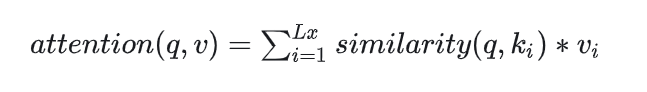
class ScaledDotProductAttention(nn.Module):""" Scaled Dot-Product Attention """def __init__(self, scale):super(ScaledDotProductAttention,self).__init__()self.scale = scaleself.softmax = nn.Softmax(dim=2)def forward(self, q, k, v, mask=None):u = torch.bmm(q, k.transpose(1, 2)) # 1.Matmulu = u / self.scale # 2.Scaleif mask is not None:u = u.masked_fill(mask, -np.inf) # 3.Maskattn = self.softmax(u) # 4.Softmaxoutput = torch.bmm(attn, v) # 5.Outputreturn attn, outputif __name__ == "__main__":batch = 2n_q, n_k, n_v = 2, 4, 4d_q, d_k, d_v = 128, 128, 64q = torch.randn(batch, n_q, d_q)k = torch.randn(batch, n_k, d_k)v = torch.randn(batch, n_v, d_v)mask = torch.zeros(batch, n_q, n_k).bool()attention = ScaledDotProductAttention(scale=np.power(d_k, 0.5))attn, output = attention(q, k, v, mask=mask)print(attn)print(output)
mask = torch.zeros(batch, n_q, n_k).bool()
这行代码是在使用 PyTorch 创建一个布尔型的零张量。具体来说,它创建了一个形状为(batch, n_q, n_k)的张量,其中的所有元素都被初始化为 False(因为在 Python 中,False 等价于 0,True 等价于 1)。
u = u.masked_fill(mask, -np.inf)
masked_fill是一个 PyTorch 张量的方法,它将mask中为 True 的元素的对应位置上的u中的元素替换为-np.inf。
这里的关键在于理解mask的作用。mask是一个布尔型张量,其中的True和False值表示我们希望保留还是忽略对应的u中的元素。在这种情况下,我们希望忽略mask中为 True 的元素,因此在u中将这些位置的值设置为负无穷大(-np.inf)。这样做的目的可能是为了在接下来的操作中排除这些被标记的元素。例如,如果我们接下来要对
u进行 softmax 操作,由于负无穷大在softmax 运算中会被视为 0,这样我们就可以有效地忽略掉那些在mask中被标记为True的元素。
self attention
self -attention 就是Q、K、 V 都是本身的注意力机制,比如transformer模型中的Encoder部分。self-attention 在文本序列中,能够挖掘出文本中不同字词之间的联系。不同与LSTM是有向性的记忆与遗忘字词之间的关系。
multi-head attention
注意力并行化的代表,多头注意力不仅计算一次注意力,而是并行化计算多次注意力,这样模型可以同时关注多个子空间的信息。
class MultiHeadAttention(nn.Module):""" Multi-Head Attention """def __init__(self, n_head, d_k_, d_v_, d_k, d_v, d_o):super().__init__()self.n_head = n_headself.d_k = d_kself.d_v = d_vself.fc_q = nn.Linear(d_k_, n_head * d_k)self.fc_k = nn.Linear(d_k_, n_head * d_k)self.fc_v = nn.Linear(d_v_, n_head * d_v)self.attention = ScaledDotProductAttention(scale=np.power(d_k, 0.5))self.fc_o = nn.Linear(n_head * d_v, d_o)def forward(self, q, k, v, mask=None):n_head, d_q, d_k, d_v = self.n_head, self.d_k, self.d_k, self.d_vbatch, n_q, d_q_ = q.size()batch, n_k, d_k_ = k.size()batch, n_v, d_v_ = v.size()q = self.fc_q(q) # 1.单头变多头k = self.fc_k(k)v = self.fc_v(v)q = q.view(batch, n_q, n_head, d_q).permute(2, 0, 1, 3).contiguous().view(-1, n_q, d_q)k = k.view(batch, n_k, n_head, d_k).permute(2, 0, 1, 3).contiguous().view(-1, n_k, d_k)v = v.view(batch, n_v, n_head, d_v).permute(2, 0, 1, 3).contiguous().view(-1, n_v, d_v)if mask is not None:mask = mask.repeat(n_head, 1, 1)attn, output = self.attention(q, k, v, mask=mask) # 2.当成单头注意力求输出output = output.view(n_head, batch, n_q, d_v).permute(1, 2, 0, 3).contiguous().view(batch, n_q, -1) # 3.Concatoutput = self.fc_o(output) # 4.仿射变换得到最终输出return attn, outputif __name__ == "__main__":n_q, n_k, n_v = 2, 4, 4d_q_, d_k_, d_v_ = 128, 128, 64q = torch.randn(batch, n_q, d_q_)k = torch.randn(batch, n_k, d_k_)v = torch.randn(batch, n_v, d_v_) mask = torch.zeros(batch, n_q, n_k).bool()mha = MultiHeadAttention(n_head=8, d_k_=128, d_v_=64, d_k=256, d_v=128, d_o=128)attn, output = mha(q, k, v, mask=mask)print(attn.size())print(output.size())
soft attention 与 hard attention
Soft attention, NLP中尝试用的注意力方式,取值为[0, 1]的权重概率分布,使用了所有编码层的隐层状态,与上两节的介绍相同,可以直接在模型训练过程中,通过后向传播优化对参数进行优化。
Hard attention, Hard attention 在原文中被称为随机硬注意力(Stochastic hard attention),这里的随机是指对编码层隐状体的采样过程,Hard attention 没有使用到所有的隐层状态,而是使用one-hot的形式对某个区域提取信息,使用这种方式无法直接进行后向传播(梯度计算),需要蒙特卡洛采样的方法来估计梯度。就好比python中的简单字典取值
相对位置编码 与 绝对位置编码
缩放因子
Transfomer中使用到的缩放点积注意力, 是点积计算的延申,增加了一个缩放因子。
在论文中我们注意到作者在做了 QK^T 时还除以一个sqrt(d_k),d_k为dim的维度,作者给出的解释如:
We suspect that for large values of d_k , the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients. To counteract this effect, we scale the dot products by d_k .
梯度消失问题:神经网络的权重与损失的梯度成比例地更新。问题是,在某些情况下,梯度会很小,有效地阻止了权重更新。简单来说就是这样可以优化结果
Unnormalized softmax:考虑一个正态分布。分布的 softmax 值在很大程度上取决于它的标准差。由于标准偏差很大,softmax 只存在一个峰值,其他全部几乎为0。
我们在注意力中做了一个softmax,假定说当前的数据分布方差较大,那么除了某几个位置是1,其它位置可能都接近0,而那些接近0的位置这样计算过后,在梯度反向传播时,我们只能获得一个很小的更新,不利于网络进行学习,所以我们应该降低整个分布的方差,这样可以让网络进行更好的训练。