DSM-GANs:为不同的域(照片和绘画风格)创建特定的映射函数,以改善风格转换的质量和准确性
- 提出背景
- DSM-GANs = 域特定映射 + 域特定内容空间 + 针对性损失函数设计
- 模型如何进行风格转换和图像到图像翻译
提出背景
论文:http://xxx.itp.ac.cn/pdf/2008.02198v1
代码:https://acht7111020.github.io/DSMAP-demo/
如果你对图像处理是新手,那么理解风格转换和图像到图像翻译的概念可能会感到有些复杂。但别担心,我会尽量用简单的语言来解释这些概念和相关工作的来龙去脉。
风格转换:艺术的数字化魔法
首先,想象一下你能够拿一张普通的照片,用一位著名画家的风格重新绘制它——比如,把你的自拍照变成梵高或毕加索的作品。
这就是风格转换的魔力,它能够捕捉一幅画的风格(比如色彩、笔触)并将其应用到另一幅图像上。
从神经网络到风格迁移:一个技术演进的故事
这个过程最初是由Gatys等人通过深度学习——特别是卷积神经网络(CNNs)——发现的。
他们展示了CNNs可以从一幅画中提取风格,并通过迭代优化的方法将这种风格应用到其他图像上。
这听起来很酷,但问题是这个方法计算量很大,就像你要画一幅画,但每一笔都要重新思考一次,非常耗时。
研究进展:加速和普及
为了加快这个过程,研究者们提出了使用前馈网络——这是一种可以一次性完成计算的快速网络。
还有一些技术,比如自适应实例规范化(AdaIN)和白化着色转换(WCT),它们通过调整图像特征的统计属性来实现风格转移,这些都是为了更快地、更通用地实现风格转换。
超越风格:语义风格转换
但是,如果你想做更复杂的事情呢?
比如,把一只猫的图像转换成一只狗,并且保持它们各自的特征?
这就需要所谓的语义风格转换。
一些研究者尝试使用语义分割图——这是图像中每个部分的详细地图——来辅助这个过程。
不过,这种方法依赖于这些分割图的质量,如果匹配得不好,效果也会不好。
图像到图像翻译:从一种视角到另一种视角
这里涉及到另一个相关领域:图像到图像翻译。
这基本上是说,我们怎样才能将一个图像领域(比如照片)中的图像转换到另一个领域(比如油画)。
这方面有许多研究,例如Pix2Pix和CycleGAN,它们通过学习源域和目标域之间的映射关系来实现转换。
一些方法甚至可以处理未配对的图像,这就像是你有一本法语到英语的词典,但你要翻译的是一本德语书。
我们的创新:域特定映射
我们的论文基于一个新颖的观点:风格和内容都有它们自己的“域”,或者说特定的特性。
我们提出了一种方法,可以在这些域之间更精确地映射图像。
这就像我们发明了一个通用的翻译器,无论你给它什么样的语言,它都能准确地转换。
这种方法比之前的技术更灵活,能处理更复杂的风格和内容转换——即使是将猫变成狗这样的任务。
简化技术,提高性能
在技术上,我们的方法更像是两步走的策略。
首先,我们有了一种特殊的技术,可以将图像的内容特征映射到一个新的空间——这个空间专门为目标风格(比如梵高的画风)量身定做。
接着,我们用一种称为损失函数的工具来微调这个过程,确保最终的图像既保留了原图的内容,又拥有了新风格的特色。
结论:打破边界,创造可能
这项技术的美妙之处在于它打破了传统的限制,使得风格转换不再受限于特定的样式或内容。
我们可以更自由地创造出新的艺术作品,或者将这项技术应用到设计和娱乐产业中。
虽然这听起来可能有些高深莫测,但其实它就像是数字世界的翻译器,将一种视觉语言转换成另一种,为我们打开了全新的视觉表达之门。
假设我们有两个图像:一个是一幅风景画(内容图像xA),另一个是梵高的星夜(风格图像xB)。
我们的目标是将星夜的风格应用到风景画上,生成一个新的图像,这个图像保留了风景画的内容布局和空间排列,同时具有星夜的颜色、色调、纹理和图案。
在传统的风格转换方法中,可能会遇到一个问题,即风格图像和内容图像虽然可以共享一个域不变的内容空间,但这种做法可能会限制对内容的精细表达。
尤其是在需要精确对应特定语义元素的场景中,比如将风景画中的树木准确地以星夜的风格表现,传统方法可能会因为域不变内容空间的限制而难以实现细腻的风格迁移。
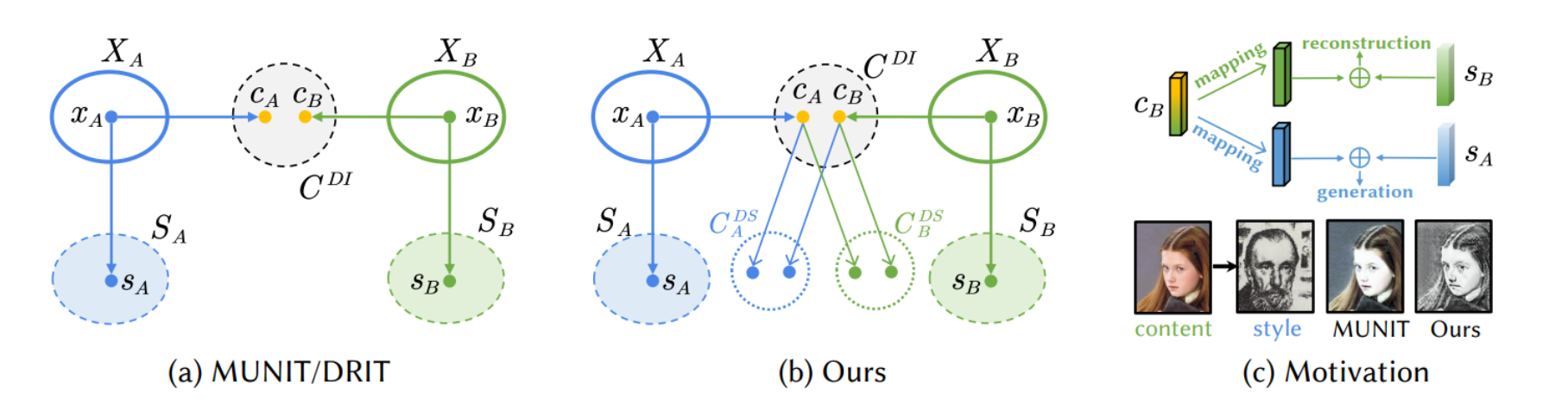
(a) MUNIT/DRIT方法:
- 这部分显示了传统的图像到图像(I2I)翻译方法,其中包括MUNIT和DRIT。
- 这些方法将图像分解为共享的域不变内容特征(C_DI)和域特定风格特征(S_A和S_B)。
- 在这些方法中,内容特征被假设为域不变的,这意味着不同图像域(例如,风格A和风格B)的内容特征会映射到相同的空间,而风格特征则是域特定的。
- 这可能限制了内容表示的能力,因为它没有考虑到内容和风格之间的关系。
(b) 该论文提出的方法(Ours):
- 论文作者提出了一种新的方法,通过找到映射函数将共享的域不变内容特征空间(C_DI)中的内容特征映射到每个域的域特定内容空间(C_DS_A和C_DS_B)。
- 这种重新映射的内容特征可以更好地与目标域的特征对齐,从而更好地捕捉目标域的特征。
- 这个过程通过两个映射函数实现,分别是ΦC→CA和ΦC→CB,它们将内容特征从共享空间映射到特定域的空间。
© 动机(Motivation):
- 右侧展示了一系列图像,以说明为什么需要这样的方法。
- 从左到右,图像展示了原始的内容图像、风格图像、使用MUNIT方法得到的风格转换结果,以及使用论文作者提出的方法得到的结果。
- 可以看到,作者的方法在风格转换上产生了更符合目标风格的结果,特别是在内容和风格匹配方面。
DSM-GANs = 域特定映射 + 域特定内容空间 + 针对性损失函数设计
结构图:
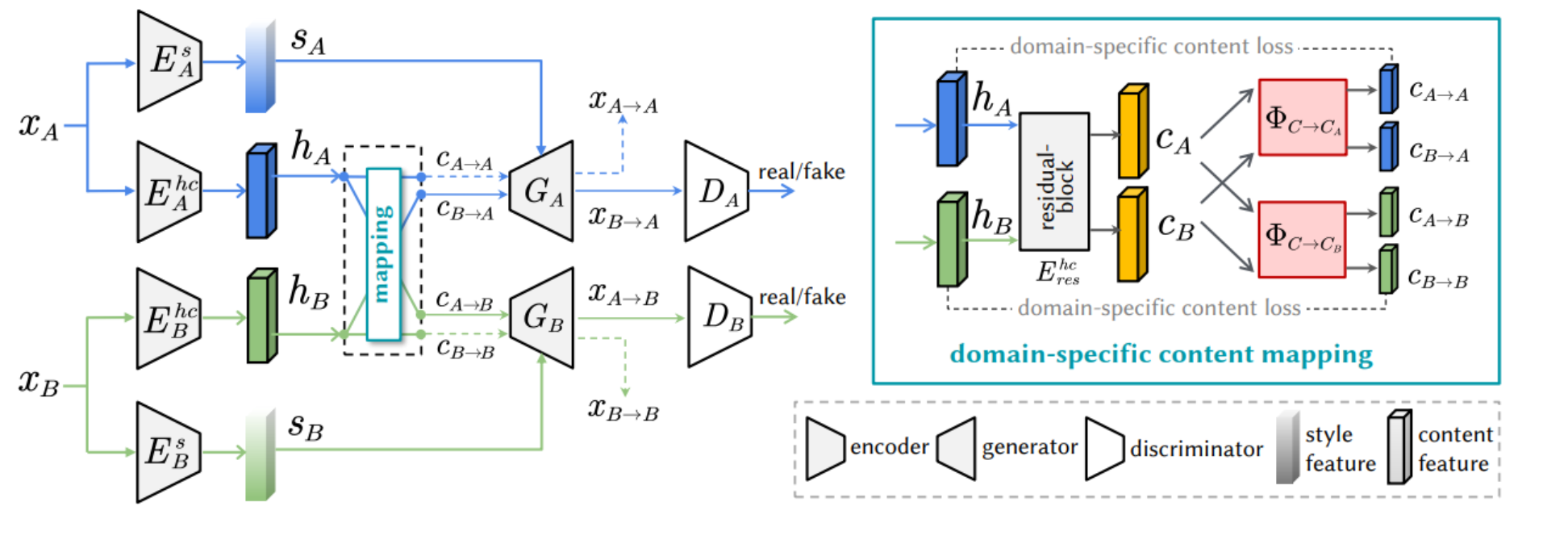
图3描述了论文提出方法的框架。这个框架使用域特定映射来改善跨域翻译的内容特征保持,它包括以下几个主要部分:
- 内容编码器 (
Ec_A,Ec_B):将源域图像 (xA,xB) 编码为内容特征 (hA,hB)。 - 风格编码器 (
Es_A,Es_B):从源域图像中提取风格特征 (sA,sB)。 - 生成器 (
GA,GB):使用内容特征和风格特征来生成新的图像 (xA→A,xB→B)。 - 判别器 (
DA,DB):判断生成的图像是否真实。 - 域特定内容映射:通过映射函数 (
ΦC→CA,ΦC→CB) 将内容特征从域不变内容空间映射到域特定内容空间。 - 域特定内容损失:确保映射后的内容特征与源域特征相似,促进学习过程。
顶部右侧的小框中展示了域特定内容映射的细节,包括如何使用这些映射函数来将内容特征 (CA, CB) 映射到目标域,以及如何通过最小化域特定内容损失来训练这些映射函数。
你想要做一道菜,这道菜来自意大利的经典菜肴——比萨饼(内容图像xA),但你想要给它加上墨西哥的塔可(风格图像xB)的风味。
你的挑战是要保持比萨的基本结构不变,同时引入塔可的辣味和风味。
-
域特定映射(Domain-Specific Mapping)
- 子特征1:这就像我们找到了一种特殊的调味方法,可以把比萨的基础(比如面饼、奶酪、番茄酱)保留下来,同时加入塔可的风味(比如辣椒、香菜、鳄梨酱)。这种调味方法要足够灵活,能让比萨适应塔可的风味,但又不失去它作为比萨的本质。
- 原因:我们需要一个能够保留比萨结构同时融入塔可风味的调味技巧,域特定映射就像是这样的一种调味技巧。
-
域特定内容空间(Domain-Specific Content Spaces)
- 子特征2:这就像我们为这种比萨-塔可混合菜创造了一个全新的烹饪空间,这个空间是为了这种特殊的风味混合而设计的。在这个空间里,比萨的基本元素被调整得可以自然地与塔可的风味结合。
- 原因:就像在厨房里调整食材搭配和烹饪方法一样,域特定内容空间允许我们精确地调整比萨,使其能够更好地融合塔可的风格。
-
针对性损失函数设计(Targeted Loss Function Design)
- 子特征3:这就像我们有一本烹饪指南,告诉我们如何评价这道菜肴是否成功地结合了两种风味。如果比萨太像塔可,就失去了它的本质;如果塔可的风味不够,又达不到我们想要的效果。这本指南帮助我们找到完美的平衡点。
- 原因:这本烹饪指南就像是我们的损失函数,确保我们不会在融合风格的过程中失去内容的精髓,同时也保证风格的引入是恰到好处的。
这篇论文提出的方法就像是烹饪中创新的调味技巧和烹饪空间的设计,以及烹饪指南的使用,这三者结合起来,让我们能够制作出既保持了原本比萨的基本结构,又有着塔可风味的全新菜肴。
模型如何进行风格转换和图像到图像翻译
-
问题:如何在两个图像域之间转换风格?
- 解法:双向映射函数ΦXA→XB 和 ΦXB→XA
- 为什么: 为了实现从域XA到XB以及从XB到XA的图像风格转换,需要两个映射函数来实现双向转换。
-
问题:如何提升风格转换的质量?
- 解法:域特定内容映射函数ΦC→CA 和 ΦC→CB
- 为什么: 传统方法可能无法在目标域中很好地表示域不变的内容特征。通过映射到域特定内容空间,可以更好地与目标风格对齐。
-
问题:如何学习域特定内容映射?
- 解法:通过内容编码器组件EcA 和 EcB的设计,并通过损失函数优化
- 为什么: 内容编码器可以将图像编码到共享的域不变内容空间中。通过优化损失函数,可以使映射函数学习到如何将内容特征转换到域特定的内容空间。
-
问题:如何确保风格编码器编码有意义的风格特征?
- 解法:风格重建损失
- 为什么: 通过这个损失函数,可以训练风格编码器以确保它们能够捕获有效的风格特征,以便在风格转换中使用。
-
问题:如何进行有效的图像到图像翻译?
- 解法:结合多种损失函数,包括对抗损失、图像重建损失、域不变内容重建损失和循环一致性损失
- 为什么: 这些损失函数帮助模型学习如何在不同域之间转换图像,同时保持图像内容的一致性和风格的多样性。
-
问题:如何确保跨域翻译保持域不变内容特征?
- 解法:域不变内容损失
- 为什么: 尽管使用了域特定内容特征,仍然需要域不变的内容空间来支持跨域翻译,以确保图像的基本内容在转换过程中保持不变。
-
问题:如何确保生成的图像具有多样性并且真实?
- 解法:模式搜索正则化项
- 为什么: 为了增加生成图像的多样性并使其更接近真实图像的分布,采用模式搜索正则化项可以增强模型的这一能力。
-
问题:如何进行双向训练并平衡多个损失函数?
- 解法:总损失函数的设计,结合双向的多个损失项
- 为什么: 总损失函数结合了所有单个方向上的损失,这允许模型在两个方向上进行训练,并在各种损失之间找到适当的平衡。
举个例子:
-
原料准备(双向映射函数):
- 你需要找到一种方法,把比萨饼转换成带有塔可风味的比萨,同时也能够将任何塔可风格的创意转回到传统比萨的风味。
- 这在我们的例子中对应于找到两个映射函数ΦXA→XB和ΦXB→XA,这就像是你有两本食谱,一个将意大利比萨转换成墨西哥风味,另一个将墨西哥风味转换回意大利风格。
-
调味(域特定内容映射):
- 你不能只是简单地将塔可的辣椒和香料撒在比萨上,这样做可能会让风味冲突,影响整体的口感。
- 你需要调整这些风味,让它们能够与比萨的基本成分——面团、酱料和奶酪——和谐融合。
- 在我们的技术中,这对应于使用域特定映射函数ΦC→CA和ΦC→CB,它们帮助将图像的内容特征适当地调整到目标风格域。
-
烹饪技巧(学习域特定内容映射):
- 为了让这种风味融合成功,你需要研究并掌握如何将比萨的传统做法调整为能够接纳塔可风味的新做法。
- 这就好比我们的模型需要学习如何将图像的内容特征映射到域特定的内容空间——就像大厨通过实践和尝试找到最佳的调味配比。
-
调味验证(风格重建损失):
- 当你尝试将塔可的风味融入比萨时,你需要确保这些风味是真正的墨西哥风味,而不是一个模糊的、不清晰的味道。
- 这在我们的模型中通过风格重建损失来实现,确保风格特征在转换过程中保持其特性。
-
最终呈现(图像重建损失等):
- 你想确保最终的菜品既有比萨的基本结构也有塔可的风味,所以你会反复尝试,直到找到完美的融合点。
- 这就类似于我们模型中的图像重建损失,确保生成的图像在风格上接近目标图像,同时在内容上保持原有的结构。

本文方法,在细节、真实度更好。