目录
往期精彩内容:
多变量特征序列、单序列数据预测实战
前言
1 风速数据预处理与数据集制作
1.1 导入数据
1.2 多变量数据预处理与数据集制作
1.3 单序列数据预处理与数据集制作
2超强模型XGBoost——原理介绍
3 模型评估和对比
3.1 随机森林预测模型
3.2 支持向量机SVM预测模型
3.3 XGBoost分类模型
代码、数据如下:

往期精彩内容:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较-CSDN博客
风速预测(一)数据集介绍和预处理-CSDN博客
风速预测(二)基于Pytorch的EMD-LSTM模型-CSDN博客
风速预测(三)EMD-LSTM-Attention模型-CSDN博客
风速预测(四)基于Pytorch的EMD-Transformer模型-CSDN博客
风速预测(五)基于Pytorch的EMD-CNN-LSTM模型-CSDN博客
风速预测(六)基于Pytorch的EMD-CNN-GRU并行模型-CSDN博客
CEEMDAN +组合预测模型(BiLSTM-Attention + ARIMA)-CSDN博客
CEEMDAN +组合预测模型(CNN-LSTM + ARIMA)-CSDN博客
CEEMDAN +组合预测模型(Transformer - BiLSTM+ ARIMA)-CSDN博客
CEEMDAN +组合预测模型(CNN-Transformer + ARIMA)-CSDN博客
多特征变量序列预测(一)——CNN-LSTM风速预测模型-CSDN博客
多特征变量序列预测(二)——CNN-LSTM-Attention风速预测模型-CSDN博客
多特征变量序列预测(三)——CNN-Transformer风速预测模型-CSDN博客
多特征变量序列预测(四)Transformer-BiLSTM风速预测模型-CSDN博客
多特征变量序列预测(五) CEEMDAN+CNN-LSTM风速预测模型-CSDN博客
多特征变量序列预测(六) CEEMDAN+CNN-Transformer风速预测模型-CSDN博客
多特征变量序列预测(七) CEEMDAN+Transformer-BiLSTM预测模型-CSDN博客
基于麻雀优化算法SSA的CEEMDAN-BiLSTM-Attention的预测模型-CSDN博客
基于麻雀优化算法SSA的CEEMDAN-Transformer-BiGRU预测模型-CSDN博客
多特征变量序列预测(八)基于麻雀优化算法的CEEMDAN-SSA-BiLSTM预测模型-CSDN博客
多特征变量序列预测(九)基于麻雀优化算法的CEEMDAN-SSA-BiGRU-Attention预测模型-CSDN博客
多特征变量序列预测(10)基于麻雀优化算法的CEEMDAN-SSA-Transformer-BiLSTM预测模型-CSDN博客
风速预测(七)VMD-CNN-BiLSTM预测模型-CSDN博客
多变量特征序列、单序列数据预测实战
前言
XGBoost是一种强大的机器学习算法,适用于预测任务。它通过梯度提升树的方式有效地处理复杂数据,并在许多领域中取得了令人瞩目的成果。本文基于前期介绍的风速数据(文末附数据集),利用XGBoost模型分别对多变量序列、单序列的数据进行建模,来实现精准预测。
风速数据集的详细介绍可以参考下文:
风速预测(一)数据集介绍和预处理_风速预测时序数据-CSDN博客
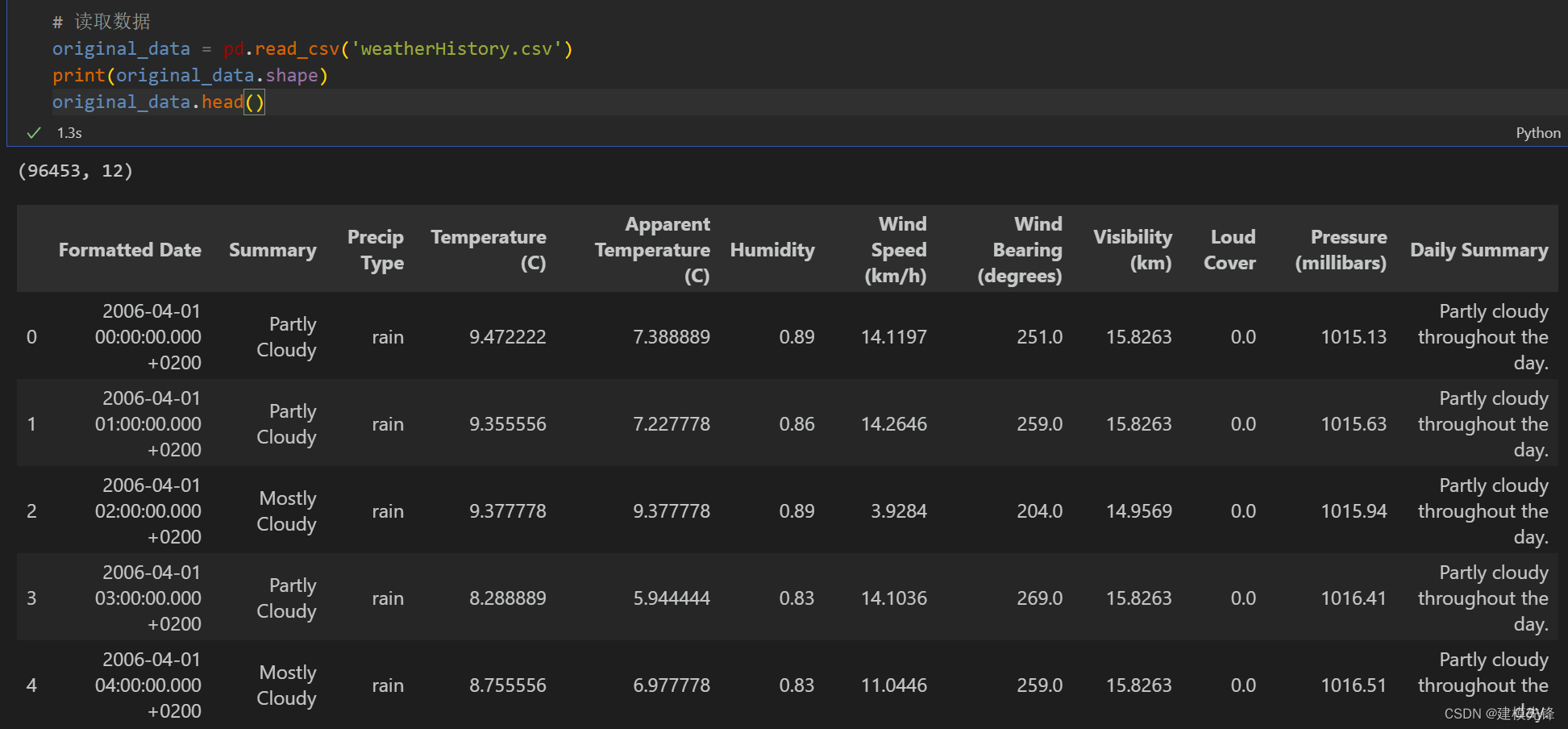
数据集一共有天气、温度、湿度、气压、风速等九个变量
我们通过对比实验来探索,在此数据集上多变量预测和单序列预测的效果
1 风速数据预处理与数据集制作
1.1 导入数据

1.2 多变量数据预处理与数据集制作
多变量数据预测 采用7个特征变量来预测风速数据
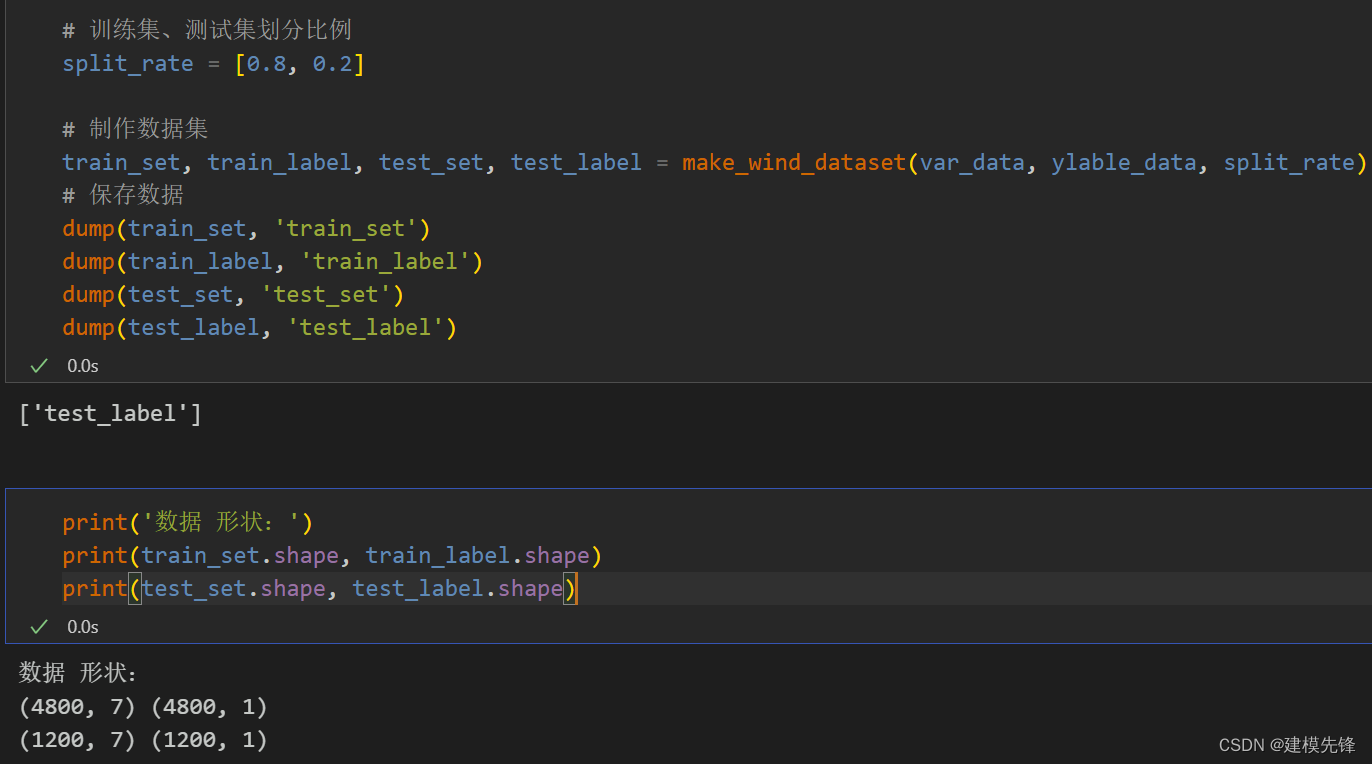
1.3 单序列数据预处理与数据集制作
仅使用风速一个变量来构建数据集和预测模型
通过滑动窗口来制作数据集

2超强模型XGBoost——原理介绍
论文链接:
XGBoost | Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
GBoost模型(eXtreme Gradient Boosting)是一种梯度提升框架,由Tianqi Chen在2014年开发,并在机器学习领域广泛应用。XGBoost的核心思想是通过迭代地训练多个弱学习器,并将它们组合起来,实现强大的预测能力。它在梯度提升算法的基础上进行了改进和优化,具有高效、灵活和可扩展的特点。
下面是XGBoost的一些关键特性和原理:
1. 梯度提升:XGBoost使用了梯度提升算法,也称为增强学习(Boosting)算法。它通过迭代地训练多个弱学习器,并通过梯度下降的方式来优化模型的预测能力。每个弱学习器都是在前一个弱学习器的残差上进行训练,从而逐步减小预测误差。
2. 基于树的模型:XGBoost采用了基于树的模型,即决策树。决策树是一种非常灵活和可解释的模型,能够学习到复杂的非线性关系。XGBoost使用了CART(Classification and Regression Trees)作为默认的基学习器,每个决策树都是通过不断划分特征空间来实现分类或回归任务。
3. 正则化策略:为了防止过拟合,XGBoost引入了正则化策略。它通过控制决策树的复杂度来限制模型的学习能力。常用的正则化策略包括限制决策树的最大深度、叶子节点的最小样本数和叶子节点的权重衰减等。
4. 特征选择和分裂:XGBoost在构建决策树时,通过特征选择和分裂来最大化模型的增益。特征选择基于某种评估准则(如信息增益或基尼系数),选择对当前节点的划分最有利的特征。特征分裂则是确定特征划分点的过程,使得划分后的子节点能够最大程度地减小预测误差。
5. 并行计算:为了提高模型的训练速度,XGBoost使用了并行计算的策略。它通过多线程和分布式计算等技术,将训练任务分解为多个子任务,并在不同的处理器上同时进行计算。这样可以加快模型的训练速度,特别是在处理大规模数据集时表现优异。
6. 自定义损失函数:XGBoost允许用户自定义损失函数,以适应不同的任务和需求。用户可以根据具体问题的特点,定义适合的损失函数,并在模型训练过程中使用它。
XGBoost模型通过梯度提升算法和基于树的模型,在许多机器学习任务中都取得了很好的效果,包括分类、回归、排序和推荐等。我们利用其高效、灵活和可扩展的特性,使用XGBoost来构建一个梯度提升模型,通过迭代地训练多个决策树来实现风速数据的精准预测。
3 模型评估和对比
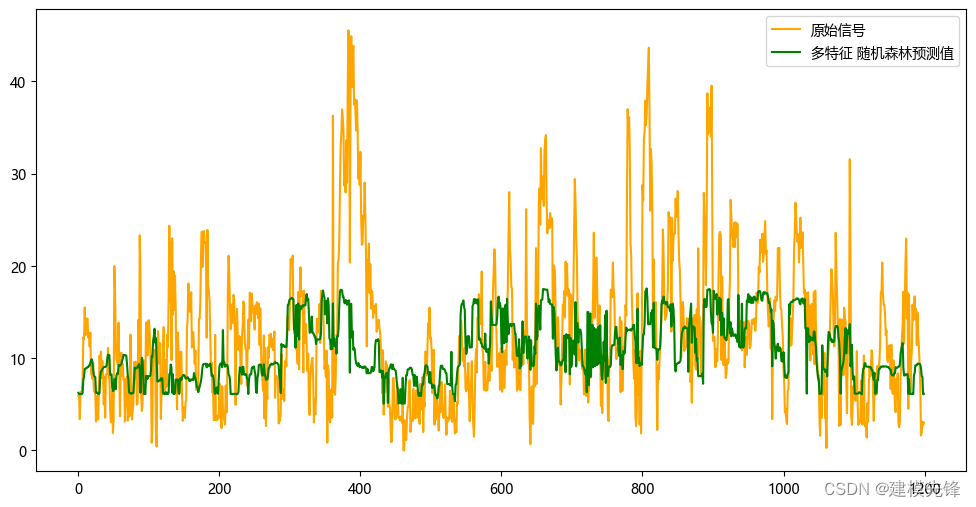
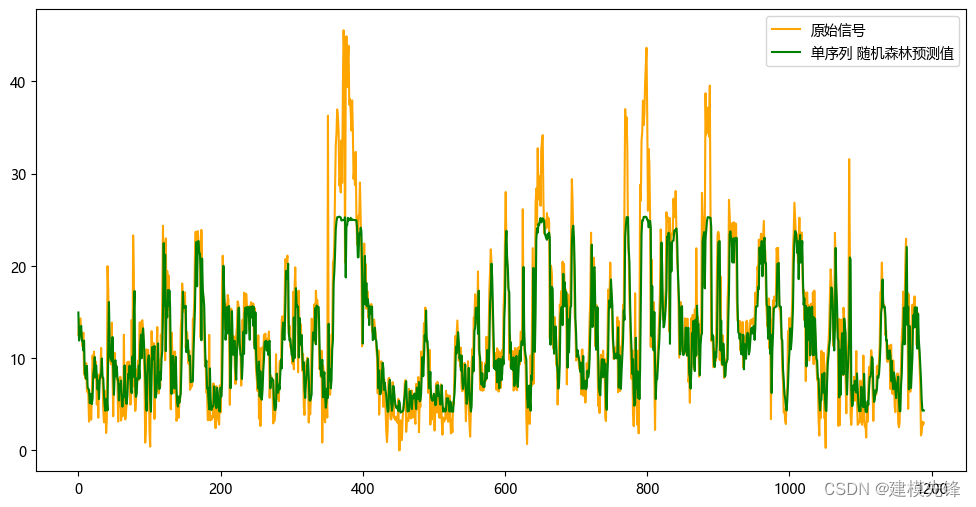
3.1 随机森林预测模型
多特征变量预测
单序列预测
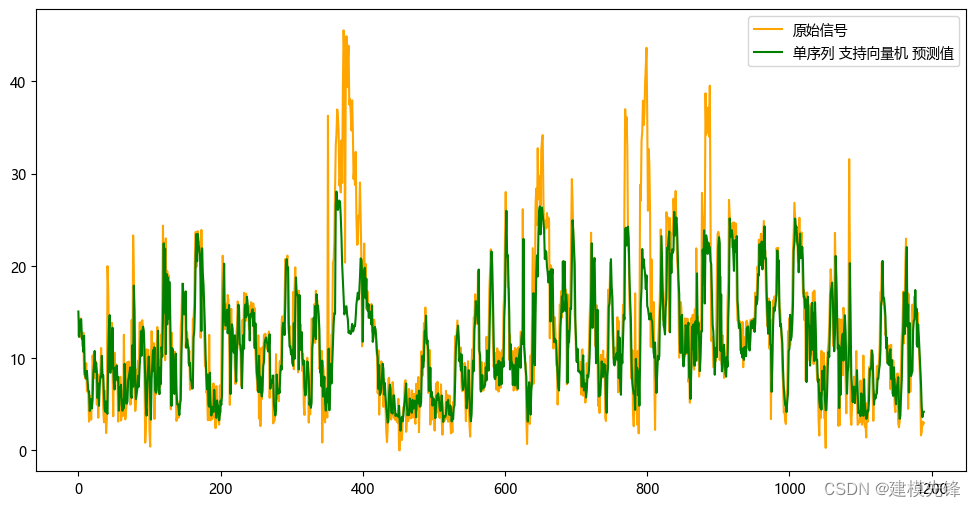
3.2 支持向量机SVM预测模型
多特征变量预测

单序列预测
3.3 XGBoost分类模型
多特征变量预测

单序列预测

模型评估
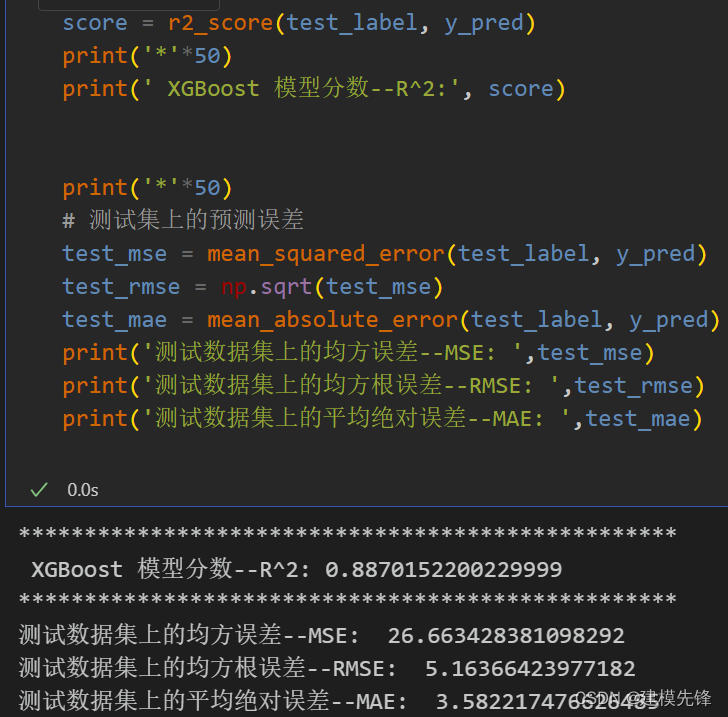
对比随机森林、SVM模型可以看出来, XGBoost预测模型性能最好,在训练集、测试集上的表现最优,模型分数也是最高,在此数据集上,单序列预测取得了良好的效果。XGBoost预测模型速度快,性能好,适当调整模型参数,还可以进一步提高模型预测表现。
代码、数据如下: