第1章:引言
在数据驱动的时代,咱们处理的不仅仅是数字和文本,还有复杂的关系和网络。想象一下社交网络中人与人之间错综复杂的联系,或者是互联网上网页之间的链接关系,传统的表格数据库已经难以高效地处理这些关系密集型的数据了。这时候,图数据库就登场了,它以图的形式存储数据,节点代表实体,边代表实体之间的关系,非常适合处理复杂的网络关系。
那为什么咱们要选择Neo4j作为图数据库的代表来深入学习呢?首先,Neo4j是目前最流行的图数据库之一,它提供了非常直观的图形化界面和强大的查询语言Cypher,让管理和查询图数据变得简单直观。更重要的是,Neo4j具有非常好的性能表现,即便是在处理大规模数据时也能保持高效的查询速度。对于Java程序员来说,Neo4j提供了良好的Java API支持,让咱们可以轻松地在Java应用中集成和使用Neo4j。
第2章:Neo4j基础
要理解Neo4j,咱们得先搞清楚几个核心概念:节点(Node)、关系(Relationship)、属性(Property)和标签(Label)。节点可以理解为图中的一个个实体,比如人、地点或事物。每个节点都可以有多个标签,用于分类或标记。关系则描述了节点之间的联系,每个关系都有方向,指从一个节点指向另一个节点,并且关系本身也可以有属性。属性则是节点或关系的详细信息,比如人的姓名、地点的名称等。
接下来,让咱们用一个简单的例子来看看Neo4j是如何工作的。假设咱们要在Neo4j中建立一个表示朋友关系的小网络。在这个网络中,每个人都是一个节点,人与人之间的朋友关系则是边。
// 连接到Neo4j数据库
Driver driver = GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("用户名", "密码"));
try (Session session = driver.session()) {// 创建节点String createNodeQuery = "CREATE (a:Person {name: '小明'}) RETURN a";session.run(createNodeQuery);// 创建另一个节点,并建立朋友关系String createAnotherNodeAndRelationQuery = "CREATE (b:Person {name: '小红'})-[:FRIEND]->(a:Person {name: '小明'}) RETURN b";session.run(createAnotherNodeAndRelationQuery);
}
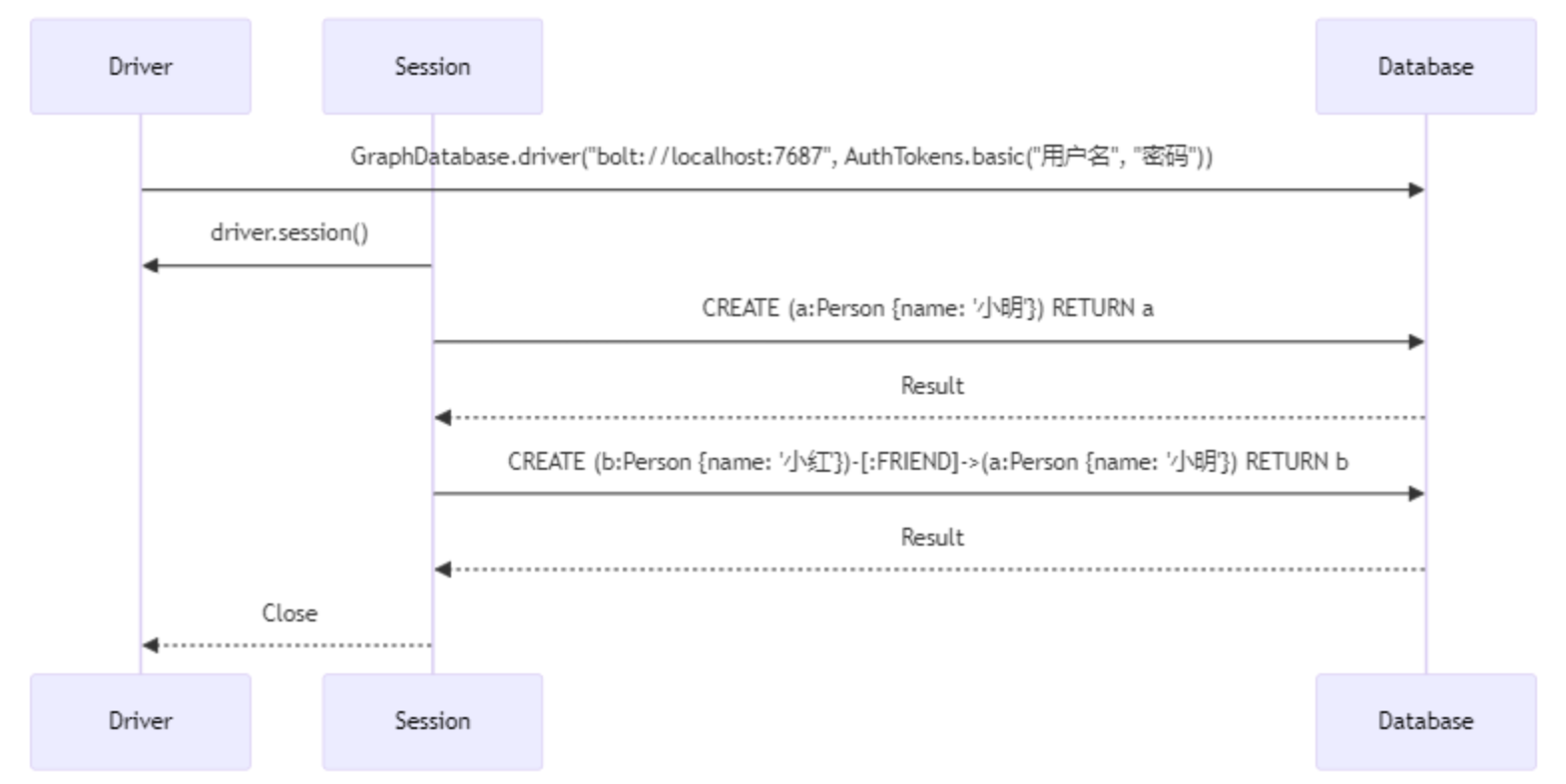
在这个例子中,咱们首先创建了两个标签为Person的节点,分别代表“小明”和“小红”,然后通过:FRIEND关系将它们连接起来。这段代码虽然简单,但已经涵盖了Neo4j操作的核心:节点的创建、关系的建立以及属性的赋值。
通过这个例子,咱们可以看出,Neo4j使得图数据的表示和查询变得直观而简单。无论是社交网络、推荐系统还是复杂的网络分析,Neo4j都能提供强大的支持。而且,对于习惯了Java开发的小黑来说,通过Neo4j提供的Java API,将这些功能整合到自己的应用中只是手到擒来的事情。
小黑偷偷告诉你一个生财信息差网站: 小黑的生财资料站
第3章:安装与配置Neo4j
咱们要开始动手实践了,第一步自然是将Neo4j安装到咱们的机器上。不管你是用Windows, Linux还是Mac,Neo4j的安装过程都设计得非常友好,接下来就一起看看怎么在这些操作系统上搞定它。
在Windows上安装Neo4j
对于Windows用户来说,咱们可以直接从Neo4j官网下载Neo4j的Windows版安装包。下载完成后,双击安装文件,跟着安装向导走就行。安装向导会提示咱们设置数据库的存储路径、HTTP和Bolt端口等,通常情况下,保持默认设置即可。安装完成后,咱们可以通过Neo4j Desktop应用来管理Neo4j数据库,非常方便。
在Linux上安装Neo4j
Linux用户可能更倾向于使用命令行,所以咱们可以通过包管理器来安装Neo4j。以Ubuntu为例,咱们可以先添加Neo4j的仓库,然后使用apt-get命令安装:
wget -O - https://debian.neo4j.com/neotechnology.gpg.key | sudo apt-key add -
echo 'deb https://debian.neo4j.com stable 4.x' | sudo tee -a /etc/apt/sources.list.d/neo4j.list
sudo apt-get update
sudo apt-get install neo4j
安装完成后,咱们可以使用sudo service neo4j start命令来启动Neo4j服务。
在Mac上安装Neo4j
Mac用户可以通过Homebrew来安装Neo4j,这是Mac下非常流行的包管理器。打开终端,输入以下命令即可安装:
brew install neo4j
安装完成后,使用neo4j start命令来启动Neo4j服务。
基本配置介绍
不管是哪个操作系统,安装完成后咱们都需要进行一些基本的配置。最重要的就是关于安全性的配置,特别是设置数据库的用户名和密码。Neo4j在首次启动时会要求设置这些信息,确保你的数据库不会被未授权的人访问。
此外,还可以通过修改conf/neo4j.conf文件来进行更多高级配置,比如调整内存设置、配置日志文件的位置等。对于大多数初学者来说,刚开始使用默认配置就已经足够了。随着咱们对Neo4j的了解加深,再根据实际需要进行相应的调整。
安装并配置好Neo4j之后,咱们就可以开始探索图数据库的强大功能了。通过Neo4j Browser,咱们可以直观地查看数据库中的数据,执行Cypher查询语句,以及进行数据库的管理工作,非常直观和方便。
到这里,咱们已经成功搭建了自己的Neo4j环境,接下来就可以开始真正的图数据库之旅了。通过上述步骤,无论是在Windows、Linux还是Mac上,咱们都能轻松地安装和配置Neo4j,为后续的学习和实践打下坚实的基础。
第4章:Cypher查询语言入门
跟着小黑一起,咱们现在进入Neo4j的心脏地带——Cypher查询语言。Cypher是Neo4j专门为图数据查询和操作设计的语言,它的语法非常直观,让咱们能够轻松地描述和处理图中的数据。没有Cypher,咱们要操作图数据就像是盲人摸象,所以掌握它对于使用Neo4j来说至关重要。
Cypher语言的基本结构
Cypher的设计哲学是让查询语句尽可能地贴近自然语言。咱们来看一个简单的例子,查询名叫“小明”的人的朋友:
MATCH (a:Person {name: "小明"})-[:FRIEND]->(b)
RETURN b
这段查询的含义是:“找到一个名叫‘小明’的人a,然后找到所有a通过FRIEND关系指向的朋友b,最后返回这些朋友b的信息。”在这里,MATCH和RETURN是Cypher语句中最常用的两个关键字,分别用于匹配图中的模式和返回结果。
常用查询、插入、更新和删除操作
- 查询(Querying)
查询是最常见的操作,上面的例子就是一个查询操作。再看一个例子,咱们如何找到所有人的朋友?
MATCH (a:Person)-[:FRIEND]->(b)
RETURN a, b
这个查询会返回所有具有FRIEND关系的人的组合。
- 插入(Creating)
插入新的节点和关系也很简单。比如,咱们想在图中添加一个新的人“小红”:
CREATE (a:Person {name: "小红"})
如果咱们还想添加一个“小红”和“小明”之间的朋友关系,可以这样写:
MATCH (a:Person {name: "小明"}), (b:Person {name: "小红"})
CREATE (a)-[:FRIEND]->(b)
- 更新(Updating)
更新数据也是咱们常常需要做的操作,比如修改“小明”的名字为“大明”:
MATCH (a:Person {name: "小明"})
SET a.name = "大明"
- 删除(Deleting)
最后,如果需要删除某个节点或关系,可以使用DELETE关键字。但要注意,如果要删除一个节点,需要先删除与之相关的所有关系。比如,删除“小红”及其所有朋友关系:
MATCH (a:Person {name: "小红"})-[r]-()
DELETE r, a
通过上述示例,咱们可以看到Cypher查询语言的强大之处,它使得图数据的查询和操作变得简单直观。对于Java程序员来说,掌握Cypher是使用Neo4j的关键,只有熟练运用Cypher,才能在图数据的海洋中自如航行。随着实践的深入,咱们会发现更多Cypher的高级特性,这将大大提升咱们处理图数据的能力。
第5章:Neo4j与Java的集成
走到这一步,咱们已经对Neo4j有了基本的了解,也学会了使用Cypher语言进行数据的查询和操作。现在,小黑要带咱们探索如何在Java应用中集成和使用Neo4j,让咱们的Java应用能够直接操作图数据库,实现更复杂的业务逻辑。
使用Neo4j Java驱动程序
要在Java应用中使用Neo4j,首先得通过添加Neo4j Java驱动的依赖来开始。如果咱们使用Maven构建项目,只需要在pom.xml文件中添加如下依赖:
<dependency><groupId>org.neo4j.driver</groupId><artifactId>neo4j-java-driver</artifactId><version>4.x.x</version>
</dependency>
请确保将4.x.x替换为当前最新的稳定版本。
配置Java项目以连接Neo4j数据库
有了驱动,下一步就是配置咱们的Java应用,让它能够连接到Neo4j数据库。这里,小黑给大家展示一个简单的例子,如何在Java中创建一个Neo4j的连接并执行一个简单的Cypher查询。
import org.neo4j.driver.AuthTokens;
import org.neo4j.driver.Driver;
import org.neo4j.driver.GraphDatabase;
import org.neo4j.driver.Session;public class Neo4jExample {public static void main(String[] args) {// 连接到Neo4j数据库Driver driver = GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("用户名", "密码"));try (Session session = driver.session()) {// 执行一个Cypher查询String cypherQuery = "MATCH (n:Person) RETURN n.name AS name";session.run(cypherQuery).list(record -> record.get("name").asString()).forEach(System.out::println);} finally {driver.close();}}
}
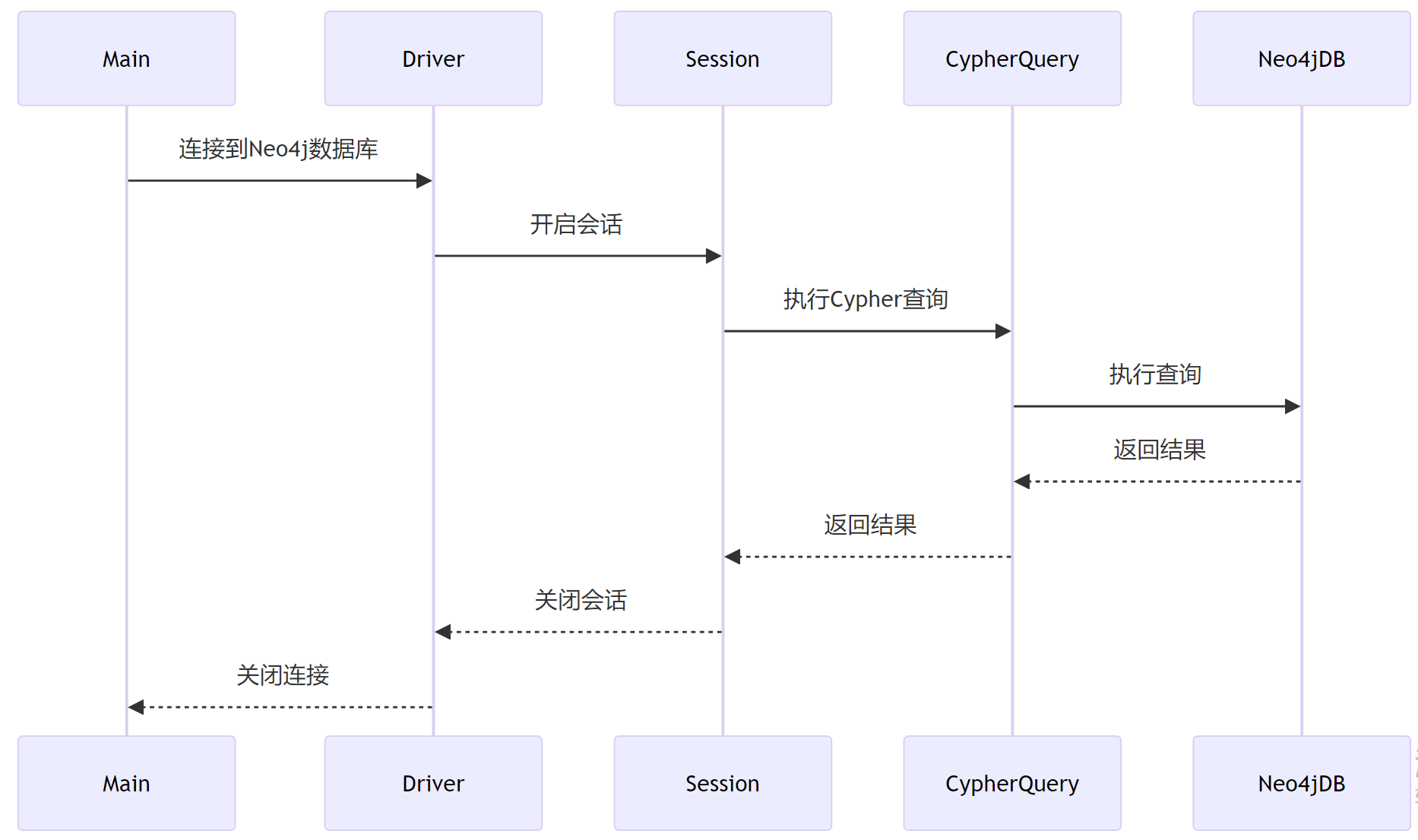
在这段代码中,咱们首先创建了一个Driver对象,用于管理与Neo4j数据库的连接。Driver对象需要咱们提供数据库的URL、用户名和密码。接下来,使用try-with-resources语句来确保会话(Session)在使用完毕后能够被自动关闭。在会话中,咱们执行了一个简单的Cypher查询,这个查询会找出所有标签为Person的节点,并返回它们的名字。最后,咱们遍历查询结果,并将每个人的名字打印出来。
这个例子虽然简单,但已经包含了在Java应用中使用Neo4j进行数据库操作的基本流程。通过这种方式,咱们可以将复杂的业务逻辑和数据处理逻辑用Java实现,而数据存储和关系处理则交给Neo4j来完成,这样既能发挥Java在业务处理上的强大能力,也能利用Neo4j在图数据管理上的优势,是一种非常理想的解决方案。
随着对Neo4j的深入使用,咱们会发现还有更多高级特性和最佳实践等着咱们去探索,比如事务管理、异步查询等。但通过这个基础的入门,咱们已经能够开始在Java应用中集成和使用Neo4j了,这为咱们打开了一个全新的图数据世界的大门。
第6章:实战:构建一个简单的Java应用使用Neo4j
好了,经过之前的铺垫,现在小黑要带着咱们进入更加实际的操作环节了。这一章,咱们将一起动手构建一个简单的Java应用,这个应用会使用Neo4j来存储和查询数据。通过这个实战案例,咱们能够更深刻地理解如何在实际项目中应用Neo4j。
设计一个简单的图模型
首先,咱们需要设计一个图模型。假设咱们要构建一个社交网络应用,核心功能是用户可以添加朋友。在这个应用中,每个用户都是一个节点,用户之间的朋友关系则通过边来表示。
在Neo4j中,咱们可以这样定义用户节点和朋友关系:
- 用户节点:标签为
Person,属性包含name(姓名)。 - 朋友关系:类型为
FRIEND,可以添加属性如since(成为朋友的时间)。
编写CRUD操作的示例代码
接下来,小黑会展示如何在Java中实现基本的CRUD(创建、读取、更新、删除)操作。
- 创建用户和朋友关系
import org.neo4j.driver.*;public class SocialNetworkApp {private final Driver driver;public SocialNetworkApp(String uri, String user, String password) {driver = GraphDatabase.driver(uri, AuthTokens.basic(user, password));}public void addFriend(String personName1, String personName2, String since) {try (Session session = driver.session()) {String query = "MERGE (p1:Person {name: $name1}) " +"MERGE (p2:Person {name: $name2}) " +"MERGE (p1)-[:FRIEND {since: $since}]->(p2)";session.run(query, Parameters.parameters("name1", personName1, "name2", personName2, "since", since));}}public static void main(String[] args) {SocialNetworkApp app = new SocialNetworkApp("bolt://localhost:7687", "用户名", "密码");app.addFriend("小明", "小红", "2023-01-01");}
}
在这个例子中,addFriend方法用于在数据库中添加两个用户节点,并创建它们之间的FRIEND关系。这里使用了MERGE关键字,它会检查相应的节点和关系是否存在,如果不存在,则创建它们;如果已存在,则不做任何操作。这避免了重复创建相同的数据。
- 查询朋友
接下来,咱们看看如何查询一个用户的所有朋友:
public void listFriends(String personName) {try (Session session = driver.session()) {String query = "MATCH (p:Person {name: $name})-[:FRIEND]->(friend) RETURN friend.name";session.run(query, Values.parameters("name", personName)).list(record -> record.get("friend.name").asString()).forEach(System.out::println);}
}
这段代码中,listFriends方法通过传入的用户名来查询该用户的所有朋友,并打印出朋友的名字。
查询优化和性能考虑
在实际应用中,查询性能是非常重要的。Neo4j提供了多种方式来优化查询性能,比如使用索引来加速查找。在大规模数据的场景下,合理的查询优化可以显著提升应用的响应速度和用户体验。
public void createIndexOnPersonName() {try (Session session = driver.session()) {String query = "CREATE INDEX ON :Person(name)";session.run(query);}
}
创建索引后,基于name属性的查询会变得更快。
到这里,咱们已经完成了一个简单的社交网络应用的核心
第7章:高级特性和最佳实践
随着小黑和咱们一步步深入Neo4j的世界,现在来到了探索其高级特性和分享一些最佳实践的时刻。理解和应用这些内容,能帮助咱们在使用Neo4j构建应用时,既能充分发挥其性能,又能保证数据的安全和稳定性。
索引和约束的使用
为了提高查询效率,使用索引是一个非常重要的策略。在Neo4j中,咱们可以为经常查询的属性创建索引,比如用户的名字。除此之外,约束也是一个有力的工具,它能保证数据库中数据的唯一性和一致性。
public void createConstraints() {try (Session session = driver.session()) {String query = "CREATE CONSTRAINT ON (p:Person) ASSERT p.name IS UNIQUE";session.run(query);}
}
这段代码创建了一个约束,确保每个Person节点的name属性是唯一的。这不仅有助于避免重复数据的产生,还能提升基于name属性的查询效率。
处理大规模数据的策略
在处理大规模数据时,咱们需要考虑数据的分片和负载均衡。虽然Neo4j是高度优化的图数据库,但在面对巨大的数据集时,合理的数据分布和查询优化仍然至关重要。使用Neo4j集群,可以实现数据的自动分片和负载均衡,从而提高应用的可伸缩性和稳定性。
安全性考虑和配置
数据的安全性是任何应用都需要考虑的问题。在使用Neo4j时,咱们应该利用其提供的安全特性,比如基于角色的访问控制(RBAC),以及使用加密连接来保护数据传输过程中的安全。
Driver driver = GraphDatabase.driver(uri, AuthTokens.basic(user, password), Config.builder().withEncryption().build());
在创建驱动程序连接时启用加密,确保数据在传输过程中的安全。
最佳实践
- 定期备份数据:定期备份数据库,以防数据丢失或损坏。
- 监控和调优:使用Neo4j提供的监控工具来观察数据库的性能指标,根据实际情况进行调优。
- 合理规划图模型:一个良好设计的图模型是高效使用Neo4j的关键。在设计图模型时,要考虑查询模式,尽量减少跨节点的查询次数,以提高性能。
- 使用参数化查询:在执行Cypher查询时,使用参数化查询可以提高性能并防止注入攻击。
通过以上的高级特性和最佳实践,咱们能够更加高效、安全地使用Neo4j来构建应用。虽然这些只是冰山一角,但已经足够咱们开始构建健壮、高效的图数据库应用。随着经验的积累,咱们会逐渐掌握更多的技巧和策略,让应用更加完善。
第8章:结语
随着小黑和咱们一起走过了Neo4j的入门到进阶,现在是时候做一个小小的总结了。从最初对图数据库的概念理解,到Neo4j的安装与配置,再到通过Cypher语言与Java驱动进行数据的增删改查,以及最后探讨的高级特性和最佳实践,咱们已经涵盖了使用Neo4j开发应用所需的基础知识和技能。
通过这一系列的学习,咱们不仅掌握了如何在Java应用中集成和使用Neo4j,还了解了如何优化查询、处理大规模数据、确保数据安全以及遵循最佳实践来提高应用的性能和稳定性。这些知识和技能将在咱们今后的开发工作中发挥重要作用,无论是构建复杂的社交网络应用、推荐系统还是其他需要处理复杂关系数据的场景。
在图数据库的世界里,Neo4j只是冰山一角,但它的强大功能和灵活性使其成为了一个非常出色的起点。随着技术的深入,咱们会发现更多高级特性和应用场景,这些都将进一步拓宽咱们的技术视野。
最后,小黑想提醒大家,技术是不断进步的,今天学到的知识可能明天就会有更新。因此,保持学习的态度,持续关注Neo4j以及图数据库领域的最新动态,是每个技术人应该做的。同时,实践是检验真理的唯一标准,不要害怕动手实验新的想法和技术,只有通过实践,才能真正掌握和深入理解Neo4j的强大能力。
在这个数据驱动的时代,图数据库无疑为咱们提供了一个强有力的工具,帮助咱们解决了许多传统数据库难以应对的问题。希望通过这篇博客,咱们能够对Neo4j有一个全面的了解,并在未来的项目中发挥它的最大价值。让咱们一起期待,在图数据的海洋中探索出更多的宝藏吧!
更多推荐
详解SpringCloud之远程方法调用神器Fegin
掌握Java Future模式及其灵活应用
小黑整的视頻会园优惠站
小黑整的生财资料站
使用Apache Commons Chain实现命令模式