一、 知识加油站
1. cpu 指令的执行过程
- 取指:cpu 获取 程序计数器 中存放的指令地址。读取内存中此地址对应指令并存入指令寄存器
- 译码:指令译码器,解析指令
- 运行:算数逻辑单元计算
- 回写:将执行结果写入对应位置
二. cpu中的技术与进化
- 最先的cpu运行时只能顺序执行指令。意思是只有一条指令从取指到回写执行完毕才可以执行下一条指令。可以明显看到cpu在“摸鱼”,整个指令周期内只有一条指令被执行。弊端在于资源浪费,指令周期内有三个步骤处于等待空闲状态;
- 然后cpu为了应对这种情况做了这样一个事来提高cpu利用率:指令流水线系统,也叫作指令预处理。顾名思义就是提前处理下一条指令,这样每个部件都可以同时并发运行,如下图:
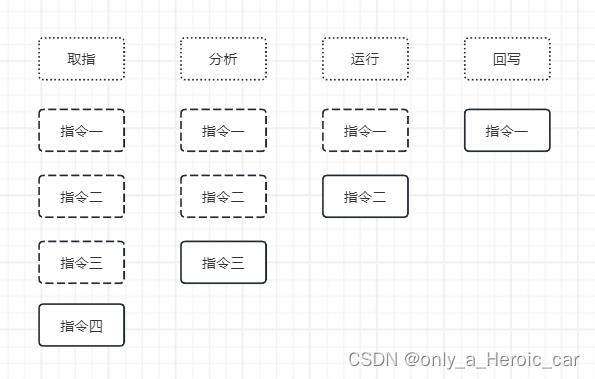
- 假如顺序执行中每个步骤耗时 1ns,那么处理100条指令需要多久?4 * 4 = 16 ns
- 假如在流水线中每个步骤耗时 1ns,那么处理4条指令需要多久?4 + (3 * 1)=7 ns
- 假如在流水线拆分更细,4个步骤变为8个步骤,每个步骤耗时 0.5ns,那么处理4条指令需要多久?4 + (3 * 0.5)= 5.5 ns
- 所以是不是意味着将流水线拆分的足够细足够多,那么就会运行的足够快呢?但实际上当拆分的足够多时反而会降低运行速度,猜猜为什么?
- 流水线拆分越深越细,需要的电路越多,同时流水线中数据传递也需要耗时,而且还会带来功耗的增加。综合这些问题反而会导致性能的下降。所以流水线的深度级数只能找一个相对的平衡点
- 使用流水线技术后,实际上并不能完全按照预期运行,因为如果同时有多个流水线模块访问内存时只能阻塞等待「结构冒险:硬件的资源竞争」;而且当一些指令依赖其他指令的结果时,也只能停下来等待「数据冒险:指令依赖其他指令的结果」;更要命的是,遇到分支的情况时并不能预测到下个分支运行哪个指令「控制冒险:流水线无法预知处于分支节点的下一条指令」。这些问题被总结为流水线中的冒险问题
- 再cpu与工艺制程的发展,运行速度也是越来越快,内存读写跟不上了。但是发现当使用某个数据时,大概率上会访问连续的空间(见下方cpp-demo)。所以cpu又搞了一块高速缓冲区「缓存」,这样就使得每条指令和数据都要从内存读取一次,变为读取一块内存数据,在需要读内存时先访问缓存,如果缓存有就直接读缓存,减少内存的访问次数。
for(int index = 0; index < 100; index++) result += data[index];
-
缓存技术又发展为指令缓存与数据缓存,一级缓存发展到二级三级缓存
-
同时在多核技术的发展下,出现多核数据不一致的问题。举例来说就是当两核同时执行i++时,本应该得到3,但是由于都从内存读到了i=1,导致两个核都计算完成并回写内存后,最终写入的是2。所以定义了一个叫原子操作的东西,表示这是不可分割的动作,谁要执行原子操作,就在总线上加LOCK#,虽然锁总线可以规避访问冲突,但是锁总线很影响其他的核心来操作内存。
-
有很多时候数据不都从内存读取,而是从缓存直接拿,因此仍然存在多核缓存数据不一致的问题。所以cpu核心之间牵入一条专线片内总线,还制定了一套规则缓存一致性协议MESI,用来同步缓存数据,具体在此不展开叙述。有了这项技术,再执行原子操作时,再也不需要锁总线了。
-
乱序执行
-
动态预测
-
并行计算
-
超线程技术
文章持续完善中