目录
前言
一、引入背景
二、OLAP引擎选型
三、架构演进
四、实时数仓构建
五、业务实践价值未来规划
原文大佬的这篇首汽约车实时数仓实践有借鉴意义,这里摘抄下来用作学习和知识沉淀。
前言
首汽约车(以下简称“首约”)是首汽集团打造的网约车出行平台。多样的用户人群、丰富的服务场景、持续升级的智能出行技术,带来业务分析需求的持续增加,分析需求复杂度的持续增加,构建一个强大统一的基础数据层势在必行。
一、引入背景
2016 年到2021年期间,基于 Hadoop、Spark、Presto 等组件,首约构建了集离线实时并行的 Lambda技术架构的大数据平台。离线计算基于Hadoop+SparkSQL 进行数仓建设,实时计算基于 Kafka+Spark Streaming 开发实时数据特征,数据落地到 MongoDB、MySQL、Redis等数据库,然后通过PrestoDB+Tableau Server 提供可视化的自助分析和交互式报表服务。
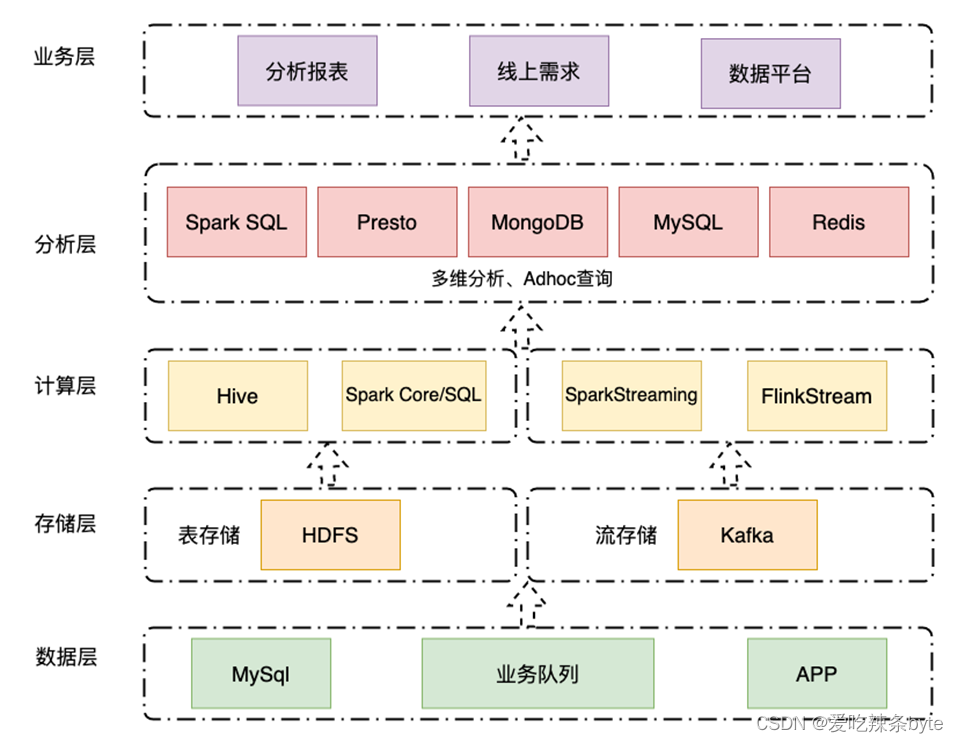
但随着数据累积和数据量的增长,加之精细化的管理运营需求,当前架构日渐吃力,业务上呈现出以下痛点:
1. 多维分析受限:从 2019 年到 2022 年初,业务数据量日增长近 10 倍,数据不断积累,分析维度不断细化,数据分析所涉及的维度越来越多。BI 层基于 Tableau Server 的多维分析报表,更新和查询效率都在变差,维度多的报表每天光刷新就需要几小时。而且基于 PrestoDB 实现的自助 SQL 查询平台并发性能较低,导致出现用户排队等待的情况,对业务方的工作效率产生了影响。
二、OLAP引擎选型
选型过程中,我们针对 StarRocks、ClickHouse、TiDB 做了一些调研和对比:
| 功能 | StarRocks | ClickHouse | TiDB、TiFlash |
| 标准 SQL | 支持标准 SQL,兼容 MySQL 协议 | 不完全支持 | 支持标准 SQL,兼容 MySQL 协议 |
| 分布式Join | 支持 | 几乎不支持分布式Join,推荐大宽表 | 支持 |
| 高并发查询 | 全面向量化引擎,提高并发查询量 | 不支持高并发,官方推荐 QPS为100 | 支持 |
| 运维 | 标准版:支持自动扩容、故障恢复,需要自己实现自动化部署,扩缩容节点、升级等,有一定开发工作 企业版:管理界面,提供集群 DashBoard、SQL Profile、监控报警等功能 | 依赖 Apache Zookeeper,运维成本 | 运维方便 |
| 社区 | 开源活跃度高,社区论坛回复快 | 开源社区发展多年,但中文社区支持较少 | 开源社区积极良好 |
| 性能 | 读写性能好 | 单机性能强悍 读性能比 StarRocks 差一些; 写性能好 | 轻量级分析良好,数据量大时性能不如 StarRocks; 写性能受限于 TiKV,一般 |
| 场景 | 纯分析场景 | 纯分析场景 | 使用HTAP 场景 |
| 其他 | 生态组件丰富 | 稳定性高 |
TiDB 适用在一些轻量级的分析场景,但对于一些数据量大、复杂查询的性能不尽人意。所以我们主要在 ClickHouse 和 StarRocks 中做选择:
在AP(分析)业务中,不同于以点查为主的TP(事务)业务 ,事实表和维度表的关联操作不可避免。但在一些灵活度要求较高的场景,比如订单的状态需要频繁改变,或者说业务人员的自助BI分析,宽表往往无法满足我们的需求,我们还需要使用更为灵活的星型或者雪花模型进行建模。
ClickHouse虽然提供了Join的的语义,但使用上对大宽表关联的能力支撑较弱,复杂的关联查询经常会引起 OOM,所以如果使用了ClickHouse,需要再ETL的过程中就将事实表与维度表打平成宽表。而StarRocks提供了Shuffle Join,Colocate Join,Broadcast Join、Bucket Shuffle Join 等多种Join模式,对于提升联表查询场景性能有着非常大的优势。
通过以上产品能力上的初步对比,我们已经比较倾向于选择 StarRocks。从使用和未来规划角度,我们继续对 StarRocks 进行了评估,双方在以下几方面具有很好的契合度:
- 1. 能够支撑 PB级别数据量,拥有灵活的建模方式,可以通过向量化引擎、物化视图、位图索引、稀疏索引等优化手段构建极速统一的分析层存储系统。
- 2.兼容 MySQL 协议,支持标准 SQL 语法,易于对接使用,全系统无外部依赖,高可用,易于运维管理。可以轻松平稳地对接多种开源或者商业BI工具,比如Tableau、FineBI。
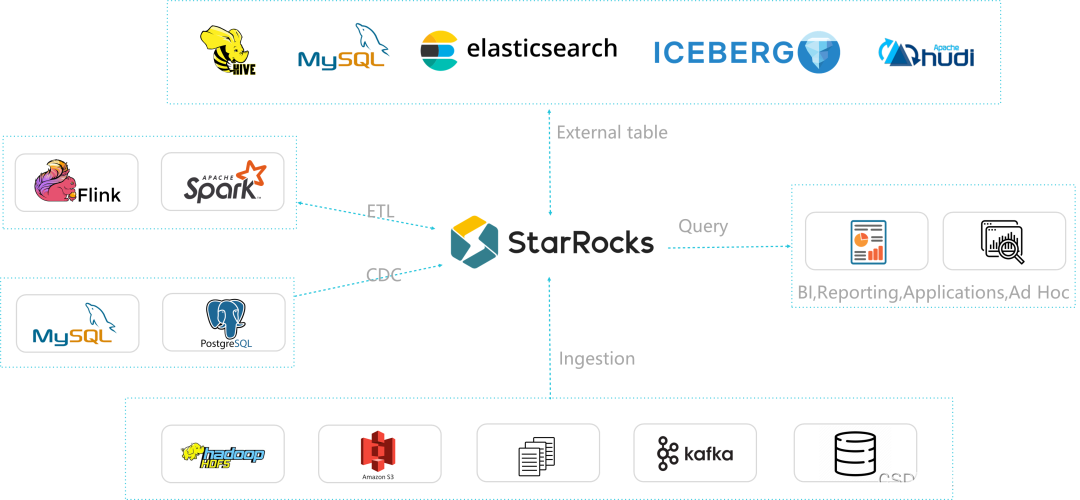
- 3. 支持 MySQL、StarRocks、Elasticsearch、 Hive、Hudi、Iceberg等多种外部表查询数据,重构了数据基础设施,把复杂的分析架构变得简单⽽统⼀。
- 4. 支持 Stream Load、Spark Load、Broker Load、Routine Load、DataX 导入、CloudCanal导入、Spark-connectors、Flink-connectors 多种导入。在离线与实时场景,可根据实际需要灵活选择各类导入方式,稳定且可靠。
- 5. 对于三方组件依赖少,可以极大减少运维范围和复杂度,并且企业版还提供了可视化的运维管理平台,极大方便了日常运维使用。
- 6. 社区活跃,问题能够较快获得反馈和解决。版本迭代快,产品能力和产品生态圈都可以看到提升迅速
StarRocks 把复杂的分析架构变得简单而统一
三、架构演进
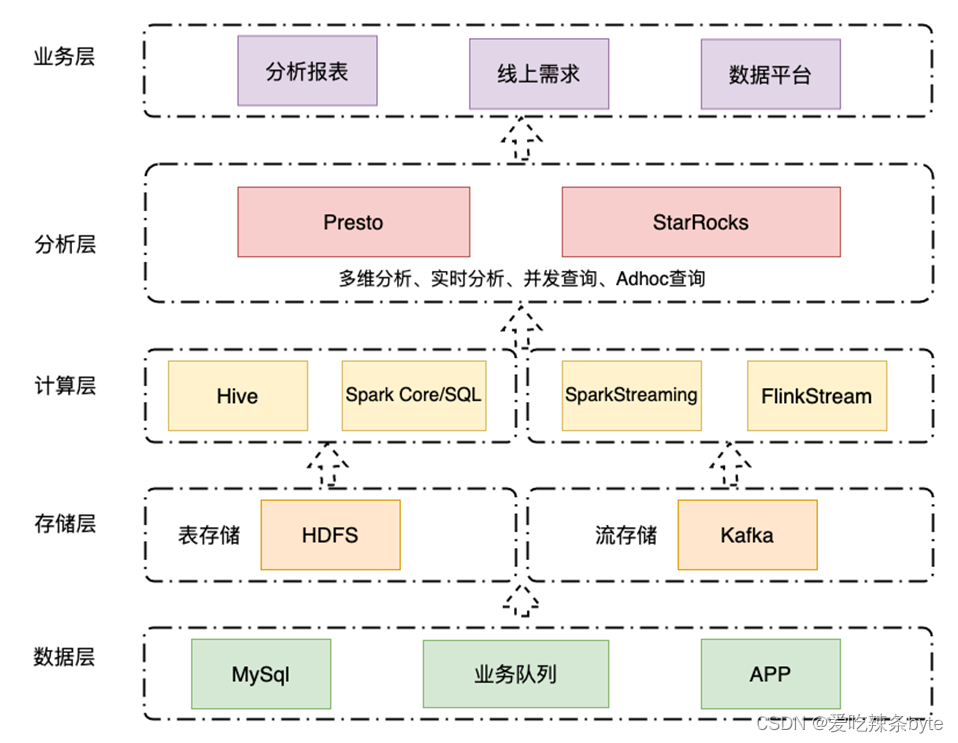
目前主要是用StarRocks存储大量明细数据,利用时效性高的特点,替换了原有大数据架构分析层中依赖的MongDB、MySQL、Redis 等数据库,从而避免了数据指标的重复开发,极大减少了快速变化业务下的复杂开发工作。未来,计划利用StarRocks强大的物化视图,多种数据Load方式、外表能力、全面完成Presto的替换,进一步提升大数据的Ad-Hoc(数据探索)性能。
四、实时数仓构建
随着数据的增长速度越来越快,精细化运营的诉求不断增加,传统的T+1离线数仓构建模式,很难满足业务运营的增长需求。越早洞察数据,越早拿到分析指标结果,才能帮助业务把握先机。数仓时效性由此逐渐从天级提高到小时级,分钟级乃至秒级。
于是,我们采用了StarRocks构建了实时数仓:
- 通过FlinkCDC从kafka摄入业务数据写入StarRocks,构建了实时数仓ODS层,外部调度组件通过SQL完成ETL计算,通过微批方式写入DWD层;DWD层进一步统计聚合写入DWS,或者直接利用物化视图构建DWS层。
- 流式系统兼容,Flink/Spark Streaming 从 Kafka摄入数据,进行业务计算。通过StarRocks提供的Connector连接器将实时计算结果写入StarRocks实时数仓DWS层,在实时场景中实现统一OLAP分析。
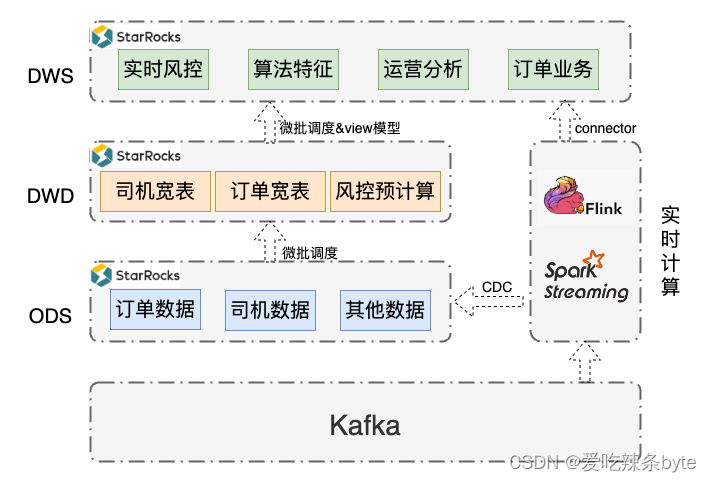
引入StarRocks 之后,我们已经对订单分析、司机分析、风控分析、算法策略等场景的数据生产过程进行了改造:
- 1.在订单场景中,StarRocks极速查询能力能够帮助将订单相关的明细数据全部导入并保存起来。数据按天分区,使用主键模型及其部分列更新的特性,将原来存储于多个系统,不同时间更新的数据写入一张订单明细宽表,为订单业务的实时分析提供了统一的数据支撑,此外订单数据在很多场景的分析中都是需要的,因为未来可以通过在主键模型上构建物化视图,为订单分析业务拓展更多可能性,且能够保证相关数据的一致性。
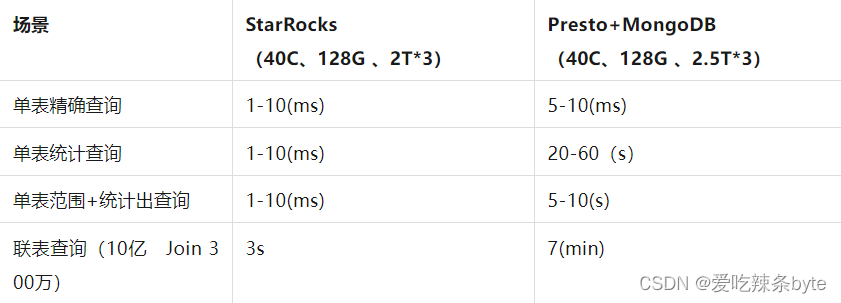
- 2. 在司机运营分析场景中,通过 Spark/Flink Streaming实时地将用于计算司机运营指标的数据写入到StarRocks,然后利用其强大的多表Join能力,使得多维分析不再完成依赖预处理,让业务运营人员更加及时地掌握当前线上司机数量,上线时长等信息,为其精细化分析和运营提供了保障。与此同时,业务人员的查询性能体验了至少5倍的提升:
- 3.在实时风控场景下,能否保障数据的时效性,对于企业损失控制具有重要意义。以司机运营活动的作弊识别为例,之前由于作弊识别滞后的时间较长,存在先发奖又扣走的情况,使得司机的体验变差,且有成本损失风险。将风控识别实时化后,能极大避免此类问题。再比如某些渠道待付率异常上涨,若能实时识别、及时干预,就能减少不必要的损失。之前风控特征使用的是离线集群T+1产生的数据,且整个过程需要复杂代码才能实现。
引入StarRocks后,我们将kafka的数据通过Flink CDC的方式写入到ODS层,之后利用SQL 以微批的方式构建DWD和DWS层,对于实时性高的数据,则通过Spark Streaming/Flink后,再利用StarRocks提供的Connector写入到DWS层,最终指标的计算直接通过SQL查询DWS层即可完成。这不仅使得风控预警更加及时,也对风控指标的快速调整提供了重要支撑,当维度变化或增加新需求时,工作量从5天缩短到2-3天即可完成。
- 4. 在算法策略中,更实时的数据和更加灵活的模型特征构建,可以帮助业务团队更快对市场和竞争上的变化做出响应。以动调策略模型迭代为例,动调是平衡供需的重要手段,动调实验结果时效性的提高,可以极大提升业务团队的开城效率。我们正在尝试和算法团队一起,利用 StarRocks 极速查询的能力来提升实时特征构建效率,加速模型的迭代速度,工期预计缩短 70% 以上,为业务团队更灵活应对业务变化提供助力。
基于StarRocks搭建实时数仓的过程中,我们也遇到了一些问题,和StarRocks沟通找到的解决和优化方案如下:
- 1. 在 Flink中使用StarRocks维表做关联时,有时QPS(并发)过高导致整个集群查询性能下降。可以通过规避多条数据一次查询,合理设置分区等措施,提升了查询的并发数;
- 2. 实时数据导入时,有时写入频率过快,可能会导致版本过多/不健康副本的问题。通过设置Spark合并分区或重新分区方式来控制写入,调整Flink Sink并行或者Flink Connector并发的方式控制写入,有效解决了问题:
- 3. 多表 Join有时出现内存过高的问题。一方面在可接受的查询性能范围内,设置查询的并发度,查询调整内存参数等,另一方面,业务开发层面对查询任务进行分解,数据进行预计算,计算整合预计算结果,分而治之,减小了查询对集群的压力;
- 4.离线数据通过Broker导入时,会出现BE资源占有过高的问题。我们通过控制导入并发量等措施,保证了整个集群得以健康稳定运行。
五、业务实践价值未来规划
总体来说,StarRocks 拥有优秀的功能和性能,迭代快速,社区活跃,服务体系良好,能够很好支撑首约大数据部门未来的规划。下一步我们将从以下几方面继续推进:
- 1.实时场景将全部迁入至StarRocks,成为首约实时数仓统一的数据底座;
- 2.接入部分离线数据,构建流批一体的数据仓库,实现极速统一的数据分析系统;
- 3. 加强StarRocks监控报警,包括数据接入,数据产出,任务监控等,及时干预 ,完善整体的运维体系;
未来,我们也更加期待 StarRocks 后续版本更加强大的功能特性:
- 1. 支持复杂数据类型,如 Map、Struct等;
- 2.RountineLoad支持自定义解析,单个任务可导入多张表的数据;
- 3. Spark-connector 支持 DataFrame 写入;
- 部分列更新不需要指定,可自适应需要更新列。
参考文章:
首汽约车驶向极速统一之路!出行平台如何基于StarRocks构建实时数仓?