阅读目录
- 文献阅读
- Abstract
- Introduction
- 3. Method
- 3.1. Problem Overview
- 3.2. Fusion via Vision-Language Model
- 4. Vision-Language Fusion Datasets
- 5. Experiment
- 5.1Infrared and Visible Image Fusion
- 6. Conclusion
- 个人总结
文献阅读

原文下载:https://arxiv.org/abs/2402.02235
Abstract
图像融合从多源图像中整合必要信息成单张图像,强调显著性的结构和纹理,精炼不足的区域。现有的方法主要是识别像素级和语义视觉特征。然而在深度语义信息之外的文本信息探索不足。因此,我们定义了一个创新的范式佳作FILM(Fusion via vIsion-Language
Model),首先利用提取不同原图像的文本信息去指导融合。输入的图像首先处理后去生成语义提示,然后喂到ChatGPT中去获得丰富的语义描述。通过交叉注意力这些描述被用于融合文本域中用于指导源图像关键视觉特征的提取,导致由文本语义信息指导更加深层的上下文理解。最终的融合图像由视觉特征解码器生成。这种范式在4种融合任务中得到了满意的结果:红外与可见光、医学图像、多曝光、多聚焦。我们也提出了一个视觉语言数据集包括基于ChatGPT的段落描述,用于在4个融合任务的8个图像融合数据集,促进了基于视觉语言模型的视觉研究。代码即将开源。
Introduction
因此,本文我们提出了创新的算法叫做Image Fusion via VIsion-Language Model (FILM)。这个方法首次将大语言模型的能力整合到图像融合中,利用从文本数据导出的语义理解来指导和增强融合图像的视觉特征。我们方法包含3部分,文本特征融合、语言指导视觉特征融合,语言特征解码器。工作流如下图1所示,我们的共享可以总结成以下几点:
- 在图像融合中提出了一个创新性的范式,据我们所知,这是第一个由语言模型驱动的文本指导实现来指导图像融合算法。这种方法有助于理解更深层次的文本语义信息,促进从各种源图像中提取和融合的优势。
- 在4中任务上我们的模型实现了令人满意的结果,在不同应用场景上证明了其有效性。
- 我们引入了一系列用于图像融合的视觉语言基准数据集,涵盖跨四个融合任务的八个数据集。这些数据集包含了用ChatGPT模型来手动细化的提示定制,以及有ChatGPT生成配对的文本描述,为了促进在图像融合中使用视觉语言模型的后续研究。
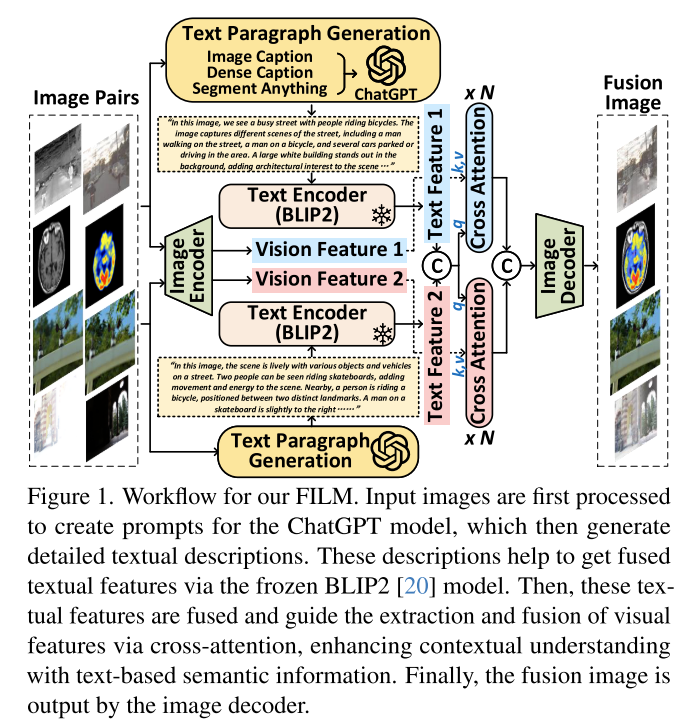
图1:FILM的工作流,输入的图像首先为ChatGPT模型生成提示,然后由它生成详细的文本描述。这些描述通过冻结的BLIP2模型得到融合的文本特征。然后这些文本特征被融合,通过交叉注意力指导视觉特征的提取和融合,通过文本的语义信息的增强上下文的理解。最终,融合图像被图像的Encoder输出。
总结一下:基于ChatGPT生成详细的文本描述,得到文本特征后通过交叉注意力来加强视觉特征,用于挖掘深层次的文本语义信息,然后将融合特征经过图像的解码器得到融合图像。
3. Method
输入的图像对为I_1和I_2,可以是红外与可见光、医学图像、多曝光图像和多聚焦图像。算法最终输出的融合图像记作F。这一节我们将对FILM进行容易理解的描述,I_F=FILM(I_1,I_2),解释它的工作流和设计细节。训练的细节,包括损失函数,都将被讨论。
3.1. Problem Overview
图1和图2是简要和细节的FILM范式工作流,算法可以分为3部分:文本特征融合、语言指导的视觉特征融合和视觉特征解码,分别对应图2的第一、二、三栏,分别用T(·) V(·) D(·)表示。
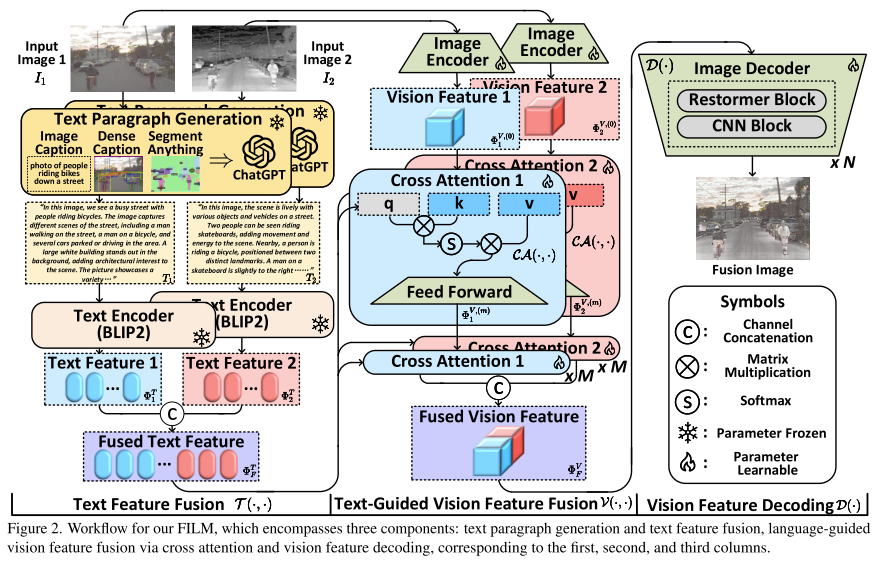
图2:FILM的工作流,包含三部分:文本范式生成、文本特征融合、通过交叉注意力指导的视觉特征融合和视觉特征解码器,分别为第一列、第二列和第三列。FILM算法包含2个输入,由文本特征融合单元T进行初始化的处理。这一部分的提示生成包含图像描述、密集描述和分割一切,通过ChatGPT来生成文本描述。文本描述通过BLIP2的文本编码器来编码,随后将融合他们。语言指导的视觉特征融合V利用融合的文本特征通过交叉注意力去指导原图像视觉特征的提取。这个过程识别并整合融合图像的显著性方面和优势。最终,融合图像F被视觉特征解码器D输出,解码融合的视觉特征到图像。每个部分的细节将分开解读。由于内容的约束,更多的网络细节可以去补充材料查看。
3.2. Fusion via Vision-Language Model
组成1:文本特征融合
文本特征融合部分,原图像{I_1, I_2}作为输入,得到融合文本特征。最初,收到文献的启发,我们将图像输入达BLIP2、GRIT和Segment Anything模型去提取图像的语义信息从整体到细粒度,作为图像描述、密集描述和语义掩码。随后将3中提示输入的ChatGPT模型来生成与原图像I_1和I_2匹配的文本描述T1和T2。我们然后输入T1和T2到冻结BLIP2模型的文本编码器,获得对应的文本特征。最终,将2个文本特征拼接后得到融合的文本特征。更多特征提示和文本生成请参考Sec 4.
组成2:语言指导的视觉特征融合
语言指导的视觉融合部分,通过文本特征来指导从原图像中提取视觉特征。最终,源图像I_1和I_2喂到图像的编码器中得到浅层的视觉特征。图像编码器包含Restormer块和CNN,关注与全局和局部的视觉表达同时保留计算效率和高效的特征提取。随后,浅层的特征被喂到交叉注意力模块,用于融合文本特征去指导视觉特征的提取,更多的关注希望在融合图像中保留原图像的各个部分。K和V由对应的视觉特征提供,Q由融合的文本特征提供。值得注意的是交叉注意力中的前馈神经网络是有Restormer块实现的。经过M次交叉注意力后,文本特征指导的视觉特征被得到,随后,在通道维度上进行拼接后得到融合的视觉特征。
组成3:视觉特征解码
最终将融合的视觉特征输入到一个解码器,包含N个Restormer和CNN模块,输入的融合图像定义为I_F,代表最终由FILM的输出。
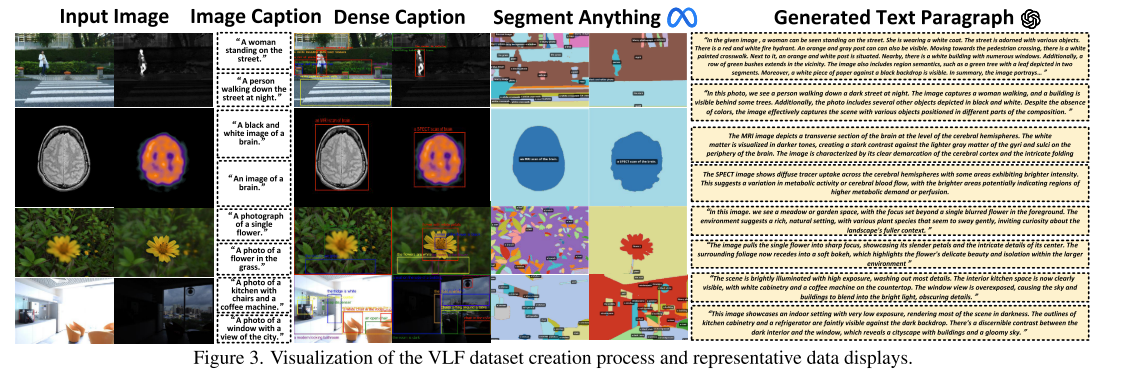
图3:VLF数据集可视化,处理和代表性数据可视化
4. Vision-Language Fusion Datasets
这一部分,将要介绍提出的Vision-Language Fusion(VLF)dataset,包含提示生成,段落描述输出和呈现代表性的可视化。
总览:考虑到各种视觉-语言模型的高计算开销,为了促进后续基于视觉语言模型的图像融合研究,我们提出了VLF数据集。数据集包含有ChatGPT生成的成对的段落描述,包含8个广泛使用的图像融合训练和测试集。MSRS、M3FD、RoadScene(IVF)the Harvard dataset 医学图像(MIF), the RealMFF [69] and Lytro [34] datasets 多聚焦图像融合(MFF), 和the SICE [3] and MEFB [71] datasets 多曝光图像融合(MEF) 。
提示生成:每一个部分的文本段落生成模型如图3。首先收到BLIP2、GRIT、Segment Anything启发,输出图像描述、密集描述和语义掩码。分别提供了一个句子的描述,对象级的信息和语义掩码,用于输入和代表性的语义信息范围,从粗粒度到细粒度。
生成段落描述:随后,生成的语义提示和成对的图像作为输入到ChatGPT中生成段落描述,用于指导随后的融合任务。
统计信息:数据集包含70040段落描述,平均每段描述至少包含7个句子和186个词。在图3中有多模态、多聚焦、多曝光的例子,更多的数据集细节可以在补充材料中查找。
5. Experiment
这一部分将证明FILM在不同融合任务上的性能,表明它的优越性。由于篇幅限制,更多的细节超参选择和视觉结果呈现在补充材料中。
损失函数,总的损失函数如下:
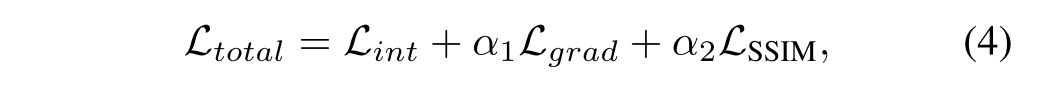
α1和α2作为调节因子。具体损失函数如下所示:

实验细节:RTX 3090,训练300轮使用Adam优化器,初始学习率为1e-4每50轮下降0.5,Batchsize设为16,采用Restormer块作为语言指导的视觉编码器和解码器,8个注意力头和64维度,M和N分别为编码、解码器的数量,分别为2和3。
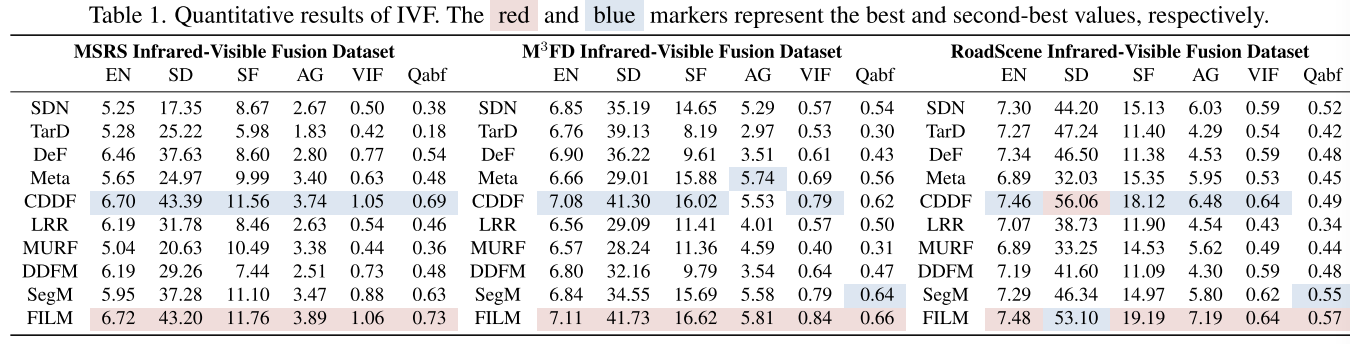
指标:使用6个人指标来评估性能:EN、SD、SF、AG和VIF和Q_abf,更高的指标表明更好的融合质量,更多的信息可以参考30。
5.1Infrared and Visible Image Fusion
红外与可见光实验包含MSRS、M3FD和RoadScene数据集,如文献20和82那样。MSRS:1083对训练集和361对测试集。在M3FD和RoadScene上无需微调,进一步验证FILM的通用性。对比的SOTA方法包括:SDNet、TarDAL、DeFusion、MetaFusion、CDDFuse、LRRNet、MURF、DDFM和SegMIF。
与SOTA方法做对比:如图4,FILM成功整合了红外热辐射信息以及到细节的纹理特征上。

利用文本特征和先验知识,融合结果增强了在低光照条件下的目标的可见性,使其纹理和轮廓更加清晰,并且减小伪影。定量实验如表1,我们方法表明实验性能在所有指标上都是最好的,证实了它在不同环境下的传感器和目标种类上的适应性。因此,FILM证明了它能够很好的保留原图像互补和丰富的信息,生成满足人类视觉的图像。
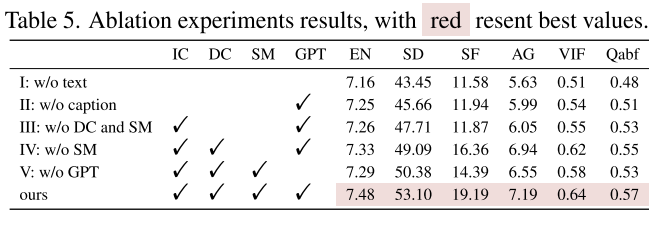
消融实验:为了在提出的方法中有效利用每一个模态,构建了消融实验在RoadScene的测试集上,结果如表5。实验1,移除了文本信息,仅使用视觉特征用于融合,消除文本和图像间的教程注意力,展示FILM中文本引导的特征提取和融合效果。增加Restormer 快的数量,保留总的模型参数接近原始模型。(没看见这个消融啊)实验二-四部分,我们测试了文本语义提示由整体到细粒度的提示,包括图像描述IC,密集描述DC和语言掩码SM。实验2我们直接把原始图像喂到ChatGPT中。通过手动提供提示,GPT生成图像总的描述,用文本输入用作图像融合。这些研究涉及绕开的提示,从IC、DC和SM,在实验3中仅将IC输入到GPT中,实验4,IC和DC共同输入到GPT中,揭示了从粗粒度到细粒度不同方面描述的重要性。最终在实验五,从图像中提取到IC、DC和SM后直接拼接三种描述不输入到GPT中。这个证明了GPT整合文本信息和有效融合的能力。消融实验证明了依赖与不同描述的互补信息,以及GPT的总结能力,我们的实验实现了最优的融合性能,验证了FILM设置的合理性。
6. Conclusion
本研究接近了图像融合中的关键技术:对于视觉特征之外的语义特征利用不足。我们第一次创新性的提出了视觉语言模型FILM,利用原图像的文本描述通过大语言模型来指导融合,能够更加全面的理解图像内容。FILM证明了在不同图像融合任务上的处理结果,包括红外与可见光、医学图像、多曝光和多聚焦图像融合。另外,我们提出了一个新的基准视觉-语言数据集,包括基于ChatGPT对8个数据集生成的描述。我们希望我们的研究能够在大语言模型的图像融合中有新的启示。
个人总结
- 本文以ChatGPT和不同的图像信息(文本描述,密集描述,语义信息),用于挖掘深层次的文本语义信息,文本特征编码通过交叉注意力来增强视觉特征,重建融合图像。能够有效在4个不同的融合任务上具有较好的实验效果。本文还针对4个任务提8个数据集上提出了视觉语言数据集(图像具有ChatGPT生成的文本描述段落)。
- 文本语义已经在成为增强图像融合视觉效果的一个趋势,后面会开源大量的具有文本描述的图像融合数据集,如何有效利用文本段落描述是我们未来研究的一个关键点?
- 还有一篇文章,可以通过控制文本输入来得到不同区域的视觉增强效果,如果利用文本语义特征显得特别重要。
- 未来的自己,不仅仅要多看论文,还要多读,多理解多思考,重要的是多跑代码,理解它,然后再思考自己的研究点,不要盲目去做。Baseline特别重要。